🔖 Spring启动过程
大致如下:
1.创建beanFactory,加载配置文件
2.解析配置文件转化beanDefination,获取到bean的所有属性、依赖及初始化用到的各类处理器等
3.刷新beanFactory容器,初始化所有单例bean
4.注册所有的单例bean并返回可用的容器,一般为扩展的applicationContext
Spring 通过一个配置文件描述 Bean 及 Bean 之间的依赖关系,利用 Java 语言的反射功能实例化 Bean 并建立 Bean 之间的依赖关系。 Spring 的 IoC 容器在完成这些底层工作的基础上,还提供了 Bean 实例缓存、生命周期管理、 Bean 实例代理、事件发布、资源装载等高级服务。
- BeanFactory 是 Spring 框架的基础设施,面向 Spring 本身;
- ApplicationContext 面向使用 Spring 框架的开发者,几乎所有的应用场合我们都直接使用 ApplicationContext 而非底层的 BeanFactory。
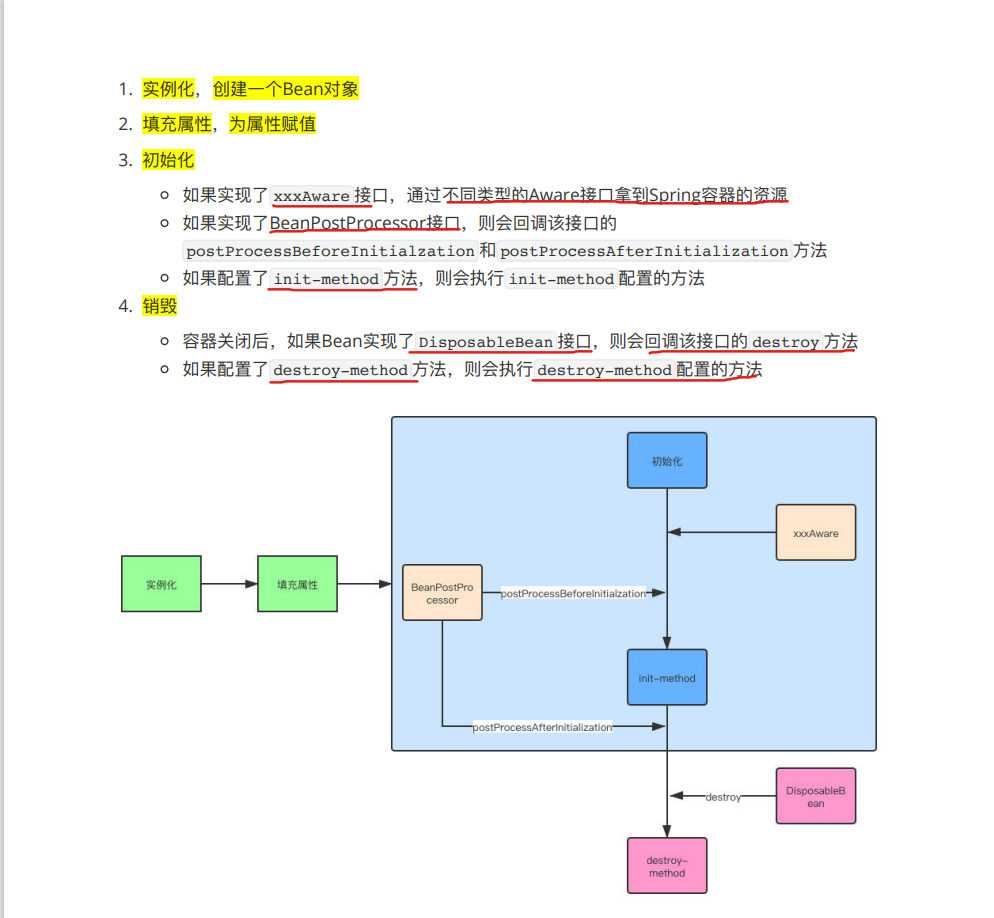
🔖 Bean生命周期
🔖 Bean作用域

✅ 循环依赖
解决了Setter注入或者Field注入的循环依赖问题,构造器注入下的循环依赖,Spring并没有直接解决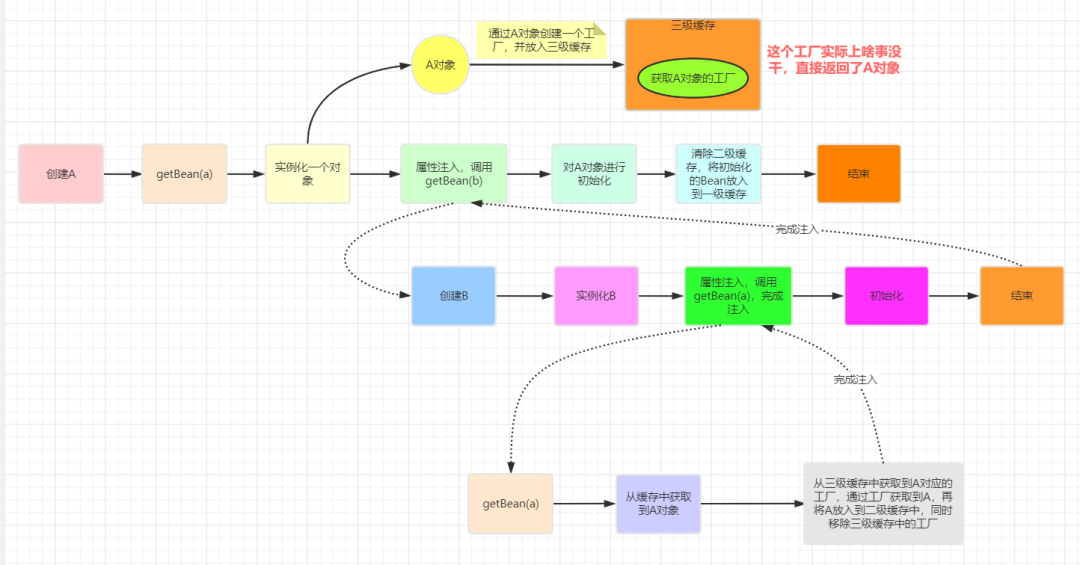
面试官:Spring是如何解决的循环依赖?
答:Spring通过三级缓存解决了循环依赖,
一级缓存为单例池(singletonObjects)
二级缓存为早期曝光对象(earlySingletonObjects)——半成品池
三级缓存为早期曝光对象工厂(singletonFactories)——工厂池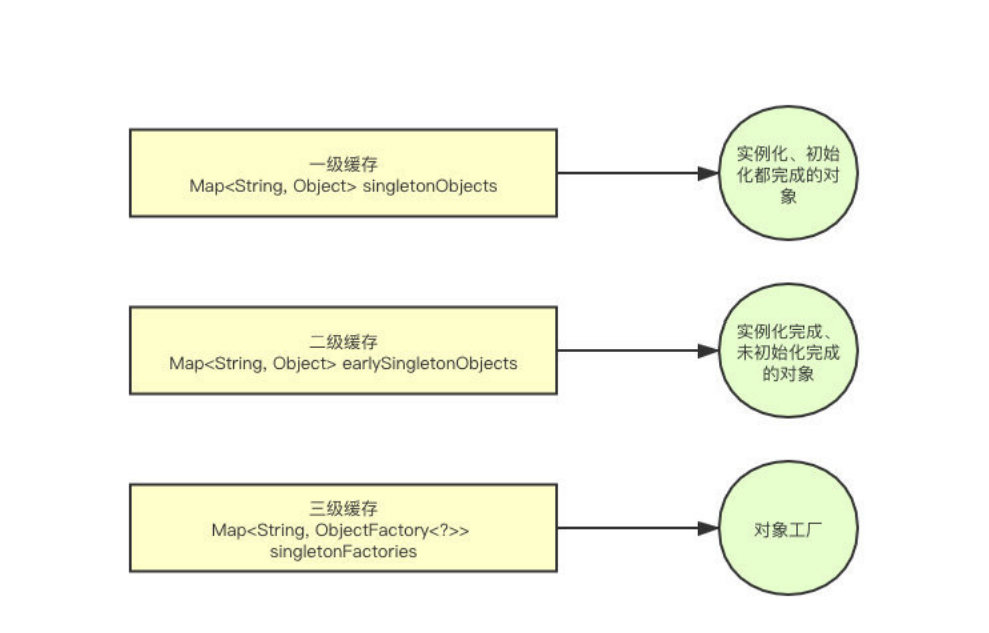
当A、B两个类发生循环引用时,在A完成实例化后,就使用实例化后的对象去创建一个对象工厂,并添加到三级缓存中,如果A被AOP代理,那么通过这个工厂获取到的就是A代理后的对象,如果A没有被AOP代理,那么这个工厂获取到的就是A实例化的对象。
当A进行属性注入时,会去创建B,同时B又依赖了A,所以创建B的同时又会去调用getBean(a)来获取需要的依赖,此时的getBean(a)会从缓存中获取,第一步,先获取到三级缓存中的工厂;第二步,调用对象工工厂的getObject方法来获取到对应的对象,得到这个对象后将其注入到B中。
紧接着B会走完它的生命周期流程,包括初始化、后置处理器等。当B创建完后,会将B再注入到A中,此时A再完成它的整个生命周期。至此,循环依赖结束!
面试官:为什么要使用三级缓存呢?二级缓存能解决循环依赖吗?
答:
A,B循环依赖,先初始化A,先暴露一个半成品A,再去初始化依赖的B,初始化B时如果发现B依赖A,也就是循环依赖,就注入半成品A,之后初始化完毕B,再回到A的初始化过程时就解决了循环依赖
在这里只需要一个Map能缓存半成品A就行了,也就是二级缓存就够了,但是这个二级缓存存的是Bean对象,如果这个对象存在代理,那应该注入的是代理对象,而不是Bean,此时二级缓存无法及缓存Bean,又缓存代理,因此三级缓存做到了缓存工厂 ,也就是生成代理:总结起来:二级缓存就能解决缓存依赖,三级缓存解决的是代理。
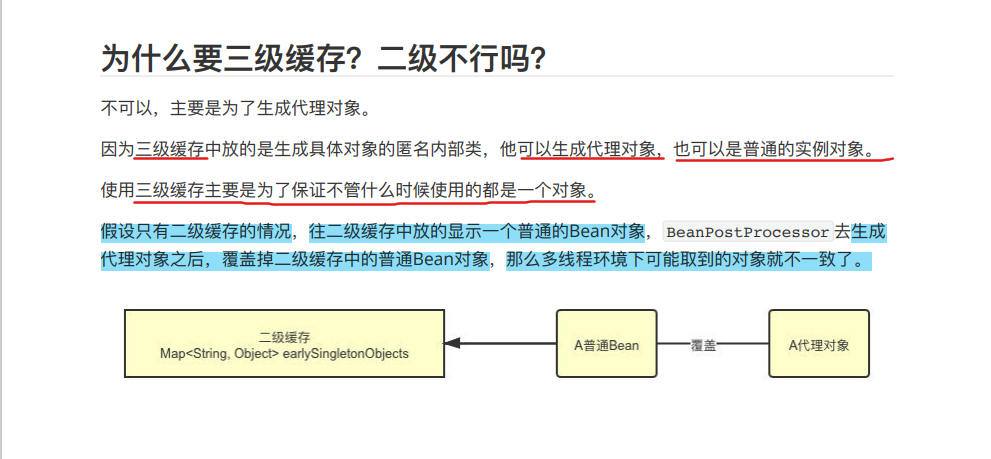
假设只有⼆级缓存的情况,往⼆级缓存中放的显示⼀个普通的Bean对象, BeanPostProcessor 去生成 代理对象之后,覆盖掉⼆级缓存中的普通Bean对象,那么多线程环境下可能取到的对象就不⼀致了
✅ IOC
要了解控制反转( Inversion of Control ), 我觉得有必要先了解软件设计的一个重要思想:依赖倒置原则(Dependency Inversion Principle )。
这就是依赖倒置原则——把原本的高层建筑依赖底层建筑“倒置”过来,变成底层建筑依赖高层建筑。高层建筑决定需要什么,底层去实现这样的需求,但是高层并不用管底层是怎么实现的。
控制反转(Inversion of Control) 就是依赖倒置原则的一种代码设计的思路。具体采用的方法就是所谓的依赖注入(Dependency Injection)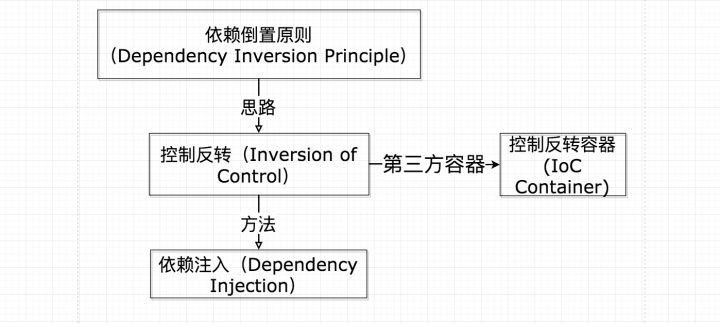
我们用依赖注入(Dependency Injection)这种方式来实现控制反转。所谓依赖注入,就是把底层类作为参数传入上层类,实现上层类对下层类的“控制”。这里我们用构造方法传递的依赖注入方式重新写车类的定义:
✅ AOP
面向对象编程(OOP)中,当需要为多个具有继承关系的对象引入同一个公共行为时,我们只有在每个对象里引用公共行为,会产生大量重复的代码。面向切面编程(AOP)关注的方向是横向的,不同于OOP的纵向。
Spring AOP就是基于动态代理的,如果要代理的对象,实现了某个接口,那么Spring AOP会使用JDK Proxy,去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候Spring AOP会使用Cglib ,这时候Spring AOP会使用 Cglib 生成⼀个被代理对象的子类来作为代理。
CGLIB 框架实现了对无接口的对象进行代理的方式。JDK 动态代理是基于接口实现的,而 CGLIB 是基于继承实现的。它会对目标类产生一个代理子类,通过方法拦截技术对过滤父类的方法调用。代理子类需要实现 MethodInterceptor 接口。
CGLIB 底层是通过 asm 字节码框架实时生成类的字节码,达到动态创建类的目的,效率较 JDK 动态代理低。
当然你也可以使用 AspectJ ,Spring AOP 已经集成了AspectJ ,AspectJ 应该算的上是 Java 生态系统中最完整的 AOP 框架了。
Spring AOP 属于运行时增强,而AspectJ 是编译时增强。 Spring AOP 基于代理(Proxying), 而 AspectJ 基于字节码操作(Bytecode Manipulation)。
如果我们的切面比较少,那么两者性能差异不⼤。但是,当切面太多的话,最好选择 AspectJ , 它比Spring AOP 快很多。

✅ Spring Boot
在使用传统的Spring去做Java EE(Java Enterprise Edition)开发中,大量的 XML 文件存在于项目之中,导致JavaEE项目变得慢慢笨重起来,繁琐的配置和整合第三方框架的配置,导致了开发和部署效率的降低。
简化依赖
比如要创建一个 web 项目,在使用 Spring 的时候,需要在 pom 文件中添加多个依赖,而 Spring Boot 则会帮助开发着快速启动一个 web 容器,在 Spring Boot 中,只需要在 pom 文件中添加如下一个 starter-web 依赖即可。
[
](https://blog.csdn.net/qq_32595453/article/details/81141643)
简化配置
Spring 配置比较繁琐,Spring Boot简化了配置。
Spring Boot如何简化配置:
主要是@EnableAutoConfiguration这个注解起的作用,这个注解是间接隐藏在springboot的启动类注解@SpringBootApplication中。 通过这个注解,SpringApplication.run(…)的内部就会执行selectImports()方法,寻找 META-INF/spring.factories文件,读取里面的文件配置,将事先已经写好的自动配置类有选择地加载到Spring容器中,并且能按照约定的写法在application.properties中配置参数或开关。
简化部署
在使用 Spring 时,项目部署时需要我们在服务器上部署 tomcat,然后把项目打成 war 包扔到 tomcat里,在使用 Spring Boot 后,我们不需要在服务器上去部署 tomcat,因为 Spring Boot 内嵌了 tomcat,我们只需要将项目打成 jar 包,使用 java -jar xxx.jar一键式启动项目。另外,也降低对运行环境的基本要求,环境变量中有JDK即可。
[
](https://blog.csdn.net/qq_32595453/article/details/81141643)
✅ BeanFactory和FactoryBean
BeanFactory 是 Bean 的工厂, ApplicationContext 的父类,IOC 容器的核心,负责生产和管理 Bean 对象。
FactoryBean 是 Bean ,是一个接口,我们可以实现这个接口定制实例化Bean的逻辑。
✅ Spring事务传播机制

✅ SpringBoot启动流程
✅ Spring源码
1.获取单例 bean
public Object getBean(String name) throws BeansException {// getBean 是一个空壳方法,所有的逻辑都封装在 doGetBean 方法中return doGetBean(name, null, null, false);}
看完了源码,下面我来简单总结一下 doGetBean 的执行流程。如下:
- 转换 beanName
转换的目的主要是为了解决两个问题,第一个是处理以字符 & 开头的 name,防止 BeanFactory 无法找到与 name 对应的 bean 实例。第二个是处理别名问题,Spring 不会存储 <别名, bean 实例> 这种映射,仅会存储
- 从缓存中获取实例
对于单例 bean,Spring 容器只会实例化一次。后续再次获取时,只需直接从缓存里获取即可,无需且不能再次实例化(否则单例就没意义了)。从缓存中取 bean 实例的方法是getSingleton(String)
- 如果实例不为空,调用 getObjectForBeanInstance 方法,并按 name 规则返回相应的 bean 实例
- 若上面的条件不成立,则到父容器中查找 beanName 对有的 bean 实例,存在则直接返回
- 若父容器中不存在,则进行下一步操作 – 合并 BeanDefinition
- 处理 depends-on 依赖
- 创建并缓存 bean
- 调用 getObjectForBeanInstance 方法,并按 name 规则返回相应的 bean 实例
- 按需转换 bean 类型,并返回转换后的 bean 实例。
2.创建单例 bean
如果某个 bean 还未实例化,这个时候就无法命中缓存。此时,就要根据 bean 的配置信息去创建这个 bean 了。调用createBean(String, RootBeanDefinition, Object[])方法。

若有收获,就点个赞吧
0 人点赞
