1.面向对象的理解
面向对象是一种“万物皆对象”的编程思想。
在现实生活中的任何物体都可以归为一类事物,而每一个个体都是一类事物的实例。面向对象的编程是以对象为中心,以消息为驱动,所以程序=对象+消息。
面向对象有三大特性,封装、继承和多态。
封装就是将一类事物的属性和行为抽象成一个类,使其属性私有化,行为公开化,提高了数据的隐秘性的同时,使代码模块化。这样做使得代码的复用性更高。
继承则是进一步将一类事物共有的属性和行为抽象成一个父类,而每一个子类有父类的行为和属性,也有自己特有的行为和属性。这样做扩展了已存在的代码块,进一步提高了代码的复用性。
多态, 即⼀个引用变量到底会指向哪个类的实例对象,必须在由程序运行期间才能决定。
多态的一大作用就是为了解耦—为了解除父子类继承的耦合度。简单来说,多态就是允许父类引用指向子类对象。多态的好处:提高了代码的扩展性,前期定义的代码可以使用后期的内容
实现多态需要哪三个步骤
- 要有继承;
- 要有重写;
- 父类引用指向子类对象。
2.简述 BIO, NIO, AIO 的区别?
BIO:同步阻塞,服务器实现模式是一个连接一个线程,当客户端发来连接时服务器就需要启动一个线程进行处理。
NIO:同步非阻塞,服务器实现模式为多个请求一个线程,即客户端发来的请求都会注册到多路复用器上,多路复用器上的连接有io请求时才开启一个线程进行处理。
AIO:异步非阻塞,服务器实现模式为多个有效请求一个线程。即客户端发来的请求由OS处理完成才会通知服务器应用启动线程进行处理。
3.Java注解
它更可以理解为是一种特殊的注释,本身不会起到任何作用,需要工具方法或者编译器本身读取注解的内容继而控制进行某种操作
注解的本质就是一个继承了 Annotation 接口的接口。
而解析一个类或者方法的注解往往有两种形式,一种是编译期直接的扫描,一种是运行期反射。
而编译器的扫描指的是编译器在对 java 代码编译字节码的过程中会检测到某个类或者方法被一些注解修饰,这时它就会对于这些注解进行某些处理。
『元注解』是用于修饰注解的注解,通常用在注解的定义上
JAVA 中有以下几个『元注解』:
- @Target:注解的作用目标
- @Retention:注解的生命周期
但是运行时注解是是我们最不常用的注解,因为反射再运行时的操作是十分的耗时的
4.Java的反射机制?
反射机制是指在程序运行期间,对任意一个类都能获取其所有属性和方法,对任意一个对象都能调用其属性和方法,这种动态获取类和对象信息的技术,称为反射机制。
先提一个问题:假如现在有一个类User,我想创建一个User对象并且获取到其name属性,该怎么做呢?
public class Main {public static void main(String[] args) {User user = new User();System.out.println(user.getName());}}
这种方式是我们日常在写代码时经常用到的一种方式。这是因为我们在使用某个对象时,总是预先知道自己需要使用到哪个类,因此可以使用直接 new 的方式获取类的对象,进而调用类的方法。
那假设我们预先并不知道自己要使用的类是什么呢?这种场景其实很常见,比如动态代理,我们事先并不知道代理类是什么,代理类是在运行时才生成的。这种情况我们就要用到今天的主角:反射
这里我们需要讲一个“类对象”的概念。那么“类”是不是也可以认为是一个对象呢?java中有一种特殊的类:Class,它的对象是“类”,比如“String”类,“Thread”类都是它的对象。
java.lang.Class是访问类型元数据的接口,也是实现反射的关键数据。通过Class提供的接口,可以访问一个类型的方法、字段等信息。
2.1 获取Class对象
public static void main(String[] args) throws ClassNotFoundException {// 1.已实例化的对象可调用 getClass() 方法来获取,通常应用在://传过来一个 Object类型的对象,不知道具体是什么类,用这种方法User user = new User();Class clz1 = user.getClass();// 2.类名.class 的方式得到,该方法最为安全可靠,程序性能更高//这说明任何一个类都有一个静态成员变量 classClass clz2 = User.class;// 通过类的全路径名获取Class对象,用的最多Class clz3 = Class.forName("com.reflect.User");// 一个类在 JVM 中只会有一个 Class 实例,即我们对上面获取的 clz1,clz2,clz3//进行 equals 比较,发现都是true。}
2.2 反射与类加载的关系
java类的执行需要经历以下过程,
编译:java文件编译后生成.class字节码文件
加载:类加载器负责根据一个类的全限定名来读取此类的二进制字节流到 JVM 内部,并存储在运行时数据区的方法区,然后在堆内存生成一个代表这个类的 java.lang.Class 对象实例。这个对象作为访问方法区中类型数据的外部接口。
链接:
- 验证:当然需要校验Class文件是否符合虚拟机规范
- 准备:静态变量赋初值和内存空间,final修饰的内存空间直接赋原值,此处不是用户指定的初值。
- 解析:符号引用转化为直接引用,分配地址
初始化:有父类先初始化父类,然后初始化自己;如果是静态变量,则用用户指定值覆盖原有初值;如果是代码块,则执行一遍操作
Java的反射就是利用上面第二步加载到jvm中的.class文件来进行操作的。.class文件中包含java类的所有信息,当你不知道某个类具体信息时,可以使用反射获取class,然后进行各种操作
首先我们来看看如何使用反射来实现方法的调用的
public class Main {public static void main(String[] args) throws ClassNotFoundException, NoSuchMethodException, IllegalAccessException, InvocationTargetException, InstantiationException {// 1.获取类对象Class clz3 = Class.forName("com.reflect.User");// 2.获取类的构造函数Constructor constructor = clz3.getConstructor(String.class, Integer.class);// 3.创建一个对象User user = (User)constructor.newInstance("璐璐", 17);// 4.获取方法getNameMethod method = clz3.getMethod("getName");// 5.调用该方法String name = (String) method.invoke(user);System.out.println(name);}}
2.3获取 Method 对象
getMethod和getDeclaredMethod的区别
Method对应的是Member.PUBLIC,DeclaredMethod对应的是Member.DECLARED
两者定义如下
publicinterface Member {/*** Identifies the set of all public members of a class or interface,* including inherited members.* 标识类或接口的所有公共成员的集合,包括父类的公共成员。*/public static final int PUBLIC = 0;/*** Identifies the set of declared members of a class or interface.* Inherited members are not included.* 标识类或接口所有声明的成员的集合(public、protected,private),但是不包括父类成员*/public static final int DECLARED = 1;}
5.接口与抽象类的区别
相同点
(1)都不能被实例化
不同点
(1)接口只有定义,不能有方法的实现,而抽象类可以有定义与实现,方法可在抽象类中实现。
(2)实现接口的关键字为implements,继承抽象类的关键字为extends。一个类可以实现多个接口,但一个类只能继承一个抽象类。
(3)接口强调特定功能的实现,而抽象类强调所属关系。
(4)接口成员变量默认为public static final,必须赋初值,不能被修改;
接口是自上而下的抽象过程,接口规范了某些行为,是对某一行为的抽象。我需要这个行为,我就去实现某个接口,但是具体这个行为怎么实现,完全由自己决定。
抽象类是自下而上的抽象过程,抽象类提供了通用实现,是对某一类事物的抽象。我们在写实现类的时候,发现某些实现类具有几乎相同的实现,因此我们将这些相同的实现抽取出来成为抽象类,然后如果有一些差异点,则可以提供抽象方法来支持自定义实现。
6.Java泛型
好处:
1,类型安全。 泛型的主要目标是提高 Java 程序的类型安全。通过知道使用泛型定义的变量的类型限制,编译器可以在一个高得多的程度上验证类型假设。
2,消除强制类型转换。 泛型的一个附带好处是,消除源代码中的许多强制类型转换。这使得代码更加可读,并且减少了出错机会。
泛型的好处是在编译的时候检查类型安全,并且所有的强制转换都是自动和隐式的,提高代码的重用率。
Java的泛型是伪泛型,这是因为在Java编译期间,所有的泛型信息都会被擦除,这也就是类型擦除。
原始类型 就是擦除去了泛型信息,最后在字节码中的类型变量的真正类型,无论何时定义一个泛型,相应的原始类型都会被自动提供,类型变量擦除,并使用其限定类型(无限定的变量用Object)替换。
因为在Pair
如果类型变量有限定,那么原始类型就用第一个边界的类型变量类替换。
public class Pair<T extends Comparable> {}
那么原始类型就是Comparable。
7.equals方法
String中的equals方法是被重写过的,因为Object的equals方法是比较对象的内存地址,而String的equals方法比较的是对象的值。
当创建String类型的对象时,JVM会在常量池中查找有没有已经存在的值和创建的值相同的对象,如果有就把它赋给当前引用,如果没有就在常量池中重新创建一个String对象。
8.String用new与不new的区别
String str1=“ABC”:可能会创建一个或不创建对象:如果常量池中有“ABC”,则不创建对象,直接指向那个地址,如果没有,则在常量池中创建一个新的值为“ABC”的对象。
String str2 = new String(“ABC”):一定会创建一个对象,可能创建两个对象:先在堆中开辟一个空间,将那个空间的地址给str2(创建了第一个对象),然后取常量池中,看有无“ABC”,如果有,则将这个地址给堆中开辟的空间,如果没有,则新建一个值为“ABC”的对象(创建了第二个对象),将这个新创建的对象给堆中开辟的那个空间。
[
](https://blog.csdn.net/weixin_44847031/article/details/110249936)
9.自动装箱与拆线
装箱就是 自动将基本数据类型转换为包装器类型;拆箱就是 自动将包装器类型转换为基本数据类型。
Integer i = 10; //装箱int n = i; //拆箱
在装箱的时候自动调用的是Integer的valueOf(int)方法。拆箱的时候自动调用的是Integer的intValue方法。
public class Main {public static void main(String[] args) {Integer i1 = 100;Integer i2 = 100;Integer i3 = 200;Integer i4 = 200;System.out.println(i1==i2);System.out.println(i3==i4);}}truefalse
public static Integer valueOf(int i) {if(i >= -128 && i <= IntegerCache.high)return IntegerCache.cache[i + 128];elsereturn new Integer(i);}
valueOf方法创建Integer对象的时候,如果数值在[-128,127]之间,便返回指向IntegerCache.cache中已经存在的对象的引用;否则创建一个新的Integer对象。
注意,Integer、Short、Byte、Character、Long这几个类的valueOf方法的实现是类似的。
Double、Float的valueOf方法的实现是类似的。——如果上面例程改成Double,则都是false
10.重载与重写
重载:同一个类中多个同名方法根据不同的传参来执行不同的处理逻辑
重写:子类方法对父类方法的重新改造,外部的样子不能改变,内部的逻辑可以改变
11.深拷贝与浅拷贝
- 浅拷贝:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷
贝。 - 深拷贝:对基本数据类型进行值传递,对引用数据类型,创建⼀个新的对象,并复制其内
容,此为深拷贝。
12.wait() 和 sleep() 方法的区别
来源不同:sleep() 来自 Thread 类,wait() 来自 Object 类。
对于同步锁的影响不同:sleep() 不会该表同步锁的行为,如果当前线程持有同步锁,那么 sleep 是不会让线程释放同步锁的。wait() 会释放同步锁,让其他线程进入 synchronized 代码块执行。
恢复方式不同:两者会暂停当前线程,但是在恢复上不太一样。sleep() 在时间到了之后会重新恢复;wait() 则需要其他线程调用同一对象的 notify()/nofityAll() 才能重新恢复。
13.StringBuilder与StringBuffer的区别
StringBuilder 与 StringBuffer 都继承自 AbstractStringBuilder 类,在 AbstractStringBuilder 中 也是使用字符数组保存字符串 char[]value 但是没有用 final 关键字修饰,所以这两种对象都是可变的。
StringBuffer 底层方法加了synchronized同步锁,是线程安全的。
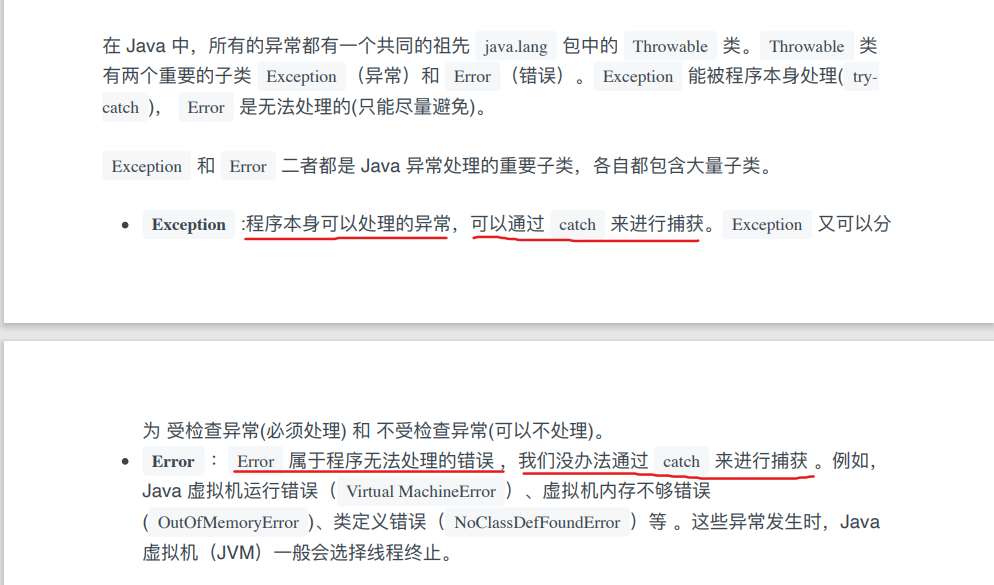
14.Java异常处理
15.静态变量

16.HashMap和HashTable的区别

17.List、Set和Map的区别


20.HashMap源码分析
类签名与成员变量
HashMap 类签名如下:
public class HashMap<K,V> extends AbstractMap<K,V>implements Map<K,V>, Cloneable, Serializable
HashMap 继承了 AbstractMap 类,并且实现了 Map、Cloneable 和 Serializable 接口。AbstractMap 类主要就是对 Map 接口的一个初步的实现。Cloneable 接口表示 HashMap 实现了 Object 类中的 clone() 方法,而 Serializable 接口则说明这个类是可序列化的,当然众所周知,Serializable 接口仅仅是一个标志接口,没有规定任何需要实现的方法。
HashMap 有几个默认属性:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16static final int MAXIMUM_CAPACITY = 1 << 30;static final float DEFAULT_LOAD_FACTOR = 0.75f;static final int TREEIFY_THRESHOLD = 8;static final int UNTREEIFY_THRESHOLD = 6;static final int MIN_TREEIFY_CAPACITY = 64;
内部存储结构
HashMap 中有两个静态内部类,Node<K, V> 和 TreeNode<K, V>,Node<K, V> 继承了 Map.Entry<K, V>,而 TreeNode<K, V> 继承了 LinkedHashMap.Entry<K, V>,LinkedHashMap.Entry<K, V>则继承了Node<K, V>类,从而 TreeNode<K, V> 间接也继承了 Node<K, V> 类。Node 类代表一个普通的键值对节点,而 TreeNode 代表一个二叉树节点。它们之间的变换将在下面讲解。
HashMap 内部有一个成员变量:transient Node<K,V>[] table,是一个 Node 数组,每一个 Node 就是一个 hash 桶。HashMap 中的所有数据实际上都存储在这个数组中。(PS:由于 TreeNode 也是 Node 的子类,所以 TreeNode 也是可以存入 Table 的)
有一个问题就是,table 数组明明是用于保存 HashMap 所有的数据的,为什么被声明为 transient 的(声明为 transient 类型的变量在对象序列化时不会参与)?
ANS:HashMap 在确定一个 key 被存储在 table 的哪个元素中时,是通过 Object.hashCode()方法获取到对象的哈希值,并将哈希值与桶个数(就是 table 数组的长度)取模来确定的。Object.hashCode()方法是一个 native 方法,其实现依赖于 JVM 虚拟机的实现。所以在不同平台,同一个对象的哈希值可能是不同的,这就导致了其保存在 table 中的位置可能是不同的,直接将一个 HashMap 传输过去可能会出错。
所以现有的 HashMap 的序列化做法,是将其中的所有 key 都直接保存,在反序列化时再重新生成一个 HashMap,并将 key 逐个插入。
构造方法
HashMap有三个构造方法:
public HashMap();public HashMap(int initialCapacity);public HashMap(int initialCapacity, float loadFactor);
第一个和第二个方法都需要调用第三个方法,不同的仅仅是使用默认值而已。第三个方法需要两个参数,initialCapacity 和loadFactor,分别是上面提到的 Node 数组 table 的初始化容量,和一个值 loadFactor,表示负载系数。这两个值的默认值分别是 DEFAULT_INITIAL_CAPACITY 和 DEFAULT_LOAD_FACTOR。也就是说,在无参构造一个 HashMap 时,Hash 桶的初始大小(capacity)为 16,且负载系数(loadFactor)是 0.75。那么负载系数是什么呢?
负载系数是 Map 扩容中的一个重要参数,当 Map 中的元素数量逐渐增多,使得 size / capacity 大于等于负载因子时(注意是 size是 key 的个数,而不是占用 Hash 桶的个数,多个 key 可能占用一个桶),就会触发 HashMap 的一次扩容操作。
那么,这个值的默认值为什么是 0.75?
大概是一个统计学原理,时间和空间成本上提供了很好的折中。解释是, 一个bucket空和非空的概率为0.5,通过牛顿二项式等数学计算,得到这个loadfactor的值为log(2),约等于0.693。回答者认为,任何小于0.75大于log(2)的值都能提供更好的性能,0.75可能就是随便写的一个值。
public HashMap(int initialCapacity, float loadFactor) {...this.loadFactor = loadFactor;this.threshold = tableSizeFor(initialCapacity);}
注意一下这里的 threshold 表示下一次扩容操作时 table 要达到的容量,由于该构造方法并没有对 table 进行初始化,那么下一次扩容操作就需要扩容到 threshold 大小。而在其他情况下,threshold 参数表示当前 map 中元素的上限,即 map 的容量与负载系数的乘积,在元素个数超出 threshold 时就会发生扩容。
除了对参数做了一些校验以外,就仅仅是把数值存了起来,并没有初始化什么东西。tableSizeFor()方法如下,作用是对于一个初始容量,给出大于等于这个容量的最小的2的幂次方:
static final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;}
put()方法
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);}
注意这里传入putVal的是key的hash值,hash()方法的实现如下,也就是扰动函数:
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}
这里就体现了为什么HashMap的key可以是null,当key为null时,其Hash值被当作0处理。那么问题来了,为什么不直接使用key的hashCode,而是要将hashCode右移16位再和自己异或?这就是扰动算法的原理了。
hashCode()方法,是key的类自带的Hash函数,返回一个int的Hash值,理论上,这个值应当均匀得分布在int的范围内,即-2147483648到2147483647之间,接近40亿的空间,这显然是很难产生碰撞的。
但是问题在于,HashMap中的Hash桶并没有40亿大小,事实上,在最初默认初始化的时候,才16个桶。所以需要将这个HashCode映射到这16个桶上,一个比较简单均匀的办法,就是取模,对容量取模。例如,以初始长度16为例,二进制数为00000000 00000000 00001111,如果我们让10100101 11000100 00100101这个数对16取模的话,其实仅仅是取这个数的低四位,而高位全部清零。这种情况下,就会导致很严重的碰撞。
这时就需要扰动函数了,它将一个32位数的高16位和低16位做一个异或操作,就变相地将高位的部分信息保存在了低位,增加了低位的随机性,减少的碰撞的几率。
[
](https://blog.csdn.net/qq_40856284/article/details/106567935)
putVal()开头首先判断当前HashMap的table(存储空间)是否已经初始化或者为空,因为在构造函数中,并没有对table进行任何操作,如果是空的话需要进行初始的扩容:
if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;
接着获取了table上对应位置的Hash桶,并判断是否为null,如果是null,说明没有发生Hash碰撞,直接新建一个节点放进去即可,否则要进行碰撞处理:
if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {// 碰撞处理部分...}
注意这个地方取出Hash桶的下标的方法,桶的下标为:(n - 1) & hash,其中n是桶的个数。上面说过,理论上将大的Hash值映射到较小的数组上,使用的取模运算。
这个公式其实就是一种快速的取模运算,大致原理可以看上面那张图的计算下标部分。这种方法有一个局限性,就是n − 1 的二进制表示必须全是1,也就是说,n必须是2的幂次方!这就是table的容量必须是2的幂次方。
接着我们看一下碰撞处理的部分:
if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {...}
分为三种情况讨论,第一种就是当前桶的头节点的hash和现有的相等,且key也相同的情况下,将其暂时保存在e中,后面需要进行替换,说明这次push是更新一个已存在的key的value。
否则,如果当前桶的头节点是一个树节点(TreeNode),那么就调用putTreeVal()方法向二叉树中插入这个节点。
否则,就是一个普通的链表插入操作了:
for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}
遍历链表至链表尾,将节点插在尾部,同时检查了一下链表的长度,如果长度大于了TREEIFY_THRESHOLD的长度,就需要将这条链表转化为一棵红黑树,调用的是treeifyBin()方法。注意这里提一嘴treeifyBin()方法,调用了treeifyBin()方法并不是绝对会转化为红黑树,在该方法开头有一个判断:
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)resize();
这里要求table的length,即桶的数量大于等于MIN_TREEIFY_CAPACITY=64的值,才可以进行下一步,否则就仅仅会进行一次扩容,而不会将链表转化为红黑树。主要是为了防止在HashMap建立初期,多个键值对恰好被放入了同一个链表中而导致不必要的转化。
如果在遍历过程中发现了相同的key,说明这次put就是一个更新操作,将在下面进行更新。
if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}
如果put是一个更新操作,就需要使用新值覆盖,并将旧的值返回。
get()方法
public V get(Object key) {Node<K,V> e;return (e = getNode(hash(key), key)) == null ? null : e.value;}
也是一个包装方法,实际的get操作在getNode()方法中实现,如果getNode()返回null,get也就返回null,否则就返回这个Node的value。
getNode()方法用于根据给定的hash和key在table中寻找Node。
final Node<K,V> getNode(int hash, Object key) {Node<K,V>[] tab; Node<K,V> first, e; int n; K k;if ((tab = table) != null && (n = tab.length) > 0 &&(first = tab[(n - 1) & hash]) != null) {if (first.hash == hash && // always check first node((k = first.key) == key || (key != null && key.equals(k))))return first;if ((e = first.next) != null) {if (first instanceof TreeNode)return ((TreeNode<K,V>)first).getTreeNode(hash, key);do {if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;} while ((e = e.next) != null);}}return null;}
它的实现很简单,大致流程是,首先根据hash值找到对应的hash桶,如果hash桶的头节点的key就等于想要的key,那就直接返回头节点。否则,判断头节点的类型,如果是树节点,就使用getTreeNode()方法在红黑树中进行查找,否则就使用普通的链表查找,找到的话返回该节点,否则返回。
resize()方法
resize()方法用于对table进行初始化,或者将table的容量扩容为原来的两倍。
if (oldCap > 0) {if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // double threshold}else if (oldThr > 0) // initial capacity was placed in thresholdnewCap = oldThr;else { // zero initial threshold signifies using defaultsnewCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab;
初始,对原本table的大小和threshold进行了一系列判断,如是否是最新初始化或者原大小是否已经超过上限之类的。最终确定要扩容到的大小newCap和新的阈值newThr。如果没有超出上限的话,newCap,即新桶的大小,是oldCap左移一位,即原桶数量的两倍,threshold也直接变为原来的两倍。
接着按照newCap的大小初始化一个Node数组newTab,并直接将table的引用指向了newTab,那么旧的桶则由oldTab持有。判断oldTab是否为null,如果是null,则说明这是HashMap构造完成后的第一次resize(),无需迁移节点,直接返回newTab即可。
迁移过程如下:
for (int j = 0; j < oldCap; ++j) {Node<K,V> e;if ((e = oldTab[j]) != null) {oldTab[j] = null;if (e.next == null)newTab[e.hash & (newCap - 1)] = e;else if (e instanceof TreeNode)((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else { // preserve orderNode<K,V> loHead = null, loTail = null;Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;do {next = e.next;if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}else {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);if (loTail != null) {loTail.next = null;newTab[j] = loHead;}if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}
迁移过程,主要就是对节点重新计算Hash并安排的过程。主要就是对桶的遍历,并且根据桶的头节点的类型来进行不同的动作,如果头节点是一个TreeNode,那么就需要调用split()方法对树进行拆分(第8行),否则就对链表进行拆分。对树的操作暂且不说,主要来看对链表的拆分操作,从第10行开始。
这里先说结论,在原Map中位于同一个桶的链表节点,在扩容后重新Hash后,必然位于两个桶之中(也有可能还在一个桶),且这两个桶位置相差oldCap。较小的那个桶位于原位置。
初始化的两个链表loHead和hiHead分别代表保持原位置的节点组成的链表和迁移到新位置的节点组成的链表。接着遍历原链表上的所有节点,将节点分配到两条链表上。第6行的if中条件,(e.hash & oldCap)即可判断出那个关键的二进制位上是否为0,为0的节点放入原位链表loHead,否则放入新链表hiHead。最后将这两条链表放到新table的对应位置即可。
[
](https://blog.csdn.net/qq_40856284/article/details/106567935)
红黑树退化成链表
在代码中有一个常量为UNTREEIFY_THRESHOLD:
static final int UNTREEIFY_THRESHOLD = 6;
这个常量仅仅会在split()方法中使用,用于分裂红黑树并重新计算Hash,split()也只会在resize()中调用,即只有在扩容时,对红黑树进行分裂,如果树的大小不足6,就会退化为链表。
if (loHead != null) {if (lc <= UNTREEIFY_THRESHOLD)tab[index] = loHead.untreeify(map);else {tab[index] = loHead;if (hiHead != null) // (else is already treeified)loHead.treeify(tab);}}if (hiHead != null) {if (hc <= UNTREEIFY_THRESHOLD)tab[index + bit] = hiHead.untreeify(map);else {tab[index + bit] = hiHead;if (loHead != null)hiHead.treeify(tab);}}
注意到TREEIFY_THRESHOLD和UNTREEIFY_THRESHOLD的值并不相等,这主要是因为防止某个桶中的节点在这个值附近震荡,就会导致频繁的红黑树和链表的转化。
30.ConcurrentHashMap源码分析
ConcurrentHashMap 在 JDK 1.7 之前使用的是分段锁,将多个链表根结点化作一段,共用一把锁,如果两个线程同时操作不同段,就不会触发同步机制。
JDK 1.8 之后的 ConcurrentHashMap,跟随 HashMap 的进化,也采用了红黑树机制,同时,细化了锁的粒度,在每个根节点(无论是链表还是红黑树)上都加了锁,这样,只要多个线程之间操作的节点不发生哈希碰撞,就不会触发同步机制。
类签名与成员变量
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>implements ConcurrentMap<K,V>, Serializable
private static final int MAXIMUM_CAPACITY = 1 << 30;private static final int DEFAULT_CAPACITY = 16;static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;private static final int DEFAULT_CONCURRENCY_LEVEL = 16;private static final float LOAD_FACTOR = 0.75f;static final int TREEIFY_THRESHOLD = 8;static final int UNTREEIFY_THRESHOLD = 6;static final int MIN_TREEIFY_CAPACITY = 64;private static final int MIN_TRANSFER_STRIDE = 16;private static int RESIZE_STAMP_BITS = 16;private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1;private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS;static final int MOVED = -1; // hash for forwarding nodesstatic final int TREEBIN = -2; // hash for roots of treesstatic final int RESERVED = -3; // hash for transient reservationsstatic final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash
内部存储结构
和 JDK 1.8 的 HashMap 类似,ConcurrentHashMap 的内部节点也分别分为链表节点(Node<K,V>)和红黑树节点(TreeNode<K,V>),其中 TreeNode<K, V> 继承了 Node<K, V>。
哈希桶的实现是 transient volatile Node<K, V>[] table,相比于 HashMap 的实现增加了 volatile关键字,以保证 table在多线程情况下的可见性。还有一个哈希桶的引用:private transient volatile Node<K,V>[] nextTable,nextTable会在扩容的时候使用。
还有一个比较关键的属性,private transient volatile int sizeCtl,该属性用于指示 table 数组的初始化状态和扩容大小。当该属性为负数时,table 数组正在被初始化或扩容:-1 时为初始化,-(1+n) 时表示正在有 n 个线程参与扩容。当 table 为 null 时,该属性保存 table 的初始化大小,若是未来会初始化为默认大小(16),则该属性为 0。初始化后,该属性保存了下次扩容需要扩容到的 table 大小,这时这个变量的作用就类似于 HashMap 中的 threshold 的作用。
put()方法
和 HashMap 类似,put()也是一个包装方法,具体的实现都在 putVal() 中。
public V put(K key, V value) {return putVal(key, value, false);}
putVal()方法和 HashMap 中同名方法流程类似,只不过增加了一些小细节以保证线程安全。
if (key == null || value == null) throw new NullPointerException();
这行说明它与HashMap 的一点不同。
ConCurrentHashMap key 和 value 都不可以是null,而 HashMap 则无此限制
putVal方法
1.如果tab == null,则要进行table的初始化
2.获取对应下标节点,如果tab[i] == null,使用CAS直接插入
3.如果 hash 冲突了,且 hash 值为 MOVED,说明是 ForwardingNode 对象 ,表明 table 正在扩容,当前线程参与帮助扩容
4.如果 hash 冲突了,且 hash 值不为 -1
- 获取 f 节点(根结点)的锁(synchronized),防止增加链表的时候导致链表成环
- f是链表类型,死循环,如果key存在就覆盖,不存在直到将值添加到链表尾部,并计算链表的长度
- f是树的话,调用对应方法插入到树中,链表长度大于等于 8 时,将该节点改成红黑树
putVal()简要流程如下:
final V putVal(K key, V value, boolean onlyIfAbsent) {if (key == null || value == null) throw new NullPointerException();int hash = spread(key.hashCode());int binCount = 0;// 死循环执行,保证最后可以插入成功for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;if (tab == null || (n = tab.length) == 0)// table 需要初始化tab = initTable();// 获取对应下标节点,如果是空,直接插入else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {// CAS 进行插入if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))break; // no lock when adding to empty bin}// 如果 hash 冲突了,且 hash 值为 MOVED,说明是 ForwardingNode 对象//这是一个占位符对象,保存了扩容后的容器,table 正在扩容,当前线程参与帮助扩容else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);// 如果 hash 冲突了,且 hash 值不为 -1else {V oldVal = null;// 获取 f 节点(根结点)的锁,防止增加链表的时候导致链表成环synchronized (f) {// 如果对应的下标位置的节点没有改变if (tabAt(tab, i) == f) {// 并且 f 节点的 hash 值大于等于 0if (fh >= 0) {// 链表初始长度binCount = 1;// 死循环,直到将值添加到链表尾部,并计算链表的长度for (Node<K,V> e = f;; ++binCount) {K ek;if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}Node<K,V> pred = e;if ((e = e.next) == null) {pred.next = new Node<K,V>(hash, key,value, null);break;}}}// 如果 f 节点的 hash 小于 0 并且 f 是树类型else if (f instanceof TreeBin) {Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}// 链表长度大于等于 8 时,将该节点改成红黑树if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);if (oldVal != null)return oldVal;break;}}}// 判断是否需要扩容addCount(1L, binCount);return null;}
helpTransfer()
在put() 存入键值对的过程当中,如果遇到根节点的哈希值为 MOVED 时,说明当前的 map 正在扩容,这时当前线程就会主动调用 helpTransfer() 方法协助进行节点迁移。
实际上,当根结点的哈希为 MOVED 时,根结点的类型实际上是 ForwardingNode 类型,这个类型是 Node 类型的子类,它只在扩容时会被创建。helpTransfer() 的实现很短,如下:
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {Node<K,V>[] nextTab; int sc;// 如果 table 不是空,且 node 节点是转移类型,数据检验// 且 node 节点的 nextTable(新 table) 不是空,同样也是数据校验// 尝试帮助扩容if (tab != null && (f instanceof ForwardingNode) &&(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {// 根据 length 得到一个标识符号int rs = resizeStamp(tab.length);// 如果 nextTab 没有被并发修改 且 tab 也没有被并发修改// 且 sizeCtl < 0 (说明还在扩容)while (nextTab == nextTable && table == tab &&(sc = sizeCtl) < 0) {// 如果 sizeCtl 无符号右移 16 不等于 rs(sc 前 16 位如果不等于标识符,则标识符变化了)// 或者 sizeCtl == rs + 1 (扩容结束了,不再有线程进行扩容)// 或者 sizeCtl == rs + 65535(如果达到最大帮助线程的数量,即 65535)// 或者转移下标正在调整(扩容结束)// 结束循环,返回 tableif ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||sc == rs + MAX_RESIZERS || transferIndex <= 0)break;// 如果以上都不是, 将 sizeCtl + 1(表示增加了一个线程帮助其扩容)if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {// 进行转移transfer(tab, nextTab);// 结束循环break;}}return nextTab;}return table;}
代码用了大量的判断,来保证这个线程加入的时候扩容还没有结束,且帮助扩容的线程数量不超限。
在之前讲到 sizeCtl变量时提到过,当该变量为 -N 时,表示当前有 N-1 个线程正在进行扩容。其中,高 16 位是通过 table.length 生成的标识符,低 16 位就是正在参与扩容的线程数。
在第 19 行有一个判断,sizeCtl == rs + 1这个条件满足时,表示当前扩容已结束。
这其实是第一个发起扩容的线程开始扩容时,会将 sizeCtl 设置成 rs + 2,
每个线程协助扩容时,就会将 sizeCtl 加 1,结束扩容时就会将 sizeCtl减 1,而最初的发起线程在结束时也会将 sizeCtl减 1,这时,所有线程都完成了扩容,sizeCtl == rs + 1。
transfer()
transfer() 方法用于在 map 扩容时迁移节点,首先先对流程进行概述:
- 计算 CPU 核心数和桶个数得出每个线程要处理多少桶——stride,步长最小值为16
- 初始化 nextTable,长度为原来的两倍,在创建新数组时,会设置 transferIndex = n。
- 死循环for做了两件事,先是计算需要转移的节点,再是将每个节点的数据进行转移,根据 finishing 变量来判断转移是否结束
- 进入一个 while 循环,计算需要转移的节点,通过transferIndex 和 stride计算出bound,bound 变量,指的是当前线程此次循环可以处理的区间的最小下标,transferIndex会被CAS操作更新,如果并发扩容,别的线程进来了,会以新的transferIndex 来计算,需要转移哪些数据。按从大到小的顺序分配给线程 ,当拿到分配值后,进行 i — 递减。这个 i 就是数组下标。超过bound这个下标,就需要重新领取区间或者结束扩容。有一个 advance 变量,指的是是否继续递减以转移下一个桶,如果为 false,说明当前桶还没有处理完。
- 进入 if 判断,判断扩容是否结束,如果扩容结束,清空 nextTable,并更新 table,更新 sizeCtl,然后将旧数组检查一遍(即再次走一遍扩容代码)。如果没完成,但已经无法领取区间,该线程退出该方法,并将 sizeCtl 减一表示参与扩容的线程少一个。
- 如果没有完成任务,且 i 对应的桶为 null,尝试 CAS 插入占位符ForwardingNode对象 这样其他线程进行 put 时就可以感知到并参与到扩容中来
- 如果对应的桶不是空,有占位符,说明别的线程已经处理过了,当前线程跳过这个桶
- 如果以上都不是,说明桶不空,且不是占位符,说明这个桶尚未被处理,当前线程就会开始处理这个桶 synchronized(f),对头节点加锁,处理这个桶
- 在迁移桶的时候是对头节点上锁的,防止有其他线程插入数据,迁移过程与 HashMap 一致(resize 方法)
/*** The next table index (plus one) to split while resizing.*/private transient volatile int transferIndex;//当出现并发扩容时,这个全局变量,是用来给各个线程分配节点的。
例如,假设 table 总长度为 64,table 就会被拆分成四个区间,每个线程处理 16 个桶,如果只有 3 个线程正在参与转移,就会有一个区间空闲等待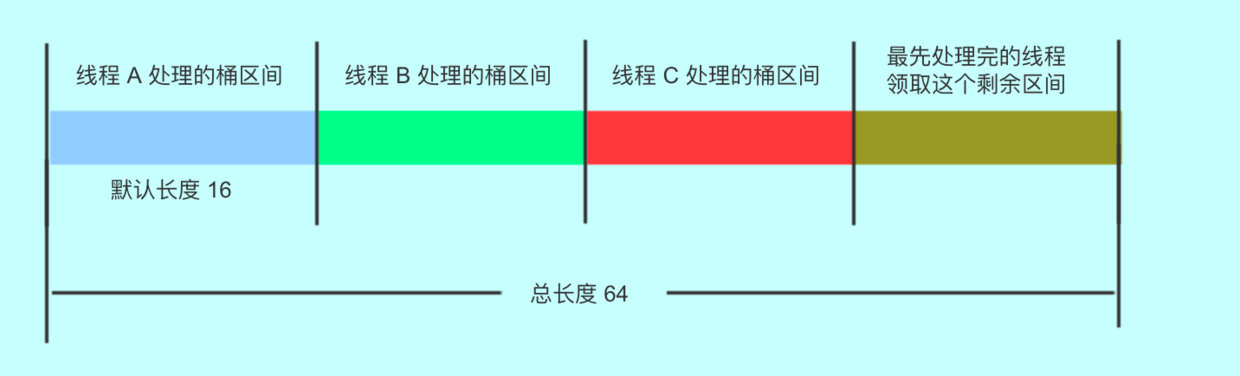
三个线程各自处理,互不影响。这就是 transfer() 方法最精华的部分。
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {int n = tab.length, stride;if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)stride = MIN_TRANSFER_STRIDE; // subdivide rangeif (nextTab == null) { // initiatingtry {@SuppressWarnings("unchecked")Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];nextTab = nt;} catch (Throwable ex) { // try to cope with OOMEsizeCtl = Integer.MAX_VALUE;return;}nextTable = nextTab;transferIndex = n;}int nextn = nextTab.length;ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);boolean advance = true;boolean finishing = false; // to ensure sweep before committing nextTabfor (int i = 0, bound = 0;;) {Node<K,V> f; int fh;while (advance) {int nextIndex, nextBound;if (--i >= bound || finishing)advance = false;else if ((nextIndex = transferIndex) <= 0) {i = -1;advance = false;}else if (U.compareAndSwapInt(this, TRANSFERINDEX, nextIndex,nextBound = (nextIndex > stride ?nextIndex - stride : 0))) {bound = nextBound;i = nextIndex - 1;advance = false;}}if (i < 0 || i >= n || i + n >= nextn) {int sc;if (finishing) {nextTable = null;table = nextTab;sizeCtl = (n << 1) - (n >>> 1);return;}if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)return;finishing = advance = true;i = n; // recheck before commit}}else if ((f = tabAt(tab, i)) == null)advance = casTabAt(tab, i, null, fwd);else if ((fh = f.hash) == MOVED)advance = true; // already processedelse {synchronized (f) {if (tabAt(tab, i) == f) {Node<K,V> ln, hn;if (fh >= 0) {int runBit = fh & n;Node<K,V> lastRun = f;for (Node<K,V> p = f.next; p != null; p = p.next) {int b = p.hash & n;if (b != runBit) {runBit = b;lastRun = p;}}if (runBit == 0) {ln = lastRun;hn = null;}else {hn = lastRun;ln = null;}for (Node<K,V> p = f; p != lastRun; p = p.next) {int ph = p.hash; K pk = p.key; V pv = p.val;if ((ph & n) == 0)ln = new Node<K,V>(ph, pk, pv, ln);elsehn = new Node<K,V>(ph, pk, pv, hn);}setTabAt(nextTab, i, ln);setTabAt(nextTab, i + n, hn);setTabAt(tab, i, fwd);advance = true;}else if (f instanceof TreeBin) {TreeBin<K,V> t = (TreeBin<K,V>)f;TreeNode<K,V> lo = null, loTail = null;TreeNode<K,V> hi = null, hiTail = null;int lc = 0, hc = 0;for (Node<K,V> e = t.first; e != null; e = e.next) {int h = e.hash;TreeNode<K,V> p = new TreeNode<K,V>(h, e.key, e.val, null, null);if ((h & n) == 0) {if ((p.prev = loTail) == null)lo = p;elseloTail.next = p;loTail = p;++lc;}else {if ((p.prev = hiTail) == null)hi = p;elsehiTail.next = p;hiTail = p;++hc;}}ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :(hc != 0) ? new TreeBin<K,V>(lo) : t;hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :(lc != 0) ? new TreeBin<K,V>(hi) : t;setTabAt(nextTab, i, ln);setTabAt(nextTab, i + n, hn);setTabAt(tab, i, fwd);advance = true;}}}}}}
sizeCtl这个参数有以下几种状态:
- 在执行数组初始化时,会设置为-1,
- 初始化完成时,会设置为扩容阈值,
- 扩容时,会是负数,并会记录有几个线程在扩容。

若有收获,就点个赞吧
0 人点赞
