极客时间
了解
- 稳定性。这个概念是说,如果待排序的序列中存在值相等的元素,经过排序之后,相等元素之间原有的先后顺序不变。
- 原地排序(Sorted in place)。原地排序算法,就是特指空间复杂度是 O(1) 的排序算法。(除了存储数据本身的空间不需要额外的辅助存储空间)
如何分析一个排序算法
排序算法的执行效率
- 最好情况、最坏情况、平均情况时间复杂度
- 时间复杂度的系数、常数 、低阶
-
排序算法的内存消耗
算法的内存消耗可以通过空间复杂度来衡量
- 针对排序算法的空间复杂度,我们还引入了一个新的概念,原地排序(Sorted in place)。
-
排序算法的稳定性
稳定性。这个概念是说,如果待排序的序列中存在值相等的元素,经过排序之后,相等元素之间原有的先后顺序不变
- 比如 2,3,1,0,3,经过大小排序后: 0,1,2,3,3
- 这组数据里有两个 3。经过某种排序算法排序之后,如果两个 3 的前后顺序没有改变,那我们就把这种排序算法叫作稳定的排序算法;如果前后顺序发生变化,那对应的排序算法就叫作不稳定的排序算法。
思考:
比如说,我们现在要给电商交易系统中的“订单”排序。订单有两个属性,一个是下单时间,另一个是订单金额。如果我们现在有 10 万条订单数据,我们希望按照金额从小到大对订单数据排序。对于金额相同的订单,我们希望按照下单时间从早到晚有序。对于这样一个排序需求,我们怎么来做呢?
算法稳定性的用处,多次排序中,下一次排序需要依赖上一次排序的稳定结果。比如订单排序中,先按时间排序,再按价格排序,最终要得到同个价格的订单按下单时间排序,就需要算法稳定性了

如何分析平均时间复杂
如果用概率论方法定量分析平均时间复杂度,涉及的数学推理和计算就会很复杂。还有一种思路,通过“有序度”和“逆序度”这两个概念来进行分析。
有序度
有序度是数组中具有有序关系的元素对的个数。有序元素对用数学表达式表示就是这样:
有序元素对:a[i] <= a[j], 如果i < j。

满序度
计算公式: n*(n-1)/2
- 对于一个倒序排列的数组,比如 6,5,4,3,2,1,有序度是 0;
对于一个完全有序的数组,比如 1,2,3,4,5,6,有序度就是 n(n-1)/2,也就是 15。我们把这种完全有序的数组的有序度叫*作满有序度。
关系
逆序度 = 满有序度 - 有序度
比较和交换。每交换一次,有序度就加 1。不管算法怎么改进,交换次数总是确定的,即为逆序度
-
冒泡排序(Bubble Sort)
实现原理
数组中有 n 个数,比较每相邻两个数,如果前者大于后者,就把两个数交换位置;这样一来,第一轮就可以选出一个最大的数放在最后面;那么经过 n-1(数组的 length - 1) 轮,就完成了所有数的排序。
实现步骤
- 首先我们先找出数组中最大的数,把它放在数组的最后面 ```javascript var arr = [3,4,1,2];
for(let i = 0; i < arr.length; i++) { if(arr[i] > arr[i+1]) { // 如果前者大于后者,就交换位置 let temp = arr[i] arr[i] = arr[i+1]; arr[i+1] = temp } }
// arr 为 [ 3, 1, 2, 4 ]
2. 然后,我们能找到数组中最大的数,放到最后,这样重复 arr.length - 1 次,便可以实现数组按从小到大的顺序排好了。```javascriptvar arr = [3,4,1,2];for(let j = 0; j < arr.length; j++) {//这里 i < arr.length - 1 ,要思考思考合适吗?for(let i = 0; i < arr.length; i++) {if(arr[i] > arr[i+1]) {let temp = arr[i]arr[i] = arr[i+1];arr[i+1] = temp}}}// arr 为 [ 1, 2, 3, 4 ]
性能优化
虽然上面的代码已经实现冒泡排序了,但就像注释中提到的,内层 for 循环的次数写成,i < arr.length - 1 ,是不是合适呢? 我们想一下,当第一次,找到最大数,放到最后,那么下一次,遍历的时候,是不是就不能把最后一个数算上了呢?因为他就是最大的了,不会出现,前一个数比后一个数大,要交换位置的情况,所以内层 for 循环的次数,改成 i < arr.length - 1 -j ,才合适,看下面的代码。
var arr = [3, 4, 1, 2];function bubbleSort (arr) {if (arr.length <= 1) returnfor (var j = 0; j < arr.length - 1; j++) {// 这里要根据外层for循环的 j,逐渐减少内层 for循环的次数for (var i = 0; i < arr.length - 1 - j; i++) {if (arr[i] > arr[i + 1]) {var temp = arr[i];arr[i] = arr[i + 1];arr[i + 1] = temp;}}}return arr;}bubbleSort(arr);
我们想下这个情况,当原数组是,
arr = [1,2,4,3];
在经过第一轮冒泡排序之后,数组就变成了
arr = [1,2,3,4];
此时,数组已经排序完成了,但是按上面的代码来看,数组还会继续排序,所以我们加一个标志位,如果某次循环完后,没有任何两数进行交换,就将标志位 设置为 true,表示排序完成,这样我们就可以减少不必要的排序,提高性能。 ```javascript var arr = [3, 4, 1, 2]; function bubbleSort (arr) { if (arr.length <= 1) return for (var j = 0; j < arr.length - 1; j++) { var flag = false // 这里要根据外层for循环的 j,逐渐减少内层 for循环的次数 for (var i = 0; i < arr.length - 1 - j; i++) {if (arr[i] > arr[i + 1]) { //交换var temp = arr[i];arr[i] = arr[i + 1];arr[i + 1] = temp;flag = true // 表示有数据交换}
} if(!flag) { // 如果没有数据交换,提前退出
break
} } return arr; }
console.log(‘arr—‘, bubbleSort(arr));
<a name="IctnN"></a>#### 复杂度分析- **时间复杂度:**平均时间复杂度O(n*n) 、最好情况O(n)、最差情况O(n*n)- **空间复杂度:** O(1)- **稳定性:**稳定的排序算法<a name="Eb4BW"></a>#### 总结1. 外层 for 循环控制循环次数1. 内层 for 循环进行两数交换,找每次的最大数,排到最后1. 设置一个标志位,减少不必要的循环<a name="VDNHf"></a>### 插入排序[参考](https://www.cnblogs.com/echolun/p/12644008.html)<a name="k87mg"></a>#### 实现原理- 首先,我们将数组中的数据分为两个区间,**已排序区间**和**未排序区间**。初始已排序区间只有一个元素,就是数组的第一个元素。插入算法的核心思想是取未排序区间中的元素,在已排序区间中找到合适的插入位置将其插入,并保证已排序区间数据一直有序。重复这个过程,直到未排序区间中元素为空,算法结束- 插入排序也包含两种操作,- 一种是**元素的比较**,- 一种是**元素的移动**。- 当我们需要将一个数据 a 插入到已排序区间时,需要拿 a 与已排序区间的元素依次比较大小,找到合适的插入位置。找到插入点之后,我们还需要将插入点之后的元素顺序往后移动一位,这样才能腾出位置给元素 a 插入。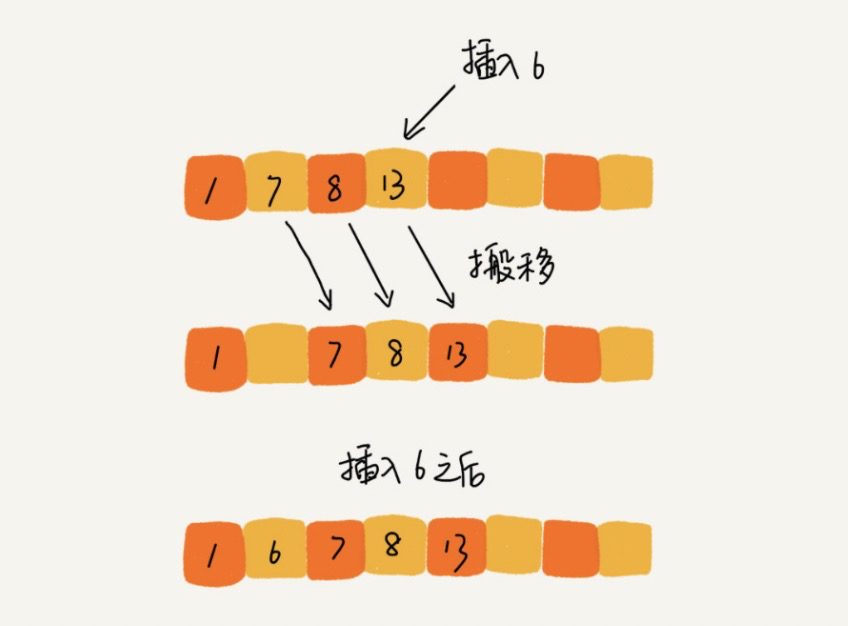<a name="hY92L"></a>#### 代码实现- 注意 往左边数组插入元素时的条件 while (**j >= 0 && arr[j] > value**) 千万不要自然的**漏掉第一个元素**```javascriptconst insert = (arr = []) => {const len = arr.lengthif (len <= 1) return;// 遍历右边未排序区间的元素,一定注意是从1开始for(let i = 1; i < len; i++) {// 先拿出要插入的值let value = arr[i]// 在确定 左边 已经排序好的区间大小,就是 i 的前一位 即 i-1let j = i -1// 每次从右边未排序的数组中拿出一个元素,放到左边有序的数组中,那到底放哪里呢// 我们就要和左边有序的数组中的元素做一个大小比较,来找出要放的位置// 怎么比较呢?// 从 i 前面的位置即 j 也就是左边有序数组的最后一个元素 往前 依次比较// 并完成数据移动,如果 arr[j] > vaule , value 往前移, arr[j] 往后走// 此时要完成两个目标// ① 找出要插入元素的位置 ②并且给要插入元素腾出位置,即数据移动while (j >= 0 && arr[j] > value) {arr[j + 1] = arr[j] // 只要条件满足arr[j]的值就往后挪一位j--}//最后插入数据//我们要插入的位置是移过去元素arr[j]的位置//而while 循环完是 j-1 所以 要把 减去的 1 加上arr[j + 1] = value}return arr}
复杂度分析
- 时间复杂度:平均时间复杂度O(nn) 、最好情况O(n)、最差情况O(nn)
- 空间复杂度: O(1)
- 稳定性:稳定的排序算法 和 冒泡排序几乎一样
- 优势:从代码实现上来看,冒泡排序的数据交换要比插入排序的数据移动要复杂,冒泡排序需要 3 个赋值操作,而插入排序只需要 1 个

总结
- 分成两个区间,已排序区间和未排序区间
遍历未排序区间的元素,将取出的元素,插入到左边已排序区间
算法的实现思路有点类似插入排序,也分已排序区间和未排序区间。但是选择排序每次会从未排序区间中找到最小的元素,将其放到已排序区间的末尾。
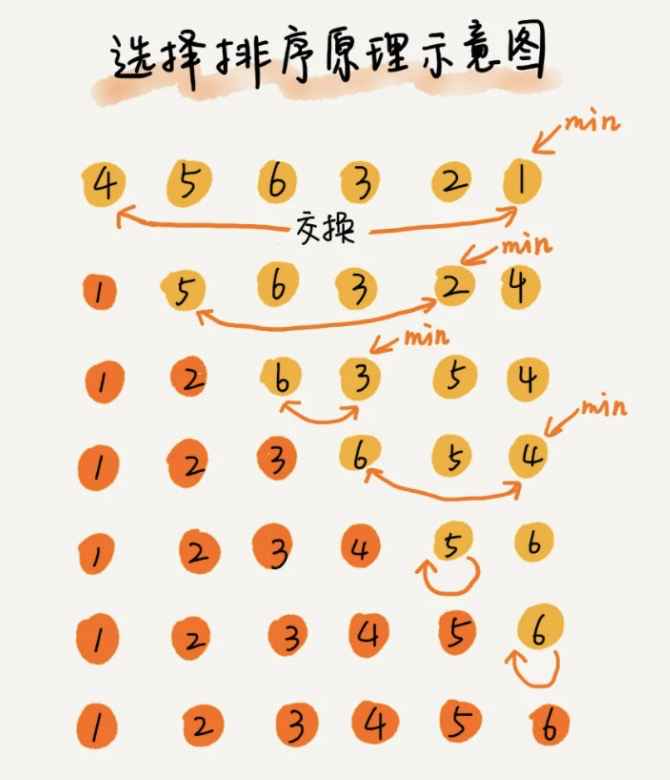
复杂度分析
选择排序空间复杂度为 O(1)
- 选择排序的最好情况时间复杂度、最坏情况和平均情况时间复杂度都为 O(n2)
-
注意
选择排序是一种不稳定的排序算法。从图中,你可以看出来,选择排序每次都要找剩余未排序元素中的最小值,并和前面的元素交换位置,这样破坏了稳定性
- 比如 5,8,5,2,9 这样一组数据,使用选择排序算法来排序的话,第一次找到最小元素 2,与第一个 5 交换位置,那第一个 5 和中间的 5 顺序就变了,所以就不稳定了。正是因此,相对于冒泡排序和插入排序,选择排序就稍微逊色了。
对于小规模数据的排序,用起来非常高效。但是在大规模数据排序的时候,这个时间复杂还是稍微有点高,所以我们更倾向于时间复杂度为 O(nlogn) 的排序算法。
归并排序
参考segmentfault
参考segmentfault-2
参考即可时间
介绍
- 归并排序使用的就是分治思想,分治,顾名思义,就是分而治之,将一个大问题分解成小的子问题来解决。小的子问题解决了,大问题也就解决了。
分治算法一般都是用递归来实现的。分治是一种解决问题的处理思想,递归是一种编程技巧
实现原理

如图所示,我们申请一个临时数组 tmp,大小与 A[p…r]相同。我们用两个游标 i 和 j,分别指向 A[p…q]和 A[q+1…r]的第一个元素。比较这两个元素 A[i]和 A[j],如果 A[i]<=A[j],我们就把 A[i]放入到临时数组 tmp,并且 i 后移一位,否则将 A[j]放入到数组 tmp,j 后移一位
代码实现
分解成小数组时,临界条件一定注意 是 if(arr.length === 1) return arr ```javascript
const arr = [5, 1, 6, 2, 3, 4] const sortArr = (arr) => { //mergeSortRec:首先将大数组分解成小数组,即每个数组元素为1,这样小数组就是有序的 return mergeSortRec(arr) }
const mergeSortRec = (arr) => { //使用递归思想 //1找到通项公式 2确认临界值 let length = arr.length if (length === 1) { //临界值 return arr } let mid = Math.floor(length / 2) let left = arr.slice(0, mid) let right = arr.slice(mid, length) //使用递推 return merge(mergeSortRec(left), mergeSortRec(right)) }
/**
- @param {*} left 有序数组
- @param {*} right 有序数组
@returns */ const merge = (left = [], right = []) => { const result = [] let il = 0 // 表示左边数组第0位 let ir = 0 // 表示右边数组的第0位 while (il < left.length && ir < right.length) { //从左右两数组中取出元素,依次比较,谁小 //小的放入 result[] if (left[il] < right[ir]) { result.push(left[il++]); } else { result.push(right[ir++]); } } //比较完后,把依然还有元素的数组中的值 //依次放入 临时数组result while (il < left.length) { result.push(left[il++]); }
while (ir < right.length) { result.push(right[ir++]); } return result } ```
复杂度分析
- 时间复杂度:平均时间复杂度O(nlogn) 、最好情况O(nlogn)、最差情况O(nlogn)
- 空间复杂度: O(n)
- 稳定性:稳定的排序算法
快速排序
参考segmentfault-1
参考segmentfault-2
实现原理
- 先从数组中取出第一个数作为基准数
- 遍历比较,比基准数小的放左边,比基准数大的放右边
- 再对左右区间重复第二部,直到区间内只剩一个元素
- 再将左右区间数组合并

代码实现
const arr = [34, 2, 65, 23, 1, 6, 3, 15]const sort = (arr) => {const baseNum = arr[0]let leftArr = []let rightArr = []for(let i = 1; i < arr.length; i++){if(arr[i] > baseNum) {rightArr.push(arr[i])} else {leftArr.push(arr[i])}}// 判断是否排序的条件 左右数组的元素个数大于2个if(leftArr.length >= 2) leftArr = sort(leftArr)if(rightArr.length >= 2) rightArr = sort(rightArr)return leftArr.concat(baseNum, rightArr)}console.log('sort', sort(arr))
复杂度分析
- 可根据递推公式,但是复杂的数据划分,比如快排是1分为2,如果1分为X,这种情况就需要 递归树来求解时间复杂度了
- 时间复杂度:
- 平均时间复杂度O(nlogn)
- 最好情况O(nlogn)
- 最差情况O(n2) — 当要排序的数据是有序的,并且每次取的分区值是 最后一个元素,这样的话每次都会 遍历 一遍 大约n 个数据,即 n 的平方
- 空间复杂度:O(nlogn)
-
排序优化
各种排序算法时间复杂度分析
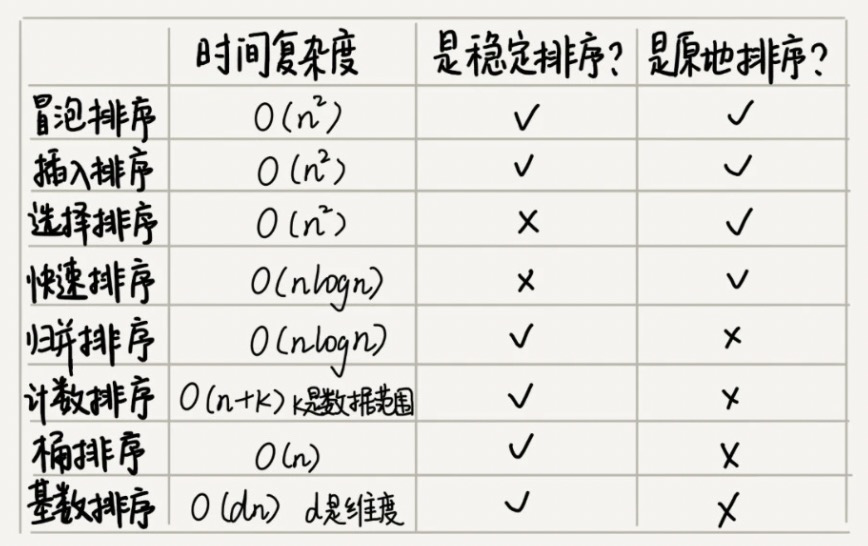
线性排序算法的时间复杂度比较低,适用场景比较特殊,是基于非比较的算法。所以如果要写一个通用的排序函数,不能选择线性排序算法
- 如果对小规模数据进行排序,可以选择时间复杂度是 O(n2) 的算法
如果对大规模数据进行排序,时间复杂度是 O(nlogn) 的算法更加高效。 了兼顾任意规模数据的排序,一般都会首选时间复杂度是 O(nlogn) 的排序算法来实现排序函数
如何优化快速排序?
—如果数据原来就是有序的或者接近有序的,每次分区点都选择最后一个数据,那快速排序算法就会变得非常糟糕,时间复杂度就会退化为 O(n2)。实际上,这种 O(n2) 时间复杂度出现的主要原因还是因为我们分区点选得不够合理
最理想的分区点是:被分区点分开的两个分区中,数据的数量差不多
三数取中法
- 从区间的首、尾、中间,分别取出一个数,然后对比大小,取这 3 个数的中间值作为分区点。
- 但是,**如果要排序的数组比较大,那“三数取中”可能就不够了,可能要“五数取中”或者“十数取中”
随机法
- 随机法就是每次从要排序的区间中,随机选择一个元素作为分区点
总结
- 要根据数据规模大小,分别选择对应的排序算法
- 对于小规模数据的排序,O(n2) 的排序算法并不一定比 O(nlogn) 排序算法执行的时间长。对于小数据量的排序,我们选择比较简单、不需要递归的插入排序算法。

若有收获,就点个赞吧
0 人点赞
