了解
- 桶排序、计数排序、基数排序,三种时间复杂度是 O(n) ,这些排序算法的时间复杂度是线性的,我们把这类排序算法叫作线性排序
- 之所以能做到线性的时间复杂度,主要原因是,这三个算法是非基于比较的排序算法,都不涉及元素之间的比较操作。
桶排序(Bucket sort)
实现原理
- 核心思想是将要排序的数据分到几个有序的桶里,每个桶里的数据再单独进行排序。桶内排完序之后,再把每个桶里的数据按照顺序依次取出,组成的序列就是有序的了。

业务场景
—比如说我们有 10GB 的订单数据,我们希望按订单金额(假设金额都是正整数)进行排序,但是我们的内存有限,只有几百 MB,没办法一次性把 10GB 的数据都加载到内存中。这个时候该怎么办呢?
理想情况
- 如果订单金额在 1 到 10 万之间均匀分布,那订单会被均匀划分到 100 个文件中,每个小文件中存储大约 100MB 的订单数据
- 我们就可以将这 100 个小文件依次放到内存中,用快排来排序。
- 等所有文件都排好序之后,我们只需要按照文件编号,从小到大依次读取每个小文件中的订单数据,并将其写入到一个文件中,那这个文件中存储的就是按照金额从小到大排序的订单数据了
非理想情况
—订单按照金额在 1 元到 10 万元之间并不一定是均匀分布的 ,所以 10GB 订单数据是无法均匀地被划分到 100 个文件中的。有可能某个金额区间的数据特别多,划分之后对应的文件就会很大,没法一次性读入内存。这又该怎么办呢?
- 这些划分之后还是比较大的文件,我们可以继续划分,比如,订单金额在 1 元到 1000 元之间的比较多,我们就将这个区间继续划分为 10 个小区间,1 元到 100 元,101 元到 200 元,201 元到 300 元….901 元到 1000 元。
- 如果划分之后,101 元到 200 元之间的订单还是太多,无法一次性读入内存,那就继续再划分,直到所有的文件都能读入内存为止
计数排序
- 计数排序其实是桶排序的一种特殊情况
-
实现原理
利用数组的index是天然有序的特征来排序.
-
业务场景
—如果你所在的省有 50 万考生,如何通过成绩快速排序得出名次呢?
考生的满分是 900 分,最小是 0 分,这个数据的范围很小,所以我们可以分成 901 个桶,对应分数从 0 分到 900 分。
- 根据考生的成绩,我们将这 50 万考生划分到这 901 个桶里。
桶内的数据都是分数相同的考生,所以并不需要再进行排序。我们只需要依次扫描每个桶,将桶内的考生依次输出到一个数组中,就实现了 50 万考生的排序。因为只涉及扫描遍历操作,所以时间复杂度是 O(n)。
实现步骤
用要排序的数据(范围不大),我们只需要遍历一遍数组,点出每个值出现的次数,并用一个新数组newAry 来存储这个次数
- 比如考生分数范围 成绩从 0 到 5 分
- 8个考生的分数:2,5,3,0,2,3,0,3,当做数组下标索引
比如数组C[6]内存储的并不是考生,而是对应的考生个数
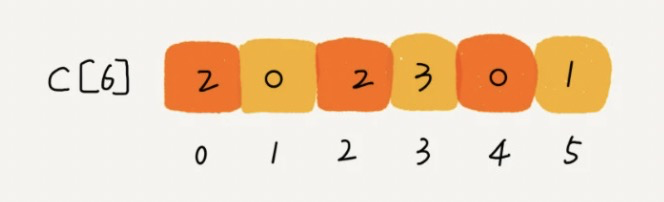
每个元素的值(即newAry 的索引)根据出现的次数依次放入空数组中即可
代码实现
let ary = [2, 5, 3, 0, 2, 3, 0, 3]function countSort(ary) {// 首先定义一个和传入数组长度相等并且值为0的数组,初始每个元素出现了0次let newAry = new Array(ary.length).fill(0);// 遍历数组,将值作为新数组newAry的索引.并且计数该值出现的次数,写入newAryfor (const value of ary) {// 在当前元素值的基础上加 1 (初始化时,元素值为 0)newAry[value]++ // 即 newAry[value] = newAry[value] + 1;}ary = [];// 给ary重新赋值for (let i = 0; i < newAry.length; i++) {// 循环数字次数// 由于newAry中存的就是原来数组arr值(按照索引,即有序)出现的次数// 所以只需要把每个元素的值(即newAry 的索引)根据出现的次数依次放入空数组中即可for (let k = newAry[i]; k > 0; k--) {ary.push(i);}}newAry = null;return ary;}console.log('---', countSort(ary));
复杂度分析
桶排序或者计数排序,它们的时间复杂度可以做到 O(n)。如果要排序的数据有 k 位,那我们就需要 k 次桶排序或者计数排序,总的时间复杂度是 O(k*n)。当 k 不大的时候,基数排序的时间复杂度就近似于 O(n)。
总结(缺点)
计数排序只能用在数据范围不大的场景中,如果数据范围 k 比要排序的数据 n 大很多,就不适合用计数排序了。
计数排序只能给非负整数排序,如果要排序的数据是其他类型的,要将其在不改变相对大小的情况下,转化为非负整数。
基数排序(Radix sort)
实现原理
基数排序要求数据可以划分成高低位,位之间有递进关系。比较两个数,我们只需要比较高位,高位相同的再比较低位。而且每一位的数据范围不能太大,因为基数排序算法需要借助桶排序或者计数排序来完成每一个位的排序工作
从左到右按位排序, 先排个位, 再排十位,百位… 需要用到计数排序的方法-使用数组计数
代码实现
-
复杂度分析
时间复杂度就近似于 O(n)。
作业
—假设我们现在需要对 D,a,F,B,c,A,z 这个字符串进行排序,要求将其中所有小写字母都排在大写字母的前面,但小写字母内部和大写字母内部不要求有序。比如经过排序之后为 a,c,z,D,F,B,A,这个如何来实现呢?如果字符串中存储的不仅有大小写字母,还有数字。要将小写字母的放到前面,大写字母放在最后,数字放在中间,不用排序算法,又该怎么解决呢?
- 利用桶排序思想,弄小写,大写,数字三个桶,遍历一遍,都放进去,然后再从桶中取出来就行了。相当于遍历了两遍,复杂度O(n)

若有收获,就点个赞吧
0 人点赞
