主要引自:https://zhuanlan.zhihu.com/p/68247149 做部分改动
Embedding is all you need
允许我做一次标题党,Embedding 必须是深度学习中的“基本操作”。不论是 NLP(Nature Language Processing,自然语言处理),搜索排序,还是推荐系统,或者CTR(Click-Through-Rate,点击通过率)模型,Embedding 都扮演着不可或缺的角色。
什么是 Embedding?
Embedding 在数学上表示一个映射关系,  , 也就是一个函数。函数具有两个性质:injective 和 structure-preserving。
, 也就是一个函数。函数具有两个性质:injective 和 structure-preserving。
- Injective,即我们所说的单射函数,对于每个 Y 只有唯一的 X 对应,反之亦然;
- structure-preserving,结构保存,比如在 X 所属的空间上 X1 < X2,那么映射后在 Y 所属空间上 Y1 < Y2。
简单点说,深度学习中,Embedding 特指用一个低维度向量表示一个实体,可以是一个词(Word2Vec),可以是一个物品(Item2Vec),亦或者网络关系中的节点(Graph Embedding)。
Embedding 所获得的低维度向量具有一些特殊的性质。如下图,我们使用 Word2Vec 将单词映射(word embedding)到新的向量空间,获得单词的新的表达(word representation)。
我们能从图中很容易得出:Embedding(Moscow) - Embedding(Russia) ≈ Embedding(Tokyo) - Embedding(Japan),说明 Embedding 之后向量可以进行计算。并且,Embedding 之后,距离相近的向量对应的实体有相近的含义,比如 Embedding (Russia) 和 Embedding (Japan) 之间的距离就会很接近,但 Embedding (Russia) 和 Embedding (Tokyo) 的距离就会远一些。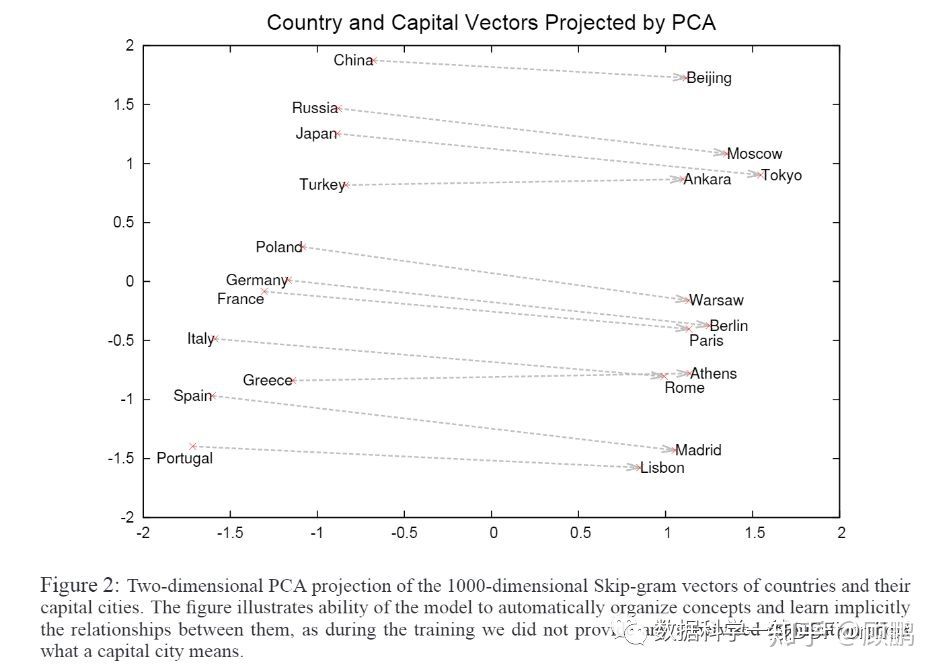
Embedding可以得到向量更低维度的表达,并且能保持实体内部的关系。
Embedding主要应用于三个方向:
- 在深度学习网络中使用 Embedding 层,将高维稀疏特征向量转换成低维稠密特征向量,从而减少后续模型参数量,后续模型可以是深度学习模型,或者传统的机器学习模型;
- 作为预训练技术,直接使用别人训练好的 Embedding 向量,与其他特征向量一同输入后续模型进行训练,例如 Word2Vec;
- 通过计算用户和物品的 Embedding 相似度,Embedding 可以直接作为推荐系统或计算广告系统的召回层或者召回方法之一,例如 Youtube 推荐系统。
什么是Graph Embedding
Graph Embedding 用低维、稠密、实值的向量表示网络中的节点。目前,Graph Embedding 已经是推荐系统、计算广告领域非常流行的做法,并且在实践后取得了非常不错的线上效果。
为什么能有这样的效果呢?
我们很容易理解,Word2Vec 通过序列(sequence)式的样本:句子,学习单词的真实含义。仿照 Word2Vec 思想而生的 Item2Vec 也通过商品的组合去生成商品的 Embedding,这里商品的组合也是序列式的,我们可以称他们为“Sequence Embedding”。然而,在更多场景下,数据对象之间更多以图/网络的结构呈现。例如下图,由淘宝用户行为数据生成的物品关系图(Item Graph):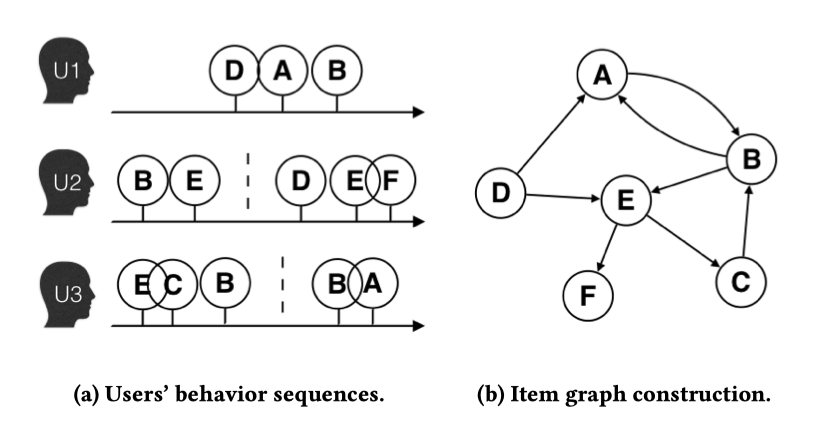
从上图的例子中,我们已经能触碰到一些 Graph Embedding 的本质。Graph Embedding 之所以能好于 “Sequence Embedding”,是因为 Graph Embedding 能够生成一些“不存在”的序列。例如,上图数据中没有这样的用户行为数据:B-E-F、D-E-C 等等。但是在物品关系图中,我们有机会生成这样的序列。
Embedding 流行起点:Word2Vec
**
Google 的 Tomas Mikolov 在 2013 年的两篇论文标志着 Word2Vec 的诞生,论文提出了 CBOW 和 Skip-gram 两种 Word2Vec 模型结构。下图是两种模型结构的架构图:
CBOW 使用目标词周边的词来预测目标词,Skip-gram 使用目标词预测周边的词。两种架构差别不大,我们在 Embedding 中更多使用Skip-gram。图中输入输出均使用词向量,词向量初始随机赋值,随着预测任务的进行,词向量在迭代中慢慢优化,使得预测任务指标越来越好,而我们最终需要的是训练好的词向量。两种模型的训练数据均使用标准的自然语言语料,利用词与词的关系(也就是语料序列)去训练词向量。
也就是说,只要我们找到词与词之间的关联关系,就能通过 Skip-gram 方法训练词的向量。
Word2Vec 有很多技术细节,例如使用 Hierarchical Softmax(层序 Softmax) 和 Negative Sampling 来减少由于词汇空间过大带来的计算量,例如优化目标的设置等等等等
Graph Embedding 早期技术:DeepWalk
**
Word2Vec 诞生之后,Embedding 的思想迅速从 NLP 领域扩散到几乎所有的机器学习领域。我们可以对语料序列中的词进行 Embedding,那么自然用户购买序列中的商品,或者用户观看序列中的电影,都可以进行 Embedding。这就是 Item2Vec。
回顾上一节的重点:是词与词的关联关系实现了 Embedding 的过程。序列(sequence)是一种“一维”的关系,而图(graph)是一种“二维”的关系,同样可以进行 Embedding。然而,我们目前能进行 Embedding 的 “工具” 只有 Skip-gram,只能处理序列这样一维的关系输入。因此,我们需要在二维关系上进行 “采样”,采样的过程可以使用随机游走算法。
DeepWalk 就是 Random Walk 与 Skip-gram 的组合。上图是 DeepWalk 算法伪代码,核心步骤 6 和 7 就是 Random Walk 与 Skip-gram。下图是算法流程示意:
Random Walk 负责对图进行采样,获得图中节点与节点的共现关系,Skip-gram 从关系(也就是采样的序列)中训练节点的 Embedding 向量。
上述结果中,比较临近的节点再 Embedding 空间更为接近,且结构更为相似的节点,距离也更近。这就是网络节点的同质性(homophily)和结构性(structural equivalence),进一步的说明会在下一小节。
所以,DeepWalk 以 Random Walk 的方式从网络中生成序列,进而转换成传统 word2vec 的方法生成 Embedding 向量。该算法可以视为 Graph Embedding 的 baseline 方法,用极小的代价完成从 word2vec 到 graph embedding 的转换和工程尝试。
DeepWalk 的改进:从 LINE 到 Node2Vec
**
DeepWalk 之后,比较重要的工作是微软亚洲研究院在 2015 年发布的 LINE(Large-scale Information Network Embedding)。阅读到这里,我们已经可以知晓,在网络上 “相似” 的节点,最终会拥有相似的 Embedding 向量。在 LINE 的论文中,定义了两种相似:
First-order proximity(1 阶相似度):用于描述图中成对顶点之间的局部相似度,形式化描述为若节点之间存在直连边,则边的权重即为两个顶点的相似度,若不存在直连边,则 1 阶相似度为0。 如下图,节点 6 和 7 之间存在直连边,且边权较大,则认为两者相似且 1 阶相似度较高,而 5 和 6 之间不存在直连边,则两者间 1 阶相似度为 0。也就是我们上一小节所说的同质性相似。
Second-order proximity(2 阶相似度):仅有1阶相似度就够了吗?显然不够,如下图,虽然节点 5 和 6 之间不存在直连边,但是他们有很多相同的相邻节点 (1,2,3,4),这其实也可以表明5和6是相似的,而 2 阶相似度就是用来描述这种关系的。 形式化定义为,令表示顶点 u 与所有其他顶点间的1阶相似度,则 u 与 v 的2阶相似度可以通过  和
和  的相似度表示。若
的相似度表示。若 u 与 v 之间不存在相同的邻居顶点,则2阶相似度为0。也就是我们上一小节所说的结构性相似。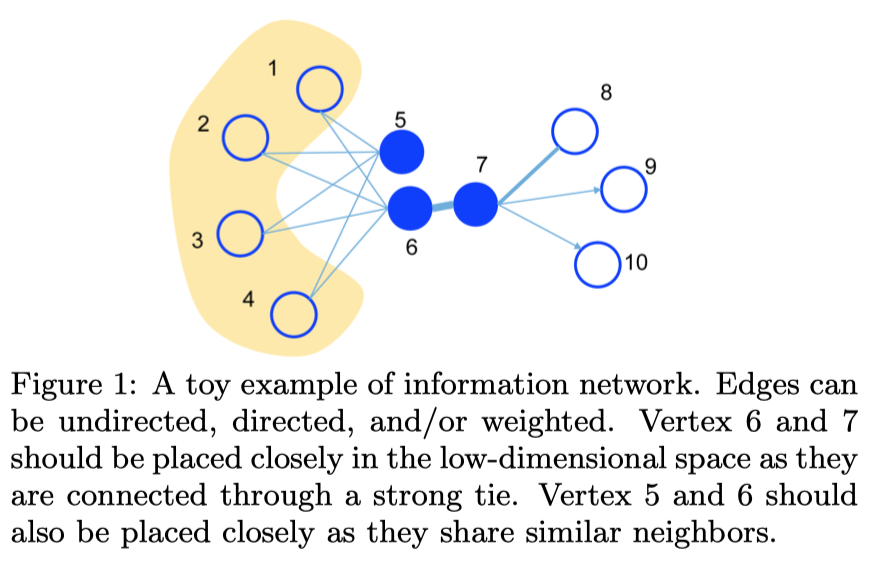
相比 DeepWalk 纯粹随机游走的序列生成方式,LINE 可以应用于有向图、无向图以及边有权重的网络,并通过将一阶、二阶的邻近关系引入目标函数,能够使最终学出的 node embedding 的分布更为均衡平滑,避免 DeepWalk 容易使 node embedding 聚集的情况发生。下图是论文中的结果对比:
从图中可以看出,LINE 的效果最好,DeepWalk 对不同颜色的点分得也不错,但是图形中部很多点都挤在一块,而这些点都是出度很大的点,文章提了一句说对于这种点的处理 DeepWalk 会产生很大噪音,但没有详细对此分析。论文还指出,DeepWalk 利用随机游走去捕获邻近关系,更像是深度优先搜索;而LINE的方式更像是广度优先搜索,相对而言更合理。上图中的 GF 代表 graph factorization,本文不作介绍,感兴趣的话可以自行 Google。
在 DeepWalk 和 LINE 的基础之上,斯坦福大学在 2016 年发布了 Node2Vec。算法不但关注了同质性和结构性的相似,更可以在两者之间进行权衡。如何做到的呢?让我们先来回顾,什么是深度优先(DFS),什么是广度优先(BFS)。
那么,节点 u 与其相连的节点 s1、s2、s3、s4 的 embedding 表达应该是接近的,这是同质性相似。节点 u 和节点 s 都是各自局域网络的中心节点,结构上相似,其 embedding 的表达也应该近似,这是结构性相似。
如果我们在随机游走的过程中以 BFS 为主,例如获得序列 ,训练出来u-s-s-s的 Embedding 向量更多反映了结构性的相似;如果随机游走以 DFS 为主,例如获得序列 ,则训练出来u-s-s-s 的Embedding 向量,更多反应同质性的相似。至于为什么,大家可以先自己思考。
那 Node2Vec 是如何权衡同质性和结构性相似的呢?换句话说,Node2Vec 如何参数化控制随机游走是更倾向 BFS 还是 DFS 呢?下图足以说明:
上图是 Node2Vec 算法中 Random Walk 的说明,假设我们随机游走到了节点 V,下一步有不同的概率到达临近的节点。假设节点 t 是访问节点 V 之前的节点,设置参数 p 为 “返回参数”(return parameter),控制节点 V 返回到节点 t 的概率,p 越大,从节点 V 返回节点 t 的概率越小。设置参数 q 为 “进出参数”(in-out parameter),控制节点 V 去往节点 x、x 的概率,q > 1 时,节点 V 之后更倾向于访问前序节点 t 的共同邻居,q < 1 时,节点 V 之后,更不倾向访问前序节点 t 的邻居。节点 x 显得有点特殊,因为节点 x 同时是节点 t 和 V 的邻居,我们设置权重为 1。通过修改参数 p 和 q,我们就能控制 Random Walk 采样过程,是更倾向 DFS 还是 BFS。
上图是 Node2Vec 的结果,同种颜色代表 Embedding 向量比较接近,节点比较相似。图中上部分参数 p = 1,q = 0.5,结果表现为同质性相似的节点更为接近。下部分参数 p = 1,q = 2,结果表现为结构性相似的节点更为接近。
Node2Vec 所体现的网络的同质性和结构性在推荐系统中也是可以被很直观的解释的。同质性相同的物品很可能是同品类、同属性、或者经常被一同购买的物品,而结构性相同的物品则是各品类的爆款、各品类的最佳凑单商品等拥有类似趋势或者结构性属性的物品。毫无疑问,二者在推荐系统中都是非常重要的特征表达。由于 Node2Vec 的这种灵活性,以及发掘不同特征的能力,甚至可以把不同 Node2Vec 生成的 embedding 融合共同输入后续深度学习网络,以保留物品的不同特征信息。
Graph Embedding 最佳实践:EGES
**我们介绍了一堆概念和算法,那么实际应用,效果如何呢?
2018 年,阿里巴巴发表论文,提出了能够落地的 EGES(Enhanced Graph Embedding with Side Information)算法,在约十亿的用户和二十亿的商品这个数据量,进行了 Graph Embedding。其基本思想是 Embedding 过程中引入带权重的补充信息(Side Information),从而解决冷启动的问题。让我们赶紧来看下流程图:
步骤如下:
- 首先,我们拥有上亿用户的行为数据,不同的用户,在每个 Session 中,访问了一系列商品,例如用户 u2 两次访问淘宝,第一次查看了两个商品
B-E,第二次产看了三个商品D-E-F; - 然后,通过用户的行为数据,我们可以建立一个商品图(Item Graph),可以看出,物品A,B之间的边产生的原因就是因为用户U1先后购买了物品A和物品B,所以产生了一条由A到B的有向边。如果后续产生了多条相同的有向边,则有向边的权重被加强。在将所有用户行为序列都转换成物品相关图中的边之后,全局的物品相关图就建立起来了。
- 接着,通过 Random Walk 对图进行采样,重新获得商品序列;
- 最后,使用 Skip-gram 模型进行 Embedding 。
仔细的读者已经能够发现,如果出现了新的商品怎么办,如果有个商品从没有被人浏览过怎么办?没有关系,就意味着在图上是孤立的点,也意味着,无法获得 Embedding,这就是冷启动的问题。淘宝商城每个小时就有百万级别的商品上线,这些商品该如何推荐呢?
答案其实已在上面给出,新上线的商品虽然没有被人浏览,但是他们也有类别,品牌,所在城市,性别,风格等等各种属性,也就是 Side Information,我们可以通过这些属性建立商品间的关联。下图是一个简单的例子:
如何实现呢?其实并不难。如下图,在训练 Embedding 的时候,不同的补充信息各自经过 Embedding,加权平均汇总到隐含层之后,再用来预测序列中的目标商品。
论文对模型性能进行了 A/B Test,在 2017 年 9 月的一周里,EGES 最终比 Base 模型 CTR 高了约 0.5 个百分点。
阿里的 EGES 并没有过于复杂的理论创新,但给出一个工程性的结合多种 Embedding 的方法,可好解决了冷启动问题,是实用性极强的 Embedding 方法。

若有收获,就点个赞吧
0 人点赞
