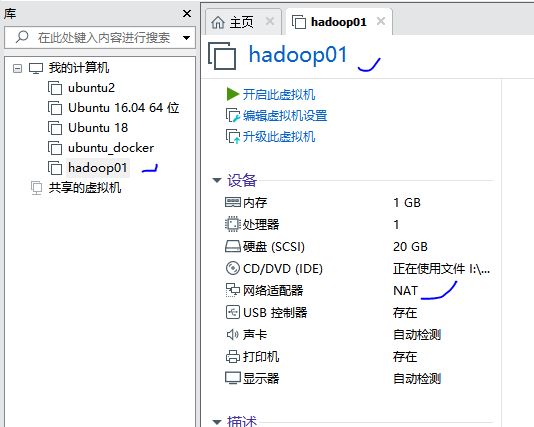
查看基本信息
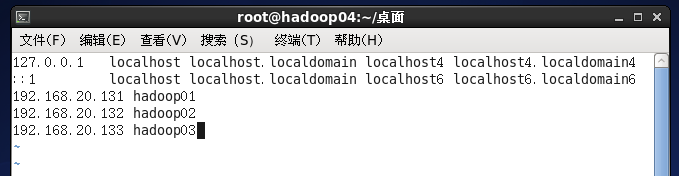
自己设计主机名和对应ip
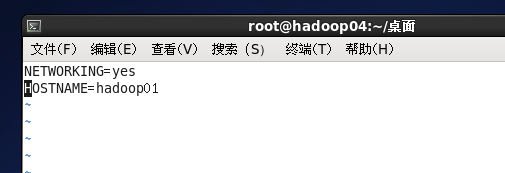
编辑主机名
安装java环境 在根目录下创建export目录,在export目录下创建software servers 目录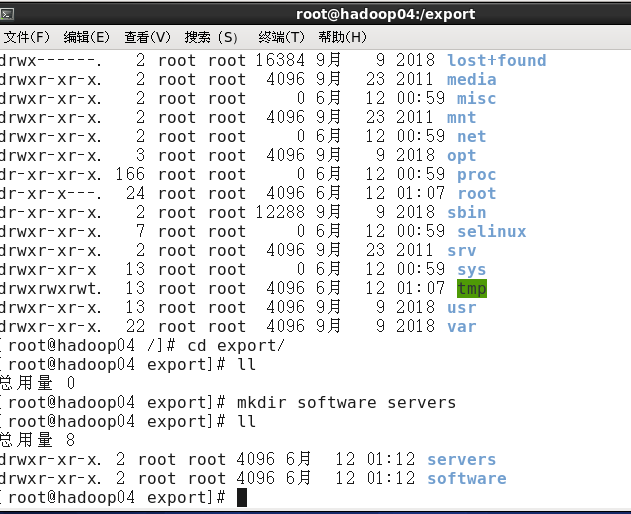
把jdk上传到software目录,然后解压到servers目录

重命名为jdk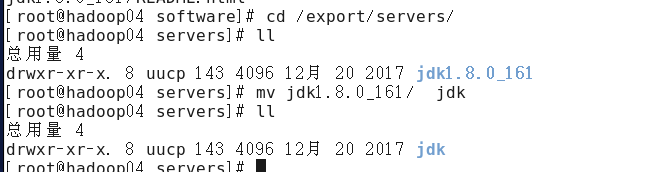
配置java环境
Vim /etc/profile
激活环境
安装wmware tools 工具


关机重启,复制三台机器,配置网络
此时hadoop01的主机名已经改过来了,其他两台机器还没有,都是hadoop01
修改网络,设置静态IP,修改网卡为eth0
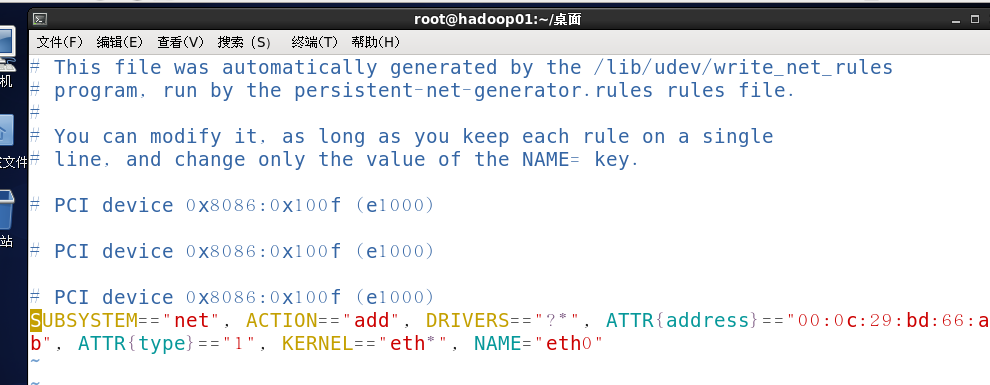

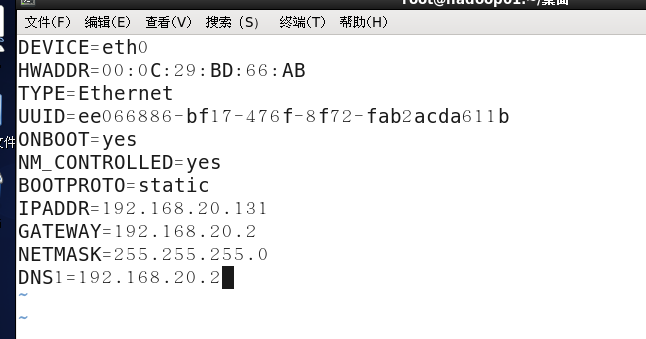
关机重启测试IP,
对其他两台机器进行同样处理
对hadoop02处理。记得修改主机名,修改ip,eth0
Vim /etc/sysconfig/network
Vim /etc/udev/rules.d/70-per-net.rules
Vim /etc/sysconfig/network-scripts/ifcfg-eth0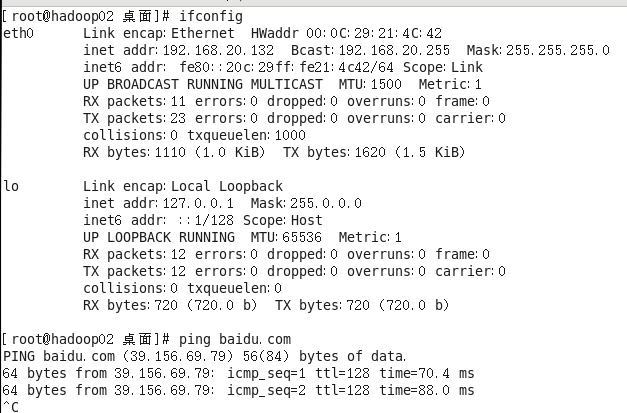
对hadoop03同样处理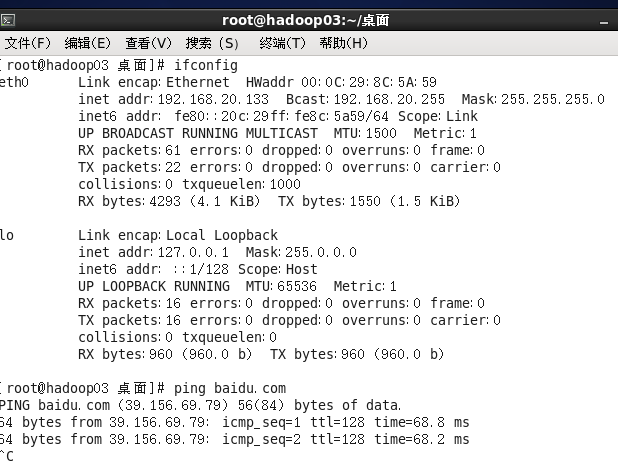
**进行免密码登录设置 可以做也可以不做,记得快照一下,防止奔溃
先远程登录一下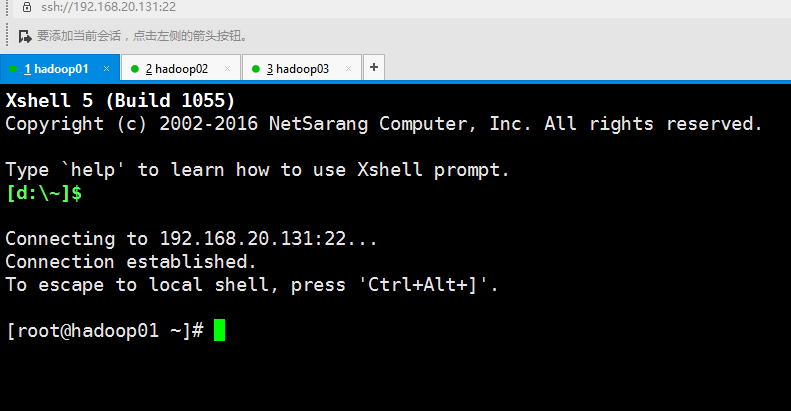

四次回车
进入root目录查看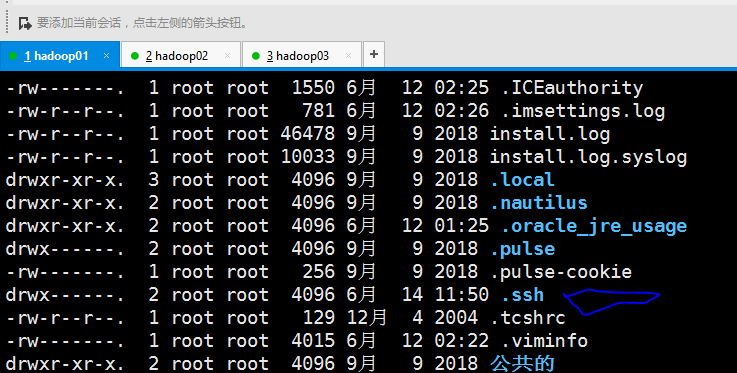
进入到.ssh目录查看公钥私钥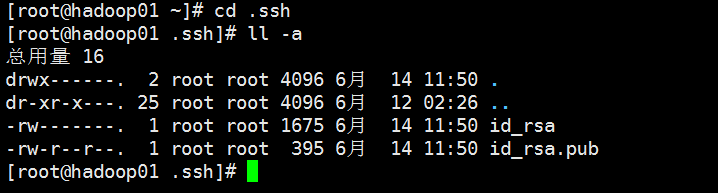
对公钥进行复制hadoop02 hadoop03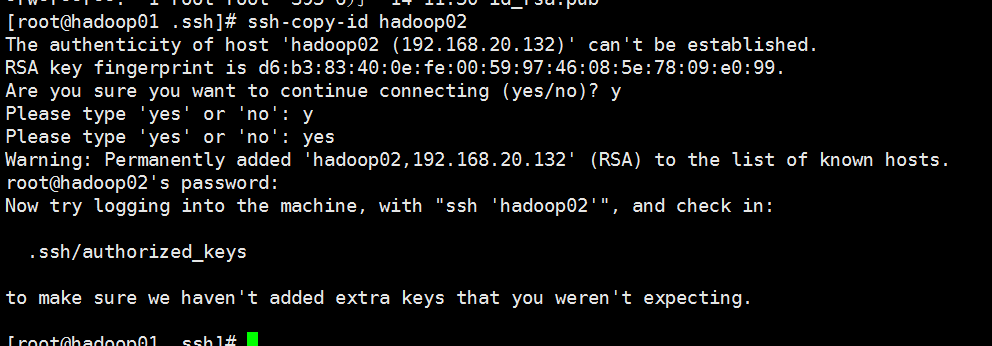
从hadoop01登录到hadoop02
对hadoop03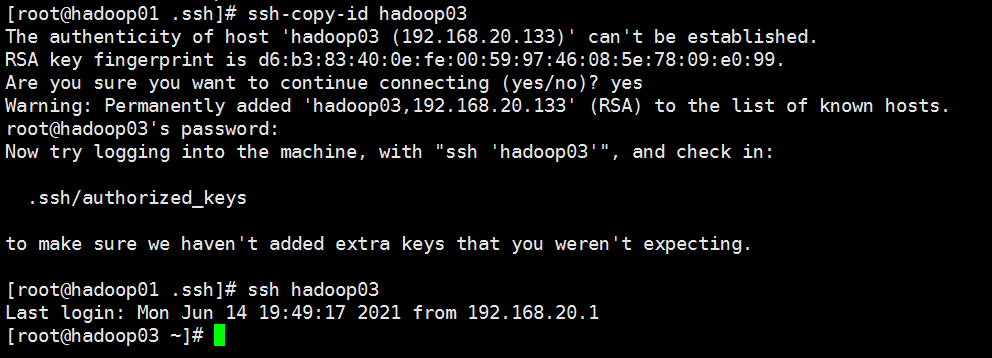
Exit 可以退出
上传hadoop软件到/export/sortware中 解压到servers中

配置 环境变量
Vim /etc/profile
若jdk版本为1.7 classpath 需要$符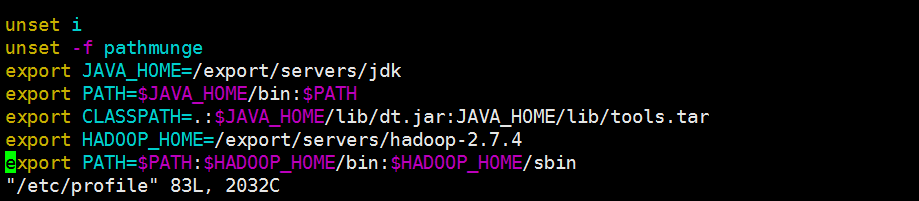
生效 
查看一下hadoop解压目录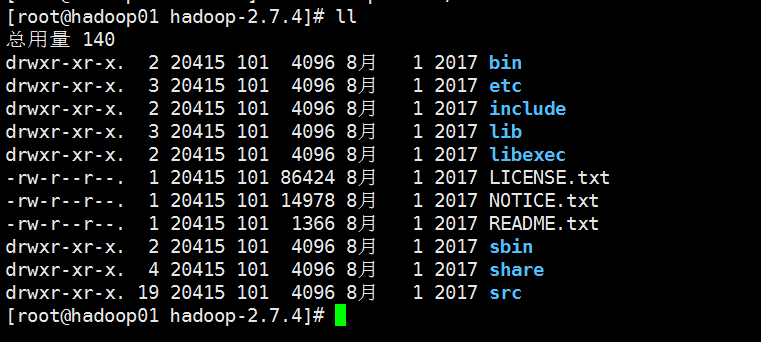
配置hadoop集群节点
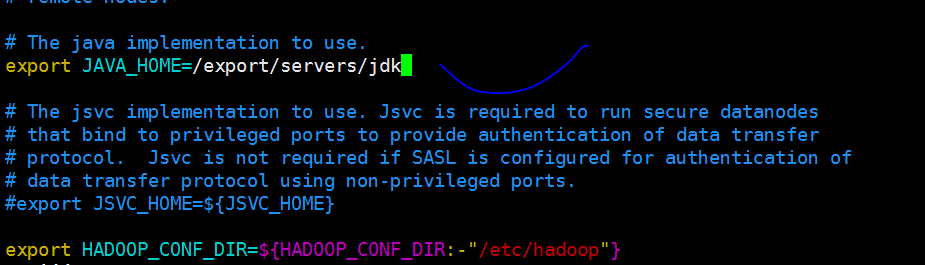
1 配置hadoop/etc/Hadoop/Hadoop-env.sh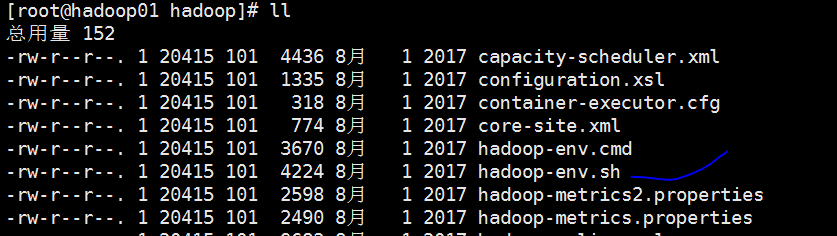

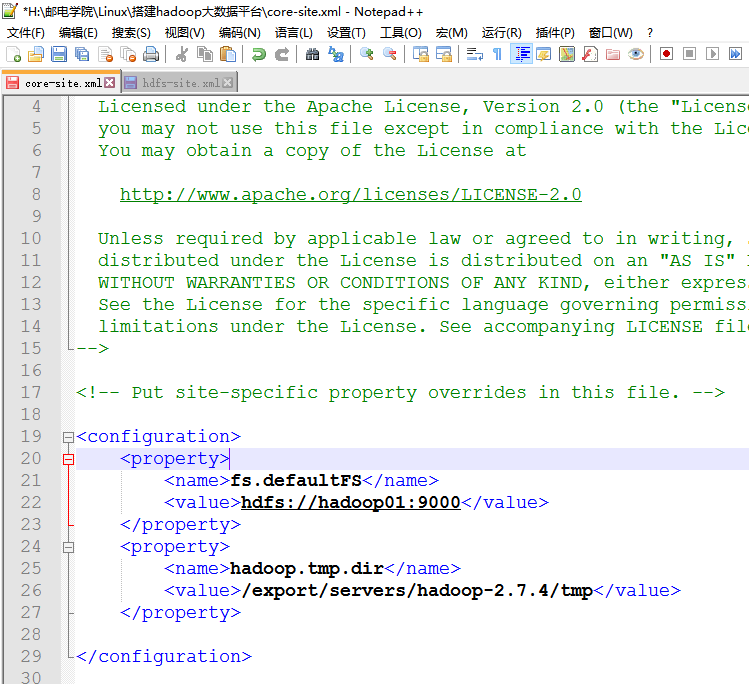
2 修改core-site.xml
如果修改不方便都给他下载到本地,再进行修改
3 修改hdfs.xml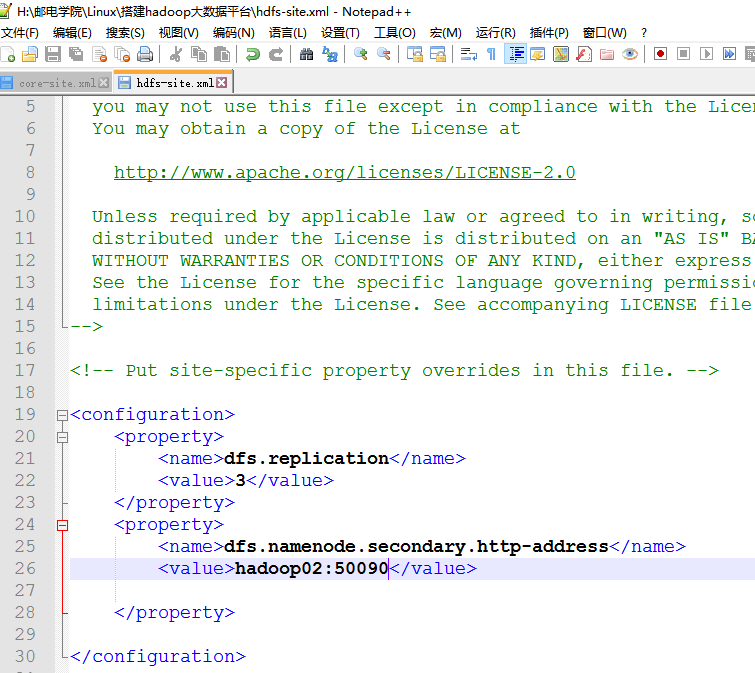
4 修改mapred-site.xml
本来没有这个文件名,需要修改文件名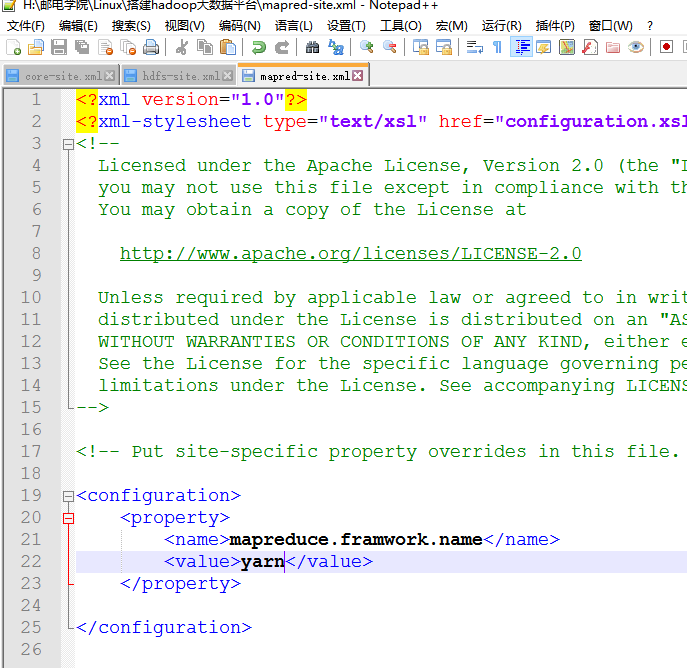
5 修改yarn-site.xml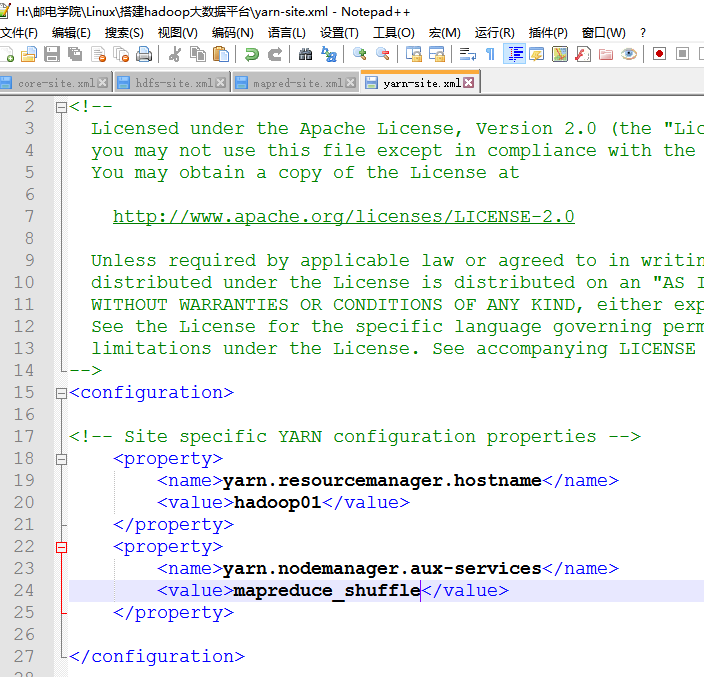
6 修改slaves
删除原来的
上传修改过的
将hadoop01配置好的上传到hadoop02 hadoop03



传输完成,要在集群之间source 一下 文件生效(这是为了保险可以去其他机器ssh端操作)
这一切都做完了,能不能见证奇迹我也不知道,就这一下了,不行你们慢慢做。
格式化文件
Hdfs namenode –format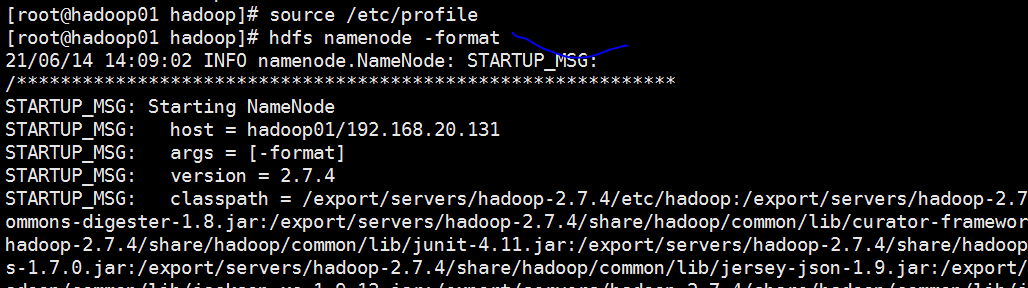

在主节点启动namenode

每一个从节点启动datanode

主节点启动yarn
在两个从节点启动yarn 的nodemanager

在hadoop02启动secondarynamenode
查看一下启动状态


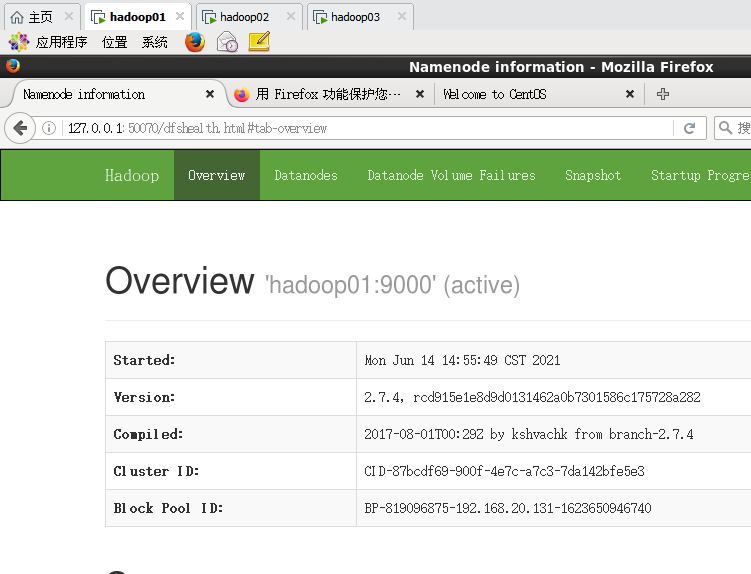
Hadoop01:8088
关闭,把每一个start改为stop

若有收获,就点个赞吧
0 人点赞
