- 了解InfluxDB
- 使用指南[运维必看]
- 概念介绍[运维必看]
- 查询语言[运维必看]
- FAQ[运维必看]
- InfluxDB数据的备份与还原[运维必看]
了解InfluxDB
Influxdb官网
Influxdb介绍
InfluxDB是一个用于存储和分析时间序列数据的开源数据库。
主要特性有:
- 内置HTTP接口,使用方便
- 数据可以打标记,这样查询可以很灵活
- 类SQL的查询语句
- 安装管理很简单,并且读写数据很高效
- 能够实时查询,数据在写入时被索引后就能够被立即查出
- ……
在最新的DB-ENGINES给出的时间序列数据库的排名中,InfluxDB高居第一位,可以预见,InfluxDB会越来越得到广泛的使用。
InfluxDB部署
# 创建influxdb数据存储配置文件路径mkdir -p /data/influxdb/{data,conf}if [ -z "$(docker network ls |grep influxdb)" ] ;thendocker network create influxdbelseecho -----------------------------------------------------------------------docker network ls |grep influxdbecho -----------------------------------------------------------------------echo docker-net:influxdb existecho -----------------------------------------------------------------------fidocker run -d \--name influxdb \--restart always \--net influxdb \-p 8086:8086 \-p 8083:8083 \-v /data/influxdb/conf/influxdb.conf:/etc/influxdb/influxdb.conf \-v /data/influxdb/data:/var/lib/influxdb \influxdb:latest
Influxdb入门
InfluxDB安装完成之后,我们开始来做一些有意思的事。在这一章里面我们将会用到influx这个命令行工具,这个工具包含在InfluxDB的安装包里,是一个操作数据库的轻量级工具。它直接通过InfluxDB的HTTP接口(如果没有修改,默认是8086)来和InfluxDB通信。
# root @ dev_207 in ~ [14:13:44]$ influxConnected to http://localhost:8086 version 1.8.3InfluxDB shell version: 1.8.3>
说明:
- InfluxDB的HTTP接口默认起在
8086上,所以influx默认也是连的本地的8086端口,你可以通过influx --help来看怎么修改默认值。
InfluxDB使用
这样这个命令行已经准备好接收influx的查询语句了(简称InfluxQL),用exit可以退出命令行。
第一次安装好InfluxDB之后是没有数据库的(除了系统自带的_internal),因此创建一个数据库是我们首先要做的事,通过CREATE DATABASE <db-name>这样的InfluxQL语句来创建,其中<db-name>就是数据库的名字。数据库的名字可以是被双引号引起来的任意Unicode字符。 如果名称只包含ASCII字母,数字或下划线,并且不以数字开头,那么也可以不用引起来。
时间戳格式
InfluxDB Cli中,time默认显示为19位时间戳格式,我没改,仍然使用默认的。
说明:
-precision参数表明了任何返回的时间戳的格式和精度,在上面的例子里,rfc3339是让InfluxDB返回RFC339格式(YYYY-MM-DDTHH:MM:SS.nnnnnnnnnZ)的时间戳。
如果需要修改时间戳格式,认为平时查询起来特不方便,那么,如何设置成为我们人类能看懂的时间格式呢?#方法一influx -precision rfc3339#方法二$ influxConnected to http://localhost:8086 version 1.8.3InfluxDB shell version: 1.8.3> precision rfc3339>
创建数据库
说明:在输入上面的语句之后,并没有看到任何信息,这在CLI里,表示语句被执行并且没有错误,如果有错误信息展示,那一定是哪里出问题了,这就是所谓的
没有消息就是好消息。
create database mydb
查看数据库
现在数据库
mydb已经创建好了,我们可以用SHOW DATABASES语句来看看已存在的数据库:
show databases
读写数据
现在我们已经有了一个数据库,那么InfluxDB就可以开始接收读写了。
说明:首先对数据存储的格式来个入门介绍。InfluxDB里存储的数据被称为
时间序列数据,其包含一个数值,就像CPU的load值或是温度值类似的。时序数据有零个或多个数据点,每一个都是一个指标值。数据点包括time(一个时间戳),measurement(例如cpu_load),至少一个k-v格式的field(也即指标的数值例如 “value=0.64”或者“temperature=21.2”),零个或多个tag,其一般是对于这个指标值的元数据(例如“host=server01”, “region=EMEA”, “dc=Frankfurt)。 在概念上,你可以将measurement类比于SQL里面的table,其主键索引总是时间戳。tag和field是在table里的其他列,tag是被索引起来的,field没有。不同之处在于,在InfluxDB里,你可以有几百万的measurements,你不用事先定义数据的scheme,并且null值不会被存储。 将数据点写入InfluxDB,只需要遵守如下的行协议:
<measurement>[,<tag-key>=<tag-value>...] <field-key>=<field-value>[,<field2-key>=<field2-value>...] [unix-nano-timestamp]
案例
# 创建measurement名为cpu
#tag-key1=host,tag-value1=serverA
#tag-key2=regoin,tag-value2=us_west
#field_key1=value,field_value1=0.64
INSERT cpu,host=serverA,region=us_west value=0.64
来开始实战吧
下面是数据写入InfluxDB的格式示例:
cpu,host=serverA,region=us_west value=0.64
payment,device=mobile,product=Notepad,method=credit billed=33,licenses=3i 1434067467100293230
stock,symbol=AAPL bid=127.46,ask=127.48
temperature,machine=unit42,type=assembly external=25,internal=37 1434067467000000000
使用CLI插入单条的时间序列数据到InfluxDB中,用INSERT后跟数据点:
INSERT cpu,host=serverA,region=us_west value=0.64
INSERT cpu,host=serverB,region=cn_east value=0.99
INSERT payment,device=mobile,product=Notepad,method=credit billed=33,licenses=3i 1434067467100293230
INSERT stock,symbol=AAPL bid=127.46,ask=127.48
INSERT temperature,machine=unit42,type=assembly external=25,internal=37 1434067467000000000
查询当前mesurements信息
show measurements
返回结果
> show measurements
name: measurements
name
----
cpu
payment
stock
temperature
>
查询cpu中的现在我们查出写入的这笔数据:
SELECT "host", "region", "value" FROM "cpu"
#也可以使用
select * from cpu
返回结果
说明:我们在写入的时候没有包含时间戳,当没有带时间戳的时候,InfluxDB会自动添加本地的当前时间作为它的时间戳。
> SELECT "host", "region", "value" FROM "cpu"
name: cpu
time host region value
---- ---- ------ -----
1606892111079838444 serverA us_west 0.64
1606892414506786057 serverB cn_east 0.99
>
查询的时候想要返回所有的字段和tag,可以用*:
select * from cpu
返回结果
> select * from cpu
name: cpu
time host region value
---- ---- ------ -----
1606892111079838444 serverA us_west 0.64
1606892414506786057 serverB cn_east 0.99
>
InfluxQL还有很多特性和用法没有被提及,包括支持golang样式的正则,例如:
> SELECT * FROM /.*/ LIMIT 1
--
> SELECT * FROM "cpu"
--
> SELECT * FROM "cpu" WHERE "value" > 0.9
使用指南[运维必看]
写入数据
查询数据
采样和数据保留
硬件指南[运维必看]
硬件指南
这一章会提供一些InfluxDB的硬件推荐,并会回答一些问的最多的关于硬件的问题。下面的推荐都是基于InfluxDB 1.2中的TSM存储引擎。
将要探讨的问题:
- 是用单节点还是集群?
- 对于单节点的一般硬件指南
- 对于集群的硬件指南
- 什么时候需要更多的内存?
- 需要那种类型的磁盘?
- 需要多大的存储空间?
- 该怎么配置硬件?
是用单节点还是集群?
InfluxDB的单节点是完全开源的,InfluxDB的集群版本是闭源的商业版。单节点的实例没有冗余,如果服务不可用,写入和读取数据都会马上失败。集群提供了高可用和冗余,多个数据副本分布在多台服务器上,任何一台服务器的丢失都不会对集群造成重大的影响。
如果您的性能要求仅仅是中等或低负载范围,那么使用单节点的InfluxDB实例就够了。如果你对性能要求相当高,那么你需要集群将负载分担到多台机器上。
对于单节点的一般硬件指南
我们这里定义的InfluxDB的负载是基于每秒的写入的数据量、每秒查询的次数以及唯一series的数目。基于你的负载,我们给出CPU、内存以及IOPS的推荐。
InfluxDB应该跑在SSD上,任何其他存储配置将具有较低的性能特征,并且在正常处理中可能甚至无法从小的中断中恢复。
| 负载 | 每秒写入的字段数 | 每秒中等查询数 | series数量 |
|---|---|---|---|
| 低 | < 5千 | <5 | <10万 |
| 中等 | <25万 | <25 | <1百万 |
| 高 | >25万 | >25 | >1百万 |
| 相当高 | >75万 | >100 | >1千万 |
说明:查询对于系统性能的影响很大
简单查询:
- 几乎没有函数和正则表达式
- 时间限制在几分钟,或是几个小时,又或者到一天
- 通常在几毫秒到几十毫秒内执行
中等查询:
- 有多个函数或者一两个正则表达式
- 有复杂点的
GROUP BY语句或是时间有几个星期的数据- 通常在几百毫秒到几千毫秒内执行
复杂查询:
- 有多个聚合函数、转换函数或者多个正则表达式
- 时间跨度很大有几个月或是几年
- 通常执行时间需要几秒
低负载推荐
- CPU:2~4核
- 内存:2~4GB
-
中等负载推荐
CPU:4~6核
- 内存:8~32GB
-
高负载推荐
CPU:8+核
- 内存:32+GB
-
超高负载
要达到这个范围挑战很大,甚至可能不能完成;联系我们的
tsales@influxdb.com寻求专业帮助吧。对于集群的硬件指南
元节点
一个集群至少要有三个独立的元节点才能允许一个节点的丢失,如果要容忍
n个节点的丢失则需要2n+1个元节点。集群的元节点的数目应该为奇数。不要是偶数元节点,因为这样在特定的配置下会导致故障。
元节点不需要多大的计算压力,忽略掉集群的负载,我们建议元节点的配置: CPU:1~2核
- 内存:512MB~1GB
- IOPS:50
数据节点
一个集群运行只有一个数据节点,但这样数据就没有冗余了。这里的冗余通过写数据的RP中的副本个数来设置。一个集群在丢失n-1个数据节点后仍然能返回完整的数据,其中n是副本个数。为了在集群内实现最佳数据分配,我们建议数据节点的个数为偶数。
对于集群的数据节点硬件的推荐和单节点的类似,数据节点应该至少有两个核的CPU,因为必须处理正常的读取和写入压力,以及集群内的数据的读写。由于集群通信开销,集群中的数据节点处理的吞吐量比同一硬件配置上的单实例的要少。
| 负载 | 每秒写入的字段数 | 每秒中等查询数 | series数量 |
|---|---|---|---|
| 低 | < 5千 | <5 | <10万 |
| 中等 | <10万 | <25 | <1百万 |
| 高 | >10万 | >25 | >1百万 |
| 相当高 | >50万 | >100 | >1千万 |
说明:查询对于系统性能的影响很大 简单查询:
- 几乎没有函数和正则表达式
- 时间限制在几分钟,或是几个小时,又或者到一天
- 通常在几毫秒到几十毫秒内执行
中等查询:
- 有多个函数或者一两个正则表达式
- 有复杂点的
GROUP BY语句或是时间有几个星期的数据- 通常在几百毫秒到几千毫秒内执行
复杂查询:
- 有多个聚合函数、转换函数或者多个正则表达式
- 时间跨度很大有几个月或是几年
- 通常执行时间需要几秒
低负载推荐
- CPU:2~4核
- 内存:2~4GB
-
中等负载推荐
CPU:4~6核
- 内存:8~32GB
-
高负载推荐
CPU:8+核
- 内存:32+GB
- IOPS:1000+
企业Web节点
企业Web服务器主要充当具有类似负载要求的HTTP服务器。 对于大多数应用程序,它不需要性能很强。 一般集群将仅使用一个Web服务器,但是考虑到冗余,可以将多个Web服务器连接到单个后端Postgres数据库。注意:生产集群不应该使用SQLite数据库,因为它不被冗余的Web服务器允许,也不能像Postgres一样处理高负载。
推荐配置:
- CPU:1~4核
- 内存:1~2GB
- IOPS:50
什么时候需要更多的内存?
一般来讲,内存越多,查询的速度越快,增加更多的内存总没有坏处。
影响内存的最主要的因素是series基数,series的基数大约或是超过千万时,就算有更多的内存也可能导致OOM,所以在设计数据的格式的时候需要考虑到这一点。
内存的增长和series的基数存在一个指数级的关系:
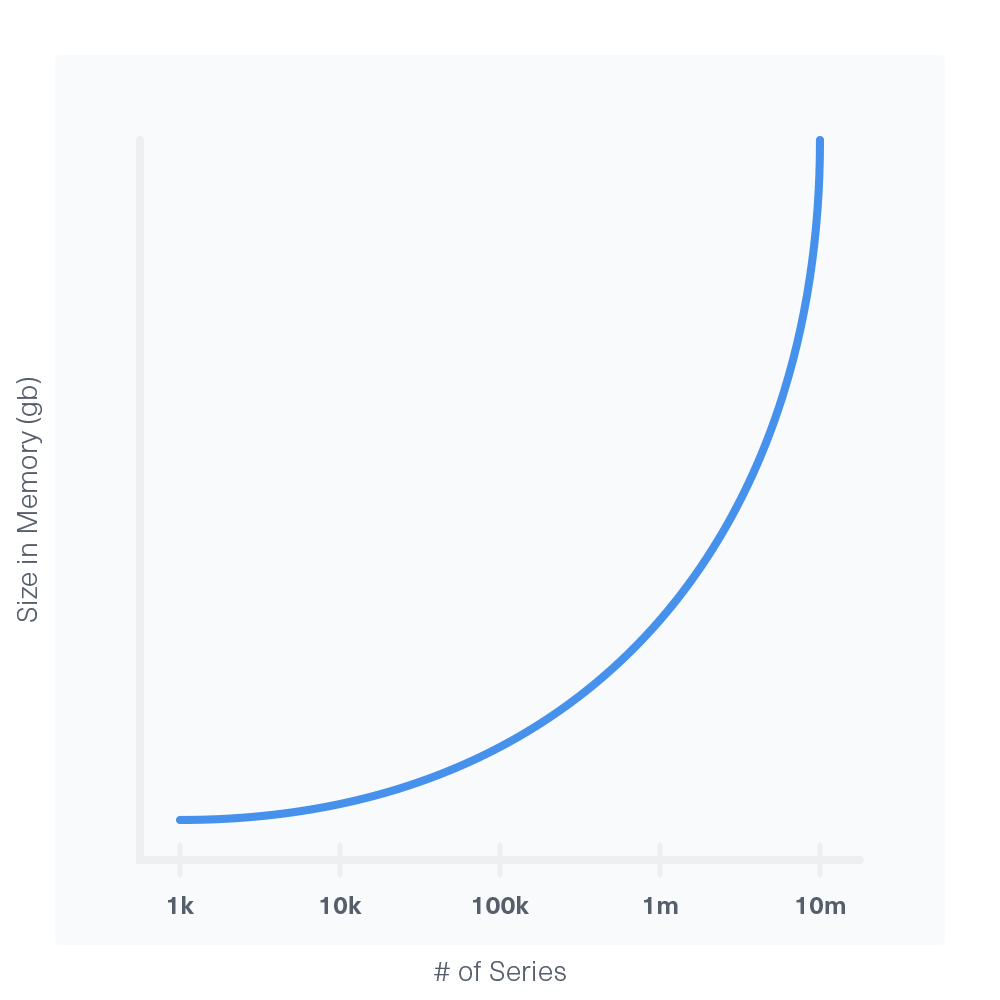
需要哪种类型的磁盘?
InfluxDB被设计运行在SSD上,InfluxData团队不会在HDD和网络存储上测试InfluxDB,所以不太建议在生产上这么去使用。在机械磁盘上性能会下降一个数量级甚至在中等负载下系统都可能死掉。为了最好的结果,InfluxDB至少需要磁盘提供1000 IOPS的性能。
注意集群的数据节点在做故障恢复的时候需要更高的IOPS,所以考虑到可能的数据恢复,我们建议磁盘至少有2000的IOPS,低于1000的IOPS,集群可能无法即时从短暂的中断中恢复。
需要多大的存储空间?
数据库的名字、measurement、tag keys、field keys和tag values只被存储一次且只能是字符串。只有field values和timestamp在每个数据点上都有存储。
非字符串类型的值大约需要3字节,字符串类型的值需要的空间由字符串的压缩来决定。
该怎么配置硬件?
当在生产上运行InfluxDB时,wal和data文件夹需要在存储设备上分开。当系统处于大量写入负载下时,此优化可显着减少磁盘争用。 如果写入负载高度变化,这是一个重要的考虑因素。 如果写入负载不超过15%,则可能不需要优化。
HTTPS设置
Influxdb_http请求写入数据
说明:从运维角度认为次方式较为复杂,这边不再详细阐述。有兴趣的开发可以看看
概念介绍[运维必看]
关键概念[运维必看]
关键概念
对InfluxDB核心架构的关键概念作简要说明,对于初学者来说很重要。
专业术语[运维必看]
专业术语
列出InfluxDB的术语及其定义。
与SQL比较[运维必看]
InfluxDB的设计见解和权衡[运维必看]
InfluxDB的设计见解和权衡
简要介绍了在设计InfluxDB的时候对性能做的一些权衡。
Schema设计[运维必看]
schema设计
InfluxDB时间序列数据结构的概述及其如何影响性能。
存储引擎[运维必看]
存储引擎
概述下InfluxDB是如何将数据存储在磁盘上。
写入协议
InfluxDB的行协议是一种写入数据点到InfluxDB的文本格式。
行协议
查询语言[运维必看]
本部分介绍InfluxQL,InfluxDB的SQL类查询语言,用于与InfluxDB中的数据进行交互。
InfluxQL教程
本部分的前七个文档提供了InfluxQL的教程式介绍。你可以随时下载文档相关的示例数据。
数据库查询语法
数据查询语法
涵盖InfluxQL的查询语言基础知识,包括SELECT语句,GROUP BY子句,INTO子句等。参阅数据查询还可以了解查询中的时间语法和正则表达式。
schema查询语法[运维必看]
schema查询语法
涵盖schema相关的查询语法。有关InfluxQL的SHOW查询的语法说明和示例。
数据库管理[运维必看]
数据库管理
涵盖InfluxQL用于管理InfluxDB中的数据库和存储策略,具体有创建删除数据库和存储策略,以及删除数据。
函数
函数
涵盖InfluxQL的函数。
连续查询
Continuous Queries
涵盖Continuous Queries的基本语法,高级语法和常见用例。 此页面还介绍了如何进行SHOW和DROP Continuous Queries。
数学计算
数学计算
涵盖InfluxQL中的数学计算。
认证和授权
认证和授权
介绍如何设置身份验证和如何验证InfluxDB中的请求。此页面还描述了用于管理数据库用户的不同用户类型和InfluxQL。
InfluxQL参考
InfluxQL参考
InfluxQL参考文档
行协议的教程样式文档
FAQ[运维必看]
管理
如何在密码中包含单引号?
在创建密码和发送身份验证请求时使用反斜杠(\)来转义单引号。
如何查看InfluxDB的版本?
在终端运行influxd version:
$ influxd version
InfluxDB ✨ v1.3.0 ✨ (git: master b7bb7e8359642b6e071735b50ae41f5eb343fd42)
curl路径/ping:
$ curl -i 'http://localhost:8086/ping'
HTTP/1.1 204 No Content
Content-Type: application/json
Request-Id: 1e08aeb6-fec0-11e6-8486-000000000000
✨ X-Influxdb-Version: 1.3.x ✨
Date: Wed, 01 Mar 2017 20:46:17 GMT
运行InfluxDB的命令行:
$ influx
Connected to http://localhost:8086✨ version 1.3.x ✨
InfluxDB shell version: 1.3.x
在日志里查看HTTP返回结果:
$ journald-ctl -u influxdb.service
Mar 01 20:49:45 rk-api influxd[29560]: [httpd] 127.0.0.1 - - [01/Mar/2017:20:49:45 +0000] "POST /query?db=&epoch=ns&q=SHOW+DATABASES HTTP/1.1" 200 151 "-" ✨ "InfluxDBShell/1.3.x" ✨ 9a4371a1-fec0-11e6-84b6-000000000000 1709
怎样查看InfluxDB的日志?
System V操作系统上,日志存储在/var/log/influxdb/下。
在systemd操作系统上,可以使用journalctl访问日志。 使用journalctl -u influxdb查看日志或journalctl -u influxdb> influxd.log将日志打印到文本文件。使用systemd时,日志保留取决于系统的日记设置。
分片组的保留时间和保留策略之间的关系?
nfluxDB将数据存储在分片组中。一个分片组覆盖特定的时间间隔; InfluxDB通过查看相关保留策略(RP)的DURATION来确定时间间隔。下表列出了RP的DURATION和分片组的时间间隔之间的默认关系:
| RP持续时间 | 分片组间隔 |
|---|---|
| <2天 | 1小时 |
| >= 2天,<= 6个月 | 1天 |
| > 6个月 | 7天 |
用户还可以使用CREATE RETENTION POLICY和ALTER RETENTION POLICY语句配置分片组持续时间。使用SHOW RETENTION POLICY语句检查保留策略的分片组持续时间。
为什么在修改了RP之后数据没有被删除?
有几个因素可以解释为什么保留策略(RP)更改后数据可能不会立即丢失。
第一个也是最可能的原因是,默认情况下,InfluxDB每30分钟检查一次强制RP。可能需要等待下一次RP检查InfluxDB才能删除RP的新DURATION设置之外的数据。30分钟的间隔是可配置的。
其次,改变RP的DURATION和SHARD DURATION可能会导致意外的数据保留。InfluxDB将数据存储在包含特定RP和时间间隔的分片组中。当InfluxDB执行一个RP时,它会删除整个分片组,而不是单个数据点。InfluxDB不能拆分分片组。
如果RP的新DURATION小于旧的SHARD DURATION,并且InfluxDB正在将数据写入其中一个较旧的分片组,则系统将被迫将所有数据保留在该分片组中。即使该分片组中的某些数据不在新的DURATION中,也会发生这种情况。一旦所有的数据都在新的DURATION之外,InfluxDB将删除该分片组。系统将开始将数据写入新的分片组,这些分片组具有新的更短的SHARD DURATION,以防止写入不被期望的数据。
为什么InfluxDB无法在配置文件中解析微秒单位?
用于指定微秒持续时间单位的语法在配置设置,和写入,查询以及在InfluxDB命令行界面(CLI)中设置精度方面有所不同。 下表显示了每个类别支持的语法:
| 单位 | 配置文件 | HTTP API写入 | 所有的查询 | CLI精度命令行 |
|---|---|---|---|---|
| u | ❌ | 👍 | 👍 | 👍 |
| us | 👍 | ❌ | ❌ | ❌ |
| µ | ❌ | ❌ | 👍 | ❌ |
| µs | 👍 | ❌ | ❌ | ❌ |
如果配置选项指定u或μ语法,InfluxDB将无法启动并在日志中报告以下错误:
run: parse config: time: unknown unit [µ|u] in duration [<integer>µ|<integer>u]
命令行
怎么让InfluxDB的CLI返回用户可读的时间戳?
当你第一次连CLI,可以指定rfc3339精度:
$ influx -precision rfc3339
此外,如果你已经连接了CLI,则可以通过指令来指定:
$ influx
Connected to http://localhost:8086 version 0.xx.x
InfluxDB shell 0.xx.x
> precision rfc3339
>
一个非admin用户怎么在InfluxDB的CLI下USE一个数据库?
在v1.3之前的版本中,非admin用户是不能在CLI执行USE <database_name>的查询的,即使拥有这个数据库的READ或/和Write权限。
从1.3开始,非admin用户也可以执行USE <database_name>的查询只要拥有这个数据库的READ或/和Write权限。如果非admin使用USE一个数据库,但是没有权限时,系统会返回一个错误:
ERR: Database <database_name> doesn't exist. Run SHOW DATABASES for a list of existing databases.
注意:非admin用户执行
SHOW DATABASES,只返回有权限的数据库。
在InfluxDB的CLI下,如何写入一个非默认的retention policy?
使用语法INSERT INTO [<database>.]<retention_policy> <line_protocol>可以在CLI下把数据写入非DEFAULT的retention policy里面。(如果使用HTTP来写入数据的话,可以通过参数db和rp来指定数据库和retention policy)。
例如:
> INSERT INTO one_day mortality bool=true
Using retention policy one_day
> SELECT * FROM "mydb"."one_day"."mortality"
name: mortality
---------------
time bool
2016-09-13T22:29:43.229530864Z true
注意如果要查询出非DEFAULT的retention policy,需要指定完整的measurement路径:
"<database>"."<retention_policy>"."<measurement>"
怎么取消一个长期运行的查询?
在CLI下,你可以用Ctrl+C来取消执行的查询。对于其他的长时间运行的查询,你可以先使用SHOW QUERIES列出来,然后使用KILL QUERY来停止对应的查询。
为什么不能查询布尔型的field value?
对于写和读,接受布尔型的数据的语法不一样。
| 布尔语法 | 写 | 读 |
|---|---|---|
| t,f | 👍 | ❌ |
| T,F | 👍 | ❌ |
| true,false | 👍 | 👍 |
| True,False | 👍 | 👍 |
| TRUE,FALSE | 👍 | 👍 |
例如,SELECT * FROM "hamlet" WHERE "bool"=True返回所有bool的值为TRUE的,但是SELECT * FROM "hamlet" WHERE "bool"=T什么都不会返回。 Github Issue #3939
InfluxDB怎么处理不同shard里面的字段类型冲突?
字段的值类型可以是浮点,整数,字符串和布尔型。字段的类型在同一个shard里面是一致的,但是在不同的shard里面可以不一样。
SELECT语句
如果所有值都具有相同的类型,SELECT语句会返回所有字段值。如果字段的值类型在不同的shard里面不一样,InfluxDB首先执行正常操作并将所有值返回为出现在下面的列表的第一个类型:浮点,整数,字符串和布尔型。
如果你的数据字段的值类型不符,使用语法<field_key>::<type>查询不同的数据类型。
例子
measurementjust_my_type有一个字段叫作my_field。my_field在四个不同shard里面有四个不同的类型分别为(浮点,整数,字符串和布尔型)。SELECT*只返回浮点数和整数字段值。注意InfluxDB在返回时把整数转化为了浮点类型。
SELECT * FROM just_my_type
name: just_my_type
------------------
time my_field
2016-06-03T15:45:00Z 9.87034
2016-06-03T16:45:00Z 7
SELECT<field_key>::<type>[…]返回所有值类型。我们可以在InfluxDB列名里增加自己的列输出的值类型。在可能的情况下,InfluxDB字段值会转到另一个类型;它把整数7在第一列中转化为了浮点数,而且把9.879034在第二列中转化为了整数。InfluxDB不能把浮点或整数转化为字符串或布尔值。
SELECT "my_field"::float,"my_field"::integer,"my_field"::string,"my_field"::boolean FROM just_my_type
name: just_my_type
------------------
time my_field my_field_1 my_field_2 my_field_3
2016-06-03T15:45:00Z 9.87034 9
2016-06-03T16:45:00Z 7 7
2016-06-03T17:45:00Z a string
2016-06-03T18:45:00Z true
SHOW FIELD KEYS查询
SHOW FIELD KEYS会返回相关field在不同的shard里面的每种类型。
measurementjust_my_type有一个字段叫作my_field。my_field在四个不同shard里面有四个不同的类型分别为(浮点,整数,字符串和布尔型)。SHOW FIELD KEYS返回所有四种数据类型:
> SHOW FIELD KEYS
name: just_my_type
fieldKey fieldType
-------- ---------
my_field float
my_field string
my_field integer
my_field boolean
InfluxDB数据的备份与还原[运维必看]

若有收获,就点个赞吧
0 人点赞
