参考文档
概述
部署架构图大致如下

Fliebeat为客户端。
Logstash+Elastsearch+Kibana 为服务端。(本文Elasticsearch没有做集群,而是单节点,后期考虑集群)
例如业务服务器上面只需要安装客户端就行了,filebeat只需要将指定日志文件中的数据传输到服务端即可,资源消耗小,轻量级。这样可以尽可能不影响业务端上的业务程序。
而且ELK服务端即使挂了也不会影响到业务端。
Logstash和filebeat是什么关系
Lf关系原文链接
因为logstash是jvm跑的,资源消耗比较大,所以后来作者又用golang写了一个功能较少但是资源消耗也小的轻量级的logstash-forwarder。不过作者只是一个人,加入http://elastic.co公司以后,因为es公司本身还收购了另一个开源项目packetbeat,而这个项目专门就是用golang的,有整个团队,所以es公司干脆把logstash-forwarder的开发工作也合并到同一个golang团队来搞,于是新的项目就叫filebeat了。
logstash 和filebeat都具有日志收集功能,filebeat更轻量,占用资源更少,但logstash 具有filter功能,能过滤分析日志。一般结构都是filebeat采集日志,然后发送到消息队列,redis,kafaka。然后logstash去获取,利用filter功能过滤分析,然后存储到elasticsearch中。
logstash类似垃圾车的角色
fieble类似环卫工人的角色
服务端环境
Centos7 4核16G
创建对应目录目录以及用户,Elastic Search启动:由于ES的启动不能用root账号直接启动,需要新创建用户,然后切换新用户去启动,接下来都以elsearch用户操作
useradd elsearchmkdir -p /data/elk && cd /data/elkchown -R elsearch.elsearch /data/elksu - elsearch
JDK
下载地址
java环境变量就不再详细阐述,jdk版本需要大于1.8
Elastsearch
cd /data/elk
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.3.2-linux-x86_64.tar.gz
tar -xvf elasticsearch-7.3.2 && mv elasticsearch-7.3.2 elasticsearch
编辑配置
修改elasticsearch/config/elasticsearch.yml添加或修改以下内容
#es名称
cluster.name: my_es_cluster
#节点名称
node.name: node-1
#索引数据存放地址
path.data: /data/elk/elasticsearch/data
#es日志存放地址
path.logs: /data/elk/elasticsearch/logs
http.cors.enabled: true
http.cors.allow-origin: "*"
node.master: true
node.data: true
# 配置白名单 0.0.0.0表示其他机器都可访问
network.host: 0.0.0.0
#默认为cluster.initial_master_nodes: [“node-1”,“node-2”],如果不删除node-2,会产生bootstrap checks failed错误
cluster.initial_master_nodes: ["node-1"]
transport.tcp.port: 9300
#tcp 传输压缩
transport.tcp.compress: true
#绑定端口
http.port: 9200
discovery.zen.ping.unicast.hosts: ["elk"]
#basic因为elasticsearch 7.2默认集成了xpack,而默认的license就只能用30天,所以更改为只使用最基本的功能
xpack.license.self_generated.type: basic
启动Elasticsearch
/data/elk/elasticsearch/bin/elasticsearch &
启动报错
启动过程中,会出现一些报错信息,如:
1、max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
2、max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决问题(1):将当前用户的软硬限制调大。
— 切换到root用户
su - root
修改/etc/security/limits.conf添加或修改以下内容
* soft nproc 65536
* hard nproc 65536
* soft nofile 65536
* hard nofile 65536
— 保存退出
— 不需要重启,重新登录即生效
— 查看修改命名是否生效
ulimit -n
— 结果65536
ulimit -H -n
— 结果65536
解决问题(2):调大elasticsearch用户拥有的内存权限
sysctl -w vm.max_map_count=262144
— 查看修改结果
sysctl -a|grep vm.max_map_count
— 结果显示:vm.max_map_count = 262144
— 永久生效设置
修改/etc/sysctl.conf添加或修改以下内容
vm.max_map_count=262144
—保存后退出
执行以下命令使其生效
sysctl -p
再次启动Elasticsearch
su - elsearch
cd /data/elk/elasticsearch
nohup bin/elasticsearch >> logs/elasticsearch.log 2>> logs/elasticsearch_error.log &
访问Elasticsearch
若访问不了,优先关闭防火墙测试
访问结果是一串json,说明启动成功了。
http//IP:9200
Kibana
下载指南
下载并解压,修改名字
cd /data/elk
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.3.2-linux-x86_64.tar.gz
tar -xvf kibana-7.3.2-linux-x86_64.tar.gz && mv kibana-7.3.2-linux-x86_64 kibana
编辑配置
vim kibana/config/kibana.yml
最下方添加
#汉化
i18n.locale: "zh-CN"
#kibana监听端口
server.port: 5601
#默认内外网都可以访问
server.host: "0.0.0.0"
#elasticsearch.hosts内部访问地址
elasticsearch.hosts: ["http://localhost:9200"]
kibana.index: ".kibana"
由于 kibana5. 6. 官方并没有支持中文,需要另外下载补丁包 推荐下面这个 ↓
https://github.com/anbai-inc/Kibana_Hanization
不过我这边下载的是7.*的版本,故直接修改配置文件即可,中文包在下面这个路径↓
找不到的就通过find搜索或locate也行 不过大概了解即可,这里就不在过多阐述。
kibana/node_modules/x-pack/plugins/translations/translations/zh-CN.jso
启动Kibana
cd /data/elk/kibana
nohup bin/kibana >> kibana.log 2>> kibana_error.log &
访问Kibana

若访问不了,优先关闭防火墙测试
http://IP:5601
Logstash
cd /data/elk
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.3.2.tar.gz
tar -xvf logstash-7.3.2.tar.gz && mv logstash-7.3.2 logstash
编辑配置
默认无需改动,只需将logstash-sample.conf命名为logstash.conf即可
cp logstash/config/logstash-sample.conf logstash/config/logstash.conf
启动Logstash
--config.reload.automatic项会定期自动重载配置,可以不停止重启Logstash就可以修改配置。
cd /data/elk/logstash
nohup bin/logstash -f config/logstash.conf --config.reload.automatic >> logstash-plain.log &
客户端安装Filebeat,并以收集nginx日志为例
mkdir -p /data && cd /data/
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.3.2-linux-x86_64.tar.gz
tar -xvf filebeat-7.3.2-linux-x86_64.tar.gz && mv filebeat-7.3.2-linux-x86_64 filebeat
cd filebeat
编辑配置
修改 filebeat.yml 以设置连接信息:
output.logstash:
# The Logstash hosts
#hosts: ["localhost:5044"]
#修改为自己服务端的logstash ip:端口
hosts: ["192.168.2.199:5044"]
在filebeat.inputs段中添加下列信息: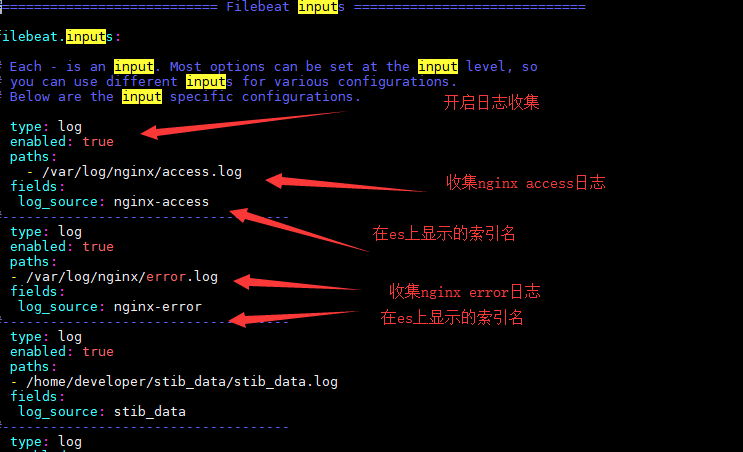
- type: log
enabled: true
paths:
#也可以是其他程序日志
- /var/log/nginx/access.log
fields:
#也可以其他索引名
log_source: nginx-access
#------------------------------------
- type: log
enabled: true
paths:
#也可以是其他程序日志
- /var/log/nginx/error.log
fields:
#也可以其他索引名
log_source: nginx-error
启动filebeat
cd /data/filebeat
nohup ./filebeat -e -c filebeat.yml >> start.log 2> error.log &
服务端logstash配置文件修改

修改 logstash.conf 以设置连接信息:
output {
# filebeat传输过来的index名
if "nginx-access" in [fields][log_source] {
elasticsearch {
#elasticsearch的ip:监听端口
hosts => ["http://localhost:9200"]
index => "nginx-access-%{+YYYY.MM}"
# index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
}
}
# filebeat传输过来的index名
if "nginx-error" in [fields][log_source] {
elasticsearch {
#elasticsearch的ip:监听端口
hosts => ["http://localhost:9200"]
index => "nginx-error-%{+YYYY.MM}"
# index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
}
}
}
因为之前在启动服务端logstash的时候,添加了这个参数--config.reload.automatic项会定期自动重载配置,可以不停止重启Logstash就可以修改配置。故无需做任何操作(也可以手动kill再启动logstash)
kibana上配置新增索引
访问服务端的kibana
http://服务端IP:5601

点击索引模式
创建索引,输入filebeat中定义的nginx-access 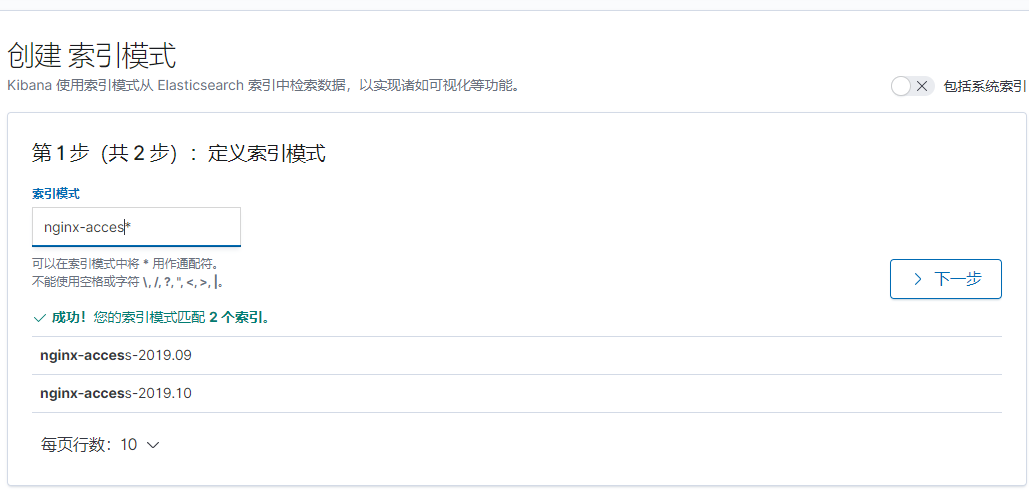
点击下一步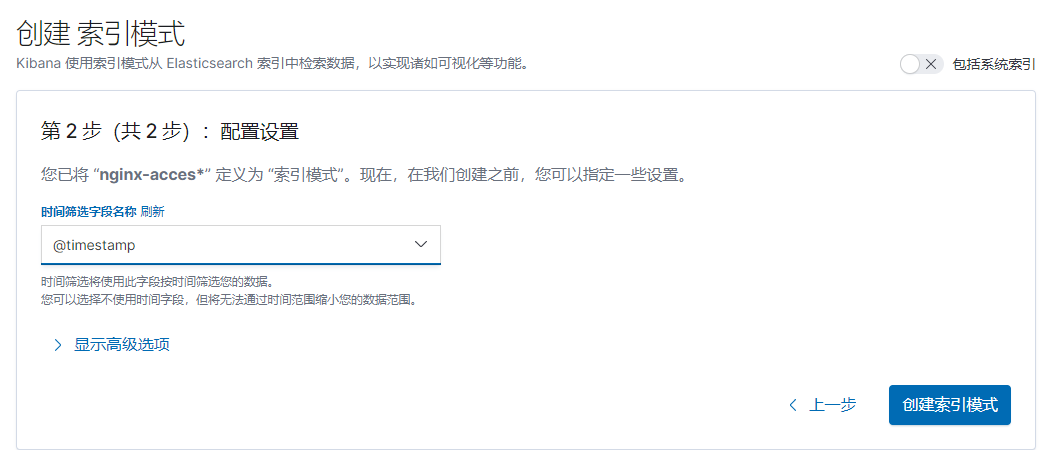
选择timestamp>>>创建索引模式即可
创建完成后回到discover发现
这时候直接看日志可能看不懂,没关系,点击字段,根据字段索引列出日志
选择message简介明了。over。就可以看到nginx的access日志了!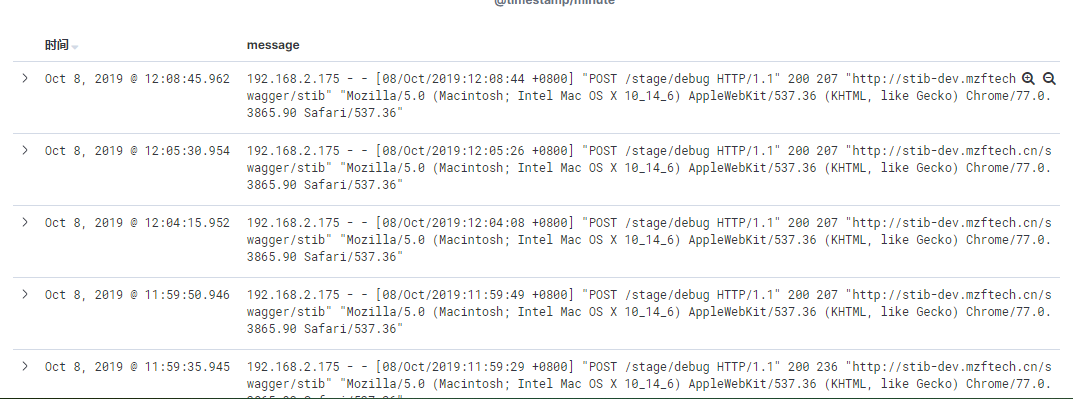
完成所有步骤后,通过自己需求,便可以随时浏览自己的数据,这边我没有在logstash上做过滤操作,有需要的请自行google。
测试情况
在国庆前,通过zabbix监控 ELK服务端 以及 F客户端 服务器的资源占用情况,至今情况来看,比较明显的是,
客户端Filebeat在产生filebeat收集的日志的时候,CPU以及 带宽占用 。有明显增长。(进程为filebeat)
服务端ELK在收集filebeat日志的时候,CPU以及 带宽占用 。有明显增长。(进程主要为elasticsearch)

若有收获,就点个赞吧
0 人点赞
