在单机上很容易实现ACID特性的事务,但是在分布式系统上就比较困难,困难之处在于三个方面:
- 通讯问题,因为网络本身的不可靠性,分布式系统中的各个节点都可能伴随着网络不可用的风险;而且即使各个节点之间能正常通信,但是相比单机的内存访问,网络通信就慢上很多(是内存访问的105、106倍多)
- (衍生)网络分区问题,如果一部分一部分的主机因为通讯问题被分割开来,各自形成一个小集群,就会导致两边的集群数据不一致
- 三态问题,单机节点上调用一个函数只会有成功和失败两种情况;而在分布式系统中,调用一个服务会有成功、失败、超时三种状态。
- 节点故障,每个节点都有可能因为各种不可避免的客观因素问题(比如硬件问题)导致故障。
而这三个问题被大佬总结为 CAP理论 。
CAP理论
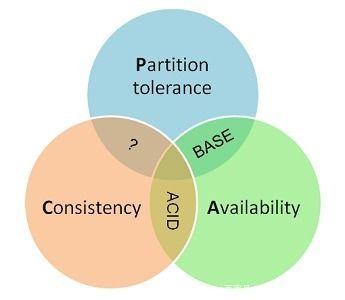
CAP理论提出了三个维度的指标:
- C:Consistency。保证一次事务执行后,所有节点的数据一致性。
- A:Availability。每次请求都能获取到非错的响应——但是不保证获取的数据最新。
- P:Partition Tolerance。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择,到底是 为了可用性允许客户端访问不一致的数据 还是 阻塞等待数据同步。
通过该理论,我们可以枚举出以下几种组合:
- CA,撇开分区容错性,这就是一个单机系统,此时强一致性和强可用性均能保证,ACID的特性均能满足
- CP(A),偏向数据一致性的理论(还没有发现叫什么名字),常见的产品有ZooKeeper
- AP(C),现有一套BASE理论描述 偏高可用性的分布式系统理论——BASE理论,该组合常见的产品有Eureka
- CAP,不存在
PS:用括号标起来的表示 弱项;比如CP(A)组合 表示 强数据一致性+分区容错性+弱可用性,并不是没有可用性,没有可用性那还用个🔨呢;同理AP(C)组合,如果没有数据一致性,那我这个分布式系统就没啥意义了呀(除非是无状态的)
我们这次介绍的系统——ZooKeeper就是CP组合的分布式服务协调软件,下面将详细分析ZooKeeper是如何实现CP的。
ZooKeeper的选择
比较常见的分布式一致性协议有以下几种:
- 2PC
- 3PC
- Paxos
而ZooKeeper没有直接这些协议,而是使用的一套自创的ZAB协议(原子广播协议,Zookeeper Atomic Broadcast)。该协议可以算是Paxos算法的变种
- 它的主要作用就是保证Zookeeper的数据一致性,基于该协议Zookeeper实现了一套主备模式的系统架构来保持集群内各个系统的一致性。
- 在这套架构中,只有一个主进程可以接收并处理请求,其余进程只做数据冗余
- 单进程处理,能够顺序执行,保持数据地依赖性。简单来说就是能够保证一个数据更新时,它依赖地其他数据必须先于它更新
- 在这套架构中,只有一个主进程可以接收并处理请求,其余进程只做数据冗余
Leader服务器负责将请求转成一个proposal并分发给其他follower服务器,之后Leader需要等待所有Follower服务器地反馈,当反馈里由一半以上地成功响应时,Leader就会向所有地Follower分发commit
它是Paxos算法的变种
它有两个模式,一个是崩溃恢复模式,一个是消息广播模式
- 当zookeeper启动过程中,或leader服务器出现网络中断,崩溃退出、重启等情况就会触发崩溃恢复,选举产生新的Leader服务器。当选举出了新的Leader服务器,同时集群中已经有过半的机器和新Leader完成数据同步,ZAB就会退出恢复模式,进入消息广播模式
- 如果Leader收到了客户端的请求,就转成事务,分发给所有follower;如果非leader接收到请求,就转发给leader,然后leader再处理
消息广播模式
点击查看【processon】
ZAB原子协议流程可以分为两个阶段:
- 第一个阶段
- 由Leader“发起提案”(外部的请求转换为事务,并分配唯一的事务ID),将事务(即proposal)发送给Follower
- Leader会为每个Follower服务器分配一个单独的队列,然后将需要广播的事务依次放入这些队列中,并且根据FIFO策略进行发送(ZAB保证每个消息的因果关系)
- Follower们如果能成功接收到数据,就先将事务以日志形式写入到本地磁盘
- 接收并写入事务成功的Follower返回ACK给Leader
- 由Leader“发起提案”(外部的请求转换为事务,并分配唯一的事务ID),将事务(即proposal)发送给Follower
- 第二个阶段
- Leader查看返回的ACK数量是否超过从机的半数
- 如果超过就发送提交请求(即commit消息)给各个Follower,接收到commit请求的Follower完成事务提交;同时Leader自身也完成事务的提交
- 如果没超过就视此次写操作失败
- Leader查看返回的ACK数量是否超过从机的半数
带来的问题:
无法处理Leader服务器崩溃退出而带来的数据不一致性问题,所以ZAB添加另一个模式 崩溃恢复模式。
崩溃恢复模式
如何快速选举出一个Leader,如何快速让集群中的其他机器也能快速感知到新leader
特点:
- ZAB需要确保那些在Leader服务器上提交的事务最终被所有服务器提交
- 比如Server1在给Server2发送了C2后就崩溃了;ZAB协议需要C2在所有服务器上提交成功
- ZAB需要丢弃那些只在Leader服务器上被提出的事务
通过标记最大的事务ID来实现(ZXID)
数据同步
ZAB状态

若有收获,就点个赞吧
0 人点赞
