伪分布式集群安装
伪分布式就是指多个Zookeeper实例在一台主机上的情况,我们需要做的就是整三个不同的配置文件,使用不同的配置文件启动Zookeeper:
主要修改的配置项为:
dataDir,保证不同的Zookeeper实例的数据保存在不同路径下(记得要创建文件夹)clientPort,客户端连接端口不能冲突server.ID=IP:CONNECT:ELECTON,集群配置信息。因为是在同一个主机上,所以这里要保证CONNECT_PORT端口和ELECTON端口都不一样
除此之外还要在每个dataDir下按照创建 myid 文件,ID来自于 server.ID 里的ID
到这里然后使用命令行分别启动三个 ZooKeeper 实例:
# 注意,这里的--config 只能指定zoo.cfg所在的目录。比如下面的zoo1其实是目录,真实的配置文件路径是# /home/apache-zookeeper-3.6.1-bin/conf/zoo1/zoo.cfg./zkServer.sh --config /home/apache-zookeeper-3.6.1-bin/conf/zoo1./zkServer.sh --config /home/apache-zookeeper-3.6.1-bin/conf/zoo2./zkServer.sh --config /home/apache-zookeeper-3.6.1-bin/conf/zoo3
分布式集群安装
相比伪分布式集群,此种方式就是一个ZooKeeper实例一个主机,相关的配置项有以下这几个:
initLimit=10,集群之间“商量”选举出Leader的时间限制,时长为initLimit * tickTimesyncLimit=5,指定了 follower 和 leader 之间 允许的超时时间间隔server.ID=IP:CONNECT:ELECTON,ID表示ZooKeeper实例的ID(只能是数字);IP表示对应的Zookeeper实例的地址;CONNECT表示Zookeeper之间交流通信的端口;ELECTON表示选举Leader的端口
PS:要注意防火墙问题,还有不同主机上的系统时间问题(Zookeeper对时间很敏感)!
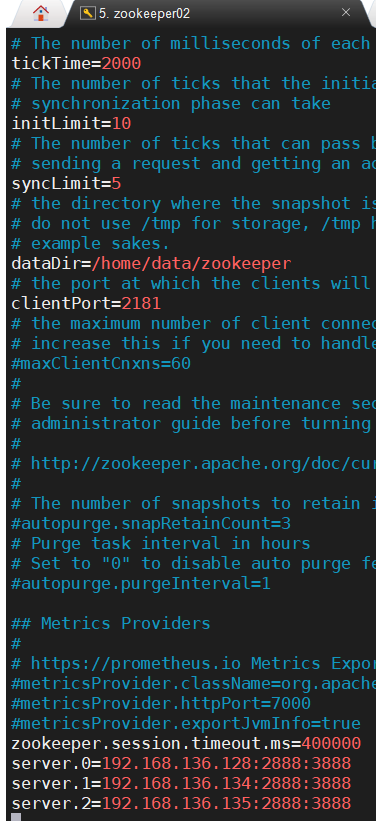
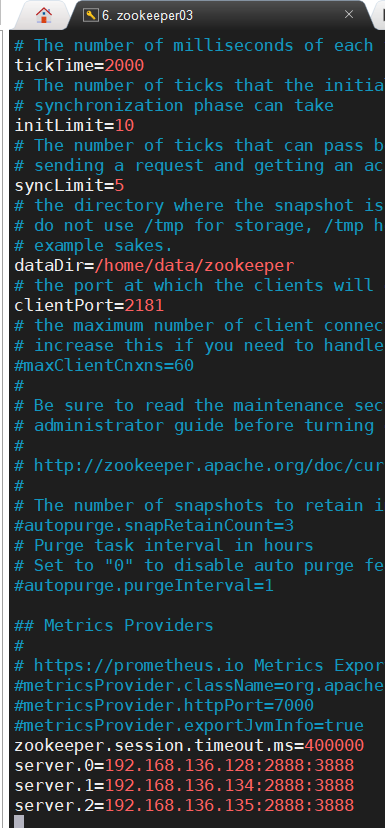
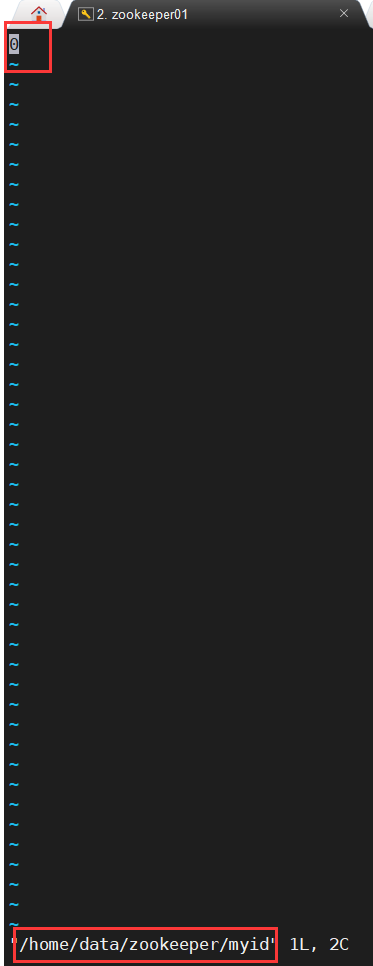
最后给每台ZooKeeper实例的dataDir目录下,创建一个 myid 文件,里面的值是该Zookeeper实例的ID,各实例的配置文件如下所示: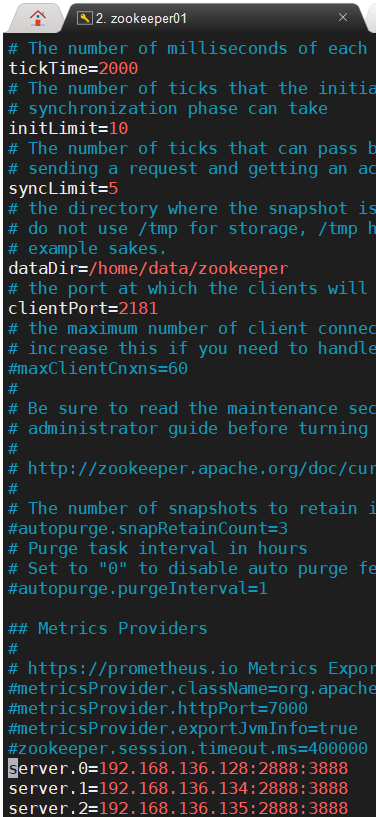
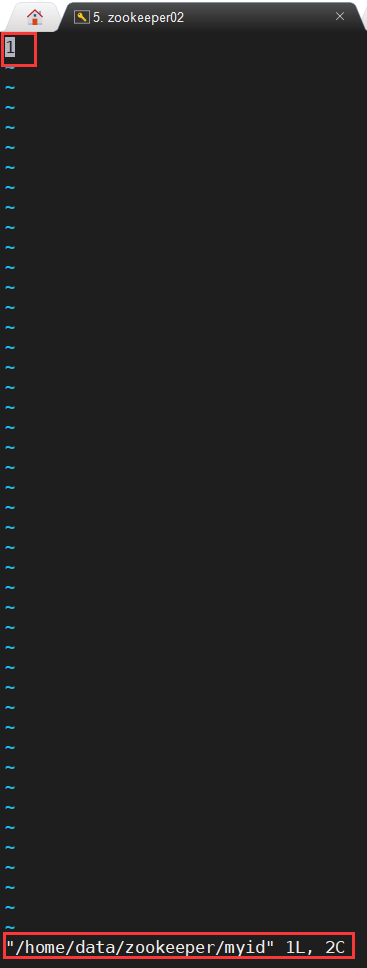
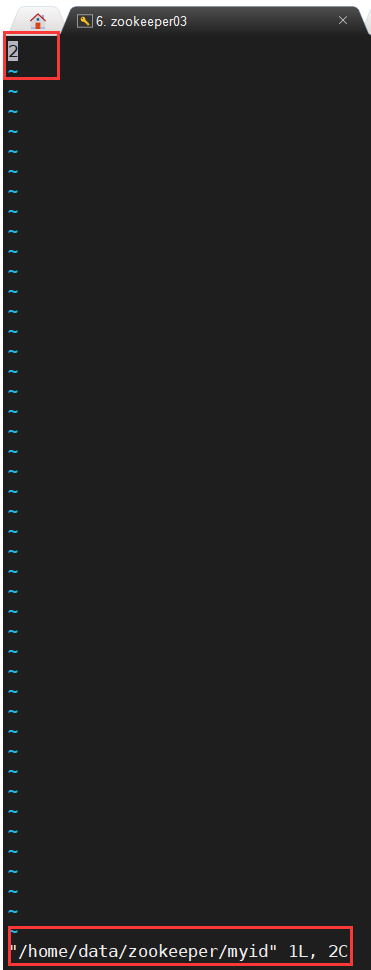
分布式启动
因为ZooKeeper没有提供启动集群的脚本,所以我们自己写了一个可以简单操作集群的脚本:
#!/bin/bash# 这是我hadoop的根目录zooKeeperHome="/opt/module/zookeeper-3.4.10/bin/zkServer.sh"# 遍历主机名for i in hadoop1 hadoop2 hadoop3doecho "-------$i--------"ssh $i $zooKeeperHome $1done
假设我要启动集群里各个机器:
[codeleven@hadoop1 bin]$ ./zkCluster.sh start
-------hadoop1--------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
-------hadoop2--------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
-------hadoop3--------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED

若有收获,就点个赞吧
0 人点赞
