伪集群分布是指跑在单实例上的多进程Hadoop。基本就是拿来测试用用的,根据官方文档搭建一下集群:
配置
$HADOOP_HOME/etc/hadoop/core-site.xml下的fs.defaultFS项,即一个实例的地址:<property><name>fs.defaultFS</name><!-- 自己实例的IP地址 --><value>hdfs://localhost:9000</value></property>
配置
core-site.xml下的hadoop.tmp.dir项,即数据保存地址:<property> <name>hadoop.tmp.dir</name> <value>/tmp/hadoop/data</value> </property>配置
hdfs-site.xml下的dfs.replication项,即备份数据:<property> <name>dfs.replication</name> <value>1</value> </property>测试访问自己是否需要密码:
ssh localhost如果需要密码,我们要配置当前实例的SSH密码,这样登录就不需要输入密码了:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys格式化
namenode(注意,初始化一遍过后就没必要再初始化了,除非想重置数据。如果想重置数据,初始化后还要删除datanode的数据)hdfs namenode -formatdaemon方式启动namenode和datanode:sbin/start-dfs.sh(默认情况下,启动日志输出到
$HADOOP_HOME/logs文件夹里;如果配置了$HADOOP_LOG_DIR环境变量,就输出到这个环境变量指定的文件夹里)启动了后,访问
http://localhost:9870/,登录成功后界面如下所示(HOST没有对应,大家自行对应一下):
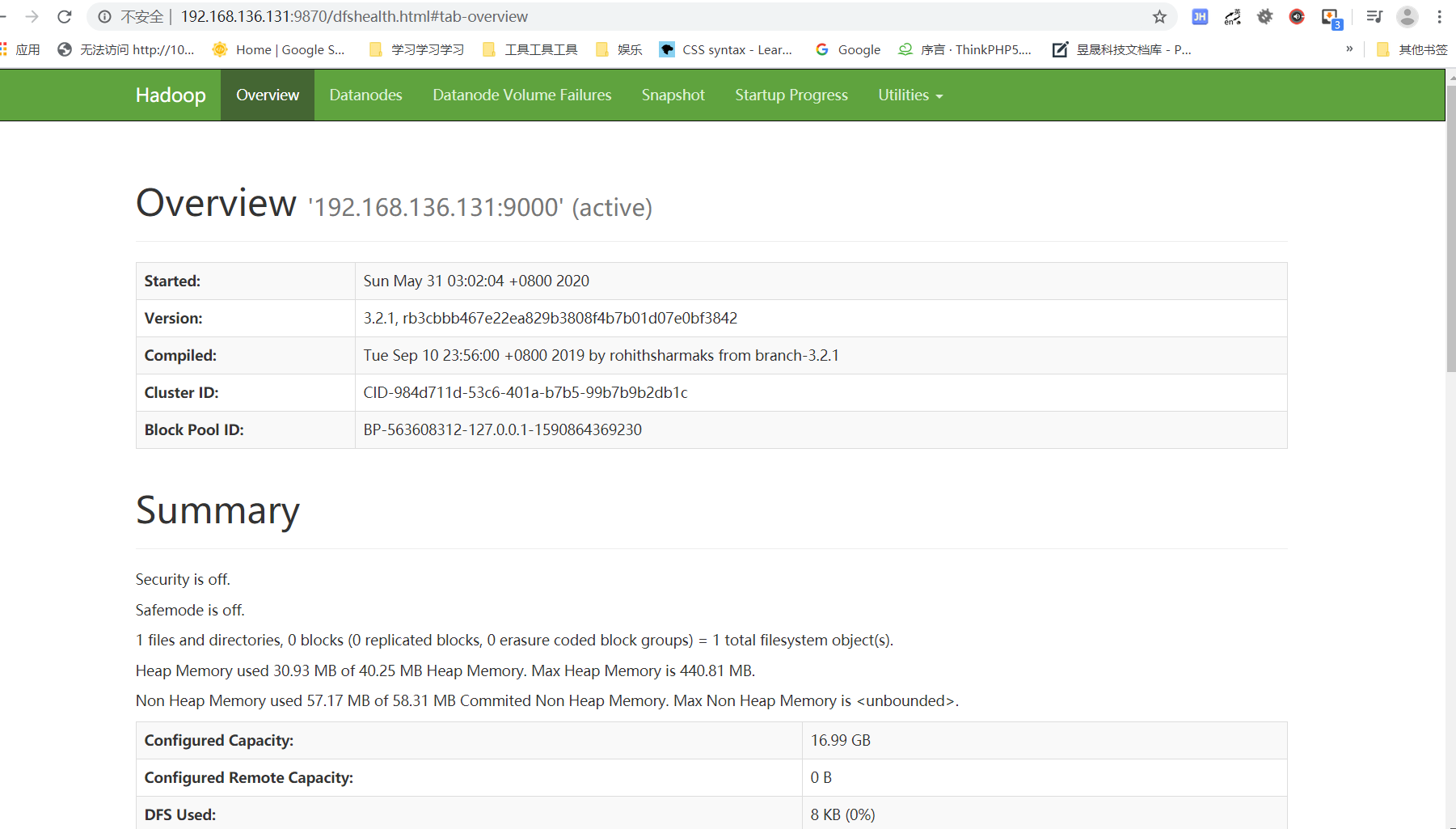
注意,如果开启了防火墙记得开放9870端口(学习阶段直接关闭好了);
如果遇到下面这种错误:
hadoop ERROR: Attempting to operate on hdfs namenode as root ERROR: but there is no HDFS_NAMENODE_US
给 start-dfs.sh 和 stop-dfs.sh 两个脚本文件添加:
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
关于hdfs的操作:
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/root
-mkdir,创建文件夹(注意只能一层一层来创建)
hdfs dfs -put etc/hadoop/*.xml /user/root
-put,将第一个参数etc/hadoop/*.xml放到/user/root文件夹下。这里要注意第一个参数是本地系统的路径、第二个参数是hdfs上的路径。完整的来说,第一个参数应该是file://etc/hadoop/*.xml,第二个参数应该是hdfs:///user/root。
该条指令执行后,我们的 hdfs:///user/root/ 目录下就包含了以下这些文件: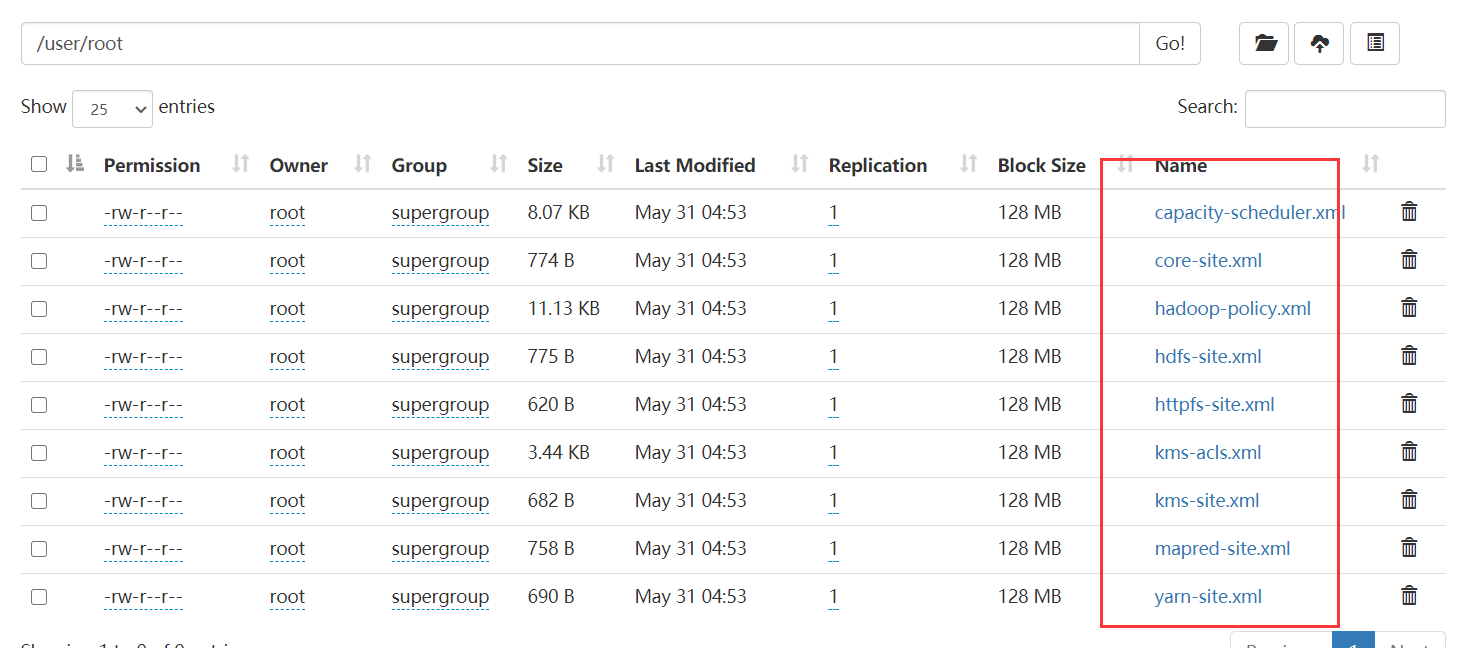
这说明文件已经放到了我们的 hdfs 上了。
如果此时执行下面这条指令查找 dfs[a-z.]+ 正则时:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'
它就是查找 hdfs:// 路径上的文件了,因为我们的配置里设置了 hdfs://
最后我们可以使用 hdfs dfs -get /output output 来获取 hdfs:///output 的数据并存到当前目录下的 output 目录里。
或者可以使用 hdfs dfs -cat /output/* 来查看 hdfs:///output 目录下的所有文件内容
注意, namenode 和 datanode 都维护了一个相同的 cluster id ,如果两个有任意一个不同,就会出问题。它们的 clusterID 必须保持一致, namenode 的 clusterID 在我们配置的 hadoop.tmp.dir/dfs/name/current/VERSION 下面; datanode 的 clusterID 在我们配置的 hadoop.tmp.dir/dfs/data/current/VERSION 下面。
所以如果要初始化 namenode ,记得要删除 datanode 。

若有收获,就点个赞吧
0 人点赞
