DML(data manipulation language)数据操纵语言:
主要是针对数据进行一些操作,比如经常用到的 SELECT、UPDATE、INSERT、DELETE。
一、加载文件数据到表
1.1 语法
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE]INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
LOCAL关键字代表从本地文件系统加载文件,省略则代表从 HDFS 上加载文件:- 从本地文件系统加载文件时,
filepath可以是绝对路径也可以是相对路径 (建议使用绝对路径); - 从 HDFS 加载文件时候,
filepath为文件完整的 URL 地址:如hdfs://namenode:port/user/hive/project/ data1 filepath可以是文件路径 (在这种情况下 Hive 会将文件移动到表中),也可以目录路径 (在这种情况下,Hive 会将该目录中的所有文件移动到表中);- 如果使用 OVERWRITE 关键字,则将删除目标表(或分区)的内容,使用新的数据填充;不使用此关键字,则数据以追加的方式加入;
- 加载的目标可以是表或分区。如果是分区表,则必须指定加载数据的分区;
- 加载文件的格式必须与建表时使用
STORED AS指定的存储格式相同。使用建议: 不论是本地路径还是 URL 都建议使用完整的。虽然可以使用不完整的 URL 地址,此时 Hive 将使用 hadoop 中的 fs.default.name 配置来推断地址,但是为避免不必要的错误,建议使用完整的本地路径或 URL 地址; 加载对象是分区表时建议显示指定分区。在 Hive 3.0 之后,内部将加载 (LOAD) 重写为 INSERT AS SELECT,此时如果不指定分区,INSERT AS SELECT 将假设最后一组列是分区列,如果该列不是表定义的分区,它将抛出错误。为避免错误,还是建议显示指定分区。
1.2 示例
-- 1.load--->Hive表load data local inpath 'path/file' into table 表名;(copy操作)oad data local inpath 'path/file' overwrite into table 表名; (有overwrite,则覆盖目标表)--2.HDFS--->Hive表load data inpath 'path/file' into table 表名;(move操作)load data local inpath 'path/file' overwrite into table 表名; (有overwrite,则覆盖目标表)--3.分区表a.分区存在,指定分区直接loadload data inpath '/user/hive/data/info.1503474550258.data' into table sms_send_reply partition(p_date='2017-10-12', p_operators='2');b. 分区不存在,先创建分区再put数据alter table track_log add partition (date='20150828');LOAD DATA INPATH "hdfs://hadoop001:8020/mydir/emp.txt" OVERWRITE INTO TABLE emp_ptn PARTITION (date='20150828');
二、查询结果插入到表
2.1 语法
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]]select_statement1 FROM from_statement;INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)]select_statement1 FROM from_statement;
- Hive 0.13.0 开始,建表时可以通过使用 TBLPROPERTIES(“immutable”=“true”)来创建不可变表 (immutable table) ,如果不可以变表中存在数据,则 INSERT INTO 失败。(注:INSERT OVERWRITE 的语句不受
immutable属性的影响); - 可以对表或分区执行插入操作。如果表已分区,则必须通过指定所有分区列的值来指定表的特定分区;
- 从 Hive 1.1.0 开始,TABLE 关键字是可选的;
- 从 Hive 1.2.0 开始 ,可以采用 INSERT INTO tablename(z,x,c1) 指明插入列;
- 可以将 SELECT 语句的查询结果插入多个表(或分区),称为多表插入。语法如下: ```plsql FROM from_statement INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 …) [IF NOT EXISTS]] select_statement1 [INSERT OVERWRITE TABLE tablename2 [PARTITION … [IF NOT EXISTS]] select_statement2] [INSERT INTO TABLE tablename2 [PARTITION …] select_statement2] …;
Hive还支持多表插入,在Hive中,我们可以把insert语句倒过来,把from放在最前面,它的执行效果和放在后面是一样的,如下: hive> from wyp
> insert into table test> partition(age)> select id, name, tel, age> insert into table test3> select id, name> where age>25;
等价于: insert into table test partition(age) select id, name, tel, age from wyp; insert into table test3 select id, name where age>25 from wyp; 可以在同一个查询中使用多个insert子句,这样的好处是我们只需要扫描一遍源表就可以生成多个不相交的输出。
<a name="S360t"></a>### 2.2 动态插入分区```plsqlINSERT OVERWRITE TABLE tablename PARTITION (partcol1[=val1], partcol2[=val2] ...)select_statement FROM from_statement;INSERT INTO TABLE tablename PARTITION (partcol1[=val1], partcol2[=val2] ...)select_statement FROM from_statement;
在向分区表插入数据时候,分区列名是必须的,但是列值是可选的。如果给出了分区列值,我们将其称为静态分区,否则它是动态分区。动态分区列必须在 SELECT 语句的列中最后指定,并且与它们在 PARTITION() 子句中出现的顺序相同。
注意:Hive 0.9.0 之前的版本动态分区插入是默认禁用的,而 0.9.0 之后的版本则默认启用。以下是动态分区的相关配置:
| 配置 | 默认值 | 说明 |
|---|---|---|
hive.exec.dynamic.partition |
true |
需要设置为 true 才能启用动态分区插入 |
hive.exec.dynamic.partition.mode |
strict |
在严格模式 (strict) 下,用户必须至少指定一个静态分区,以防用户意外覆盖所有分区,在非严格模式下,允许所有分区都是动态的 |
hive.exec.max.dynamic.partitions.pernode |
100 | 允许在每个 mapper/reducer 节点中创建的最大动态分区数 |
hive.exec.max.dynamic.partitions |
1000 | 允许总共创建的最大动态分区数 |
hive.exec.max.created.files |
100000 | 作业中所有 mapper/reducer 创建的 HDFS 文件的最大数量 |
hive.error.on.empty.partition |
false |
如果动态分区插入生成空结果,是否抛出异常 |
2.3 示例
- 新建 emp 表,作为查询对象表 ```plsql 无分区表: insert into(overwrite) table 表名 select * from emp; —追加(覆盖) 有分区表: i)动态分区插入 方式一: a.动态分区参数设置
SET hive.exec.dynamic.partition = true;//是否开启动态分区功能,默认false关闭。使用动态分区时候,该参数必须设置成true;
SET hive.exec.dynamic.partition.mode=nonstrict;
SET hive.exec.max.dynamic.partitions = 1000000;//参数指的是总共的最大的动态分区数
SET hive.exec.max.dynamic.partitions.pernode=100000;//参数指的是每个节点上能够生成的最大分区,这个在最坏情况下应该是跟最大分区一样的值
b.insert加载(注意:查询时需要加上分区字段)
INSERT INTO(OVERWRITE) table dw_order.order_info partition(p_date) select * from dw_order.order_info;
方式二:
alter创建分区
alter table dw_order.order_info add partition (date='20150828');
insert加载(注意:查询时不要加上分区字段)
INSERT INTO(OVERWRITE) table dw_order.order_info partition(p_date='20150828') select order_no,encoding(uid),mobile,operators,province_id,province_code,city_id,city_code,product_id,product_code,product_name,flow_size,tag_type,flow_type,order_mode,status,upper_id,upper_msg,upper_order_no,upper_fee,serial_no,invoker_id,invoker_order_no,invoker_fee,notify_url,api_source,api_version,comment,event_json,create_time,update_time,commit_time,success_time,recharge_code,channel,source from dw_order.order_info where p_date='20150828';
<a name="mithf"></a>
## 三、SQL行插入
```plsql
INSERT INTO TABLE tablename [PARTITION (partcol1[=val1], partcol2[=val2] ...)]
VALUES ( value [, value ...] )
- 使用时必须为表中的每个列都提供值。不支持只向部分列插入值(可以为缺省值的列提供空值来消除这个弊端);
- 如果目标表表支持 ACID 及其事务管理器,则插入后自动提交;
不支持支持复杂类型 (array, map, struct, union) 的插入。
四、更新和删除数据
4.1 语法
更新和删除的语法比较简单,和关系型数据库一致。需要注意的是这两个操作都只能在支持 ACID 的表,也就是事务表上才能执行。
-- 更新 UPDATE tablename SET column = value [, column = value ...] [WHERE expression] --删除 DELETE FROM tablename [WHERE expression]4.2 示例
1. 修改配置,开启事务支持
首先需要更改hive-site.xml,添加如下配置,开启事务支持,配置完成后需要重启 Hive 服务。<property> <name>hive.support.concurrency</name> <value>true</value> </property> <property> <name>hive.enforce.bucketing</name> <value>true</value> </property> <property> <name>hive.exec.dynamic.partition.mode</name> <value>nonstrict</value> </property> <property> <name>hive.txn.manager</name> <value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value> </property> <property> <name>hive.compactor.initiator.on</name> <value>true</value> </property> <property> <name>hive.in.test</name> <value>true</value> </property>2. 创建测试表
创建用于测试的事务表,建表时候指定属性transactional = true则代表该表是事务表。需要注意的是,按照官方文档 的说明,目前 Hive 中的事务表有以下限制:必须是 buckets Table;
- 仅支持 ORC 文件格式;
不支持 LOAD DATA …语句。
CREATE TABLE emp_ts( empno int, ename String ) CLUSTERED BY (empno) INTO 2 BUCKETS STORED AS ORC TBLPROPERTIES ("transactional"="true");3. 插入测试数据
INSERT INTO TABLE emp_ts VALUES (1,"ming"),(2,"hong");插入数据依靠的是 MapReduce 作业,执行成功后数据如下:
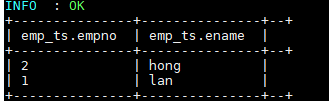
4. 测试更新和删除--更新数据 UPDATE emp_ts SET ename = "lan" WHERE empno=1; --删除数据 DELETE FROM emp_ts WHERE empno=2;更新和删除数据依靠的也是 MapReduce 作业,执行成功后数据如下:

五、查询结果导出
5.1 语法
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 [ROW FORMAT row_format] [STORED AS file_format] SELECT ... FROM ...OVERWRITE 关键字表示输出文件存在时,先删除后再重新写入;
- 和 Load 语句一样,建议无论是本地路径还是 URL 地址都使用完整的;
- 写入文件系统的数据被序列化为文本,其中列默认由^A 分隔,行由换行符分隔。如果列不是基本类型,则将其序列化为 JSON 格式。其中行分隔符不允许自定义,但列分隔符可以自定义;
- 列分隔符,可以通过fields terminated by指定分割符
5.2 示例
这里我们将上面创建的emp_ptn表导出到本地文件系统,语句如下: ```plsql — 1 导出到本地文件系统 insert overwrite local directory ‘/home/wyp/wyp’ select from wyp; — 2.导出到HDFS INSERT overwrite directory “/user/yaochengzong/tmp/dttag/count/“ ROW format delimited fields terminated BY “\t” SELECT FROM wyp; —3 导出到Hive表 insert into table test partition (age=’25’) select id, name, tel from wyp;
参考资料

若有收获,就点个赞吧
0 人点赞
