一、数据准备
1.1 建表
-- 建表语句CREATE TABLE emp_a(id string,name string);CREATE TABLE emp_b(id string,age int);
1.2 加载测试数据
hive> select * from emp_a;1 zhangsan2 lisi3 wangwuhive> select * from emp_b;1 302 294 21
二、单表查询
2.1 SELECT
-- 查询表中全部数据SELECT * FROM emp;
2.2 WHERE
-- 查询 10 号部门中员工编号大于 7782 的员工信息SELECT * FROM emp WHERE empno > 7782 AND deptno = 10;
2.3 DISTINCT
Hive 支持使用 DISTINCT 关键字去重。
-- 查询所有工作类型SELECT DISTINCT job FROM emp;
2.4 分区查询
分区查询 (Partition Based Queries),可以指定某个分区或者分区范围。
-- 查询分区表中部门编号在[20,40]之间的员工SELECT emp_ptn.* FROM emp_ptnWHERE emp_ptn.deptno >= 20 AND emp_ptn.deptno <= 40;
2.5 LIMIT
-- 查询薪资最高的 5 名员工SELECT * FROM emp ORDER BY sal DESC LIMIT 5;
2.6 GROUP BY
Hive 支持使用 GROUP BY 进行分组聚合操作。
select col1 [,col2] ,count(1),sel_expr(聚合操作)from tablewhere condition -->Map端执行group by col1 [,col2] -->Reduce端执行[having] -->Reduce端执行从表中读取数据,执行where条件,以col1列分组,把col列的内容作为key,其他列值作为value,上传到reduce,在reduce端执行聚合操作和having过滤。-- 查询各个部门薪酬综合SELECT deptno,SUM(sal) FROM emp GROUP BY deptno;
【注】
- group by中不能使用当前层次中select查询字段的别名,如:select name a,count(*) from student group by a;
- select后面非聚合列,必须出现在group by中。
- group by后面也可以跟表达式,比如substr(col)。
特性 使用了reduce操作,受限于reduce数量,设置reduce参数mapred.reduce.tasks 输出文件个数与reduce数相同,文件大小与reduce处理的数据量有关。 问题 网络负载过重 数据倾斜,优化参数hive.groupby.skewindata为true,会启动一个优化程序,避免数据倾斜。
2.7 ORDER BY AND SORT BY 排序
可以使用 ORDER BY 或者 Sort BY 对查询结果进行排序,排序字段可以是整型也可以是字符串:如果是整型,则按照大小排序;如果是字符串,则按照字典序排序。
order by 全局排序输出
select col1,other...from tablewhere conditioorder by col1,col2 [asc|desc]从表中读取数据,执行where条件,以col1,col2列的值做成组合key,其他列值作为value,然后在把数据传到同一个reduce中,根据需要的排序方式进行。-- 查询员工工资,结果按照部门升序,按照工资降序排列SELECT empno, deptno, sal FROM emp ORDER BY deptno ASC, sal DESC;
【注】
- order by后面可以有多列进行排序,默认按字典排序
- order by为全局排序
- order by需要reduce操作,且只有一个reduce,与配置无关。数据量很大时,慎用。
sort by 同一reduce排序输出
sort by col – 按照col列把数据排序:select col1,col2 from Mdistribute by col1sort by col1 asc,col2 desc
【注】
- sort by只能保证在同一个reduce中的数据可以按指定字段排序。使用sort by 你可以指定执行的reduce个数 (set mapreduce.job.reduce=50)。
【总结】
ORDER BY 和 SORT BY 的区别如下:
- 使用 ORDER BY 时会有一个 Reducer 对全部查询结果进行排序,可以保证数据的全局有序性;
- 使用 SORT BY 时只会在每个 Reducer 中进行排序,这可以保证每个 Reducer 的输出数据是有序的,但不能保证全局有序。
由于 ORDER BY 的时间可能很长,如果你设置了严格模式 (hive.mapred.mode = strict),则其后面必须再跟一个
limit子句。 注 :hive.mapred.mode 默认值是 nonstrict ,也就是非严格模式。
2.8 HAVING
可以使用 HAVING 对分组数据进行过滤。
-- 查询工资总和大于 9000 的所有部门SELECT deptno,SUM(sal) FROM emp GROUP BY deptno HAVING SUM(sal)>9000;
2.9 DISTRIBUTE BY
默认情况下,MapReduce 程序会对 Map 输出结果的 Key 值进行散列,并均匀分发到所有 Reducer 上。如果想要把具有相同 Key 值的数据分发到同一个 Reducer 进行处理,这就需要使用 DISTRIBUTE BY 字句。
需要注意的是,DISTRIBUTE BY 虽然能保证具有相同 Key 值的数据分发到同一个 Reducer,但是不能保证数据在 Reducer 上是有序的。情况如下:
把以下 5 个数据发送到两个 Reducer 上进行处理:
k1k2k4k3k1
Reducer1 得到如下乱序数据:
k1k2k1
Reducer2 得到数据如下:
k4k3
如果想让 Reducer 上的数据时有序的,可以结合 SORT BY 使用 (示例如下),或者使用下面我们将要介绍的 CLUSTER BY。
-- 将数据按照部门分发到对应的 Reducer 上处理SELECT empno, deptno, sal FROM emp DISTRIBUTE BY deptno SORT BY deptno ASC;
【总结】
distribute by与group by对比
都是按key值划分数据
都使用reduce操作
唯一不同的是distribute by只是单纯的分散数据,而group by把相同key的数据聚集到一起,后续必须是聚合操作。order by与sort by 对比
order by是全局排序
sort by只是确保每个reduce上面输出的数据有序。如果只有一个reduce时,和order by作用一样。
2.10 CLUSTER BY
如果 SORT BY 和 DISTRIBUTE BY 指定的是相同字段,且 SORT BY 排序规则是 ASC,此时可以使用 CLUSTER BY 进行替换,同时 CLUSTER BY 可以保证数据在全局是有序的。
SELECT empno, deptno, sal FROM emp DISTRIBUTE BY deptno SORT BY deptno ASC;-- 等价于SELECT empno, deptno, sal FROM emp CLUSTER BY deptno ;
补充: Hive去重
在hive数据清洗中有三种常用的去重方式
1.distinct
--两个字段去重,distinct放在后一个字段前select id, distinct content from tmp_tb;结果出现错误提示:FAILED: ParseException line 1:11 cannot recognize input near'distinct' 'content' 'from' in selection target--正确写法:select distinct id, content from tmp_tb;
结论:
当选择两个字段时,如果将distinct放在前一个字段之前,则会返回对两个字段的组合去重后的结果,即distinct同时作用于两个字段;而如果将distinct放在后一个字段之前,则有语法错误。
2.group by
3.row_number()
SET hive.auto.convert.join=TRUE;SET hive.exec.dynamic.partition = true;SET hive.exec.dynamic.partition.mode=nonstrict;SET hive.output.file.extension=_dpi_zj.avro; //文件名扩展SET hive.exec.max.dynamic.partitions = 1000000;SET hive.exec.max.dynamic.partitions.pernode=100000;set mapred.max.split.size=256000000;set mapred.min.split.size.per.node=100000000;set mapred.min.split.size.per.rack=100000000;set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;set hive.merge.mapfiles = true;set hive.merge.mapredfiles = true;set hive.merge.size.per.task = 256000000;set hive.merge.smallfiles.avgsize=256000000;INSERT overwrite TABLE etl_fetch.`828_dpi_result` PARTITION (p_biz,p_date)SELECT t.phone_number,t.uid,t.host_freq,t.biz_code,t.log_date,t.get_time,t.city_code,t.p_biz,t.p_dateFROM(SELECT *,row_number() over (partition BY concat(p_biz,p_date,uid) //注意分组条件,唯一性ORDER BY get_time ASC) numFROM etl_fetch.`828_dpi_result`WHERE p_date='20190107' or p_date='20190117' or p_date='20190207') tWHERE t.num=1;--上面SQL对字段(send_time)排序后拼接分区字段(p_biz,p_date,uid)去重,注意加t.num=1过滤条件,这样便可实现对重复数据过滤提取。
模板:SELECT t. from (SELECT a., row_number() over(PARTITION BY COL1 ORDER BY COL2 ASC) num from a) t WHERE t.num=1;
row_number() OVER (PARTITION BY COL1 ORDERBY COL2) 表示根据COL1分组,在分组内部根据 COL2排序,而此函数计算的值就表示每组内部排序后的顺序编号(该编号在组内是连续并且唯一的) 。
三、多表联结查询
Hive 支持内连接,外连接,左外连接,右外连接,笛卡尔连接,这和传统数据库中的概念是一致的,可以参见下图。
需要特别强调:JOIN 语句的关联条件必须用 ON 指定,不能用 WHERE 指定,否则就会先做笛卡尔积,再过滤,这会导致你得不到预期的结果 (下面的演示会有说明)。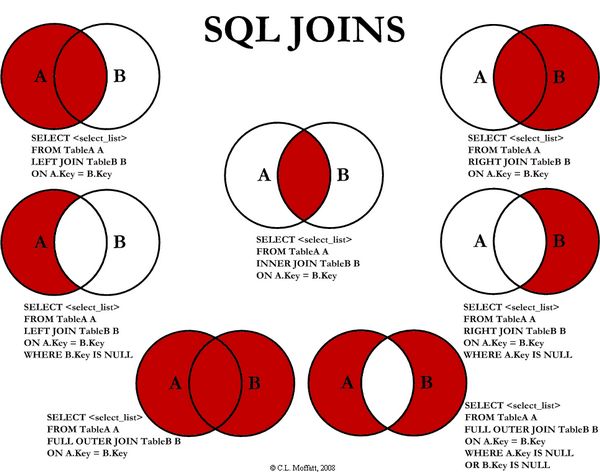
3.1 内连接( [INNER] JOIN)
(INNER) JOIN 内连接,只返回能关联上的结果。
SELECT a.id,a.name,b.ageFROM emp_a ajoin emp_b bON (a.id = b.id);--执行结果1 zhangsan 302 lisi 29
3.2 左外连接(LEFT [OUTER] JOIN)
以LEFT [OUTER] JOIN关键字前面的表(左表)作为主表,和其他表进行关联,返回记录和主表的记录数一致,关联不上的字段置为NULL。是否指定OUTER关键字,对查询结果无影响。
SELECT a.id,a.name,b.ageFROM emp_a aleft join emp_b bON (a.id = b.id);--执行结果:1 zhangsan 302 lisi 293 wangwu NULL
3.3 右外连接(RIGHT [OUTER] JOIN)
和左外关联相反,以RIGTH [OUTER] JOIN关键词后面的表(右表)作为主表,和前面的表做关联,返回记录数和主表一致,关联不上的字段为NULL。是否指定OUTER关键字,对查询结果无影响。
SELECT a.id,a.name,b.ageFROM emp_a aRIGHT OUTER JOIN emp_b bON (a.id = b.id);--执行结果:1 zhangsan 302 lisi 29NULL NULL 21
3.5 全外连接(FULL [OUTER] JOIN)
以两个表的记录为基准,返回两个表的记录去重之和,关联不上的字段为NULL。是否指定OUTER关键字,对查询结果无影响。
注意:FULL JOIN时候,Hive不会使用MapJoin来优化。
SELECT a.id,a.name,b.ageFROM emp_a aFULL OUTER JOIN emp_b bON (a.id = b.id);--执行结果:1 zhangsan 302 lisi 293 wangwu NULLNULL NULL 21
3.5 LEFT SEMI JOIN
LEFT SEMI JOIN (左半连接)是 IN/EXISTS 子查询的一种更高效的实现。以LEFT SEMI JOIN关键字前面的表为主表,返回主表的KEY也在副表中的记录。但需注意:
- JOIN 子句中右边的表只能在 ON 子句中设置过滤条件;
- 查询结果只包含左边表的数据,所以只能 SELECT 左表中的列。 ```plsql SELECT a.id, a.name FROM emp_a a LEFT SEMI JOIN emp_b b ON (a.id = b.id);
—执行结果: 1 zhangsan 2 lisi
—等价于: 1.IN子查询 SELECT a.id, a.name FROM emp_a a WHERE a.id IN (SELECT id FROM emp_b);
2.内连接 SELECT a.id, a.name FROM emp_a a join emp_b b ON (a.id = b.id);
3.EXISTS 子查询 SELECT a.id, a.name FROM emp_a a WHERE EXISTS (SELECT 1 FROM emp_b b WHERE a.id = b.id);
<a name="YNO6k"></a>### 3.6 **笛卡尔积([CROSS] JOIN)**笛卡尔积连接,返回两个表的笛卡尔积结果,不需要指定关联键。笛卡尔积性能消耗比较大,慎用。基于这个原因,如果在严格模式下 (hive.mapred.mode = strict),Hive 会阻止用户执行此操作。```plsqlSELECT a.id,a.name,b.ageFROM emp_a aCROSS JOIN emp_b b;--执行结果:1 zhangsan 301 zhangsan 291 zhangsan 212 lisi 302 lisi 292 lisi 213 wangwu 303 wangwu 293 wangwu 21
总结:
1.Hive支持通常的SQL JOIN语句,但是只支持等值连接。同时Hive目前还不支持on字句中使用or
hive不支持on or解决办法:UNION ALL合并表
2.hive sql join on中的链接字段必须一致。类型不一致时,使用cast函数将类型转换为一致。eg:cast(b.id as STRING) (参见:hive sql join 时字段类型不一致问题)
select * from (SELECT * FROM dw_sms.sms_status WHERE p_date>='2019-05-01') AS aINNER JOIN bigdata_dev_dashuju.t2_record_sms_send_id b ON (a.sms_id=cast(b.id as STRING));
3.left/right join,为保证输出基表(左连接为左表,右连接为右表)**所有行, 因此 on里的条件只对副表起过滤作用,控制基表的条件写到这里也没用。**基表不会根据on中and的过滤条件来过滤数据,可以通过在后面再增加where语句来实现过滤的功能。(参见:[Left join的on后条件不起作用的原因](https://blog.csdn.net/spw55381155/article/details/89638558))
-- 数据准备hive> select * from tab1;id size1 102 203 30hive> select * from tab2;size name10 AAA20 BBB20 CCC--两条SQL:select * form tab1 left join tab2 on (tab1.size = tab2.size) where tab2.name=’AAA’;select * form tab1 left join tab2 on (tab1.size = tab2.size and tab2.name=’AAA’);
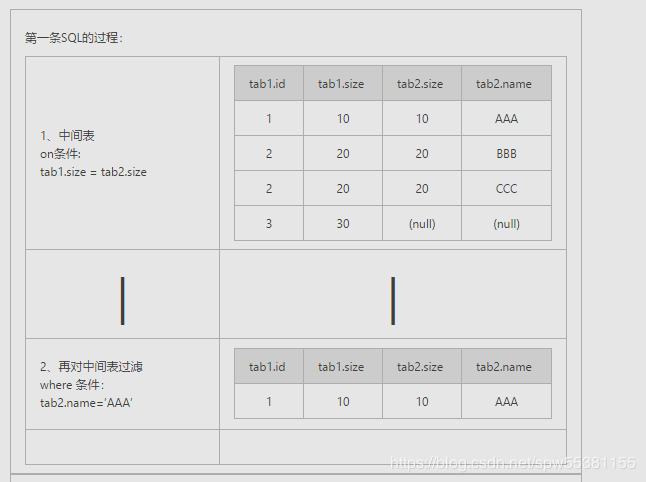
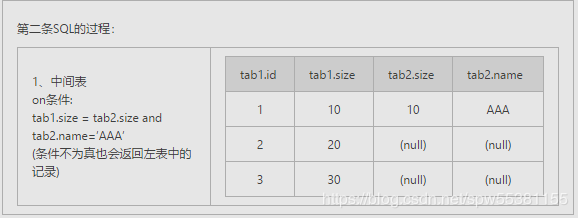
在使用left[rigt] jion时,on和where条件的区别如下:
1、 on条件是在生成临时表时使用的条件,它不管on中的条件是否为真,都会返回左边表中的记录。
2、where条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有left[rigt] join的含义(必须返回基表的记录)了,条件不为真的就全部过滤掉。
其实以上结果的关键原因就是left join,right join,full join的特殊性,不管on上的条件是否为真都会返回left或right表中的记录,full则具有left和right的特性的并集。 而inner jion没这个特殊性,则条件放在on中和where中,返回的结果集是相同的。
四、Hive中Join的原理和机制
笼统的说,Hive中的Join可分为Common Join(Reduce阶段完成join)和Map Join(Map阶段完成join)。本文简单介绍一下两种join的原理和机制。
4.1 Hive Common Join
如果不指定MapJoin或者不符合MapJoin的条件,那么Hive解析器会将Join操作转换成Common Join。即:在Reduce阶段完成join.
整个过程包含Map、Shuffle、Reduce阶段。
- Map阶段
读取源表的数据,Map输出时候以Join on条件中的列为key,如果Join有多个关联键,则以这些关联键的组合作为key;
Map输出的value为join之后所关心的(select或者where中需要用到的)列;同时在value中还会包含表的Tag信息,用于标明此value对应哪个表;
按照key进行排序
- Shuffle阶段
根据key的值进行hash,并将key/value按照hash值推送至不同的reduce中,这样确保两个表中相同的key位于同一个reduce中
- Reduce阶段
根据key的值完成join操作,期间通过Tag来识别不同表中的数据。
以下面的HQL为例,图解其过程:
SELECTa.id,a.dept,b.ageFROM a join bON (a.id = b.id);
看了这个图,应该知道如何使用MapReduce进行join操作了吧。
4.2 Hive Map Join
MapJoin通常用于一个很小的表和一个大表进行join的场景。具体小表有多小,由参数hive.mapjoin.smalltable.filesize来决定,该参数表示小表的总大小,默认值为25000000字节,即25M。Hive0.7之前,需要使用hint提示 /+ mapjoin(table) /才会执行MapJoin,否则执行Common Join,但在0.7版本之后,默认自动会转换Map Join,由参数hive.auto.convert.join来控制,默认为true。
仍然以9.1中的HQL来说吧,假设a表为一张大表,b为小表,并且hive.auto.convert.join=true,那么Hive在执行时候会自动转化为MapJoin。
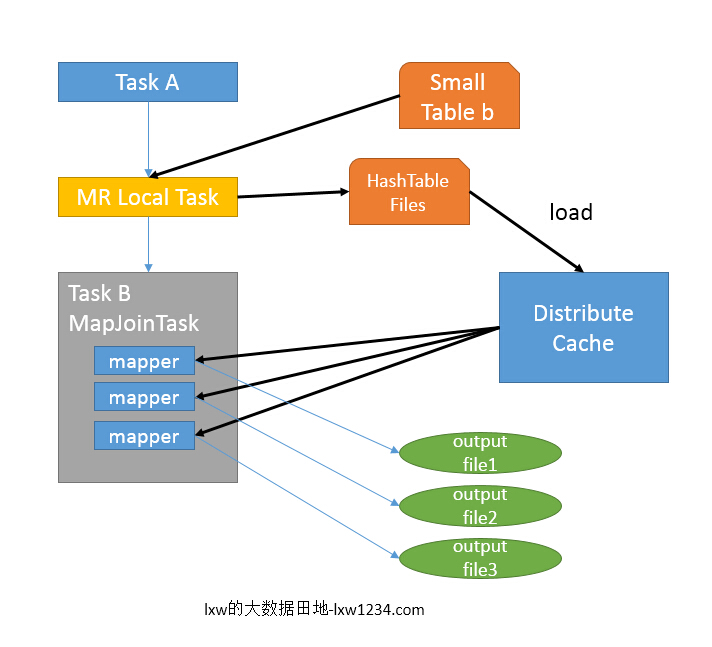
- 如图中的流程,首先是Task A,它是一个Local Task(在客户端本地执行的Task),负责扫描小表b的数据,将其转换成一个HashTable的数据结构,并写入本地的文件中,之后将该文件加载到DistributeCache中,该HashTable的数据结构可以抽象为:
| key | value |
|---|---|
| 1 | 26 |
| 2 | 34 |

图中红框圈出了执行Local Task的信息。
- 接下来是Task B,该任务是一个没有Reduce的MR,启动MapTasks扫描大表a,在Map阶段,根据a的每一条记录去和DistributeCache中b表对应的HashTable关联,并直接输出结果。
- 由于MapJoin没有Reduce,所以由Map直接输出结果文件,有多少个Map Task,就有多少个结果文件。
五、UNION 多表联接
UNION 用于将来自多个 SELECT 语句的结果合并为一个结果集。 ```plsql 语法: select_statement UNION [ALL | DISTINCT] select_statement UNION [ALL | DISTINCT] select_statement …
示例: select col from( select a as col from t1 union all select b as col from t2 )tmp
注意:- [1.2.0](https://issues.apache.org/jira/browse/HIVE-9039)之前的 Hive 版本仅支持 UNION ALL,其中不会消除重复的行。- **这里需要特别注意,****每个select语句返回的列的数量和名字必须一样,同时字段类型必须完全匹配****,否则会抛出语法错误。**```plsqlunion all必须满足如下要求字段名字一样字段类型一样字段个数一样子表不能有别名如果需要从合并之后的表中查询数据,那么合并的表必须要有别名select * from (select * from munion allselect * from n)temp;如果两张表的字段名不一样,要将一个表修改别名同另一个表的字段名一样。select * from (select col1,col2 from munion allselect col1,col3 as col2 from n)temp;
六、本地模式
在上面演示的语句中,大多数都会触发 MapReduce, 少部分不会触发,比如 select * from emp limit 5 就不会触发 MR,此时 Hive 只是简单的读取数据文件中的内容,然后格式化后进行输出。在需要执行 MapReduce 的查询中,你会发现执行时间可能会很长,这时候你可以选择开启本地模式。
--本地模式默认关闭,需要手动开启此功能SET hive.exec.mode.local.auto=true;
启用后,Hive 将分析查询中每个 map-reduce 作业的大小,如果满足以下条件,则可以在本地运行它:
- 作业的总输入大小低于:hive.exec.mode.local.auto.inputbytes.max(默认为 128MB);
- map-tasks 的总数小于:hive.exec.mode.local.auto.tasks.max(默认为 4);
- 所需的 reduce 任务总数为 1 或 0。
因为我们测试的数据集很小,所以你再次去执行上面涉及 MR 操作的查询,你会发现速度会有显著的提升。
参考资料
- LanguageManual Select
- LanguageManual Joins
- LanguageManual GroupBy
- LanguageManual SortBy
- Hive数据查询详解
- Hive中Join的原理和机制
- .Hive中Join的类型和用法

若有收获,就点个赞吧
0 人点赞
