一、Hive CLI
1.1 Help
1.2 交互式命令行
1.3 执行SQL命令
1.4 执行SQL脚本
1.5 配置Hive变量
1.6 配置文件启动
1.7 用户自定义变量
二、Beeline
2.1 HiveServer2
2.1 Beeline
2.3 常用参数
三、Hive配置
3.1 配置文件
3.2 hiveconf
3.3 set
3.4 配置优先级
3.5 配置参数
一、Hive CLI
1.1 Help
使用 hive -H 或者 hive --help 命令可以查看所有命令的帮助,显示如下:
usage: hive-d,--define <key=value> Variable subsitution to apply to hivecommands. e.g. -d A=B or --define A=B --定义用户自定义变量--database <databasename> Specify the database to use -- 指定使用的数据库-e <quoted-query-string> SQL from command line -- 执行指定的 SQL-f <filename> SQL from files --执行 SQL 脚本-H,--help Print help information -- 打印帮助信息--hiveconf <property=value> Use value for given property --自定义配置--hivevar <key=value> Variable subsitution to apply to hive --自定义变量commands. e.g. --hivevar A=B-i <filename> Initialization SQL file --在进入交互模式之前运行初始化脚本-S,--silent Silent mode in interactive shell --静默模式-v,--verbose Verbose mode (echo executed SQL to the console) --详细模式
1.2 交互式命令行
直接使用 Hive 命令,不加任何参数,即可进入交互式命令行。
1.3 执行SQL命令
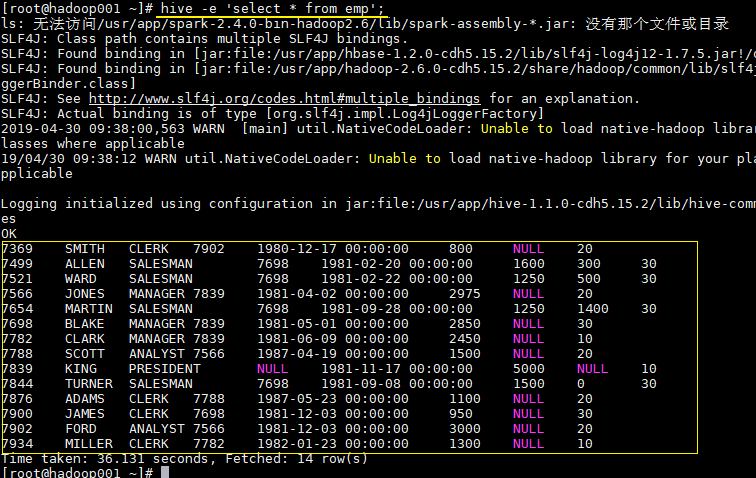
在不进入交互式命令行的情况下,可以使用 hive -e执行 SQL 命令。
hive -e 'select * from emp';
1.4 执行SQL脚本
用于执行的 sql 脚本可以在本地文件系统,也可以在 HDFS 上。
# 本地文件系统
hive -f /usr/file/simple.sql;
# HDFS文件系统
hive -f hdfs://hadoop001:8020/tmp/simple.sql;
其中 simple.sql 内容如下:
select * from emp;
1.5 配置Hive变量
可以使用 --hiveconf 设置 Hive 运行时的变量。
hive -e 'select * from emp' \
--hiveconf hive.exec.scratchdir=/tmp/hive_scratch \
--hiveconf mapred.reduce.tasks=4;
hive.exec.scratchdir:指定 HDFS 上目录位置,用于存储不同 map/reduce 阶段的执行计划和这些阶段的中间输出结果。
1.6 配置文件启动
使用 -i 可以在进入交互模式之前运行初始化脚本,相当于指定配置文件启动。
hive -i /usr/file/hive-init.conf;
其中 hive-init.conf 的内容如下:
set hive.exec.mode.local.auto = true;
hive.exec.mode.local.auto 默认值为 false,这里设置为 true ,代表开启本地模式。
1.7 用户自定义变量
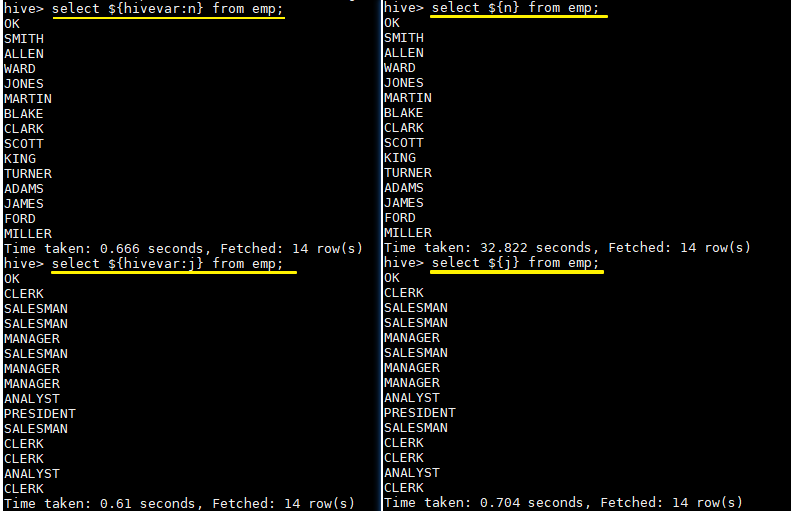
--define <key=value>和 --hivevar <key=value>在功能上是等价的,都是用来实现自定义变量,这里给出一个示例:
定义变量:
hive --define n=ename --hiveconf --hivevar j=job;
在查询中引用自定义变量:
# 以下两条语句等价
hive > select ${n} from emp;
hive > select ${hivevar:n} from emp;
# 以下两条语句等价
hive > select ${j} from emp;
hive > select ${hivevar:j} from emp;
二、Beeline
2.1 HiveServer2
Hive 内置了 HiveServer 和 HiveServer2 服务,两者都允许客户端使用多种编程语言进行连接,但是 HiveServer 不能处理多个客户端的并发请求,所以产生了 HiveServer2。
HiveServer2(HS2)允许远程客户端可以使用各种编程语言向 Hive 提交请求并检索结果,支持多客户端并发访问和身份验证。HS2 是由多个服务组成的单个进程,其包括基于 Thrift 的 Hive 服务(TCP 或 HTTP)和用于 Web UI 的 Jetty Web 服务器。
HiveServer2 拥有自己的 CLI(Beeline),Beeline 是一个基于 SQLLine 的 JDBC 客户端。由于 HiveServer2 是 Hive 开发维护的重点 (Hive0.15 后就不再支持 hiveserver),所以 Hive CLI 已经不推荐使用了,官方更加推荐使用 Beeline。
2.2 Beeline 常用参数
Beeline 拥有更多可使用参数,可以使用 beeline --help 查看。
在 Hive CLI 中支持的参数,Beeline 都支持,常用的参数如下。更多参数说明可以参见官方文档 Beeline Command Options
| 参数 | 说明 |
|---|---|
| -u |
数据库地址 |
| -n |
用户名 |
| -p |
密码 |
| -d |
驱动 (可选) |
| -e |
执行 SQL 命令 |
| -f |
执行 SQL 脚本 |
| -i (or)—init |
在进入交互模式之前运行初始化脚本 |
| —property-file |
指定配置文件 |
| —hiveconf property=value | 指定配置属性 |
| —hivevar name=value | 用户自定义属性,在会话级别有效 |
示例: 使用用户名和密码连接 Hive
_$ _beeline -u jdbc:hive2://localhost:10000 -n username -p password
三、Hive配置
可以通过三种方式对 Hive 的相关属性进行配置,分别介绍如下:
3.1 配置文件
方式一为使用配置文件,使用配置文件指定的配置是永久有效的。Hive 有以下三个可选的配置文件:
- hive-site.xml :Hive 的主要配置文件;
- hivemetastore-site.xml: 关于元数据的配置;
- hiveserver2-site.xml:关于 HiveServer2 的配置。
示例如下,在 hive-site.xml 配置 hive.exec.scratchdir:
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/mydir</value>
<description>Scratch space for Hive jobs</description>
</property>
3.2 hiveconf
方式二为在启动命令行 (Hive CLI / Beeline) 的时候使用 --hiveconf 指定配置,这种方式指定的配置作用于整个 Session。
hive --hiveconf hive.exec.scratchdir=/tmp/mydir
3.3 set
方式三为在交互式环境下 (Hive CLI / Beeline),使用 set 命令指定。这种设置的作用范围也是 Session 级别的,配置对于执行该命令后的所有命令生效。set 兼具设置参数和查看参数的功能。如下:
0: jdbc:hive2://hadoop001:10000> set hive.exec.scratchdir=/tmp/mydir;
No rows affected (0.025 seconds)
0: jdbc:hive2://hadoop001:10000> set hive.exec.scratchdir;
+----------------------------------+--+
| set |
+----------------------------------+--+
| hive.exec.scratchdir=/tmp/mydir |
+----------------------------------+--+
3.4 配置优先级
配置的优先顺序如下 (由低到高):hive-site.xml - >hivemetastore-site.xml- > hiveserver2-site.xml - >-- hiveconf- > set
3.5 配置参数
Hive 可选的配置参数非常多,在用到时查阅官方文档即可AdminManual Configuration
四、Hive常见参数配置方式
4.1.配置文件
在Hive中,所有的默认配置都在${HIVE_HOME}/conf/hive-default.xml文件中,如果需要对默认的配置进行修改,可以创建一个hive-site.xml文件,放在${HIVE_HOME}/conf目录下。里面可以对一些配置进行个性化设定。在这里做的配置都全局用户都生效,而且是永久的。用户自定义配置会覆盖默认配置。另外,Hive也会读入Hadoop的配置,因为Hive是作为Hadoop的客户端启动的,Hive的配置会覆盖Hadoop的配置。
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of
default database for the warehouse</description>
</property>
</configuration>
4.2.启动Hive cli的时候进行参数配置
在启动Hive cli的时候进行配置,可以在命令行添加-hiveconf param=value来设定参数。这种设置只对本次启动的会话有效,下次启动需要重新配置
[wuql@master ~]$ hive --hiveconf mapreduce.job.queuename=queue1
4.3.登陆cli客户端后进行参数设置
在已经进入cli时进行参数声明,可以在HQL中使用SET关键字设定参数。这种设置只对本次启动的会话有效,下次启动需要重新配置
hive> set mapreduce.job.queuename=queue1;
总结:
上述三种设定方式的优先级依次递增。即参数声明覆盖命令行参数,命令行参数覆盖配置文件设定。
注意:某些系统级的参数,例如log4j相关的设定,必须用前两种方式设定,因为那些参数的读取在会话建立以前已经完成了。所以在HQL中设定是无效的。这个特列可以参见本博客《Hive日志调试》进行了解。
五、Hive常用参数
5.1.hive merge小文件
当Hive输入由很多个小文件组成,由于每个小文件都会启动一个map任务,如果文件过小,以至于map任务启动和初始化的时间大于逻辑处理的时间,会造成资源浪费,甚至OOM。 为此,当我们启动一个任务,发现输入数据量小但任务数量多时,需要注意在Map前端进行输入合并 当然,在我们向一个表写数据时,也需要注意输出文件大小
1. Map输入合并小文件
对应参数:
set mapred.max.split.size=256000000; #每个Map最大输入大小
set mapred.min.split.size.per.node=100000000; #一个节点上split的至少的大小
set mapred.min.split.size.per.rack=100000000; #一个交换机下split的至少的大小
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; #执行Map前进行小文件合并
注:
- 在开启了org.apache.hadoop.hive.ql.io.CombineHiveInputFormat后,一个data node节点上多个小文件会进行合并,合并文件数由mapred.max.split.size限制的大小决定。
- mapred.min.split.size.per.node决定了多个data node上的文件是否需要合并~
- mapred.min.split.size.per.rack决定了多个交换机上的文件是否需要合并~
2.输出合并
eg:set hive.merge.mapfiles = true #在Map-only的任务结束时合并小文件 set hive.merge.mapredfiles = true #在Map-Reduce的任务结束时合并小文件 set hive.merge.size.per.task = 256000000 #合并文件的大小 set hive.merge.smallfiles.avgsize=16000000 #默认为此值,当输出文件的平均大小小于该值时,启动一个独立的map-reduce任务进行文件merge
参考资料:hive merge小文件SET hive.auto.convert.join=TRUE; SET hive.exec.dynamic.partition = true; SET hive.exec.dynamic.partition.mode=nonstrict; SET hive.exec.max.dynamic.partitions = 1000000; SET hive.exec.max.dynamic.partitions.pernode=100000; SET hive.exec.max.created.files=1000000; set mapred.max.split.size=256000000; set mapred.min.split.size.per.node=100000000; set mapred.min.split.size.per.rack=100000000; set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; set hive.merge.mapfiles = true; set hive.merge.mapredfiles = true; set hive.merge.size.per.task = 256000000; set hive.merge.smallfiles.avgsize=256000000; INSERT INTO table bigdata_dev_dashuju.t2_666_dpi_result PARTITION(p_biz,p_date) SELECT case when lower(regexp_replace(a.biz,'dtmatch',''))='cc' OR lower(regexp_replace(a.biz,'dtmatch',''))='rpyx' then d.uid else d.mobile end mobile, d.uid, a.province, a.log_date, a.user_agent, a.host_freq, a.biz, a.get_time, d.uid, substr(m.city_id,0,4), a.p_biz, a.p_date FROM etl_fetch.`666_dpi_result_unknownid` a JOIN dw_resource.mapping_mobile_property d ON (a.device_id=d.md55mb AND d.p_operate='0' AND a.p_date>='20181006' AND substr(regexp_replace(a.get_time,'-',''),0,8) <='20181029') INNER JOIN dw_common.mobile_belong_head m ON substr(d.mobile,0,7) = m.number_head;
设置map/reduce个数
设置map个数:
1. 调整reduce个数方法一:
调整hive.exec.reducers.bytes.per.reducer参数的值;
set hive.exec.reducers.bytes.per.reducer=500000000; (500M)
2. 调整map个数方法二;
set mapreduce.job.maps = 1;
set mapred.max.split.size=10000000000;
set mapred.min.split.size=10000000000;
set mapred.min.split.size.per.node=10000000000;
set mapred.min.split.size.per.rack=10000000000;
set mapreduce.map.memory.mb=10000 ;
set mapreduce.map.java.opts=-Xmx12064m;
设置reduce个数:
1. 调整reduce个数方法一:
调整hive.exec.reducers.bytes.per.reducer参数的值;
set hive.exec.reducers.bytes.per.reducer=500 000 000; (500M)
2. 调整reduce个数方法二;
set mapreduce.job.reduces = 1;
— 加大内存
set mapreduce.map.memory.mb=16384;
set mapreduce.map.java.opts=-Xmx13106M;
set mapred.map.child.java.opts=-Xmx13106M;
set mapreduce.reduce.memory.mb=16384;
set mapreduce.reduce.java.opts=-Xmx13106M;—reduce.memory*0.8
set mapreduce.task.io.sort.mb=512
— 控制hive任务的reduce数
set hive.exec.reducers.bytes.per.reducer=200000000;
set hive.exec.reducers.max=150;
set hive.exec.compress.intermediate=true;
— map执行前合并小文件,减少map数
set mapred.max.split.size=256000000;
set mapred.min.split.size=256000000;
set mapred.min.split.size.per.node=100000000;
set mapred.min.split.size.per.rack=100000000;
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
— 设置hive的计算引擎为spark
set hive.execution.engine=spark;
— 1、合并输入文件
— 每个Map最大输入大小
set mapred.max.split.size=128000000;
— 一个节点上split的至少的大小
set mapred.min.split.size.per.node=100000000;
— 一个交换机下split的至少的大小
set mapred.min.split.size.per.rack=100000000;
— 执行Map前进行小文件合并
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
— 2、合并输出文件
— 在Map-only的任务结束时合并小文件
set hive.merge.mapfiles=true;
— 在Map-Reduce的任务结束时合并小文件
set hive.merge.mapredfiles = true;
— 合并文件的大小
set hive.merge.size.per.task = 134217728;
— 当输出文件的平均大小小于该值时,启动一个独立的map-reduce任务进行文件merge
set hive.merge.smallfiles.avgsize=16000000;
参考资料

若有收获,就点个赞吧
0 人点赞
