安装spark需要先安装scala 注意在安装过程中需要对应spark与scala版本, spark 也要跟hadoop对应版本,具体的可以在spark官网下载页面查看
1 安装Scala
1.1 下载
https://www.scala-lang.org/files/archive/scala-2.11.12.tgz
wget http://d3kbcqa49mib13.cloudfront.net/spark-2.1.0-bin-hadoop2.6.tgz
1.2 解压
tar -zxvf scala-2.11.12.tgz
1.3 配置环境变量
vim /etc/profileexport SCALA_HOME=/usr/local/scala/scala-2.11.12export PATH=$PATH:$SCALA_HOME/binsource /etc/profile
注意:Spark与hadoop版本必须互相匹配,因为Spark会读取Hadoop HDFS 并且必须能在Hadoop YARN执行程序,所以必须要按照我们目前安装的Hadoop版本来选择 笔者这里用的是hadoop2.7.7 所以我选择的是Pre-built for Apache Hadoop 2.7 and later
2 安装Spark
2.1 下载Spark
http://mirror.bit.edu.cn/apache/spark/spark-2.3.3/spark-2.3.3-bin-hadoop2.7.tgz
2.2 解压
tar -zvxf spark-3.0.0-preview2-bin-hadoop2.7.tgz
2.3 配置环境变量
vim /etc/profileexport SPARK_HOME=/usr/local/spark/spark-3.0.0-preview2-bin-hadoop2.7export PATH=$PATH:$SPARK_HOME/binsource /etc/profile
2.4 修改配置文件
# 进入配置文件目录cd /usr/local/spark/spark-3.0.0-preview2-bin-hadoop2.7/conf# 复制temnplate文件cp spark-env.sh.template spark-env.sh# 修改spark-env.sh 文件export JAVA_HOME=/hadoop/jdk1.8.0_161export SCALA_HOME=/usr/local/scala/scala-2.11.12export HADOOP_HOME=/usr/local/hadoop/tar/hadoop-2.10.0export HADOOP_CONF_DIR=/usr/local/hadoop/tar/hadoop-2.10.0/etc/hadoopSPARK_MASTER_IP=192.168.2.128SPARK_WORKER_MEMORY=1gSPARK_WORKER_CORES=2SPARK_WORKER_INSTANCES=1SPARK_LOCAL_DIRS=/usr/local/spark/spark-3.0.0-preview2-bin-hadoop2.7# 配置slaves文件cp slaves.template slavesvim slaveslocalhosthadoop02hadoop03
参数说明:
JAVA_HOME:Java安装目录 SCALA_HOME:Scala安装目录 HADOOP_HOME:hadoop安装目录 HADOOP_CONF_DIR:hadoop集群的配置文件的目录 SPARK_MASTER_IP:spark集群的Master节点的ip地址 SPARK_WORKER_MEMORY:每个worker节点能够最大分配给exectors的内存大小 SPARK_WORKER_CORES:每个worker节点所占有的CPU核数目 SPARK_WORKER_INSTANCES:每台机器上开启的worker节点的数目
2.5 发送scala、spark、host文件到其他服务器
scp /etc/profile root@hadoop02:/etc/profile
scp /etc/profile root@hadoop03:/etc/profile
scp -r /usr/local/spark/ root@hadoop02:/usr/local/
scp -r /usr/local/scala/ root@hadoop02:/usr/local/
scp -r /usr/local/scala/ root@hadoop03:/usr/local/
scp -r /usr/local/scala/ root@hadoop03:/usr/local/
source /etc/profile
2.6 启动spark
使用命令cd spark/hadoop/hadoop-2.9.1进入hadoop目录,在该目录下,启动 hadoop 文件管理系统 HDFS以及启动 hadoop 任务管理器 YARN。
cd /usr/local/spark/spark-3.0.0-preview2-bin-hadoop2.7/sbin
./start-all.sh
成功页面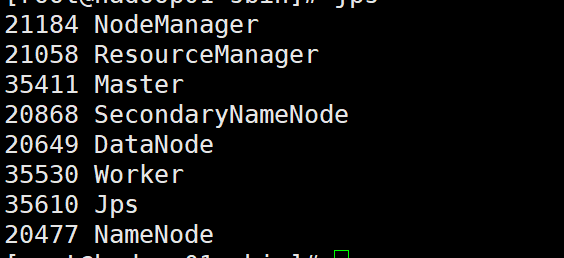


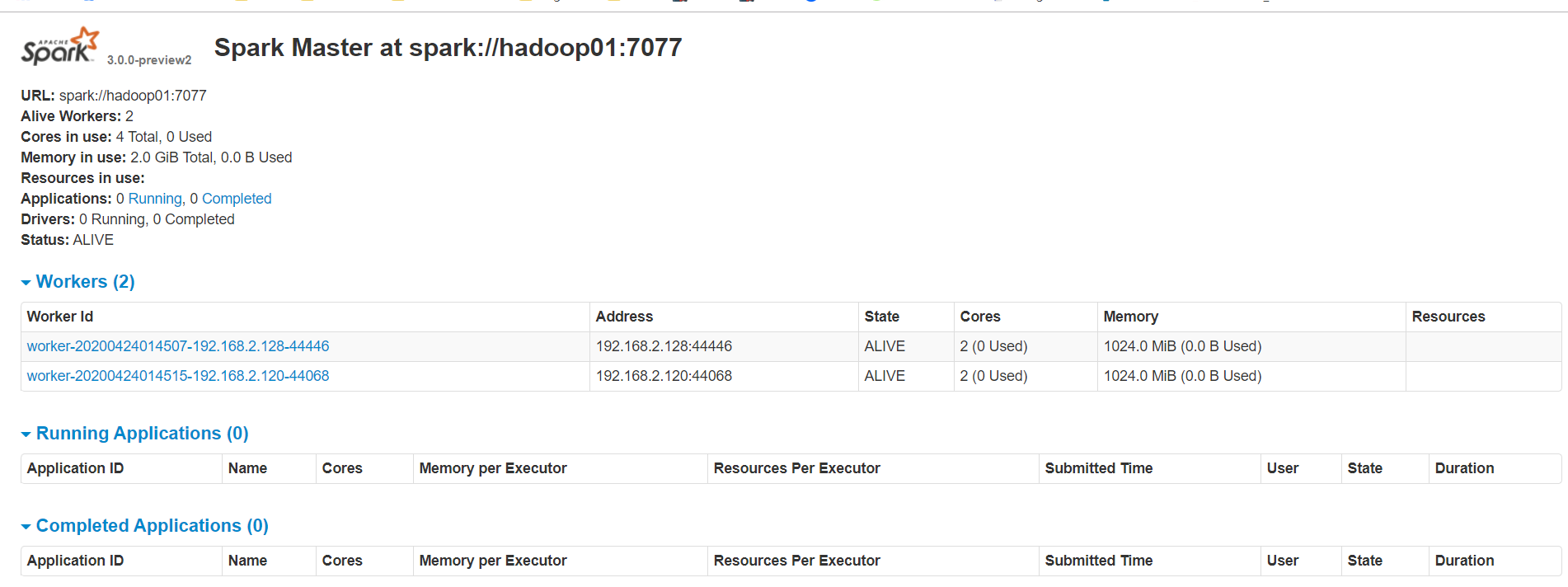
2.7 测试Spark
使用Spark shell的交互式方式分析数据
2.7.1 加载本地文件到HDFS中
1) 使用命令
hdfs dfs -mkdir -p /data/input
,即在虚拟分布式文件系统上创建一个测试目录/data/input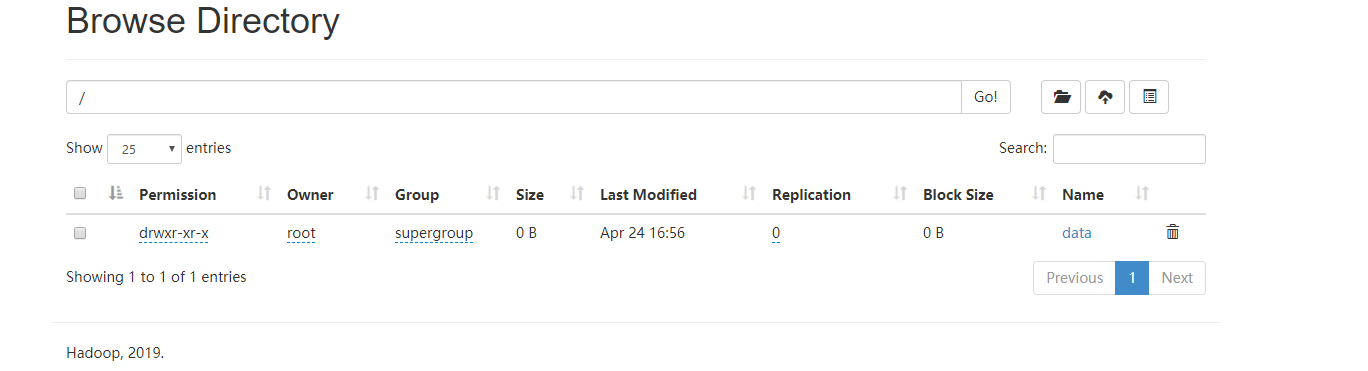
2) 使用命令
cd /usr/local/hadoop/tar/hadoop-2.10.0/
hdfs dfs -put README.txt /data/input
,即将/hadoop-2.9.1目录下的README.txt文件复制到虚拟分布式文件系统中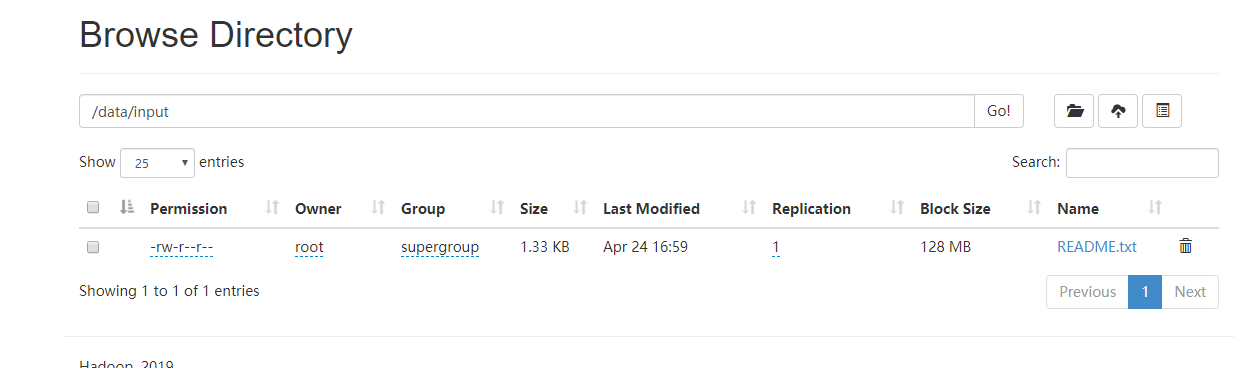
3) 使用命令
hdfs dfs -ls /data/input

2.7.2 简单分析(TODO 打算用java写)
在spark-shell 窗口,编写scala语句,将从HDFS中加载README.txt文件,并对该文件作简单分析
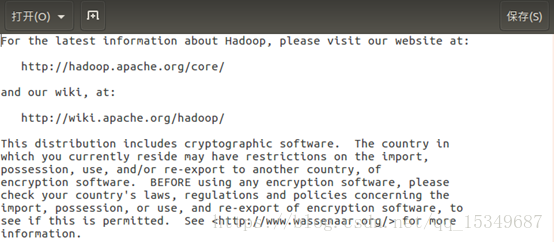
1) 首先,将README.txt的文件打开,可以看到里面的内容,如下所示:
2) 在spark-shell窗口上,通过使用count()、first()、collect()等操作,来对README.txt进行分析
i) 从HDFS中加载README.txt文件

ii) Count()操作的含义:RDD 中的 item 数量,对于文本文件来说,就是其总行数。First()的含义:RDD 中的第一个 item,对于文本文件,就是指其第一行内容,与第1步骤中的第一行内容一样,说明没出错。

iii) 使用collect(),对文件进行词数统计
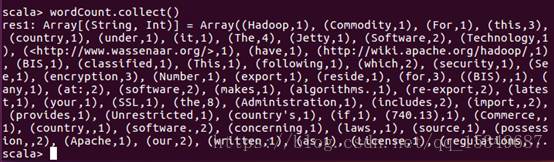
参考链接

若有收获,就点个赞吧
0 人点赞
