1 下载Hadoop和Jdk安装包(三个服务器均需下面操作)
请前往百度云上上下载相关安装包(密码:8op1)
1.1 修改静态IP
vim /etc/sysconfig/network-scripts/ifcfg-ens33
桥接模式也是可以设置静态IP
配置内容
TYPE=EthernetBOOTPROTO=static #改成static,针对NATNAME=eno16777736UUID=4cc9c89b-cf9e-4847-b9ea-ac713baf4cc8DEVICE=eno16777736DNS1=114.114.114.114 #和网关相同ONBOOT=yes #开机启动此网卡IPADDR=192.168.65.161 #固定IP地址NETMASK=255.255.255.0 #子网掩码GATEWAY=192.168.65.2 #网关和NAT自动配置的相同,不同则无法登录重启网络service network restart #重启网络systemctl restart network.service #重启网络ip addr #查看IP
1.2 关闭防火墙
systemctl stop firewalld.service #关闭防火墙服务systemctl disable firewalld.service #禁止防火墙开启启动
检查防火墙状态
firewall-cmd --state
1.3 修改主机名
vim /etc/hostname删掉原内容,改为:hadoop01Hostname为内核属性需要重启才能生效,不想重启可以定义零时主机名执行以下命令hostname hadoop01查看主机名hostname
1.4 修改hosts文件
vi /etc/hosts
删除原来内容
127.0.0.1 localhost::1 localhost192.168.65.161 hadoop01192.168.65.162 hadoop02192.168.65.163 hadoop03
1.5 设置免密登录
每台都执行以下操作在白框任意路径执行:ssh-keygen然后三次直接回车不输入任何内容得到秘钥后执行:ssh-copy-id root@hadoop01 #hadoop02、hadoop03测试ssh hadoop02不需要输入密码直接进入说明成功,exit退出
1.6 jdk 安装
解压
vim /etc/profileexport JAVA_HOME=/hadoop/jdk1.8.0_161export JAVA_JRE=JAVA_HOME/jreexport CLASSPATH=.:$JAVA_HOME/lib:$JAVA_JRE/libexport PATH=$PATH:$JAVA_HOME/binsource /etc/profilejava -verison

2 hadoop 安装
单机模式:解压就能运行,但是只支持MapReduce的测试,不支持HDFS,不用。
伪分布式模式:单机通过多进程模拟集群方式安装,支持Hadoop所有功能。学习测试用
2.1 伪分布式安装
需要环境:
JDK,JAVA_HOME,配置hosts,hostname,关闭防火墙,配置免密登录。
安装在hadoop01节点上。
2.1.1 创建目录
mkdir hadoop
2.1.2 上传安装包并解压
tar -xvf 安装包
2.1.3 修改配置文件
1 修改 hadoop-env.sh
vim [hadoop]/etc/hadoop/hadoop-env.sh
主要是修改java_home的路径
在hadoop-env.sh,把export JAVA_HOME=${JAVA_HOME}修改成具体的路径
修改HADOOP_CONF_DIR为具体的路径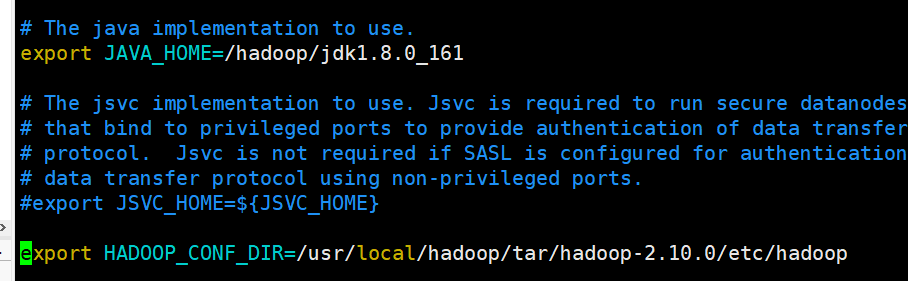
source hadoop-env.sh
2 修改 core-site.xml
vim [hadoop]/etc/hadoop/core-site.xml
增加namenode配置、文件存储位置配置
<configuration>
<property>
<!--用来指定hdfs的老大,namenode的地址-->
<name>fs.default.name</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<!--用来指定hadoop运行时产生文件的存放目录-->
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop/hadoop-2.7.1/tmp</value>
</property>
</configuration>
这边还需要创建一个临时文件夹
cd /usr/local/src/hadoop/hadoop-2.7.1
mkdir tmp
3 修改 hdfs-site.xml
vim [hadoop]/etc/hadoop/hdfs-site.xml
配置包括自身在内的备份副本数量
<configuration>
<property>
<!--指定hdfs保存数据副本的数量,包括自己,默认为3-->
<!--伪分布式模式,此值必须为1-->
<name>dfs.replication</name>
<value>1</value>
</property>
<!--设置hdfs操作权限,false表示任何用户都可以在hdfs上操作文件-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
4 修改 mapred-site.xml
说明:在/etc/hadoop的目录下,只有一个mapred-site.xml.template文件,复制一个。
cp mapred-site.xml.template mapred-site.xml
vim [hadoop]/etc/hadoop/mapred-site.xml
<configuration>
<property>
<!--指定mapreduce运行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5 修改 yarn-site.xml
vim [hadoop]/etc/hadoop/yarn-site.xml
<configuration>
<property>
<!--指定yarn的老大resourcemanager的地址-->
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<!--NodeManager获取数据的方式-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
6 修改 slaves
伪分布部署的时、候 需要配置三台主机(hadoop01,hadoop02,hadoop03)
vim slaves

2.2 修改profile
JAVA_HOME=/usr/local/java/jdk1.8.0_141
CLASSPATH=$JAVA_HOME/lib/
PATH=$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH
export HADOOP_HOME=/usr/local/hadoop/tar/hadoop-2.10.0
export PATH=${HADOOP_HOME}/bin:$PATH
2.2.1 测试
echo $HADOOP_HOME
2.3 初始化hadoop
hdfs namenode -format

cd /usr/local/hadoop/tar/hadoop-2.10.0/sbin
start-all.sh
stop-all.sh
2.4 启动hadoop

访问hadoop01:50070 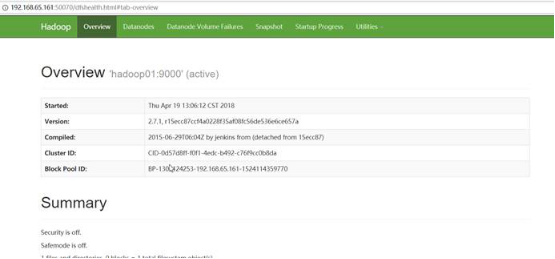
安装成功!
如果没有成功(进程数不够)
1.stop-all.sh **停掉hadoop所有进程
2.删掉tmp文件并重新创建tmp
3.hdfs namenode -format 重新初始化(出现successfully**证明成功),如果配置文件报错,安装报错信息修改相应位置后重新执行第二步。
4.start-all.sh **启动**hadoop
参考链接
王瑞同学的干货 hadoop 安装hadoop(2).docx

若有收获,就点个赞吧
0 人点赞
