2021.01.08 重建二叉树
今日题目:输入某二叉树的前序遍历和中序遍历的结果,请重建该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。
限制:0 <= 节点个数 <= 5000
- 思路:
- 法一:因为前序遍历序列的第一个元素就是树的根节点,然后在中序遍历序列中查找,返回查找到的数组下标,以此为分界线,将中序遍历序列划分为左右两个子数组,左数组为该根节点的左子树,右数组即为该根结点的右子树。再对左右两个子树进行同样的操作。本方法中传递递归调用的参数时(即子树的前序遍历序列和后序遍历序列,采用的是java中Arrays.copyOfRange(original, from, to) 方法,但是这个方法会新建一个子数组,大大增加空间复杂度,,而且每次在中序遍历序列中进行根节点索引的查找使得时间复杂度大大增加,可以再改进)。
- 法二(好了我又来评论区看大佬的代码了,叹为观止,每天都在被大佬震惊):前序遍历的首元素是树的根节点,然后在中序遍历序列找到根结点对应的下标,进而把中序遍历序列划分为左右两棵子树,即[ 左子树 | 根节点 | 右子树 ],然后根据中序遍历序列的划分结果确定左右子树的节点数量,进而对前序遍历序列进行划分,即[ 根节点 | 左子树 | 右子树 ]。而对于左右子树,仍可以用相同的方法继续进行划分,这是分治算法的体现。
- 递推算法解析:
- 递推参数:根节点在前序遍历序列中的数组下标 root,子树在中序遍历序列中的左边界 left,子树在中序遍历序列中的右边界 right。
- 终止条件:left > right。表示已经越过叶子结点,此时返回null。
- 递推工作:建立根节点,根结点值为preorder[root];划分左右子树为了提升效率,本文使用哈希表存储中序遍历的值与索引的映射,查找操作的时间复杂度为 O(1);构建左右子树,开始递归。
- 返回值: 回溯返回 node,作为上一层递归中根节点的左 / 右子节点。
| | 根节点数组下标 | 中序遍历序列左边界 | 中序遍历序列右边界 |
| —- | —- | —- | —- |
| 左子树 | root+1 | left | index - 1 |
| 右子树 | root + index - left + 1
(根节点索引 + 左子树长度 + 1) | index + 1 | right |
自己的菜鸡代码: ```java /**
- Definition for a binary tree node.
- public class TreeNode {
- int val;
- TreeNode left;
- TreeNode right;
- TreeNode(int x) { val = x; }
} */ // 法一:太烂了,与法二形成鲜明对比 class Solution { public TreeNode buildTree(int[] preorder, int[] inorder) {
// 终究是要面对的,树的结构很多可用递归的方法解决if(preorder.length == 0)return null;TreeNode root = new TreeNode(preorder[0]);// 求出的index表示左子树的长度int index = findIndex(inorder,preorder[0]);// 存在左子树 copyOfRange,若是to的位置超过了数组的长度,则其余位置自动补0if(index != 0)root.left = buildTree(Arrays.copyOfRange(preorder, 1, index + 1), Arrays.copyOfRange(inorder, 0, index));// 存在右子树if(index != inorder.length-1)root.right = buildTree(Arrays.copyOfRange(preorder, index + 1, preorder.length), Arrays.copyOfRange(inorder,index+1, inorder.length));return root;
}
public int findIndex(int []nums, int x){
for(int i = 0; i < nums.length; i++)if(nums[i] == x) return i;// 照理说不会出现这种情况,因为一个是前序遍历,一个是中序遍历return -1;
} }
// 法二
class Solution {
private int []preorder;
private HashMap
TreeNode build(int root, int left, int right){// root是在preorder中的数组下标值,left是树对应的中序遍历序列的最左下标值,right是树对应的中序遍历序列中的最右下标值if(left > right) return null;TreeNode ret = new TreeNode(preorder[root]);int index = map.get(preorder[root]);ret.left = build(root + 1 , left, index - 1);ret.right = build(root + index - left + 1, index + 1 , right);return ret;}
}
- 运行结果:法一(左):这个代码是真的烂,giao命。法二(右):太强了,真的太强了。<br /><a name="pTAOT"></a>### 2021.01.11 树的子结构(不简单)今日题目:<br />输入两棵二叉树A和B,判断B是不是A的子结构。(约定空树不是任意一个树的子结构)<br />B是A的子结构, 即 A中有出现和B相同的结构和节点值。<br /><br />限制:0 <= 节点个数 <= 10000- 思路:dbq,这个算法是看了大佬的代码,自己也知道是用递归来做这个题,但是自己原来的想法是先在A中找到B所在的子树,然后再递归查看是否是A子树的子树。这题大佬的思路好难描述giao命,那俺就原样copy大佬的思想了(俺太菜了)。===================================================================================- 解题思路:若树 B 是树 A 的子结构,则子结构的根节点可能为树 A 的任意一个节点。因此,判断树 B 是否是树 A 的子结构,需完成以下两步工作:<br />先序遍历树 A 中的每个节点 n(对应函数 isSubStructure(A, B))<br />判断树 A 中 以 n为根节点的子树 是否包含树 B 。(对应函数 recur(A, B))- recur(A, B) 函数:- 终止条件:- 当节点 B 为空:说明树 B 已匹配完成(越过叶子节点),因此返回 true;- 当节点 A 为空:说明已经越过树 A 叶子节点,即匹配失败,返回 false ;- 当节点 A 和 B 的值不同:说明匹配失败,返回 false;- 返回值:- 判断 A 和 B 的左子节点是否相等,即 recur(A.left, B.left) ;- 判断 A 和 B 的右子节点是否相等,即 recur(A.right, B.right) ;- isSubStructure(A, B) 函数:- 特例处理: 当 树 A 为空 或 树 B 为空 时,直接返回 false;- 返回值: 若树 B 是树 A 的子结构,则必满足以下三种情况之一,因此用或 || 连接;- 以 节点 A 为根节点的子树 包含树 B ,对应 recur(A, B);- 树 B 是 树 A 左子树 的子结构,对应 isSubStructure(A.left, B);- 树 B 是 树 A 右子树 的子结构,对应 isSubStructure(A.right, B);以上实质上是在对树 A 做先序遍历 。 <br />==================================================================================- 大佬的代码(不是我自己想的5555):```java/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode(int x) { val = x; }* }*/class Solution {public boolean isSubStructure(TreeNode A, TreeNode B) {// dbq 还是看了大佬的代码,大佬太强了55555555,这就是强者的世界吗// &&的后半部分实质上就是树的后根遍历return (A != null && B != null) && (recur(A,B) || isSubStructure(A.left,B) || isSubStructure(A.right,B));}boolean recur(TreeNode A, TreeNode B){// B已经遍历结束代表B是A的子结构if(B == null) return true;// A已经越过子结点或者A与B的结点值不一样,则返回false,if(A == null || A.val != B.val) return false;// 对A的左子树继续查看,对B的右子树继续查看return (recur(A.left, B.left) && recur(A.right, B.right));}}
- 运行结果:
2021.01.11 二叉树的镜像(简单)
今日题目:
请完成一个函数,输入一个二叉树,该函数输出它的镜像。(要改变结构)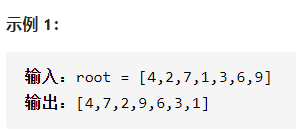
限制:0 <= 节点个数 <= 1000
- 思路:
- 法一:利用递归,先对二叉树的左子树进行递归处理实现镜像,再对二叉树的右子树进行递归处理实现镜像,最后交换左右子树的位置,即完成整颗二叉树的镜像处理(啊哈哈哈自己写出来啦,没有看大佬的代码555555555555555)。这题的实质是树的后根遍历,先对树的子树进行处理,再对根进行处理。
- mirrorTree(root)函数:
- 递归结束的条件:结点为空
- 返回值:已经进行镜像处理的树的根节点
- 时间复杂度为O(n),空间复杂度为O(n)
- mirrorTree(root)函数:
- 法二:利用队列,无需递归。实质上是树的层次遍历。
- 算法流程:
- 特例处理: 当 root 为空时,直接返回 null;
- 初始化: 初始化队列并加入根节点 root 。
- 循环交换: 当队列queue为空时跳出;
- 出队: 记为 temp ;
- 交换: 交换 temp 的左 / 右子节点。
- 添加子节点: 将 temp 左和右子节点入队;
- 返回值: 返回根节点 root。
- 时间复杂度O(n),空间复杂度为O(n)
- 算法流程:
- 法一:利用递归,先对二叉树的左子树进行递归处理实现镜像,再对二叉树的右子树进行递归处理实现镜像,最后交换左右子树的位置,即完成整颗二叉树的镜像处理(啊哈哈哈自己写出来啦,没有看大佬的代码555555555555555)。这题的实质是树的后根遍历,先对树的子树进行处理,再对根进行处理。
- 自己的菜鸡代码:
```java
/**
- Definition for a binary tree node.
- public class TreeNode {
- int val;
- TreeNode left;
- TreeNode right;
- TreeNode(int x) { val = x; }
- }
*/
// 法一(递归)
class Solution {
public TreeNode mirrorTree(TreeNode root) {
} }if(root == null) return null;root.left = mirrorTree(root.left);root.right = mirrorTree(root.right);TreeNode temp = root.left;root.left = root.right;root.right = temp;return root;
// 法二(队列)
class Solution {
public TreeNode mirrorTree(TreeNode root) {
if(root == null) return null;
LinkedList
- 运行结果:法一(左)、法二(右)<br /><a name="p56ld"></a>### 2021.01.12 从上往下打印二叉树今日题目:从上到下打印出二叉树的每个节点,同一层的节点按照从左到右的顺序打印。<br /><br />提示:节点总数 <= 1000- 思路:暴力解决,本质上就是代码的层次遍历。层次遍历需要用到一个辅助队列,同时因为事先不知道树的结点数量,故用一个辅助的list类型来记录结点的值。- 算法流程:- 初始化: 初始化队列并加入根节点 root,初始化 list 。- 循环交换: 当队列 queue 为空时跳出;- 出队: 记为 temp ;- 添加子节点: 若 temp 不为空,则将 temp 左和右子节点入队,同时用 list 记录 temp 的值;- 后续处理:初始化结果数组 result ,将 list 中的值逐个放到 result 中。- 返回值: 返回表示层序遍历结点值的数组 result 。- 时间复杂度O(n),空间复杂度为O(n)。- 自己的菜鸡代码:```java/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode(int x) { val = x; }* }*/class Solution {public int[] levelOrder(TreeNode root) {LinkedList<TreeNode> queue = new LinkedList<>();List<Integer> list = new ArrayList<>();queue.addLast(root);TreeNode temp;int count = 0;while(!queue.isEmpty()){temp = queue.poll();if(temp != null){list.add(temp.val);queue.addLast(temp.left);queue.addLast(temp.right);}}int[] result = new int[list.size()];for(int i = 0; i < list.size(); i++){result[i] = list.get(i);}return result;}}
- 运行结果:
2021.01.12 从上到下打印二叉树II
今日题目:从上到下按层打印二叉树,同一层的节点按从左到右的顺序打印,每一层打印到一行。

提示:节点总数 <= 1000
- 思路:
- 法一:自己的思路。可以用两个队列来交替存放每一行的结点,从而实现同一层的节点按从左到右的顺序打印,每一层打印到一行的效果但是这样子时间复杂度好高🆘。照理来说时间复杂度为O(n),空间复杂度为O(n),运行结果应该还可以,没想到这么差。
- 法二:本质上也是树的层次遍历。但是巧妙的利用队列的长度来区分不同层的结点。时间复杂度为O(n),空间复杂度也为O(n)。
- 自己的菜鸡代码:
```java
/**
- Definition for a binary tree node.
- public class TreeNode {
- int val;
- TreeNode left;
- TreeNode right;
- TreeNode(int x) { val = x; }
- }
*/
// 法一(可以再改进
class Solution {
public List
} }// 想到一种用空间换时间的方法,先试一下,这题比较烦的地方就是要把每层分隔开// 本来想用两个队列,交替进行List<List<Integer>> list = new ArrayList<>();LinkedList<TreeNode> queue1 = new LinkedList<>();LinkedList<TreeNode> queue2 = new LinkedList<>();queue1.addLast(root);TreeNode temp;List<Integer> data;while(!queue1.isEmpty() || !queue2.isEmpty()){data = new ArrayList<>();while(!queue1.isEmpty()){temp = queue1.poll();if(temp != null){data.add(temp.val);queue2.addLast(temp.left);queue2.addLast(temp.right);}}if(data.size() > 0) list.add(data);data = new ArrayList<>();while(!queue2.isEmpty()){temp = queue2.poll();if(temp != null){data.add(temp.val);queue1.addLast(temp.left);queue1.addLast(temp.right);}}if(data.size() > 0) list.add(data);}return list;
// 法二,大佬改进版本,只需用到一个栈即可。
class Solution {
public List
- 运行结果:法一:一个是在剑指中的运行结果,一个是在主站一道一样的题的运行结果,为什么差别会如此之大呢<br />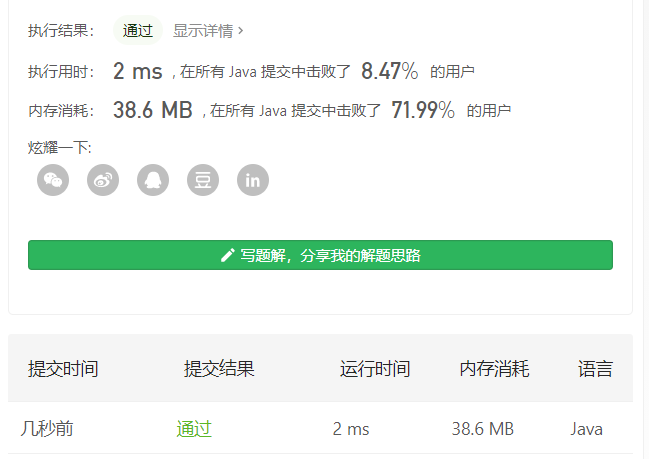<br />按照法二中的发现进行改动的结果,但是在主站中的运行结果如右图<br />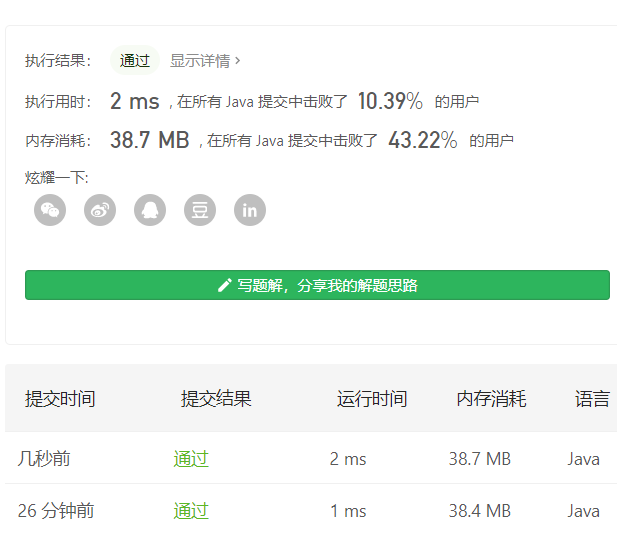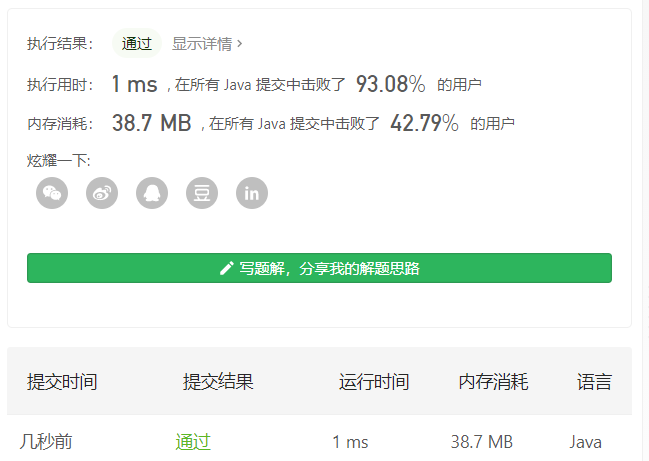<br />法二:为啥时间上都不太令人满意呢(我发现一点小小的问题)就是先声明再赋值与边声明边赋值的时间开销差别好大。<br />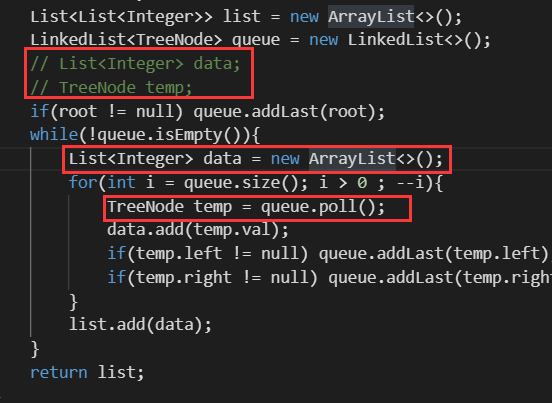<br /><a name="S2G1D"></a>### 2021.01.12 从上到下打印二叉树III今日题目:请实现一个函数按照之字形顺序打印二叉树,即第一行按照从左到右的顺序打印,第二层按照从右到左的顺序打印,第三行再按照从左到右的顺序打印,其他行以此类推。<br /><br />提示:节点总数 <= 1000- 思路:之字形从上到下打印二叉树实质上还是二叉树的层次遍历。这里利用的是双端队列、队列的长度、还有一个标记值来区分不同层的结点,从而实现最终结果。- 算法流程:- 初始化: 初始化队列并加入根节点 root,初始化 list 。- 循环交换: 当队列 queue 为空时跳出;- 区分从左到右还是从右到左:利用标记值的奇偶性,奇数则从左到右输出,偶数则从右到左输出。- 区分不同层的结点:用 i 记录记录队列的长度,即为某一层的节点数量。- 出队: 记为 temp ,并将temp的值存入data列表中;- 奇数层的处理:从队首出队,在孩子不为空的情况下在队尾存入左、右孩子(注意顺序)- 偶数层的处理:从队尾出队,在孩子不为空的情况下在队首存入右、左孩子(注意顺序)- 然后遍历完一层后将data存入list中。<br />- 返回值: 返回结果 list 。- 时间复杂度O(n),空间复杂度为O(n)。- 自己的菜鸡代码:```java/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode(int x) { val = x; }* }*/class Solution {public List<List<Integer>> levelOrder(TreeNode root) {// 本质上还是树的层次遍历// 可以利用双端队列List<List<Integer>> list = new ArrayList<>();LinkedList<TreeNode> queue = new LinkedList<>();if(root != null) queue.addLast(root);int flag = 1;while(!queue.isEmpty()){List<Integer> data = new ArrayList<>();if(flag % 2 == 1){for(int i = queue.size(); i > 0; --i){TreeNode temp = queue.poll();data.add(temp.val);if(temp.left != null) queue.addLast(temp.left);if(temp.right != null) queue.addLast(temp.right);}}else{for(int i = queue.size(); i > 0; --i){TreeNode temp = queue.removeLast();data.add(temp.val);if(temp.right != null) queue.addFirst(temp.right);if(temp.left != null) queue.addFirst(temp.left);}}++flag;list.add(data);}return list;}}
- 运行结果:
2021.01.12 二叉搜索树的后序遍历序列(这题有点难)
今日题目:输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历结果。如果是则返回 true,否则返回 false。假设输入的数组的任意两个数字都互不相同。

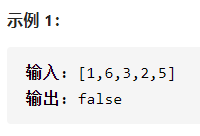

提示:数组长度 <= 1000
- 思路:后序遍历序列的结构为 左子树 | 右子树 | 根 ,所以可以利用递归的方式进行处理。❗这里是二叉搜索树❗,不是普通的二叉树。
- 自己的菜鸡代码:
- 运行结果
2021.01.18 二叉树的深度
今日题目(最近没学是我不对55):二叉树的深度
- 思路:
- 法一:利用递归解决(这题很简单)。若结点为空则返回0,若结点不为空则返回左子树高度和右子树之间高度较大的那个数+1的值。
- 法二:非递归解决,采用队列进行层次遍历,设置一个计数器,每经过一层就进行+1
- 自己的菜鸡代码:
```java
/**
- Definition for a binary tree node.
- public class TreeNode {
- int val;
- TreeNode left;
- TreeNode right;
- TreeNode(int x) { val = x; }
- }
*/
// 法一
class Solution {
public int maxDepth(TreeNode root) {
} }if(root == null) return 0;int left = maxDepth(root.left);int right = maxDepth(root.right);return 1 + (left > right? left : right);
// 法二 class Solution { public int maxDepth(TreeNode root) { // if(root == null) return 0; // int left = maxDepth(root.left); // int right = maxDepth(root.right); // return 1 + (left > right? left : right);
// if(root == null) return 0;// return Math.max(maxDepth(root.left), maxDepth(root.right)) + 1;if(root == null) return 0;LinkedList<TreeNode> queue = new LinkedList<>();queue.addLast(root);int count = 0;while(!queue.isEmpty()){for(int i = queue.size(); i > 0; --i){TreeNode temp = queue.poll();if(temp.left != null) queue.addLast(temp.left);if(temp.right != null) queue.addLast(temp.right);}++count;}return count;}
}
- 运行结果:<a name="xGOOf"></a>### 2021.01.20 对称的二叉树今日题目:请实现一个函数,用来判断一棵二叉树是不是对称的。如果一棵二叉树和它的镜像一样,那么它是对称的。<br />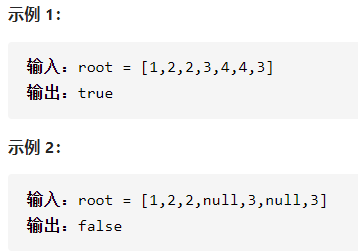<br />限制:0 <= 节点个数 <= 1000- 思路:- 法一:感觉本质上就是二叉树的层次遍历(写的贼烂)。使用两个双端队列,逐层比较。先是判断根节点是否为空,若不为空则在queue1的末端先后插入左孩子结点和右孩子结点。若queue1不为空或者queue2不为空,先处理queue1中的结点,同时从队首和队尾各poll一个结点,队首的记为left,队尾的记为right,若left == null 且 right null,则继续循环,若是left != null 且right != null且left.val == right.val则在queue2队首依次插入left的右孩子和左孩子,在队尾插入right的左孩子和右孩子。对queue2进行相同的处理,只是此时孩子结点是存入queue1中。- 法二:按照树的结构,肯定可以利用递归的方式来写,但是我不知道要怎么写救命。嘿嘿嘿,睡了一觉起来就知道怎么写了。先判断root是否为null,若是则直接返回true,若不是则继续。- 写了一个递归函数symmetry(TreeNode left, TreeNode right),left 表示对称部分的左边,right表示对称部分的右边。- 判断是否对称:1. 传入的两个结点在都不为空的情况下,结点值若相等,则继续调用symmetry,返回left的左子树、right的右子树以及left的右子树、right的左子树对称性的相与结果。1. 若两个结点都为空,则返回true。1. 其他情况返回false。- 自己的菜鸡代码:```java/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode(int x) { val = x; }* }*/class Solution {public boolean isSymmetric(TreeNode root) {// 这种方法的时间复杂度和空间复杂度都好高,giao命// 本质上是层次遍历// 不对啊 为什么一直不行呢我就不明白了if(root == null) return true;LinkedList<TreeNode> queue1 = new LinkedList<>();LinkedList<TreeNode> queue2 = new LinkedList<>();queue1.addLast(root.left);queue1.addLast(root.right);while(!queue1.isEmpty() || !queue2.isEmpty()){for(int i = queue1.size(); i > 0; --i){TreeNode left = queue1.poll();TreeNode right = queue1.pollLast();if(left == null && right == null)continue;if(left != null && right != null && left.val == right.val){queue2.addFirst(left.right);queue2.addFirst(left.left);queue2.addLast(right.left);queue2.addLast(right.right);}else return false;}for(int i = queue2.size(); i > 0; --i){TreeNode left = queue2.poll();TreeNode right = queue2.pollLast();if(left == null && right == null)continue;if(left != null && right != null && left.val == right.val){queue1.addFirst(left.right);queue1.addFirst(left.left);queue1.addLast(right.left);queue1.addLast(right.right);}else return false;}}return true;}}// 法二 采用递归的方式class Solution {public boolean isSymmetric(TreeNode root) {if(root == null) return true;return symmetry(root.left, root.right);}boolean symmetry(TreeNode left, TreeNode right){if(left != null && right != null && left.val == right.val){return symmetry(left.left, right.right) && symmetry(left.right, right.left);}else if(left == null && right == null){return true;}else{return false;}}}
- 运行结果:
法一(左)、法二(右)
2021.01.21 平衡二叉树
今日题目:输入一棵二叉树的根节点,判断该树是不是平衡二叉树。如果某二叉树中任意节点的左右子树的深度相差不超过1,那么它就是一棵平衡二叉树。

限制:1 <= 树的结点个数 <= 10000
- 思路:
- 法一(本质上是先根遍历):是否可以利用递归呢。可以!!但是这个方法中时递归嵌套递归。isBalanced方法中需要调用height方法。本来想用HashMap来记录每个结点的高度值,但是看到评论区中有人说: java如果用hashmap来防止重复计算深度会慢很多…估计是因为例子都比较小 反而不停调用hashmap耗费了时间,故不采用。
- isBalanced(TreeNode root):
- 若root == null,则返回true;
- 若左右子树的高度差大于1,返回false;
- 继续判断左右子树是否为平衡二叉树。
- height(TreeNode root):
- 若root == null,则返回0;
- 否则将左右子树高度较大的值进行加一并返回。
- isBalanced(TreeNode root):
大佬给了两种解决方法,法一的解决方法是其中一种,但是复杂度不知道要怎么分析,以下是大佬的分析:
复杂度分析: 时间复杂度 O(NlogN): 最差情况下(为“满二叉树”时),isBalanced(root) 遍历树所有节点,判断每个节点的深度 height(root) 需要遍历各子树的所有节点 。满二叉树高度的复杂度 O(logN) ,将满二叉树按层分为 log(N+1) 层; 空间复杂度 O(N): 最差情况下(树退化为链表时),系统递归需要使用 O(N)的栈空间。
- 法二(本质上是后序遍历):从底至顶返回子树深度,若判定某子树不是平衡,直接向上返回。
- recur(root)函数:
- 返回值:
- 当节点root左/右子树的深度差<= 1:则返回当前子树的深度,即节点root的左/右子树的深度最大值+1(max(left, right) + 1);
- 当节点root左/右子树的深度差>1:则返回-1,代表此子树不是平衡树,因此剪枝,直接返回-1;
- isBalanced(root)函数:
- 返回值:若recur(root) != -1,则说明此树平衡,返回true;否则返回false。
- 复杂度
- 时间复杂度:O(n),N为数的节点数;最差情况下,需要递归遍历树的所有节点。
- 空间复杂度:O(n),最差情况下(树退化成链表),系统递归需调用O(n)的栈空间
- recur(root)函数:
自己的菜鸡代码: ```java /**
- Definition for a binary tree node.
- public class TreeNode {
- int val;
- TreeNode left;
- TreeNode right;
- TreeNode(int x) { val = x; }
} */ // 法一 class Solution { public boolean isBalanced(TreeNode root) {
// 可以通过递归解决if(root == null) return true;if(Math.abs(height(root.left) - height(root.right)) > 1) return false;return isBalanced(root.left) && isBalanced(root.right);
}
int height(TreeNode root){
if(root == null) return 0;return Math.max(height(root.left), height(root.right)) + 1;
} }
// 法二 class Solution { public boolean isBalanced(TreeNode root) { return recur(root) != -1; }
int recur(TreeNode root){if(root == null) return 0;int left = recur(root.left);if(left == -1) return -1;int right = recur(root.right);if(right == -1) return -1;return Math.abs(left - right) < 2? Math.max(left,right) + 1 : -1;}
}
- 运行结果:法一(左)、法二(右):<br /><a name="1TBhZ"></a>### 2021.01.22 二叉树的最近公共祖先今日题目:给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。(5555好难的样子救命)<br />百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”<br />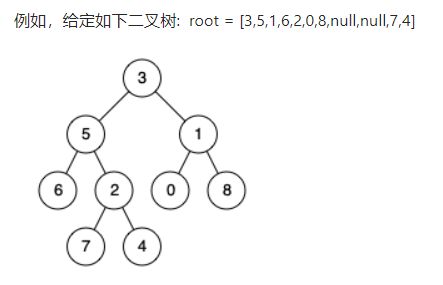<br />说明:- 所有节点的值都是唯一的。- p、q 为不同节点且均存在于给定的二叉树中。- 思路:- 法一(本质上是先序遍历):救命救命时间复杂度和空间复杂度怎么这么高。递归中嵌套递归sos。先判断根节点是否是p或q中的一个,若是,则直接返回p或q;否则判断p与q是否都在root 的左子树中,若都在则在左子树中继续寻找,若p与q都在root的右子树中,则继续在右子树中寻找,若在不同子树中则返回root(最近公共祖先)。- lowestCommonAncestor(root,p,q):返回值:<br />若 p == root,返回p;若q ==root,返回q;<br />若p 与 q 同在左子树中,则继续返回lowestCommonAncestor(root.left, p, q);<br />若p 与 q 同在右子树中,则继续返回lowestCommonAncestor(root.right, p, q);<br />若p 与 q 在不同子树中,则返回root。- contain(root, target):在以root为根的树中查找目标值target返回值:<br />若root == null,返回false;<br />若root == target,返回true;<br />其他情况返回contain(root.left, target) || contain(root.right, target);- 法二:应该跟上一题一样,本质是后序遍历,可以采用从底向上的方式,但是我不会啊giao。通过这一题跟上一题,有的情况下可以采用先序遍历和后序遍历,但是先序遍历中总是存在递归的嵌套,时间复杂度和空间复杂度很高且不好分析,效率很差;关键是要会用后序遍历,这个很不好理解。- 若 rootroot 是 p, q 的 最近公共祖先 ,则只可能为以下情况之一:p与q在root的两个子树中,且分列root的异侧。<br />p ==root,q在root的左右子树中。<br />q == root,p在root的左右子树中。- 递归解析:- 终止条件:当越过叶节点时,直接返回null,当root等于p、q时,直接返回root;- 递推工作:1. 开启递归左子节点,返回值记为left。1. 开启递归右子节点,返回值记位right。- 返回值:根据left和right的值,可以分为四种情况:3. 当left与right同时为空,说明root的左右子树中都不含p、q,返回null;3. 当left与right同时不为空,说明p、q在root的异侧,返回root;3. 当left为空、right不为空时,说明p、q都不在root的左子树中,直接返回right。具体可以分为两种情况:p、q其中一个为最近公共祖先,另一个在子树中;p、q在不同的子树中,right指向最近公共祖先。- 自己的菜鸡代码:```java/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode(int x) { val = x; }* }*/// 法一class Solution {public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {// 本质上是先根遍历。最近公共祖先无论如何都是存在的if(p == root) return p;if(q == root) return q;boolean leftContainP = contain(root.left, p);boolean leftContainQ = contain(root.left, q);if(leftContainP && leftContainQ){// 同在左子树中return lowestCommonAncestor(root.left, p, q);}if(leftContainP || leftContainQ){// 在不同子树中return root;}else{// 同在右子树中return lowestCommonAncestor(root.right, p, q);}}boolean contain(TreeNode root, TreeNode target){if(root == null) return false;if(root == target) return true;return contain(root.left, target) || contain(root.right, target);}}// 法二class Solution {public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {if(root == null || root == p || root == q) return root;TreeNode left = lowestCommonAncestor(root.left, p, q);TreeNode right = lowestCommonAncestor(root.right, p, q);if(left == null && right == null) return null;if(left == null) return right;if(right == null) return left;return root;}}
- 运行结果:
法一(左)、法二(右)
2021.01.22 二叉搜索树的第k大结点
今日题目:给定一棵二叉搜索树,请找出其中第k大的节点。

限制:1 ≤ k ≤ 二叉搜索树元素个数
思路:(这题本质上就是树的中序遍历)关键是要一边遍历,一边计数,然后还要返回值,当找到第k大结点时就要提前结束递归。
- 递归解析:
- 终止条件:当root结点为空,结束递归。
- 递归右子树;
- 进行三步处理:先判断是否已经找到第k大的值,若是,则提前结束递归;若未找到,则进行 —k的操作,若此时k == 0,则用res记录root的值(表示当前结点为第k大的数)。
- 递归左子树。
- 递归解析:
自己的菜鸡代码:
/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode(int x) { val = x; }* }*/class Solution {private int res;private int k;public int kthLargest(TreeNode root, int k) {// 中序遍历序列逆序this.k = k;inorder(root);return res;}void inorder(TreeNode root){if(root == null) return;inorder(root.right);if(k == 0) return;if(--k == 0) res = root.val;inorder(root.left);}}
运行结果:
2021.02.17 二叉搜索树的后序遍历序列
今日题目:输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历结果。如果是则返回 true,否则返回 false。假设输入的数组的任意两个数字都互不相同。

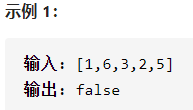

提示:数组长度 <= 1000
- 思路:后序遍历序列的最后一个是根节点,而本棵树是二叉搜索树,这意味着左子树中的所有值都小于根节点的值,右子树中的所有值都大于根节点的值,从第一个元开始遍历,直至找到第一个大于根节点的值,以此为分界线将后序遍历序列划分为 左子树 | 右子树 | 根 ,继续往后遍历,若是在右子树中找到小于根节点的值,则返回false。否则继续对左子树(判断是否存在)与右子树(判断是否存在)进行递归操作。
自己的菜鸡代码:
class Solution {private int[] postorder;public boolean verifyPostorder(int[] postorder) {// 这题是用递归吗,我好困giao命 二叉搜索树的中序遍历序列是有序的// 关键就是如何分出左右子树if(postorder.length == 0)return true;this.postorder = postorder;return recur(0, postorder.length - 1);}boolean recur(int begin, int end){if(end - begin + 1 <= 0) return true;int root = postorder[end];int i = begin;for(; i < end; i++){if(postorder[i] > root) break;}int j = i;for(; j < end; j++){if(postorder[j] < root) return false;}//[4, 8, 6, 12, 16, 14, 10]boolean left = true;// 为什么要判断啊if(i > 0){left = recur(begin, i-1);}boolean right = true;if(i < end - 1){right = recur(i, j - 1);}return left && right;}}
运行结果:

若有收获,就点个赞吧
0 人点赞
