认识集合
在java程序中 **集合是存放数据的容器**,它数组一样。但是但是 是存在差异的,从使用上说,集合更为方便,因为集合容量会随着元素的增减自动变化,而且集合提供丰富的方法来操作元素。而数组是一种非常基础的数据容器,直接使用不是很方便。
数组=它是语法层面提供的数据存储的简单容器,几乎所有的语言都提供了这个数组。**集合=数据结构+算法**,不同的集合一般都依托于某种数据结构,比如ArrayList 底层使用的数组。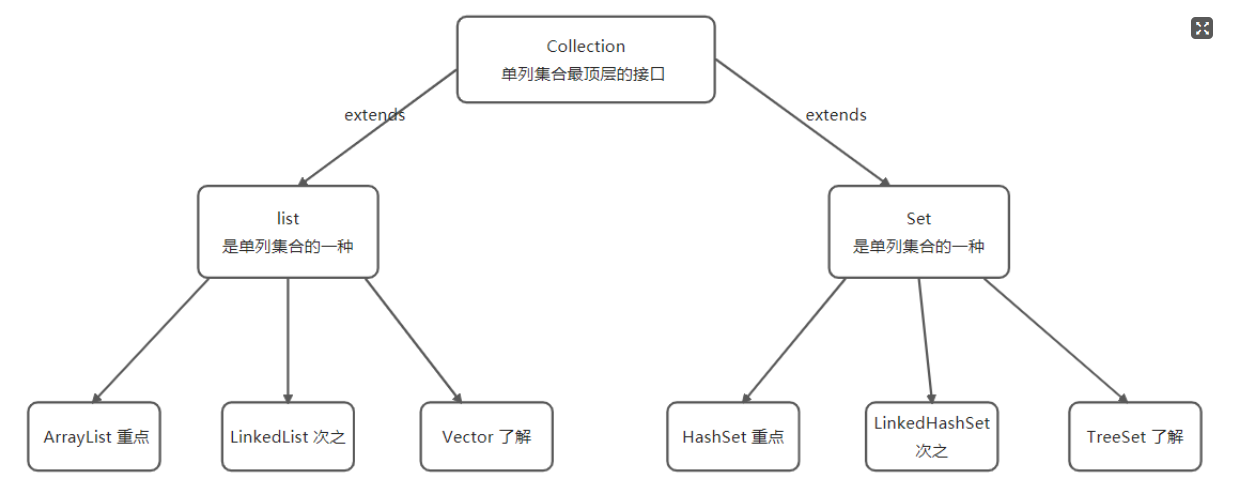
List集合
认识List接口
List接口是Collection的一个子接口,它代表的是有序集合( 元素有序 有下标 可以重复 ),它在Collection基础上新增了一些个与下标操作相关的方法。
List接口实现类
其主要的实现类有
- ArrayList
- LinkedList
- Vector
疑问?都是做相同的事情,为什么要搞个实现呢?
答案:因为他们底层的数据结构和算法乃至于线程安全性问题不同。
List接口常用方法
List方法来自两个部分,继承Collection的和自己的。
Collection集合常用方法
boolean |
[**add**](../../java/util/Collection.html#add(E))([E](../../java/util/Collection.html) e)确保此 collection 包含指定的元素(可选操作)。 |
|---|---|
boolean |
[**addAll**](../../java/util/Collection.html#addAll(java.util.Collection))([Collection](../../java/util/Collection.html)<? extends [E](../../java/util/Collection.html)> c)将指定 collection 中的所有元素都添加到此 collection 中 |
void |
[**clear**](../../java/util/Collection.html#clear())()移除此 collection 中的所有元素(可选操作)。 |
boolean |
[**contains**](../../java/util/Collection.html#contains(java.lang.Object))([Object](../../java/lang/Object.html) o)如果此 collection 包含指定的元素,则返回 true。 |
boolean |
[**containsAll**](../../java/util/Collection.html#containsAll(java.util.Collection))([Collection](../../java/util/Collection.html)<?> c)如果此 collection 包含指定 collection 中的所有元素,则返回 true。 |
boolean |
[**equals**](../../java/util/Collection.html#equals(java.lang.Object))([Object](../../java/lang/Object.html) o)比较此 collection 与指定对象是否相等。 |
int |
[**hashCode**](../../java/util/Collection.html#hashCode())()返回此 collection 的哈希码值。 |
boolean |
[**isEmpty**](../../java/util/Collection.html#isEmpty())()如果此 collection 不包含元素,则返回 true。 |
[Iterator](../../java/util/Iterator.html)<[E](../../java/util/Collection.html)> |
[**iterator**](../../java/util/Collection.html#iterator())()返回在此 collection 的元素上进行迭代的迭代器。 |
boolean |
[**remove**](../../java/util/Collection.html#remove(java.lang.Object))([Object](../../java/lang/Object.html) o)从此 collection 中移除指定元素的单个实例,如果存在的话(可选操作)。 |
boolean |
[**removeAll**](../../java/util/Collection.html#removeAll(java.util.Collection))([Collection](../../java/util/Collection.html)<?> c)移除此 collection 中那些也包含在指定 collection 中的所有元素 |
boolean |
[**retainAll**](../../java/util/Collection.html#retainAll(java.util.Collection))([Collection](../../java/util/Collection.html)<?> c)仅保留此 collection 中那些也包含在指定 collection 的元素 |
int |
[**size**](../../java/util/Collection.html#size())()返回此 collection 中的元素数。 |
[Object](../../java/lang/Object.html)[] |
[**toArray**](../../java/util/Collection.html#toArray())()返回包含此 collection 中所有元素的数组。 |
public static void main(String[] args) {//实例化集合Collection list = new ArrayList();Actress a1 = new Actress("苍井空",30,'F',"上班的第一天.AVI");Actress a2 = new Actress("小泽玛利亚",31,'G',"坐轻轨去上班.AVI");Actress a3 = new Actress("波多野结衣",33,'C',"回家的诱惑.AVI");Actress a4 = new Actress("武藤兰",25,'D',"在学校的一天.AVI");//1 添加一个元素 add(Object obj):voidlist.add(a1);list.add(a2);list.add(a3);list.add(a4);//声明一个国产明星集合Collection other = new ArrayList();other.add( new Actress("白百何",40,'F',"失恋33天") );other.add( new Actress("马蓉",41,'G',"宝强块回来") );//2 添加一个集合 add(Collection obj):voidlist.addAll(other);//3 获得元素个数 size()System.out.println(list.size());//4 清空全部元素 clear():void//list.clear();//System.out.println(list.size());//5 判断是否包含指定元素System.out.println(list.contains(a4));System.out.println(list.containsAll(other));//6 判断集合是否为空集合 isEmpty():booleanSystem.out.println(list.isEmpty());//7 移除元素 remove(Object obj) removeAll(Collection obj)//list.remove(a1);list.removeAll(other);//8 集合转数组 toArray()Object[] arr = list.toArray();System.out.println(Arrays.toString(arr));//9 集合求交集 retainAll(Collection list)Collection s1 = new ArrayList();s1.add("A");s1.add("B");s1.add("C");Collection s2 = new ArrayList();s2.add("A");s2.add("B");s2.add("f");s1.retainAll( s2);System.out.println(s1);//10 集合的遍历:foreach 快捷键:iterfor (Object o : list) {System.out.println(o);}}}
自身扩展的方法
void |
[**add**](../../java/util/List.html#add(int, E))(int index, [E](../../java/util/List.html) element)在列表的指定位置插入指定元素(可选操作)。 |
|---|---|
boolean |
[**addAll**](../../java/util/List.html#addAll(int, java.util.Collection))(int index, [Collection](../../java/util/Collection.html)<? extends [E](../../java/util/List.html)> c)将指定 collection 中的所有元素都插入到列表中的指定位置 |
[E](../../java/util/List.html) |
[**get**](../../java/util/List.html#get(int))(int index)返回列表中指定位置的元素。 |
int |
[**indexOf**](../../java/util/List.html#indexOf(java.lang.Object))([Object](../../java/lang/Object.html) o)返回此列表中第一次出现的指定元素的索引;如果此列表不包含该元素,则返回 -1。 |
int |
[**lastIndexOf**](../../java/util/List.html#lastIndexOf(java.lang.Object))([Object](../../java/lang/Object.html) o)返回此列表中最后出现的指定元素的索引;如果列表不包含此元素,则返回 -1。 |
[E](../../java/util/List.html) |
[**remove**](../../java/util/List.html#remove(int))(int index)移除列表中指定位置的元素(可选操作)。 |
[E](../../java/util/List.html) |
[**set**](../../java/util/List.html#set(int, E))(int index, [E](../../java/util/List.html) element)用指定元素替换列表中指定位置的元素(可选操作)。 |
[List](../../java/util/List.html)<[E](../../java/util/List.html)> |
[**subList**](../../java/util/List.html#subList(int, int))(int fromIndex, int toIndex)返回列表中指定的 fromIndex(包括 )和 toIndex(不包括)之间的部分视图。 |
public static void main(String[] args) {List list = new ArrayList();list.add("唐僧");list.add("八戒");list.add("小明");list.add("晓东");//1 插入方法 add(int index , Object obj)list.add(1,"悟空");//2 获取元素的方法 get(int index):ObjectSystem.out.println(list.get(0));//3 移除元素 remove(int index):Objectlist.remove(2);//4 截取一段元素 subList( int index , int end )List sonList = list.subList(1, 3);System.out.println(sonList);//5 修改指定位置的元素 set(int index , Object obj)list.set(0,"唐三藏");//6 查找元素下标 indexOf(Object obj)int n = list.indexOf("晓东");System.out.println(n);System.out.println("-------- 遍历 -----------");for( Object e : list){System.out.println(e);}}
List集合遍历方式【掌握】
普通for循环
public static void main(String[] args) {Actress a1 = new Actress("苍井空",30,'F',"上班的第一天");Actress a2 = new Actress("小泽玛利亚",31,'G',"坐轻轨去上班");Actress a3 = new Actress("波多野结衣",33,'C',"回家的诱惑");Actress a4 = new Actress("武藤兰",25,'D',"在学校的一天");//实例化一个集合List list = new ArrayList();//核心中的核心方法 添加元素list.add(a4);list.add(a2);list.add(a1);list.add(a3);System.out.println("------------------- 有序集合遍历方式 1: 普通for --------------------");for( int i=0; i< list.size() ; i++ ){Object obj = list.get(i);//根据下下标找元素Actress actress = (Actress) obj;System.out.println( actress.getProduct() );}}
增强for循环
- 用来遍历集合和数组
格式:
for(集合/数组数据类型 变量名:集合名/数组名){循环体sout(变量名)}
public static void main(String[] args) {Actress a1 = new Actress("苍井空",30,'F',"上班的第一天");Actress a2 = new Actress("小泽玛利亚",31,'G',"坐轻轨去上班");Actress a3 = new Actress("波多野结衣",33,'C',"回家的诱惑");Actress a4 = new Actress("武藤兰",25,'D',"在学校的一天");//实例化一个集合List list = new ArrayList();//核心中的核心方法 添加元素list.add(a4);list.add(a2);list.add(a1);list.add(a3);System.out.println("------------------- 有序集合遍历方式 2: 增强for ------------------- ");for( Object obj : list ){Actress actress = (Actress) obj;System.out.println(actress.getName());}}
List实现类区别【掌握】
ArrayList 特点
ArrayList 它底层依靠**数组**实现的 使用 Object[] elementData 存储数据。**查询快** ,**增删慢**。每次扩容增长0.5倍。ArrayList 是线程不安的,多线程环境下不保证数据一致性。
Vector 特点
它和ArrayList实现原理一样。默认每次扩容增长1倍,这个类是一个古老的集合类,JDK1.O提供的有序集合类,他是线程安全的,效率低,在JDK1.2推出的ArrayList 代替它的功能,这个类几乎不用了。
LinkedList 特点
**链表**这种数据结构,**查询慢**,**增删快**,当然他还是实现了队列相关功能,同时它也不保证线程安全。
Iterator迭代器
java.util.Iterator接口:迭代器(对集合进行遍历)
两个常用的方法**boolean hasNext()**:判断集合中还有没有下一个元素,有就返回true,没有就false**E next()**:取出集合中的下一个元素
迭代器的使用步骤(重点)
- 先获取集合上的迭代器:
**Iterator it = list.iterator**_**()**_**;** - 先判断迭代器后是否有数据:
**it.hasNext**_**()-->boolean**_ 通过迭代器获取集合的元素:
**it.next**_**()**_**;**```java public class CollectionDemo { public static void main(String[] args) {Collection list = new ArrayList();list.add(123);list.add(true);list.add("hello");//迭代器//step1Iterator it = list.iterator();//step2while (it.hasNext()){//step3Object next = it.next();System.out.println(next);}
} }
<a name="jkzSK"></a>## 泛型<a name="GQoWz"></a>### 泛型概念泛型指的是类型参数化的一个技术,在设计类/接口的时候,如果他们内部某些地方的类型无法确定,可以使用一个占位符,先站位,使用这个类或接口的时候再指定(把类型的确定推迟到这个类具体使用的时候)。<a name="okgYH"></a>####<a name="QV9Tx"></a>### 泛型集合使用```java//泛型集合 使用public class GenericCollectionDemo {public static void main(String[] args) {Actress a1 = new Actress("苍井空",30,'F',"上班的第一天");Actress a2 = new Actress("小泽玛利亚",31,'G',"坐轻轨去上班");Actress a3 = new Actress("波多野结衣",33,'C',"回家的诱惑");Actress a4 = new Actress("武藤兰",25,'D',"在学校的一天");//实例化集合指定泛型参数List<Actress> list = new ArrayList<>();//添加对象list.add(a1);list.add(a2);list.add(a3);list.add(a4);//遍历for( Actress o : list){ //不用Object 用泛型指定的类型就可以了,不用转型方便System.out.println(o.getName());}}}
开发中通常都是使用泛型集合,保证元素的单一性,同时元素类型不会提升,使用时无需转型
泛型类/接口定义/泛型方法
比如定义一个位置类,但是不想把x y 坐标的类型定死,这是使用X,Y字母 来占位,通常使用的有**E** **K** **V** **T** 这些。
//定义带有泛型的类public class Position<X,Y> {X x;Y y;public Position(X x, Y y) {this.x = x;this.y = y;}public X getX() {return x;}public void setX(X x) {this.x = x;}public Y getY() {return y;}public void setY(Y y) {this.y = y;}}
//泛型原理public class GenericPrinciple {public static void main(String[] args) {//使用类时 必须指定具体X Y字母的类型Position<Integer,Integer> position = new Position<>(10,20);System.out.println(position.getX());System.out.println(position.getY());System.out.println("----------------------------");//使用类时 必须指定具体X Y字母的类型Position<String,String> position2 = new Position<>("东经30","北纬50");System.out.println(position2.getX());System.out.println(position2.getY());}}
使用泛型技术可以让代码更灵活,一个类当无数个类使用,需要注意的是 基本数据类型不支持泛型,需要使用其包装类
泛型限定
指的是设计泛型方法的时候,方法参数存在的一些泛型类型要求
public static void m1(List<Integer> obj ){ // 接收一个特定泛型的集合 参数}public static void m2( List<?> obj ){ // 接收一个任意泛型的集合 参数 ?不限定}public static void m3(List< ? super Integer > obj ){ // 接收一个特定泛型及其父类类型 的集合参数}public static void m4(List< ?extends Number > obj ){ // 接收一个特定泛型及其子类类型 的集合参数}
泛型擦除
java中泛型是一种伪泛型,编译效果,一旦编译泛型就没有泛型信息了,所以需要注意就是不同的泛型类型不可重载。
public static void m1(List<Integer> obj ){}public static void m1(List<Double> obj ){ // 报错不可重载}//--------------------泛型擦除后------------------------public static void m1(List obj ){ // 参数一样了}public static void m1(List obj ){ // 参数一样了}
泛型不支持多态
public static void main(String[] args) {List<Integer> brr = new ArrayList<>();List<Number> arr ;arr= brr; //报错 不可直接赋值,不考虑多态问题,泛型类+ 具体类型完全是一个全新类型。}
泛型通配符
**<?>**不确定接受的类型就用通配符
public class Test02 {public static void main(String[] args) {ArrayList<String> list1 = new ArrayList<>();list1.add("aaa");list1.add("bbb");list1.add("ccc");ArrayList<Integer> list2 = new ArrayList<>();list2.add(12);list2.add(23);list2.add(56);print(list1);print(list2);}// 不确定接受的类型就用通配符 ArrayList<?>public static void print(ArrayList<?> list){for (int i = 0; i < list.size(); i++) {System.out.println(list.get(i));}}}
泛型总结
- jdk1.5以后
- 泛型实际就是一个<>引用来的参数类型,这个参数类型具体在使用的时候才会确定具体类型
- 使用泛型后,可以确定集合中存放数据的类型,在编译时期就可以检查出来
- 使用泛型可能会觉得麻烦,其实实际使用泛型才会简单,后续的遍历等操作简单
- 泛型的类型:都是引用数据类型,不能是基本数据类型
ArrayList_<_Integer_> _al = new ArrayList_<_Integer_>()_;在jdk1.7以后可以写成为:ArrayList_<_Integer_> _al = new ArrayList_<>()_;
Set集合
Set接口的特点
Set表示的是 **无序 无下标 元素不可重复** ,它也是一个子接口但是没有扩展新的方法,也就是说只有Collection接口中的方法。
Set接口的实现类
- HashSet:底层是(
**哈希表+红黑树**)实现的,无索引、不可存储重复元素 - LinkedHashSet:底层是 (
**哈希表+链表**)实现的,无索引、不可存储重复元素,可以保证存取顺序 - TreeSet:底层是
**二叉树**实现,一般用于排序,可以有序,去重
常用API
和Collection中的一致,无需重复学习。
无序集合遍历
- 迭代器
增强for ```java public class SetDemo {
public static void main(String[] args) {
//无序无下标不可重复Set<String> sets = new HashSet<>();sets.add("Java");sets.add("MySQL");sets.add("Java");sets.add("H5");sets.add("MMP");sets.add("HMP");System.out.println(sets); //[Java, MySQL, php, H5]
//遍历System.out.println("---------------迭代器-----------------");Iterator<String> it = sets.iterator();while ( it.hasNext() ){String obj = it.next();System.out.println(obj);}System.out.println("---------------增强for-----------------");for( String obj : sets){System.out.println(obj);}System.out.println("---------------查找-----------------");for( String obj : sets){char c = obj.charAt(0);if(c=='H'){System.out.println(obj);}}}
}
> Set集合不可以单独直接取出某个元素,需要遍历筛选出你要的元素<a name="Ob5Ou"></a>### HashSet去重HashSet去重原理:- 添加元素的时候,先判断对象的hashcode 是否与现有元素的hashcode 相同。- 不相同:直接保存- 相同: 需要进一步判断 equals 是否和现有元素相同- 相同: 放弃保存- 不同: 保存自定义类型:如果希望自定义类型,成员相同的时候,不要重复添加到Set集合,则需重写两个方法 `**hashCode()**` `**equals()**`** **```javaclass Book{String name;String author;public Book() {}public Book(String name, String author) {this.name = name;this.author = author;}@Overridepublic String toString() {return "Book{" +"name='" + name + '\'' +", author='" + author + '\'' +'}';}@Overridepublic int hashCode() {int result = name != null ? name.hashCode() : 0;result = 31 * result + (author != null ? author.hashCode() : 0);return result;}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Book book = (Book) o;if (name != null ? !name.equals(book.name) : book.name != null) return false;return author != null ? author.equals(book.author) : book.author == null;}}
HashSet 集合底层 是套娃 HashMap
LinkedHashSet 【了解】
HashSet子类,可以记录元素的添加顺序,底层使用LinkedHashMap。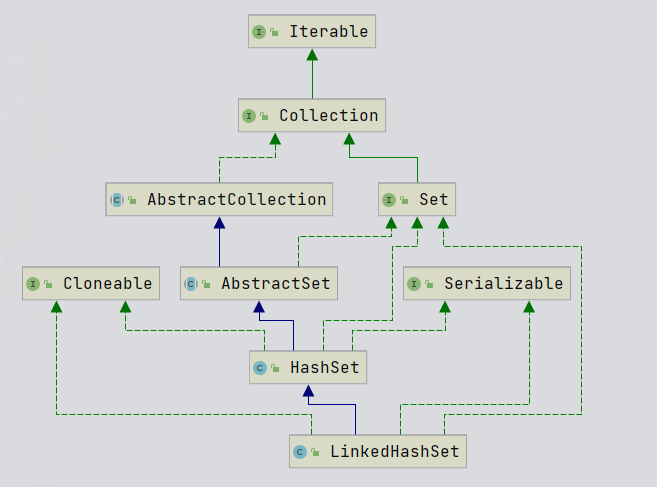
public class LinkedHashSetDemo {public static void main(String[] args) {Set<String> sets = new LinkedHashSet<>();sets.add("Hello");sets.add("CSS");sets.add("MySQL");sets.add("Hello");System.out.println(sets);}}
TreeSet 【了解】
他是Sorted接口的实现类,具备元素可排序的能力,可以把元素按照从小到大或者从大到小排列(可以把元素升序降序排列)。它的底层套娃 TreeMap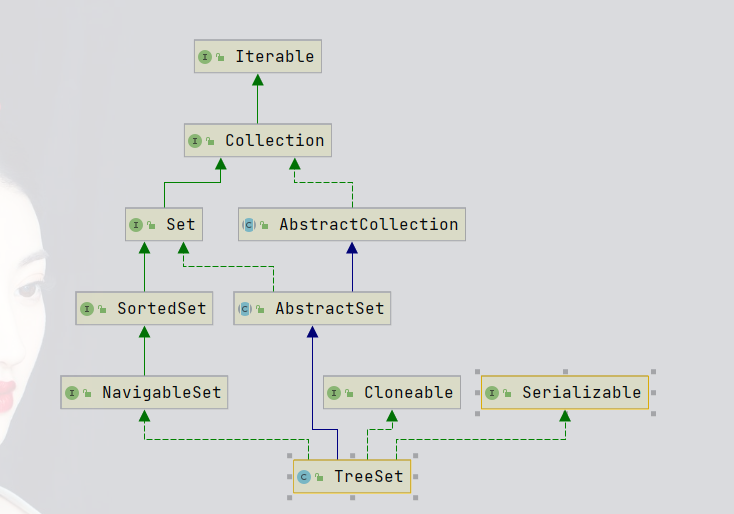
自然排序
自然排序需要 让类实现Comparable 接口,这是一个排序接口 ,需要重写一个方法 public int compareTo(T o);
这个方法用于让用户 自定义比较规则。
Book类
package set;public class Book implements Comparable {String name;String author;double pirce;//省略其他//自动定义比较规则的方法@Overridepublic int compareTo(Object o) {Book book = (Book) o;if(this.pirce > book.pirce){return 1;}if( this.pirce< book.pirce ){return -1;}//return 0; //去重return this.name.compareTo(book.name);}}
测试类
public class TreeSetDemo {public static void main(String[] args) {System.out.println("------------自用自然排序------------------");Set<Book> books = new TreeSet<>();books.add( new Book("西游记","a",10) );books.add( new Book("西游记后传","a",23) );books.add( new Book("西游记前传","a",9) );for (Book book : books) {System.out.println(book);}}}
排序器排序
这种方式需要在创建TreeSet实例的时候传入一个Comparator接口的实例,通常使用匿名内部类来做。元素类不需要实现Comparable 接口。
package set;public class Book {String name;String author;double pirce;//省略其他}
public class TreeSetDemo {public static void main(String[] args) {System.out.println("-----------使用排序器排序-------------------");Set<Book> books = new TreeSet<>( new Comparator<Book>() {@Overridepublic int compare(Book o1, Book o2) {if(o1.pirce>o2.pirce){return 1;}if(o1.pirce<o2.pirce){return -1;}return 0;}} );books.add( new Book("西游记","a",10) );books.add( new Book("西游记后传","a",23) );books.add( new Book("西游记前传","a",9) );for (Book book : books) {System.out.println(book);}}}
Map集合
理解Map 映射
map接口,也是一种容器,存储的数据是成对出现,**key-->value**
注意点:
- 存储无序的键值对
- key必须是唯一的,而且和value是一一对应
常用API
void |
[**clear**](../../java/util/Map.html#clear())()从此映射中移除所有映射关系(可选操作)。 |
|---|---|
boolean |
[**containsKey**](../../java/util/Map.html#containsKey(java.lang.Object))([Object](../../java/lang/Object.html) key)如果此映射包含指定键的映射关系,则返回 true。 |
boolean |
[**containsValue**](../../java/util/Map.html#containsValue(java.lang.Object))([Object](../../java/lang/Object.html) value)如果此映射将一个或多个键映射到指定值,则返回 true。 |
[Set](../../java/util/Set.html)<[Map.Entry](../../java/util/Map.Entry.html)<[K](../../java/util/Map.html),[V](../../java/util/Map.html)>> |
[**entrySet**](../../java/util/Map.html#entrySet())()返回此映射中包含的映射关系的 [Set](../../java/util/Set.html)视图。 |
boolean |
[**equals**](../../java/util/Map.html#equals(java.lang.Object))([Object](../../java/lang/Object.html) o)比较指定的对象与此映射是否相等。 |
[V](../../java/util/Map.html) |
[**get**](../../java/util/Map.html#get(java.lang.Object))([Object](../../java/lang/Object.html) key)返回指定键所映射的值;如果此映射不包含该键的映射关系,则返回 null。 |
int |
[**hashCode**](../../java/util/Map.html#hashCode())()返回此映射的哈希码值。 |
boolean |
[**isEmpty**](../../java/util/Map.html#isEmpty())()如果此映射未包含键-值映射关系,则返回 true。 |
[Set](../../java/util/Set.html)<[K](../../java/util/Map.html)> |
[**keySet**](../../java/util/Map.html#keySet())()返回此映射中包含的键的 [Set](../../java/util/Set.html)视图。 |
[V](../../java/util/Map.html) |
[**put**](../../java/util/Map.html#put(K, V))([K](../../java/util/Map.html) key, [V](../../java/util/Map.html) value)将指定的值与此映射中的指定键关联(可选操作)。 |
void |
[**putAll**](../../java/util/Map.html#putAll(java.util.Map))([Map](../../java/util/Map.html)<? extends [K](../../java/util/Map.html),? extends [V](../../java/util/Map.html)> m)从指定映射中将所有映射关系复制到此映射中(可选操作)。 |
[V](../../java/util/Map.html) |
[**remove**](../../java/util/Map.html#remove(java.lang.Object))([Object](../../java/lang/Object.html) key)如果存在一个键的映射关系,则将其从此映射中移除(可选操作)。 |
int |
[**size**](../../java/util/Map.html#size())()返回此映射中的键-值映射关系数。 |
[Collection](../../java/util/Collection.html)<[V](../../java/util/Map.html)> |
[**values**](../../java/util/Map.html#values())()返回此映射中包含的值的 [Collection](../../java/util/Collection.html)视图。 |
public class TestMap {public static void main(String[] args) {//实例化一个map集合Map<String,String> maps= new HashMap<>();//1 添加元素(key-value) put(K key, V value)maps.put("apple","苹果");maps.put("actress","女优");maps.put("student","学生");maps.put("teacher","老师");//2 根据key 获得value get(K key):VString actress = maps.get("apple");System.out.println(actress);//3 获得元素个数 size():intSystem.out.println(maps.size());//4 清空全部元素 clear():void//maps.clear();//5 检查键 containsKey(K key):booleanSystem.out.println(maps.containsKey("apple1"));//6 检查值 containsValue(K key):booleanSystem.out.println(maps.containsValue("女优"));//7 移除元素 remove(K key):Vmaps.remove("teacher");System.out.println(maps);}}
Map集合遍历[ 掌握 ]
根据keySet()
Map集合提供了一种视图,这个视图就是可以看见和搜集全部键的集合
/*** Map集合遍历*/public class MapDemo {public static void main(String[] args) {//实例化Map集合Map<String, String> map = new HashMap<>();//添加元素 key要唯一map.put("台湾","周杰伦");map.put("香港","刘德华");map.put("大陆","黄渤");System.out.println("---------------------- keySet()----------------------");Set<String> keySet = map.keySet();for (String key : map.keySet()) {String value = map.get(key);System.out.println(key+":"+value);}}}
根据entrySet()
Map集合提供了一种视图,这个视图就是可以看见和搜集全部的 把键值视为一个整体**(Map.Entry<K,V>)** 的集合。Entry是Map中的内部类类型。
/*** Map集合遍历*/public class MapDemo {public static void main(String[] args) {//实例化Map集合Map<String, String> map = new HashMap<>();//添加元素 key要唯一map.put("台湾","周杰伦");map.put("香港","刘德华");map.put("大陆","黄渤");System.out.println("-----------------------entrySet()---------------------");Set<Map.Entry<String,String>> entries = map.entrySet();for (Map.Entry<String, String> entry : entries) {System.out.println(entry);}}}
遍历全部值values()
Map集合提供了一种视图,这个视图就是可以看见和搜集全部的value,全部的value构成一个Collection
public class MapDemo {public static void main(String[] args) {//实例化Map集合Map<String, String> map = new HashMap<>();//添加元素 key要唯一map.put("台湾","周杰伦");map.put("香港","刘德华");map.put("大陆","黄渤");System.out.println("-----------------------values()------------------------");Collection<String> values = map.values();for (String value : values) {System.out.println(value);}}}
Map 集合实现类区别
HashMap 特点
它是最常用的Map实现类,底层使用 hash表,它是一种(数组+链表+红黑数)数据结构,不保证线程安全。HashSet底层就是使用的HashMap实现的功能,并且只使用了它的Key空间。HashMap的键是**无序**的,且允许包含空键和空值。 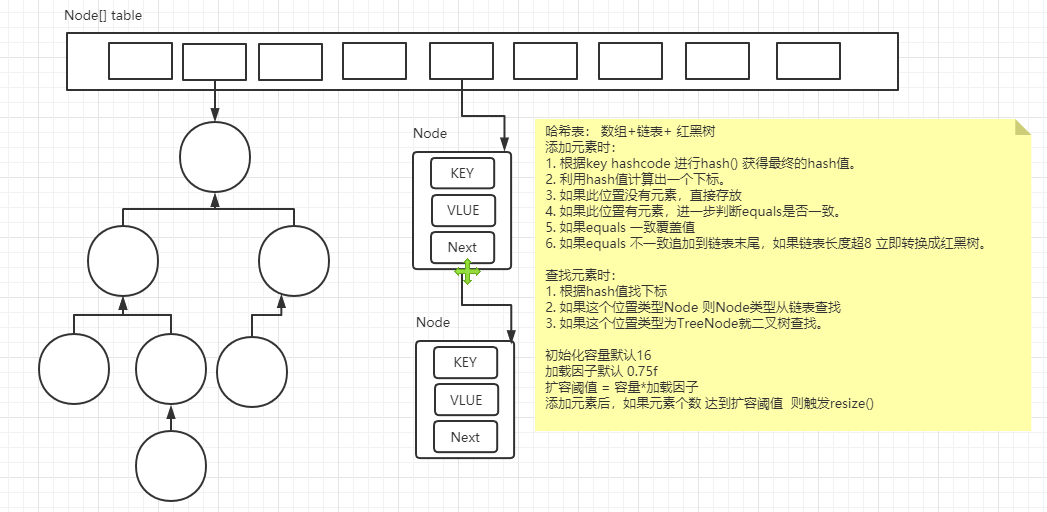
Hashtable 特点
它也是Map实现类,但是它是一个古老映射集合,是jdk1.0的集合,它是线程安全的。实现原理也就是hash表,就是说实现原理和HashMap一样,API兼容。 它不允许出现空键和空值 ,HashMap可以。可以说HashMap的出现就是为了替代Hashtable,Hashtable 几乎不用。
TreeMap 特点
它是一个底层通过红黑树实现,可以把**key进行排序**。TreeSet就是可以把元素排序,应为它的底层就是使用的TreeMap,并就是利用key空间来装元素。
TreeMap 虽然可以对key排序,但是对Key的类型有要求,要求Key类型实现Comparable 接口。 这就是为什么使用TreeSet时元素类型需要实现接口的原因。

若有收获,就点个赞吧
0 人点赞
