小故事
爱因斯坦, 发表了一篇文章, <<相对论>>. 世界上的人都想看. 在没有计算机的时代,通过报纸 邮件进行传递.后来有了计算机.人们可以通过计算机进行数据传递了. 如果谁要就发给谁,那么会很累.所以爱因斯坦想:"我不发了,你们来取". 所以爱因斯坦就找了一台计算机,让它24小时开机,把文章放在这台电脑上,运行了一个程序。谁通过电脑访问这个服务器谁就能够看到文章内容. 这个计算机,我们就管它叫做硬件服务器。同样的运行起来的这个程序,叫作软件服务器。所以服务器就是一台计算机运行了一个程序.这个程序就是服务器,它可以对请求做出响应.下一个问题:有了服务器,可以进行数据的响应.那么就必然要有一个查看方式.这个查看方式就是通过电脑,更准确的说,应该是电脑上的浏览器应用程序(IE、Chrome、FireFox等).下一个问题:服务器和浏览器之间进行数据传递,如何保证看到的就是服务器上的原本的内容呢?于是服务器和浏览器之间就进行了协定:浏览器说:我按照这个格式发送请求服务器说:那我就按照这个格式解析请求服务器说:我按照这个格式进行响应内容浏览器说:那我就按照这个格式解析响应内容于是协议达成,这个协议叫做HTTP协议.后来,牛顿也搭建了一个服务器.此时服务器就有多台.问题来了,如何区分不同的服务器?答案: IP地址 IP是计算机的 唯一身份证。 每台电脑都有一个IP地址。(就好比人类的身份证号)每一台服务器,都应当有一个公网的IP地址。(占据公网的一块区域,为了方便记忆,我们就有了域名)比如: www.aixinsitan.com 转换成IP地址可能是: 10.30.151.23比如: www.niudun.com 转换成IP地址可能是:11.5.232.171但是人类如果去记IP地址,不方便,所以就将IP地址映射成了"域名"域名与IP地址的映射列表所在的地址: DNS服务器 Domain Name Server"根域名"服务器在全球一共13台
服务器
就是计算机,但是与普通计算机有区别: 保密性/安全性/稳定性的不同服务器分硬件和软件,它们一起组成服务器.
浏览器
负责发送请求,请求服务器上的内容并显示出来.
HTTP协议
全称 HyperText Transfer Protocal作用: 规定前后端之间的数据传输的规则
HTTP协议规定了一个请求应当具备的部分以及每一部分的具体信息。
HTTP协议规定一个请求由4部分组成:
请求首行URL和Method请求头相关配置项请求空行空白行请求正文(报文)具体的携带的信息
HTTP请求
浏览器每一次根据HTTP协议,去服务器获取数据的行为,就是一次HTTP请求。
现在我们要学习如何在浏览器中观察HTTP请求的内容
network面板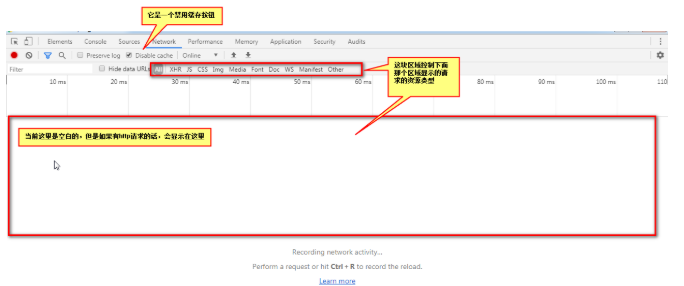
具体的某一个请求的查看方式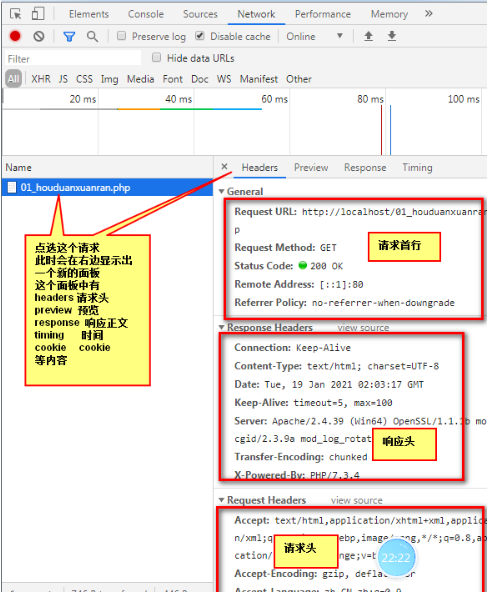
HTTP请求的方式
根据发送HTTP请求的目的,HTTP协议中规定了很多种请求方式。最最常用的,还是get和post。其次我们要知道的请求方式: get、post、put、delete、options、head、patch、connect、traceGET和POST的区别:目的:GET是为了从服务器上获取内容 POST是为了往服务器上传内容GET请求没有请求正文参数携带:GET请求携带在URL的Search部分(Search由一个问号和一个querystring组成)POST放在请求正文中数据容量:GET请求因为携带在URL上,所以受地址栏的长度限制。2KB左右。POST请求容量无限制安全性:POST较好 因为不会被浏览器所记住GET较差 因为会被浏览器的历史记录记住触发方式:GET请求很容易就能触发。地址栏按回车、a标签、video、audio、img、link、script等标签、表单、AJAXPOST请求:只有表单和AJAX能够发送
域名
用于区分不同的服务器的字符串
DNS服务器
域名与IP地址的查找服务器
URL
统一资源定位符 (uniform resource location)
就是我们通常意义上说的网址
URL中规定:一个URL应当由以下部分组成
protocol: 协议 (http、 https)host: 主机 (域名+端口)hostname: 主机名(www.baidu.com、10.30.151.3)port: 80、443、3000等pathname: 资源名称search: 搜索字符串 组成: ?和querystring共同组成hash: 哈希字符串
http://10.30.151.3/index.html?a=1&b=2#vvvvvvvvvvvv协议: http主机: 10.30.151.3端口: 这上面没有但是我们知道是80(因为http协议默认使用)pathname: /index.htmlsearch: ?a=1&b=2hash: #vvvvvvvvvvvvv
URL转码
URL中规定,不可以使用中文等特殊字符。可是有时候我们真的需要传递中文。我们就按照某一定的规则先把中文转为符合要求的编码。就可以携带在URL上了。传递给服务器之后,服务器那边再转回来就可以了。比如 张三 这两个汉字<br />encodeURIComponent这个函数用于转码转码:将不合规则的字符转变成合规则的字符解码:将合规则的字符再转换成原字符
从浏览器输入地址栏,到页面完全展示都经历了什么
1 接收到输入的字符串
2 分析字符串的格式,判定是否是URL
3 将域名转换为ip地址
1 查看浏览器缓存中是否有该域名与ip地址的对应关系 如果有就得到ip地址进行第四步 如果没有本栏目将继续向下2 操作系统也有缓存 查看 如果有 本栏目终止 进行第四步 如果没有继续向下3 路由器缓存4 调用操作系统的一个服务,发送请求去DNS服务器,得到结果。如果没有,就真没有 如果有就得到IP地址了。
4 浏览器会发送TCP请求,申请建立TCP连接。服务器验证,验证通过,连接建立。
5 浏览器开始发送请求内容
6 服务器接收到请求 进行响应
7 浏览器接收到数据(首页html的文件内容)
8 断开连接
9 浏览器开始处理数据
1 建立DOM树2 建立样式树3 DOM树与样式树结合生成渲染树4 浏览器开始渲染页面
10 处理数据的过程中会发现还有更多的资源要请求 此时会重复以上步骤
11 所有资源加载并处理完毕 执行onload事件

若有收获,就点个赞吧
0 人点赞
