近年来人工智能可谓风风火火,掀起一波又一波浪潮,从人脸识别、活体检验发现刑事案件报警到阿尔法狗大战人类围棋手李世石、再到无人驾驶、以及已被普遍应用的精准营销,AI逐步进入人们生活的方方面面。
而 AI是靠数据来喂的,而且是大量优质数据,这一点大部分公司都是无法满足的,即使是很大的公司也也需要别的公司的数据来相互印证。同时国内外监管环境也在逐步加强数据保护,陆续出台相关政策,如欧盟最近引入 的新法案《通用数据保护条例》(GDPR),我国国家互联网信息办公室起草的《数据安全管理办法(征求意见稿)》,因此数据在安全合规的前提下自由流动,成了大势所趋。 安全计算(联邦学习)也在此场景下从小众慢慢变成了必不可少。
安全计算(联邦学习)一个安全的数据交换方式,让数据可以做到 可用不可见,相逢不相识,
密码学算法
差分隐私
假设现在有一个婚恋数据库,2个单身8个已婚,只能查有多少人单身。刚开始的时候查询发现,2个人单身;现在张三跑去登记了自己婚姻状况,再一查,发现3个人单身。所以张三单身。
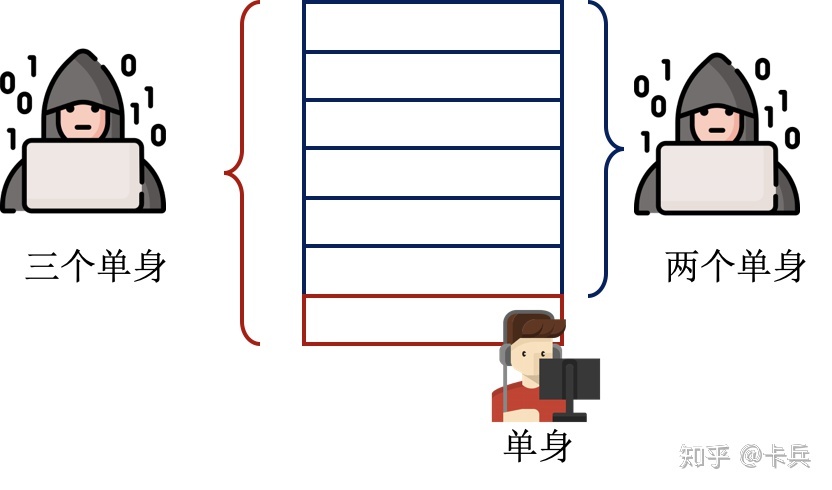
这里张三作为一个样本的的出现,使得攻击者获得了奇怪的知识。而差分隐私需要做到的就是使得攻击者的知识不会因为这些新样本的出现而发生变化。
那么怎么解决这个问题呢?答案是加入噪声,让查有多少人单身返回的数据是随机的,有时候2 ,有时候三,这样张三加进去,也不会被别人发现是单身。
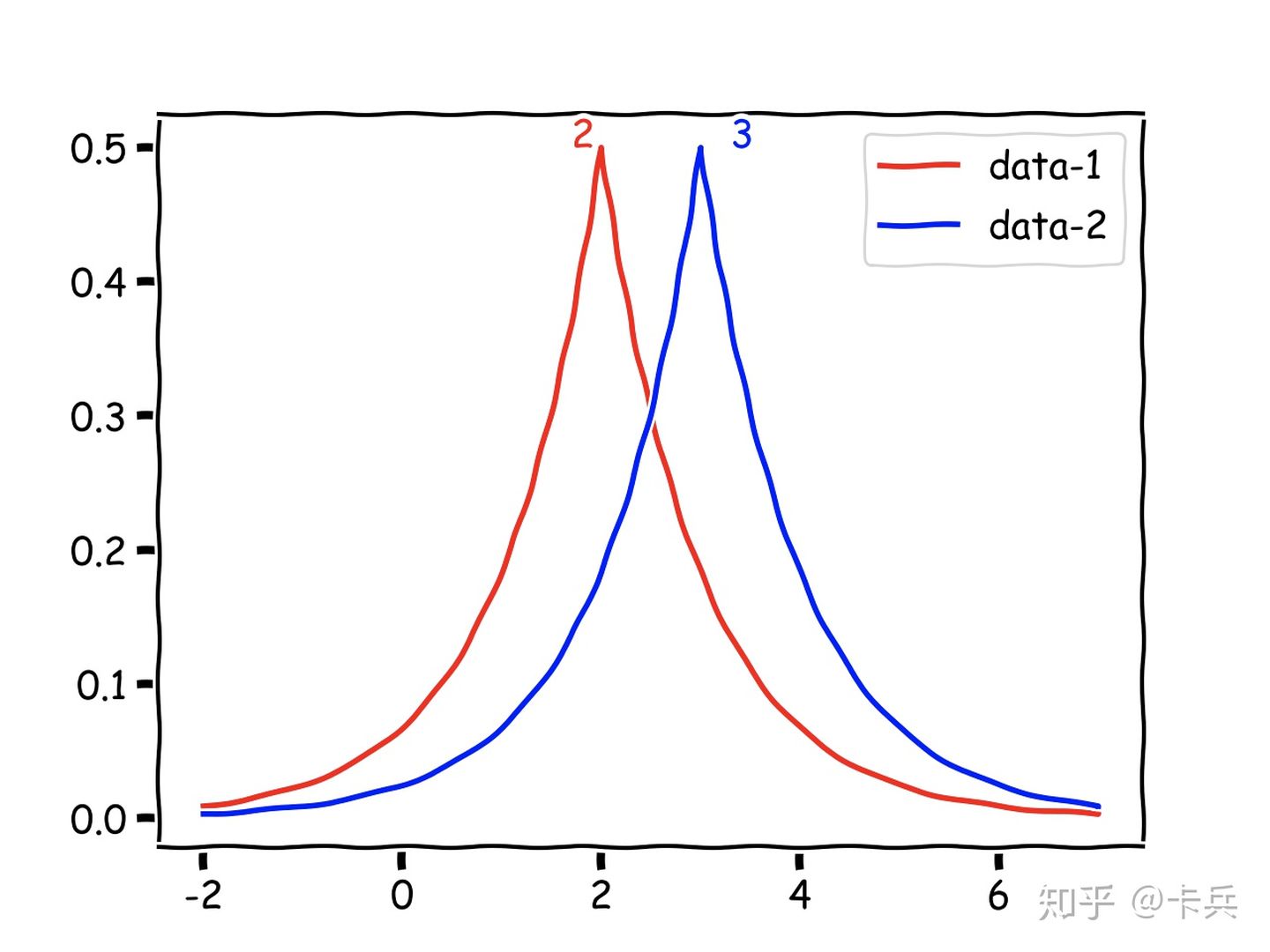
有点像这样的图片,让细节丢失,但是比例是对的,比如下面的图片你还是能看出来是一个风景图,但是山上的建筑物信息丢失了。

同态加密
传统的加密方法和数据处理方法是互斥的,比如我们常用的 ssh 算法,如果加密了之后,就无法对密文进行计算,如果数据拥有方和计算方是同一方,那么知道 1 和 2 没啥问题;但如果数据拥有方和计算方并非同一方,并且数据拥有方还不想让计算方知道这两个数字是 1 和 2,这个时候就是同态加密发挥作用的时候了。
那么同态加密是什么呢? p 是公钥,f 是私钥
这是我能理解的最简单的公式,但是真实的算法过于复杂。
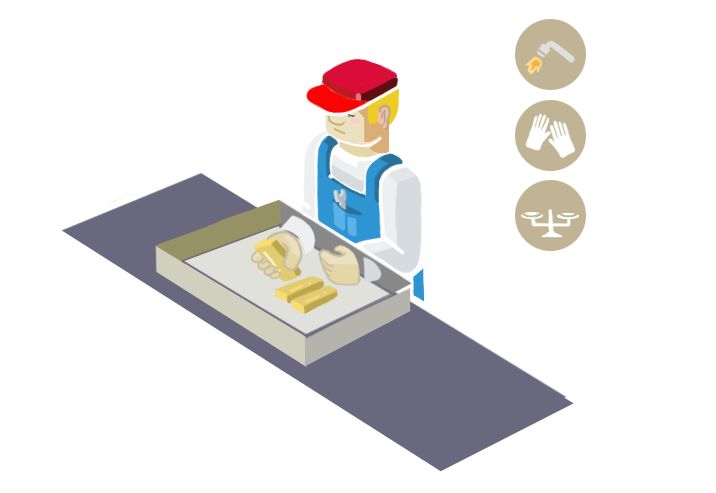
- 盒子:加密算法
- 盒子上的锁:用户密钥
- 将金块放在盒子里面并且用锁锁上:将数据用同态加密方案进行加密
- 加工:应用同态特性,在无法取得数据的条件下直接对加密结果进行处理
- 开锁:对结果进行解密,直接得到处理后的结果
同态加密虽然再安全计算中用的比较多,但是最支持的是云服务厂商,用户总是很担心把隐私数据放到云上来计算,如果有同态加密就可以把计算放到云上,机密的数据就可以在云中计算。这样一来:
- 用户向云服务商付款,得到了处理的结果;
- 云服务商挣到了费用,并在不知道用户数据的前提下正确处理了数据;
零知识证明
零知识证明是一种可在多方交互验证需求中实现隐私保护的密码学方案,用于在不泄露具体数据的情况下对数据知识的掌握或相关计算的正确性进行证明,听起来虽然非常不可理喻,让一方向另一方证明他知道某个问题的答案但却不想透露该问题的具体答案。但是实际上在数学上是可以成立的,下面就是个例子:
A要向B证明自己拥有某个房间的钥匙,假设该房间只能用钥匙打开锁,而其他任何方法都打不开。这时有2个方法:
- A把钥匙出示给B,B用这把钥匙打开该房间的锁,从而证明A拥有该房间的正确的钥匙。
- 确定该房间内有某一物体,A用自己拥有的钥匙打开该房间的门,然后把物体拿出来出示给B,从而证明自己确实拥有该房间的钥匙。
零知识证明大多数情况下是作为一种辅助技术存在的,可以大大提升效率,在区块链应用中,对于不同参与方的数据交互验证可采用零知识证明技术实现,避免敏感信息的相互泄露;在安全多方计算应用中,参与双方可在通过同态加密等方法保护的隐私计算完成后要求互相提供计算过程的零知识证明结果进行验证,防止虚假计算,同时又不会泄露计算过程中的敏感信息。
不经意传输
流程:
1. 发送者Alice生成两对rsa公私钥,并将两个公钥puk0、puk1发送给接受者Bob。
Bob生成一个随机数,并用收到的两个公钥之一加密随机数(用哪个秘钥取决于想获取哪条数据,例如如果想要得到消息M0 就用puk0加密随机数,如果想要得到M1就用puk1加密随机数),并将密文结果发送给Alice。
Alice用自己的两个私钥分别解密收到随机数密文,并得到两个解密结果k0,k1,
并将两个结果分别与要发送的两条信息进行异或(k0异或M0,k1异或M1),并将两个结果e0,e1发给Bob。Bob用自己的真实随机数与收到的e0、e1分别做异或操作,得到的两个结果中只有一条为真实数据,另外一条为随机数。
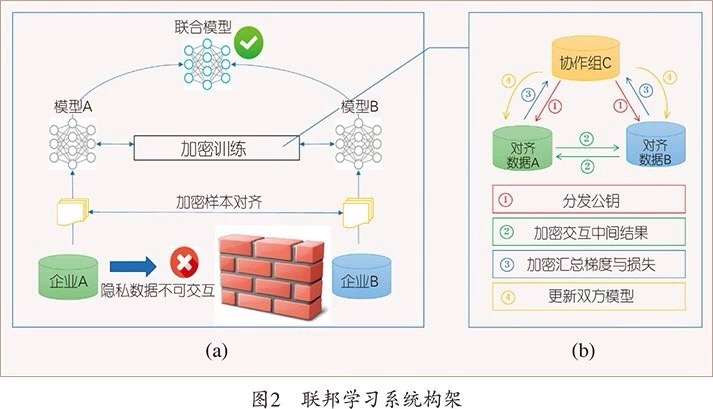
联邦学习
什么是联邦学习呢?举例来说,假设有两个不同的企业 A 和 B,它们拥有不同的数据,比如企业 A 有用户特征数据,企业 B 有产品特征数据和标注数据。这两个企业按照 GDPR 准则是不能粗暴地把双方数据加以合并的,因为他们各自的用户并没有机会同意这样做。
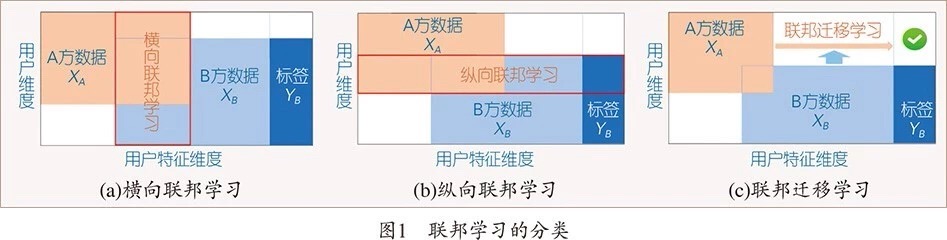
在确定共有用户群体后,就可以利用这些数据训练机器学习模型。为了保证训练过程中数据的保密性,需要借助第三方协作者 C 进行加密训练。以线性回归模型为例,训练过程可分为以下 4 步:
- 协作者 C 把公钥分发给 A 和 B,用以对训练过程中需要交换的数据进行加密。
- A 和 B 之间以加密形式交互用于计算梯度的中间结果。
- A 和 B 分别基于加密的梯度值进行计算,同时 B 根据其标签数据计算损失,并把结果汇总给 C。C 通过汇总结果计算总梯度值并将其解密。
- C 将解密后的梯度分别回传给 A 和 B,A 和 B 根据梯度更新各自模型的参数。

若有收获,就点个赞吧
0 人点赞
