- Redis基础
- 1.非关系型数据库和关系型数据库的对比
- 2.什么是Redis
- 3.Redis的应用场景
- 4.Redis数据类型
- 5.Redis 持久化怎么实现
- 6.Redis持久化实现方式对比
- 7.Redis的缓存失效策略和主键失效策略机制
- 8.Redis中一个字符串的值最大能存储多大容量?
- 9.redis 过期键的删除策略
- 10.为什么 Redis需要把所有的数据都放在内存中?
- 11.Redis 是单进程线程的吗?
- 12.假如 Redis 里面有 1 亿个key,其中有10W个key 是以某个固定的已知的前缀开头的,如何将它们全部找出来?
- 13.如果有大量的 key 需要设置同一时间过期,一般需要注意什么?
- 14.什么是缓存雪崩?解决方案是什么?
- 15.什么是缓存穿透?解决方案是什么?
- 16.什么是缓存击穿?解决方案是什么?
- 17.什么是缓存预热?解决方案是什么?
- 18.什么是缓存降级
- 19.Redis 事务的概念
Redis基础
1.非关系型数据库和关系型数据库的对比
- 非关系数据库优点
- 成本:nosql数据库部署简单,基本上都是开源软件,不需要像使用oracle那边花费大量成本购买使用,相比关系型数据库比较便宜。
- 查询速度:nosql数据库将数据存储在缓存中,关系型数据库将数据存储在硬盘中,自然查询速度远不及nosql数据库
- 扩展性:关系型数据库有类似join这样的多表连接查询导致扩展非常的难,nosql基于键值对,数据之间没有耦合性,容易水平扩展。
- 非关系数据库缺点
- 维护的工具的资料有限,nosql是新技术,不能和关系型数据库10几年的技术相比
- 不提供对sql的支持,如果不支持sql这样的工业标准,有用户学习和使用的成本
- 不提供关系型数据库对事务的处理
- 关系型数据库优势
- 复杂查询可以用SQL语句方便的在一个表或者多个表之间查询
- 事务的支持使对于安全性能很高的数据访问要求得以实现
关系型数据库与 NoSql 数据库非对立而是互补的关系,既通常情况下使用关系型数据库,在适合使用 NoSql 弥补非关系型数据库的不足。一般会将数据存储在关系型数据库中,在 NoSql 数据库中存储备份数据
2.什么是Redis
- 开源,Redis是完全开源的,遵守 BSD 协议,是一个高性能的 key-value 数据库
- 支持数据持久化,可以将内存中的数据存储在磁盘里面,重启的时候可以再次加载进行使用
- 丰富的数据类型,不仅仅支持简单的 key-value 类型数据, 同时还提供了 list、set、zset、string 等数据结构
- 支持数据备份,既 master-slave 模式的数据备份
- 性能高,读的性能是 11000 次/s,写的速度是 81000 次/s
- 原子,Redis所有的操作都是原子性的,要么成功执行要么失败完全不执行,单个操作是原子性的。多个操作也支持事务,通过 MULTI 和 EXEC指令包其起来。
- 丰富的特性,还支持 publish/subscribe 通知 key过期等
3.Redis的应用场景
- 缓存 (数据查询,短连接,新闻内容,字典)
- 聊天室的在线好友列表
- 任务队列 (秒杀,抢购,12306等)
- 应用排行榜
- 网站访问统计
- 数据过期处理
- 分布式集群架构的session
4.Redis数据类型
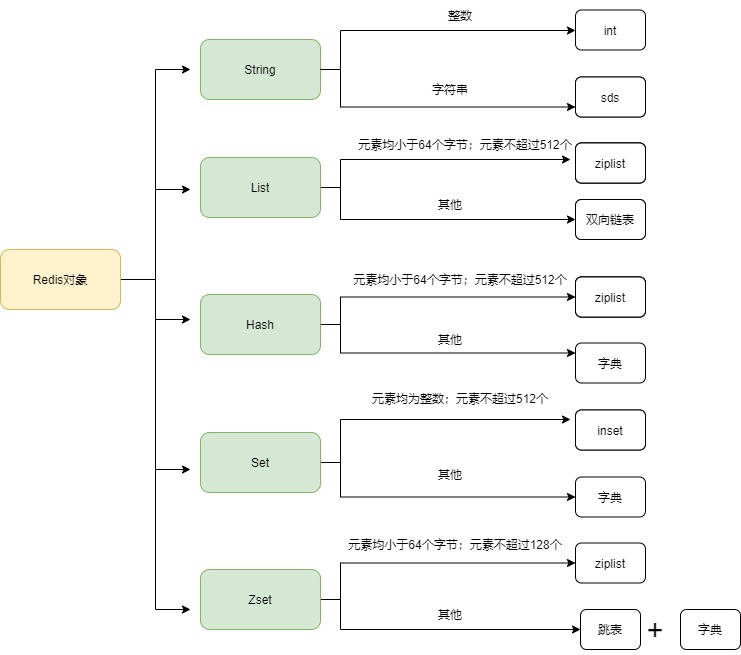
| 数据类型 | 可以存储的值 | 底层实现 | 应用场景 |
|---|---|---|---|
| String | 字符串、整数、浮点数 | long、double、SDS 动态字符串 | 做简单的键值对缓存 |
| List | 列表 | ziplist(压缩表),linkedList(链表) | 存储一些列表型数据结构,类似于粉丝列表,文章评论列表之类的数据 |
| Hash | 包含键值对的无序散列表 | ziplist、hashTble(字典) | 结构化的数据,比如一个对象 |
| Set | 无序集合 | intset(整数),hashTable | 交集、并集、差集的操作,比如交集,可以把两个人粉丝列表整一个交集 |
| Zset | 有序集合 | ziplist,skipList(跳跃表) | 去重但可以排序,如获取排名前几名的用户 |
5.Redis 持久化怎么实现
Redis 的数据全部存储在内存里面,如果宕机, 数据就会全部的丢失, 因此必须有一种机制来保证 Redis 的数据不会因为故障而丢失, 这种机制就是 Redis 的持久化。目前有两种:1.RDB快照,2. AOF 日志。快照是一次全量的备份,AOF日志是连续的增量备份。快照是内存数据二进制序列化的形式,在存储上非常的紧凑,而 AOF 日志记录是内存数据的修改,指令记录文本。
6.Redis持久化实现方式对比
RDB 模式
RDB 模式持久化 是把当前进程数据生成快照保存到硬盘的过程,触发RDB持久化过程分为手动触发和自动触发。
优点:
- 与AOF相比,通过rdb文件恢复数据快。
- rdb数据非常紧凑,适合于数据备份。
- 通过 RDB 进行数据备份,由于使用子进程生成,对Redis 服务器的性能影响较小。
缺点:
- 如果服务器宕机,采用 RDB 会造成某个时间段内的数据丢失, 比如我们设置10分钟同步一次或者5分钟 达到1000次就同步一次,那么还没达到这个条件 服务器就死机了,那么这个时间段内的数据就会丢失
- 使用 save 命令会造成服务器的阻塞, 直到数据同步完成后才能接受后续请求
- 使用 bgsave 命令 在forks子进程时, 如果数据量太大, forks 的过程中也会发生阻塞, 另外, fork子进程也会耗费内存
AOF模式
AOF (append only file)持久化: 以独立的日志的方式记录每次写命令,重启时再重新执行 AOF 中的命令 达到恢复数据目的。解决了数据持久化的实时性,目前是redis的主流方式。
AOF 模式在配置文件中可以通过 appendfsync 选项中指定写入策略,有三个选项
- always 客户端在每一个写操作都保存到aof文档当中,这种策略很安全,但是每一个请求都有IO操作,所以也很慢
- everysec appendfsync 默认写入策略,每秒写入一次 aof 文件, 因此,最多可能会丢失1s的数据
- no Redis 服务器不负责写入 aof,而是 交由操作系统来处理什么时候写入 aof 文件。更快,但也是最不安全的选择。不推荐使用。
优点
只是追加日志文件,因此对服务器的性能影响比较小,速度比RDB要快,消耗的内存比较小
缺点
- AOF生成的文件太大了,即使通过AFO重写,文件的体积任然很大
- 恢复数据速度比RDB慢 | 方式 | RDB | AOF | | —- | —- | —- | | 启动优先级 | 低 | 高 | | 体积 | 小 | 大 | | 恢复速度 | 快 | 慢 | | 数据安全性 | 会丢数据 | 由策略决定 | | 轻重 | 重 | 轻 |
当RDB 与 AOF 两种方式都开启时候, Redis 会优先使用 AOF 日志 来恢复数据, 因为 AOF 保存的文件比 RDB 文件更完整。
7.Redis的缓存失效策略和主键失效策略机制
作为缓存系统都要定期清理无用的数据,需要一个主键失效和淘汰策略,在redis中有生存期的key被称为 volatile。在创建缓存时,要给定的key设置生存时间,当key 过期时候(生存期为0),它就会被删除。
影响生存时间的一些操作生存时间可以通过使用 DEL 命令来 删除整个 key,或者被 SET 和 GERSET 命令来覆盖原来的数据,修改key对应的 value 和使用另外相同的kay和 value 来覆盖之后,当前数据的生存时间不同。 比如说,对一个 key 执行 INCR 命令,对一个列表进行 LPUSH 命令, 或者对一个 HASH表 执行 HSET命令,这类查询的操作都不会修改 key 原本的生存空间。另一方面,如果使用 RENAME 对一个 key 进行改名,那么改名后的 key 生存时间和改名一样。 RENAME 命令的另外一种可能是,尝试将一个带生存空间的 key 改名为另外带生存时间的 another_key,这时旧的 another_key(以及他的生存空间) 会被删除,然后旧的 key 会改名为 another_key, 因此,新的 another_key 的生存空间也和原来的 key 一样。使用 PERSIST 命令可以在不删除 key 的情况下,移除 key 的生存时间, 让 key 重新成为一个新的 persistent key。
如何更新生存时间可以对一个已经有生存时间的 key 执行 EXPIRE 命令,新指定的生存时间会取代旧的生存时间。过期时间的精度已经被控制在1ms之内,主键的失效复杂度是O(),EXPIRE 和 TTL 命令搭配使用,TTL可以查看 key当前的生存时间。设置成功返回 1 。当 key 不存在或者不能为 key 设置的生存时间时,返回0。
最大缓存配置
在redis中,允许用户设置最大使用内存大小 server.maxmermory, 默认为 0,没有指定最大缓存,如果有新的数据添加,超过了最大内存,则会使 redis 奔溃,所以一定要设置。redis 内存数据集达到一定大小时候,就会实行数据淘汰策略。
Redis 提供6种淘汰策略:
- volatile-lru: 从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
- volatile-ttl: 从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰。
- volatile-random: 从已设置过期时间的数据集(server.db[i].expires)中任意数据淘汰
- allkeys-lru: 从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
- allkeys-random: 从数据集(server.db[i].dict) 中挑选任意数据淘汰
- no-enviction(驱逐): 禁止驱逐数据
使用策略:如果缓存中的数据呈现幂律分布,也是一部分高,一部分低,则使用 allkeys-lru;如果数据呈平等分布,也就是数据的访问频率都相同,则使用allkeys-random
8.Redis中一个字符串的值最大能存储多大容量?
512M
9.redis 过期键的删除策略
- 定期删除: 在设置键的过期时间同时,创建一个定时器 timer,让定时器在过期的同时来定时,执行对键的删除操作
- 惰性删除: 放任键的过期不管,但是每次从键空间获取键时候,都检查取的键是否过期,过期话就删除该键;如果没有过期,就返回该键
- 定期删除: 每隔一段时间就对数据库进行检查,删除里面过期的键。至于要删除多少过期键,以及检查多少个数据库
10.为什么 Redis需要把所有的数据都放在内存中?
Redis 为了达到最快的读写速度将数据都读到内存中,并通过异步方式将数据写入磁盘。所以 redis 具有快速和数据持久化的特征。如果不将数据放在内存中,磁盘 I/O 速度会严重影响到 redis 的性能。在内存越来越越便宜的今天, redis 将会越来越越受欢迎。 如果设置了最大使用内存,则数据已有记录数达到内存限值后将不能继续插入新值。
11.Redis 是单进程线程的吗?
Redis是单进程单线程的,redis 利用队列技术将并发访问换为串行访问,消除了传统数据库
12.假如 Redis 里面有 1 亿个key,其中有10W个key 是以某个固定的已知的前缀开头的,如何将它们全部找出来?
使用 keys 指令可以扫出指定模式的 key 列表
如果这个redis正在给线上的业务提供服务,那使用keys会导致线程阻塞一段时间,线上的服务会停顿,直到指令执行完毕,服务才能恢复。
这时候可以使用 scan 指令, scan指令可以无阻塞的提取出指定模式的 key列表,但是有一定的几率重复,在客户端做一次去重就可以了。
13.如果有大量的 key 需要设置同一时间过期,一般需要注意什么?
如果大量的 key 的过期时间设置的过于集中, 到过期的那个时间点可能会出现 redis 卡顿的现象。一般要在过期时间上面设置一个随机值,使得过期的时间分散一些。
14.什么是缓存雪崩?解决方案是什么?
缓存在同一时间出现大面积的过期,导致访问缓存的请求都到查询数据库里面去,从而对数据库CPU和内存造成巨大的压力,严重会导致数据库宕机,从而导致系统的奔溃。
- 当并发量不高的时候加锁等待
- 缓存数据过期时间设置随机,防止同一时间缓存大量过期
15.什么是缓存穿透?解决方案是什么?
查询数据库或者缓存中没有的数据,导致所有的请求都落在数据库上,造成了数据库短时间承受巨大的请求而崩掉。
- 增加业务逻辑校验,不符合规范的的查询直接先过滤掉
- 当一个数据在缓存或者数据库中都没有的时候,可以先设置一个 key-null 的键值对在缓存中, 设置比较短的过期时间, 比如 30s
- 使用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap 中, 一定不存在的数据会被这个 bitmap 给过滤掉,从而避免对于底层数据库的压力
布隆过滤器: 可以判断一个元素是否存在
它会采用多个不同的哈希函数来将一个元素映射到 bitmap 中。当需要判断一个元素是否存在时, 只需要通过这些哈希函数对元素进行映射,如果映射的位置都存在,则可以判断该元素存在;反之只要有一个哈希函数的映射不存在,则该元素不存在
16.什么是缓存击穿?解决方案是什么?
指一个key非常热点,在不停扛着大并发,大并发集中对这个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求到数据库,造成数据库的压力过大。与缓存雪崩不同,缓存击穿是指并发着一条数据,一个key,而缓存雪崩是发生在大面积的缓存过期(很多数据在缓存中查不到,从而查数据库)
- 设置热点永不过期
- 通过 setnx 加互斥锁(一次只能有一个请求访问,访问完后释放锁后其他请求才能继续访问)
17.什么是缓存预热?解决方案是什么?
就是系统上线之后,将相关的缓存直接加载到缓存系统中,这样就避免用户在请求的时候先查数据库,再更新缓存。用户可以直接查询预热的数据。
- 定时刷新数据
- 上线后手动操作
18.什么是缓存降级
当访问剧增、服务出现问题(如响应慢或不响应)或非核心业务影响到核心业务流程的时候,即使是有损于服务。系统可以根据一些关键的数据进行自动降级,也可以配置开关实现人工降级。
在进行降级之前要对系统进行梳理,看系统是不是可以丢卒保帅,比如可以参考日志级别设置的预案:
- 一般: 比如一些服务偶尔因为网络波动或者服务升级而超时,可以自动降级;
- 警告:有些服务在一段时间内成功率有波动(如在95%-100% 之间),可以自动自动降级或者人工降级,并且发出告警;
- 错误:比如可用率低于90%,或者数据库连接池被打爆或者达到系统能承受最大阈值,此时可以根据情况自动降级或者人工降级
- 严重错误:比如因为特殊的原因数据错误了,此时需要紧急的人工降级。
服务降级的目的就是为了防止 Redis 服务故障,导致数据库跟着一起发生雪崩。因此,对于不重要的缓存数据,可以采取服务降级的策略。比如一个比较常见的做法就是 Redis 出现问题时候,不去数据库查询,而是直接返回默认值给用户。
19.Redis 事务的概念
Redis 事务的本质是通过 MULTI,EXEC, WATCH 等一组命令的集合。事务支持一次执行多个命令,一个事务中所有命令都会被序列化队列中的命令,其他客户端提交的命令请求不会插到事务执行命令中。
redis 的事务就是一次性、顺序性、排他性的执行一个队列中的一系列命令。
20.Redis事务的三个阶段
- 事务开始 MULTI
- 命令入队
- 事务执行 EXEC
21. Redis事务相关命令
Redis 事务功能是通过 MULTI, EXEC, DISCANRD 和 WATCH 四个原语实现的
将一个事务中的所有命令序列化,然后按顺序执行
- redis 不支持回滚,在事务失败的时候不进行回滚,而是继续执行余下的命令, 所以 Redis的内部可以保持简单且快速
- 如果在一个事务中的命令出现错误,那么所有的命令都不会执行(这句话的意思是指在MULTI之后将命令加入到命令队列的过程中,某条命令出现语法错误,则这次事务不会执行)
- 如果在一个事务中出现运行错误,那么正确的命令会被正常执行。(在命令已经全部加到命令队列之后,执行EXEC命令开始执行命令队列中的命令时候发生错误,错误的命令不会被执行,而正确的命令依旧会被执行)

若有收获,就点个赞吧
0 人点赞
