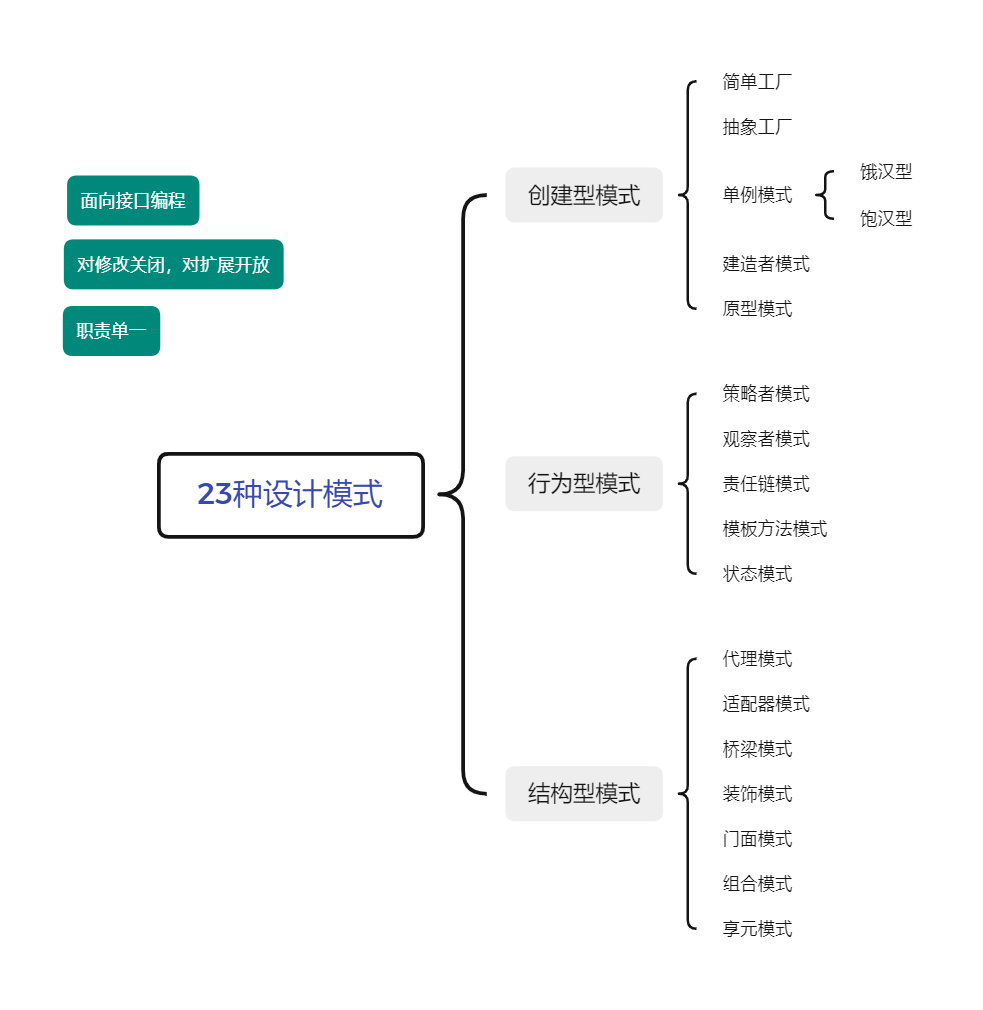
创建型模式
Factory Pattern(工厂方法模式)
public class FoodFactory {public static Food makeFood(String name) {if (name.equals("noodle")) {Food noodle = new LanZhouNoodle();noodle.addSpicy("more");return noodle;} else if (name.equals("chicken")) {Food chicken = new HuangMenChicken();chicken.addCondiment("potato");return chicken;} else {return null;}}}
其中,LanZhouNoodle 和 HuangMenChicken 都继承自 Food。
简单地说,简单工厂模式通常就是这样,一个工厂类 XxxFactory,里面有一个静态方法,根据我们不同的参数,返回不同的派生自同一个父类(或实现同一接口)的实例对象。
我们强调职责单一原则,一个类只提供一种功能,FoodFactory 的功能就是只要负责生产各种 Food。
简单工厂模式很简单,如果它能满足我们的需要,我觉得就不要折腾了。之所以需要引入工厂模式,是因为我们往往需要使用两个或两个以上的工厂。
public interface FoodFactory {Food makeFood(String name);}public class ChineseFoodFactory implements FoodFactory {@Overridepublic Food makeFood(String name) {if (name.equals("A")) {return new ChineseFoodA();} else if (name.equals("B")) {return new ChineseFoodB();} else {return null;}}}public class AmericanFoodFactory implements FoodFactory {@Overridepublic Food makeFood(String name) {if (name.equals("A")) {return new AmericanFoodA();} else if (name.equals("B")) {return new AmericanFoodB();} else {return null;}}}
其中,ChineseFoodA、ChineseFoodB、AmericanFoodA、AmericanFoodB 都派生自 Food。
客户端调用:
public class APP {public static void main(String[] args) {// 先选择一个具体的工厂FoodFactory factory = new ChineseFoodFactory();// 由第一步的工厂产生具体的对象,不同的工厂造出不一样的对象Food food = factory.makeFood("A");}}
第一步,我们需要选取合适的工厂,然后第二步基本上和简单工厂一样。
核心在于,我们需要在第一步选好我们需要的工厂。比如,我们有 LogFactory 接口,实现类有 FileLogFactory 和 KafkaLogFactory,分别对应将日志写入文件和写入 Kafka 中,显然,我们客户端第一步就需要决定到底要实例化 FileLogFactory 还是 KafkaLogFactory,这将决定之后的所有的操作。
虽然简单,不过我也把所有的构件都画到一张图上,这样读者看着比较清晰
Abstract Factory Pattern(抽象工厂模式)
当涉及到产品族的时候,就需要引入抽象工厂模式了。
一个经典的例子是造一台电脑。我们先不引入抽象工厂模式,看看怎么实现。
因为电脑是由许多的构件组成的,我们将 CPU 和主板进行抽象,然后 CPU 由 CPUFactory 生产,主板由 MainBoardFactory 生产,然后,我们再将 CPU 和主板搭配起来组合在一起,如下图: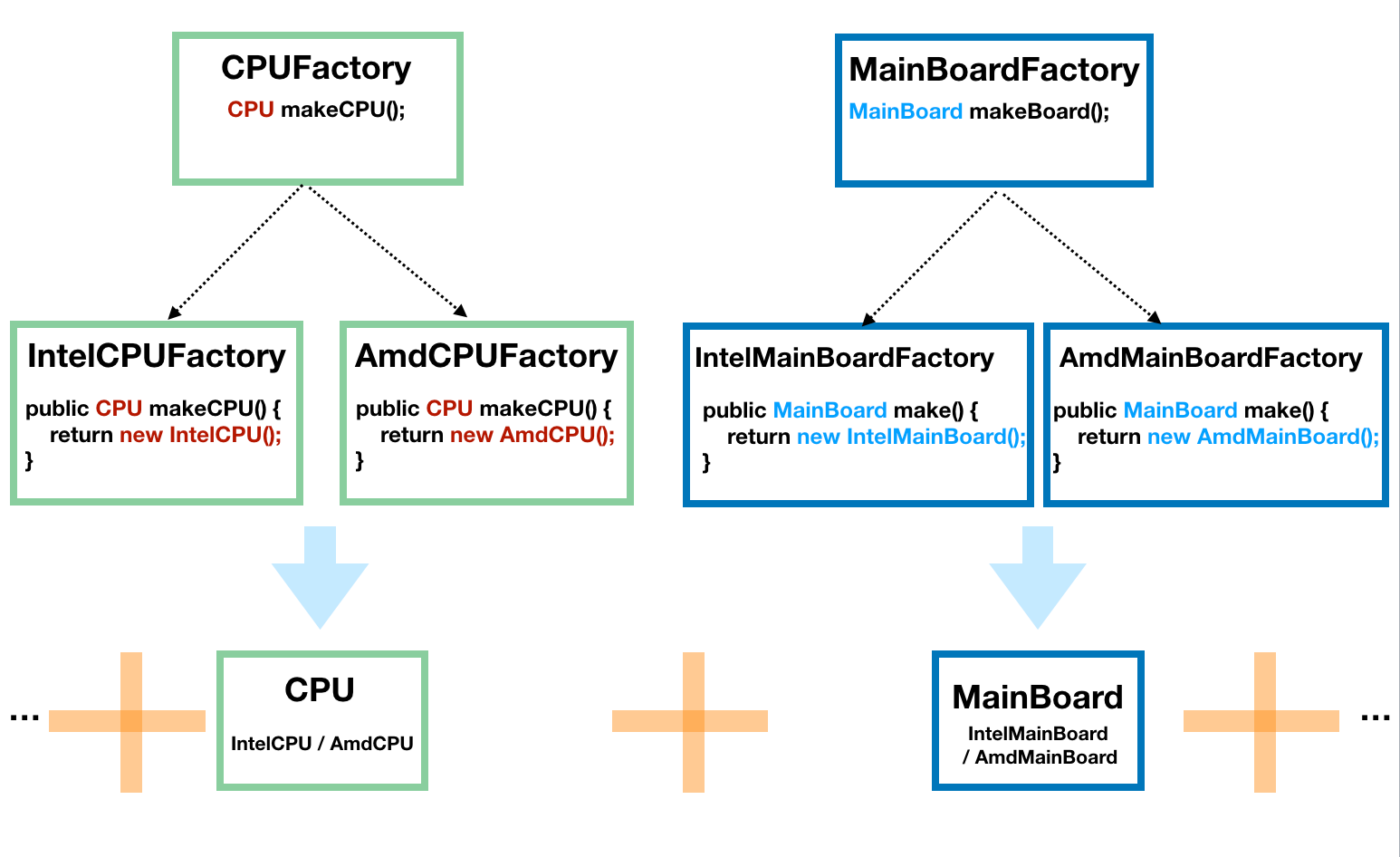
这个时候的客户端调用是这样的:
// 得到 Intel 的 CPUCPUFactory cpuFactory = new IntelCPUFactory();CPU cpu = intelCPUFactory.makeCPU();// 得到 AMD 的主板MainBoardFactory mainBoardFactory = new AmdMainBoardFactory();MainBoard mainBoard = mainBoardFactory.make();// 组装 CPU 和主板Computer computer = new Computer(cpu, mainBoard);
单独看 CPU 工厂和主板工厂,它们分别是前面我们说的工厂模式。这种方式也容易扩展,因为要给电脑加硬盘的话,只需要加一个 HardDiskFactory 和相应的实现即可,不需要修改现有的工厂.
但是,这种方式有一个问题,那就是如果 Intel 家产的 CPU 和 AMD 产的主板不能兼容使用,那么这代码就容易出错,因为客户端并不知道它们不兼容,也就会错误地出现随意组合。
下面就是我们要说的产品族的概念,它代表了组成某个产品的一系列附件的集合: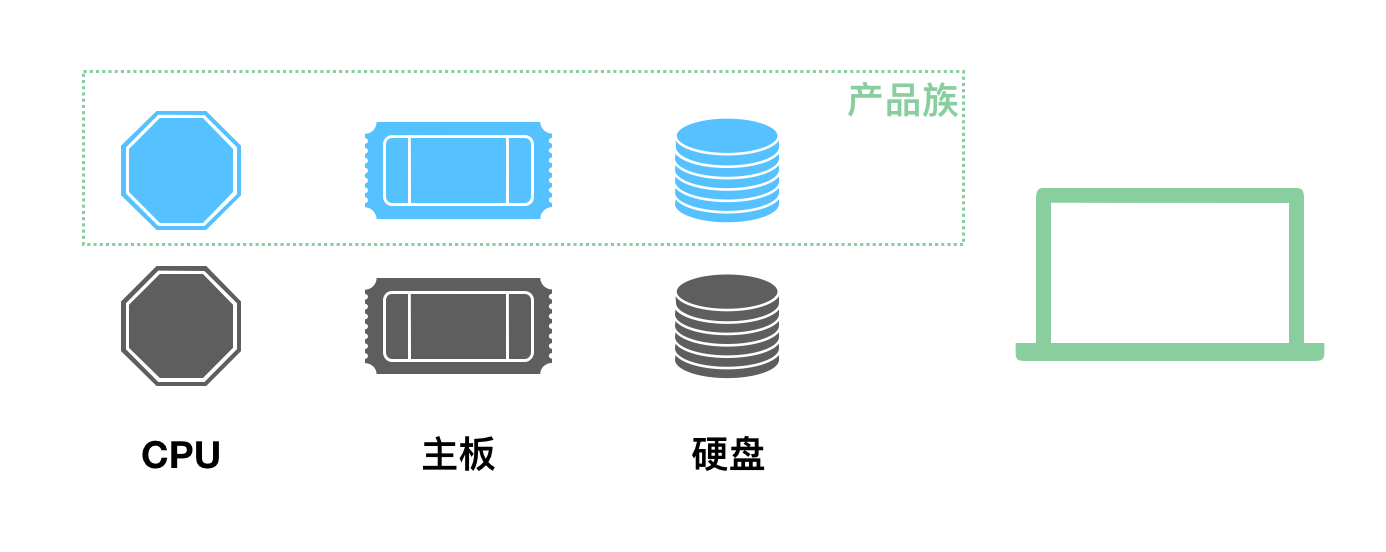
当涉及到这种产品族的问题的时候,就需要抽象工厂模式来支持了。我们不再定义 CPU 工厂、主板工厂、硬盘工厂、显示屏工厂等等,我们直接定义电脑工厂,每个电脑工厂负责生产所有的设备,这样能保证肯定不存在兼容问题。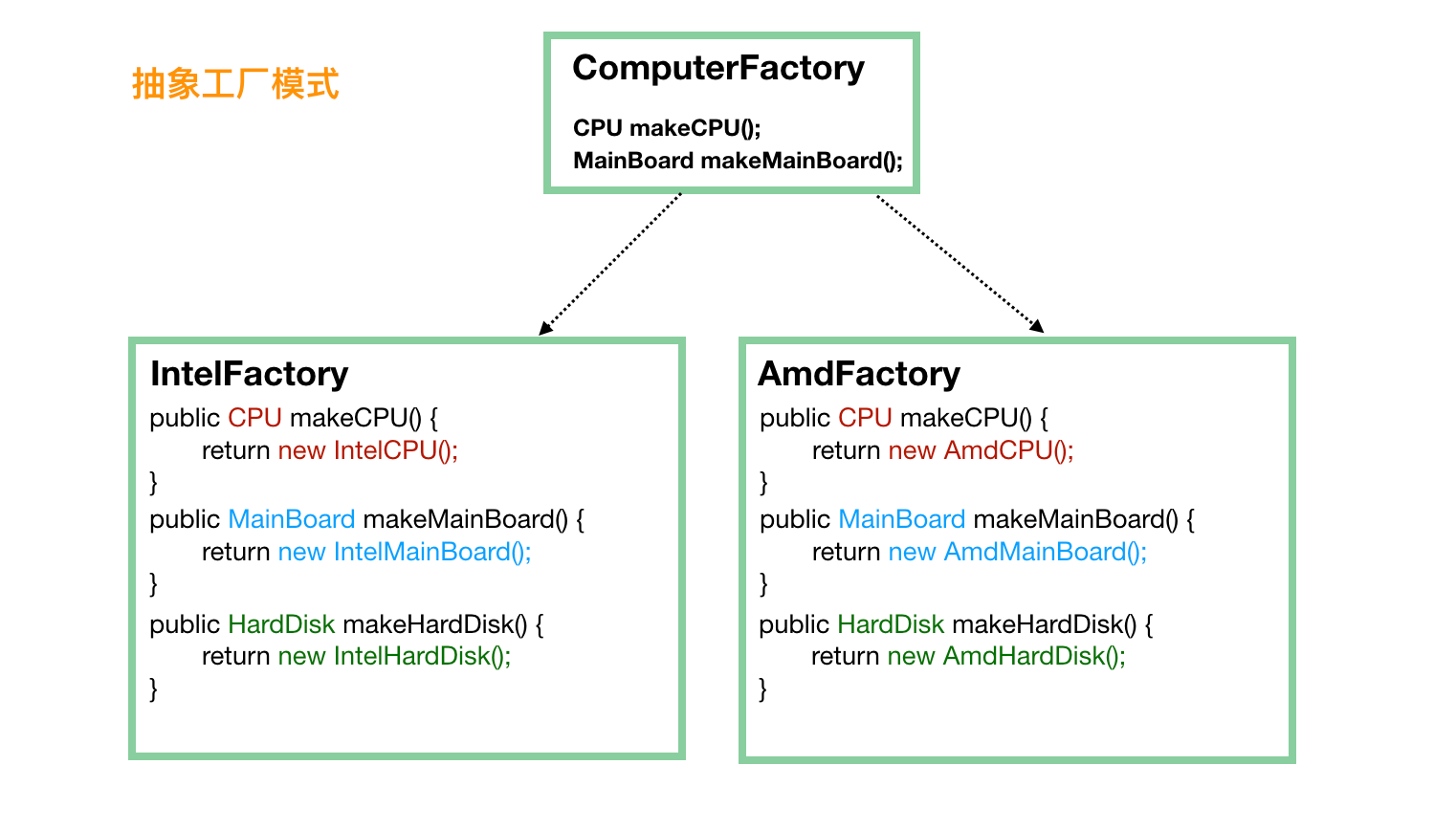
这个时候,对于客户端来说,不再需要单独挑选 CPU厂商、主板厂商、硬盘厂商等,直接选择一家品牌工厂,品牌工厂会负责生产所有的东西,而且能保证肯定是兼容可用的。
public static void main(String[] args) {// 第一步就要选定一个“大厂”ComputerFactory cf = new AmdFactory();// 从这个大厂造 CPUCPU cpu = cf.makeCPU();// 从这个大厂造主板MainBoard board = cf.makeMainBoard();// 从这个大厂造硬盘HardDisk hardDisk = cf.makeHardDisk();// 将同一个厂子出来的 CPU、主板、硬盘组装在一起Computer result = new Computer(cpu, board, hardDisk);}
当然,抽象工厂的问题也是显而易见的,比如我们要加个显示器,就需要修改所有的工厂,给所有的工厂都加上制造显示器的方法。这有点违反了对修改关闭,对扩展开放这个设计原则。
Singleton Pattern(单例模式)
看几个单例对象的示例代码,其中有些代码是线程安全的,有些则不是线程安全的,需要大家细细品味.
代码一:SingletonExample1
public class SingletonExample1 {private SingletonExample1(){}private static SingletonExample1 instance = null;public static SingletonExample1 getInstance(){//多个线程同时调用,可能会创建多个对象if (instance == null){instance = new SingletonExample1();}return instance;}}
代码二:SingletonExample2
public class SingletonExample2 {private SingletonExample2(){}private static SingletonExample2 instance = new SingletonExample2();public static SingletonExample2 getInstance(){return instance;}}
代码三:SingletonExample3
public class SingletonExample3 {private SingletonExample3(){}private static SingletonExample3 instance = null;public static synchronized SingletonExample3 getInstance(){if (instance == null){instance = new SingletonExample3();}return instance;}}
代码四:SingletonExample4
public class SingletonExample4 {private SingletonExample4(){}private static SingletonExample4 instance = null;public static SingletonExample4 getInstance(){if (instance == null){synchronized (SingletonExample4.class){if(instance == null){instance = new SingletonExample4();}}}return instance;}}
线程不安全分析如下:
当执行instance = new SingletonExample4();这行代码时,CPU会执行如下指令:
1.memory = allocate() 分配对象的内存空间
2.ctorInstance() 初始化对象
3.instance = memory 设置instance指向刚分配的内存
单纯执行以上三步没啥问题,但是在多线程情况下,可能会发生指令重排序。
指令重排序对单线程没有影响,单线程下CPU可以按照顺序执行以上三个步骤,但是在多线程下,如果发生了指令重排序,则会打乱上面的三个步骤。
如果发生了JVM和CPU优化,发生重排序时,可能会按照下面的顺序执行:
1.memory = allocate() 分配对象的内存空间
3.instance = memory 设置instance指向刚分配的内存
2.ctorInstance() 初始化对象
假设目前有两个线程A和B同时执行getInstance()方法,A线程执行到instance = new SingletonExample4(); B线程刚执行到第一个 if (instance == null){处,如果按照1.3.2的顺序,假设线程A执行到3.instance = memory 设置instance指向刚分配的内存,此时,线程B判断instance已经有值,就会直接return instance;而实际上,线程A还未执行2.ctorInstance() 初始化对象,也就是说线程B拿到的instance对象还未进行初始化,这个未初始化的instance对象一旦被线程B使用,就会出现问题。
代码五:SingletonExample5
懒汉模式(双重锁同步锁单例模式)单例实例在第一次使用的时候进行创建,这个类是线程安全的,使用的是 volatile + 双重检测机制来禁止指令重排达到线程安全
public class SingletonExample5 {private SingletonExample5(){}//单例对象 volatile + 双重检测机制来禁止指令重排private volatile static SingletonExample5 instance = null;public static SingletonExample5 getInstance(){if (instance == null){synchronized (SingletonExample5.class){if(instance == null){instance = new SingletonExample5();}}}return instance;}}
Builder Pattern(建造者模式)
Prototype Pattern(原型模式)
行为型模式
Strategy Pattern(策略模式)
策略模式定义了算法族,分别封装起来,让它们之间可以相互替换,此模式让算法的变化独立于使用算法的的客户。策略模式针对一组算法,将每一个算法封装到具有共同接口的独立的类中,从而使得它们可以相互替换。可以减少代码的if else if。。。。等结构
if(type=="A"){//按照A格式解析}else if(type=="B"){//按B格式解析}else{//按照默认格式解析}
- 一个接口或者抽象类,里面两个方法(一个方法匹配类型,一个可替换的逻辑实现方法)
- 不同策略的差异化实现(就是说,不同策略的实现类)
-
一个接口,两个方法
public interface IFileStrategy {//属于哪种文件解析类型FileTypeResolveEnum gainFileType();//封装的公用算法(具体的解析方法)void resolve(Object objectparam);}
不同策略的差异化实现
A 类型策略具体实现
@Componentpublic class AFileResolve implements IFileStrategy {@Overridepublic FileTypeResolveEnum gainFileType() {return FileTypeResolveEnum.File_A_RESOLVE;}@Overridepublic void resolve(Object objectparam) {logger.info("A 类型解析文件,参数:{}",objectparam);//A类型解析具体逻辑}}
B 类型策略具体实现 ```java @Component public class BFileResolve implements IFileStrategy {
@Override public FileTypeResolveEnum gainFileType() {
return FileTypeResolveEnum.File_B_RESOLVE;
}
@Overridepublic void resolve(Object objectparam) {logger.info("B 类型解析文件,参数:{}",objectparam);//B类型解析具体逻辑}
}
默认类型策略具体实现```java@Componentpublic class DefaultFileResolve implements IFileStrategy {@Overridepublic FileTypeResolveEnum gainFileType() {return FileTypeResolveEnum.File_DEFAULT_RESOLVE;}@Overridepublic void resolve(Object objectparam) {logger.info("默认类型解析文件,参数:{}",objectparam);//默认类型解析具体逻辑}}
如何使用呢?我们借助spring的生命周期,使用ApplicationContextAware接口,把对用的策略,初始化到map里面。然后对外提供resolveFile方法即
@Componentpublic class StrategyUseService implements ApplicationContextAware{private Map<FileTypeResolveEnum, IFileStrategy> iFileStrategyMap = new ConcurrentHashMap<>();public void resolveFile(FileTypeResolveEnum fileTypeResolveEnum, Object objectParam) {IFileStrategy iFileStrategy = iFileStrategyMap.get(fileTypeResolveEnum);if (iFileStrategy != null) {iFileStrategy.resolve(objectParam);}}//把不同策略放到map@Overridepublic void setApplicationContext(ApplicationContext applicationContext) throws BeansException {Map<String, IFileStrategy> tmepMap = applicationContext.getBeansOfType(IFileStrategy.class);tmepMap.values().forEach(strategyService -> iFileStrategyMap.put(strategyService.gainFileType(), strategyService));}}
Observer Pattern(观察者模式)
责任链模式
当你想要让一个以上的对象有机会能够处理某个请求的时候,就使用责任链模式。
责任链模式为请求创建了一个接收者对象的链。执行链上有多个对象节点,每个对象节点都有机会(条件匹配)处理请求事务,如果某个对象节点处理完了,就可以根据实际业务需求传递给下一个节点继续处理或者返回处理完毕。这种模式给予请求的类型,对请求的发送者和接收者进行解耦。
责任链模式实际上是一种处理请求的模式,它让多个处理器(对象节点)都有机会处理该请求,直到其中某个处理成功为止。责任链模式把多个处理器串成链,然后让请求在链上传递: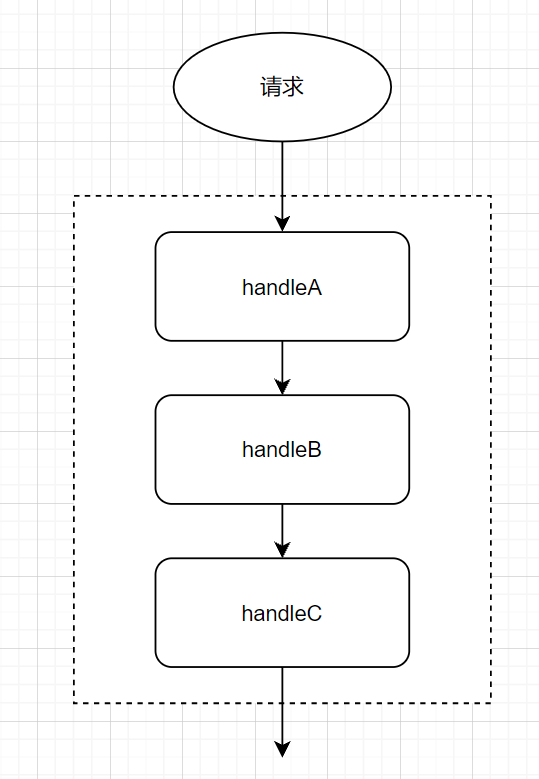
Template Method Pattern(模板方法模式)
状态模式
结构型模式
Proxy pattern(代理模式)
Adapter Pattern(适配器模式)
Decorator Pattern(装饰模式)
装饰器模式
Facade Pattern(门面模式)
Composite Pattern(组合模式)
Flyweight Pattern(享元模式)
引用:

若有收获,就点个赞吧
0 人点赞
