Chapter 3 Neural Reading Comprehension Models
在本章中,我们将介绍神经网络模型的本质:从基本构建模块,到最近的进展。
在深入研究神经模型的细节之前,我们在3.1节简要介绍了用于阅读理解的基于特征的非神经模型。特别地,我们描述了我们在Chen et al.(2016)中构建的一个模型。我们希望这能让读者更好地理解这两种方法的本质区别。
在3.2节中,我们提出了一种用于阅读理解的神经方法,称为THE STANFORD ATTENTIVE READER,这在Chen et al.(2016)中针对完形填空式阅读理解任务被首次提出,之后又将其应用于SQUAD的范围预测问题(Chen et al.,2017)。我们首先简要回顾了现代神经NLP模型的基本构建模块,然后描述了我们的模型是如何建立在这些模块之上的。最后,我们将其扩展到其他类型的阅读理解问题。
接下来,我们将在CNN/DAILY MAIL和SQUAD数据集中展示我们模型的实证结果,并在3.3节中提供更多的实现细节。我们进一步仔细地分析了错误,以帮助我们更好地理解:1)哪些组件对最终性能最重要;2)在经验上,神经模型优于非神经特征模型。
最后,我们在第3.4节中总结了神经阅读理解的最新进展。
3.1 Previous Approaches:Feature-based Models
我们首先描述了在Chen et al.(2016)这篇论文中针对完形填空风格问题构建的一个强大的基于特征的模型,主要是针对CNN/DAILY MAIL数据集(Hermann等人,2015)。然后,我们将讨论为多项选择和范围预测问题建立的类似模型。
对于完形填空式问题,任务表述为预测正确的实体a∈E,该实体a∈E可以根据阅读短文p来填补问题q的空白(表2.1中有一个例子),其中E表示候选实体集。传统的线性、基于特征的分类器通常需要为每个候选实体e∈\epsilon构造一个特征向量fp,q(e)∈Rd,并学习一个权向量w∈Rd,使得正确答案a的排名要高于所有其他候选实体:
w^Tf{p,q}(a) > w^Tf{p,q}(e), ∀e ∈ \epsilon \ {a},
【译者注:变成了一个排序问题。我猜测在深度学习那边,思路是一致的,只是在特征构造的时候不一样,我们之后验证一下】
在为每个实体e构造好所有特征向量后,我们就可以应用任何流行的机器学习算法(如logistic回归或SVM)。在Chen等人(2016)中,我们选择使用LAMBDAMART (Wu等人,2010),因为它是一个自然的排序问题,而近来应用boost的决策树森林非常成功。
剩下的关键问题是我们如何从文章p,问题q和每个实体e中构建有用的特征向量?表3.1列出了我们为CNN/DAILY MAIL任务提出的8组特性。如表所示,这些特征被很好地设计并描述了实体的信息(例如,频率、位置以及它是否是一个问题/短文词),以及它们如何与短文/短文对齐(例如,共现、距离、线性和句法匹配)。一些特性(#6和#8)还依赖于语言工具,比如依赖关系解析和词性标记(决定一个单词是否是动词)。一般来说,对于非神经模型,如何构造一组有用的特征始终是一个挑战。有用的特征必须是有意义的,并且能够很好地适应特定的任务,同时又不能过于稀疏而不能很好地从训练集中概括出来。我们在之前的2.1.2节中已经讨论过,这在大多数基于特征的模型中是一个常见的问题。此外,使用现成的语言工具使模型更加昂贵,它们的最终性能取决于这些(语言工具的)注释的准确性。【译者:同时也添加了潜在的噪声。】

Table 3.1
Rajpurkar等人(2016)和Joshi等人(2017)也尝试分别为SQUAD和TRIVIAQA数据集构建基于特征的模型。除了范围预测任务,这些模型在本质上与我们的相似,他们需要首先确定一组可能的答案。对于SQUAD, Rajpurkar et al.(2016)将Stanford CoreNLP(Manning et al., 2014)生成的parses中的所有成分作为候选答案;而对于TRIVIAQA, Joshi et al.(2017)考虑所有出现在句子中的n-gram(1≤n≤5),其中至少包含一个与问题相同的单词。他们还试图从选民分析中添加更多的词汇化特性和标签。对MCTEST数据集的多项选择问题也进行了其他尝试,如(Wang et al., 2015),并使用了丰富的特性集,包括语义框架、单词嵌入和指代消解。
我们将展示这些基于特征的分类器的经验结果,并在3.3节与神经模型进行比较。
3.2 A Neural Approach: The Stanford Attentive Reader
3.2.1 Preliminaries
下面,我们将概述构成现代神经NLP模型基础的最少要素和关键思想。更多细节,请参考(Cho, 2015; Goldberg, 2017)。
Word embeddings 【在cs224n的课程中,第一时间讲的就是这个方面,可以参考我在这门课的笔记:https://github.com/DukeEnglish/cs224n_learning_note】
第一个关键思想是将单词表示为低维(例如,300)真实值向量。在前深度学习时代,常见的是,把单词用一个词汇表中的索引来代表,这是一个使用一个one-hot向量符号变体:每个单词都被表示为一个高维、稀疏向量,只有代表这个单词的地方是1,其他地方都是0:
V_{car}=[0, 0, … 0, 0, 1, 0, … 0]^T
V_{vehicle}=[0, 1, … 0, 0, 0, 0, … 0]^T
这些稀疏向量最大的问题是它们在单词之间没有任何语义相似性,即,对于任意一对不同的单词a, b, cos(v_a, v_b) = 0。低维单词嵌入有效地解决了这一问题,相似的单词可以在几何空间中编码为相似的向量:cos(v_car, v_vechicle) < cos(v_car, v_man)。【使用cos的值来反映两个向量的相似度】
这些单词嵌入可以有效地从大型无标记文本语料库中学习,这是基于单词出现在相似的上下文中往往具有相似的含义这一假设(也称为分布假设)。的确,从文本中学习单词嵌入有悠久的历史,最近的scalable算法和发布的预先训练的单词嵌入集,如WORD2VEC (Mikolov et al., 2013)、GLOVE (Pennington et al., 2014)和FASTTEXT (Bojanowski et al., 2017),最终使从文本中学习单词嵌入得到了普及。它们已成为现代NLP系统的中流砥柱。
Recurrent neural networks
第二个重要的思想是使用递归神经网络(RNNs)对自然语言处理中的时态或段落进行建模。递归神经网络是一类适合处理变长序列的神经网络。更具体地说,它们递归地对序列x1……xn应用一个参数化函数:
ht=f(h{t-1},x_t; \theta)
对于NLP应用程序,我们将句子或段落表示为单词序列,其中每个单词都转换为向量(通常通过预先训练的单词嵌入):x = x1,x2,…,xn∈R^d和h_t∈R^h可以对x1:t的上下文信息进行建模。
Vanilla的RNNs采用下列的形式:
ht=tanh(W^{hh}h{t-1}+W^{hx}x_t+b)
其中Whh∈Rh×h,Whx∈Rh×d, b∈Rh为待学习参数。为了简化优化,提出了许多RNNs的变体。其中,长短时记忆网络(LSTMs) (Hochreiter and Schmidhuber, 1997)和门控循环单元(GRUs) (Cho et al., 2014)是常用的一种。可以说,LSTM仍然是当今NLP应用中最有竞争力的RNN变体,也是我们将描述的神经模型的默认选择。在数学上,LSTMs可以表示为:
【公式…写论文好辛苦,我就不重新敲lstm的公式了,如果对lstm有问题的话,欢迎查看网络博客:】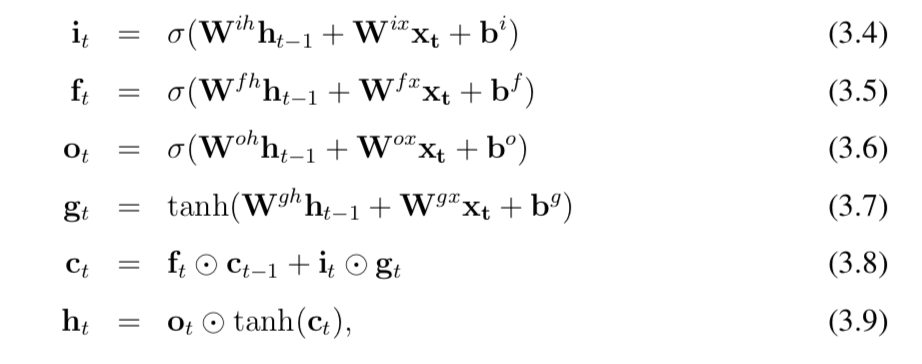
其中所有的W和b都是待学习参数。
最后,RNN中一个有用的东西是bidirectional RNN:想法很简单:对于一个句子或者一个段落来说:x=x1,….xn,一个前向RNN从左到右学习,另一个反过来学习。
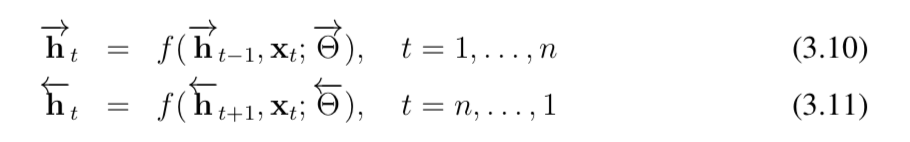
最后,我们定义h_t是将公式中的两个h做拼接得到的结果。这些表示可以有效编码左边和右边的上下文,并且适用于多种NLP任务的通用可训练特征提取组件。
Attention mechanism
第三个重要的组件是attention机制。这个机制首次在sequence-to-sequence模型(Sutskever et al., 2014)中被提出为神经机器翻译提出(Bahdanau et al., 2015; Luong et al., 2015)并且之后被延伸应用到别的NLP任务中。
关键的想法是,如果我们想要预测一句话的情感(sentiment),或者从一种语言的一句话翻译到另外一种语言,我们通常使用recurrent neural networks来对一句话做编码(encode):h1, h2, …hn并且使用最后一个time step的hn来预测最后的情感标签或者是目标语言的第一个word:
P(Y = y) = exp(Wyh_n) / \sum{y’}exp(W_{y’}h_n)
这要求模型可以压缩一句话的所有信息到一个固定长度的向量中,这会导致在提升性能上的信息瓶颈。注意力机制(attention)就是设计来解决这个问题的:与其将所有的信息都压缩在最后一个隐藏向量中,我们监督每一个time step,并且自适应地选择这些向量的子集:
\alphai= exp(g(h_i, w; \Theta_g)) / \sum{i’=1}^n exp(g(h_{i’}, w; \Theta_g))
c= \sum_{i=1}^n \alpha_ih_i
这里的w可以是在训练过程中针对任务学习出来的向量,或者当作机器翻译中现在的目标隐藏状态,g是一个可以以多种不同方式选择的参数,比如说点乘,bilinear product或者是MLP的一个隐藏层:
g_{dot}(h_i, w) = h_i^Tw
g_{bilinear}(h_i, w) = h_i^TWw
g_{MLP}(h_i, w) = v^Ttanh(W^hh_i + W^ww)
简单来说,注意力机制对每一个$h_i$ 计算一个相似度分数,之后使用一个softmax方程来为每一个time step返回一个离散概率分布。因此$\alpha$本质上捕获的句子的哪些部分确实是相关,而c聚合了所有time step的信息,可用于最终的预测。我们不会在这里讨论更多细节,感兴趣的读者可以参考Bahdanau等人(2015);Luong等(2015)。
注意力机制已经被证明在大量的应用是有广泛的影响力,并且成为神经NLP模型的一个组成部分。最近,Parikn等人(2016)和Vaswani等人(2017)推测注意力机制并不一定非要和RNN一起使用,并且可以单纯得基于word embeddings和前向神经网络建立,同时提供最小的序列信息。这类方法通常需要更少的参数,并且更加容易并行和规模变化。特别的,Vaswani等人在2017年的论文中提出的transformer已经变成了最近的趋势,我们会在Section3.4.3中讨论它。
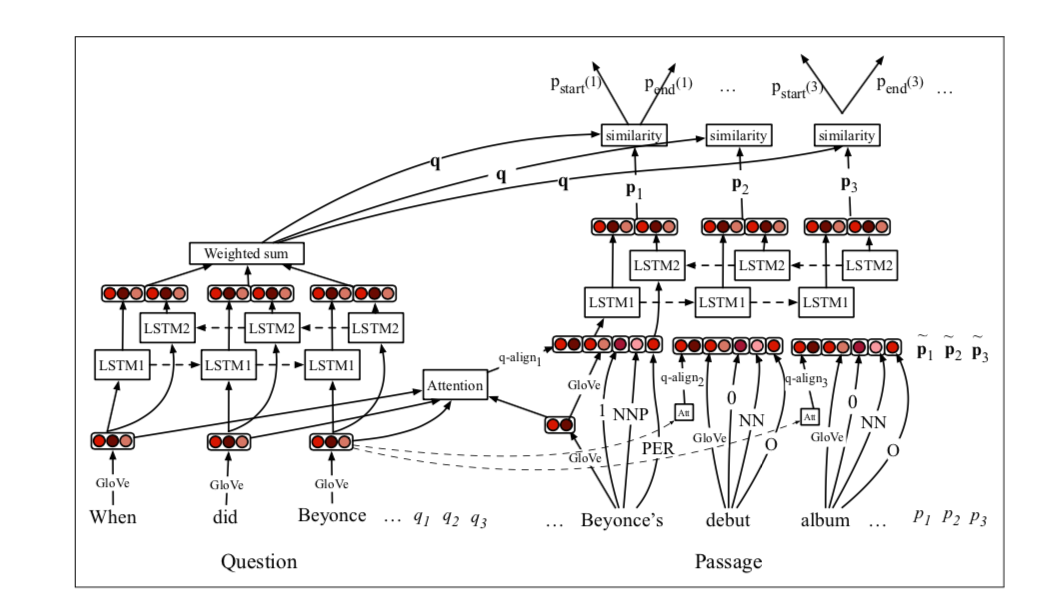
3.2.2 The Model
目前,我们已经具备了所有的构建模块。我们如何利用他们为阅读理解建立有效的神经模型呢?关键成分是什么?接下来我们会介绍我们的模型:STANFORD ATTENTIVE READER。我们的模型受到Hermann et al.(2015)中描述的ATTENTIVE READER以及其他同一时期工作的启发,并且满怀着让模型简单高效的目标。我们首先描述了模型解决范围预测问题的全形式(我们在Chen et al(2017)中预测了),之后我们讨论了其他的变种。
让我们首先回顾一下基于范围的预测阅读理解问题的设定:给定一个passage p,由lp个tokens(p1,p2,…pl_p)组成,以及一个问题q,有l_q个token(q1, q2, …ql_q)组成,目标是预测一个范围(a_start, a_end),其中1<=a_start<=a_end<=l_p,所以对应的字符串:p{astart}, p{astart+1}, … , p{a_end}就是问题的答案。
整个模型如图3.1所示。纵观整个模型,模型首先为问题构建一个向量表示,并为文章中的每个token构建一个向量来表示。然后计算上下文中问题及其短文词之间的相似度函数,然后使用问题-短文相似度评分来决定答案跨度的起始和结束位置。该模型建立在文章和问题中每个单词的低维、预先训练的单词嵌入的基础上(可以选择使用语言学标注)。对文章/问题编码的所有参数和相似度函数进行联合优化,实现最终的答案预测。让我们进一步了解每个组件的细节:
Question encoding
问题编码相对简单:我们首先将问题中的每个单词qi映射到它相应的embedding上,之后我们在他们上面应用一个Bi-LSTM模型,最后获得
q1 ,q_2 ,…,q{lq} = BiLSTM(E(q_1 ),E(q_2 ),…,E(q{l_q} );Θ^{(q)}) ∈ R^h(3.18)
之后我们通过attention层聚合这些隐藏单元到一个向量中。
bj= exp(w^{qT}q_j) / \sum{j} exp(w^{qT}q_{j’}) (3.19)
q= \sum_{j}^n b_jq_i (3.20)
bj衡量question中的每一个单词的重要性,而$w^q∈ R^h$ 是一个要学习的权重向量。因此,$q∈ R^h$ 是最终的问题的向量表示。事实上,将双向LSTMs最后的隐层向量拼接来代表q既简单又常见。然而,基于经验,我们发现添加attention层是有帮助的,因为它对更相关的问题中的单词添加了更多的权重。
Passage encoding
篇章编码类似,因此我们也是先为文章中的每个单词形成一个输入表示,然后将他们通过另一个Bi-LSTM:
p1 ,p_2 ,…,p{lp} = BiLSTMp_1 ̃ ,p_2 ̃ ,…,p{l_p} ̃ ;Θ(p) ∈ Rh
输入表示p可以被分成两个类别:一个是编码每个单词本身的属性,另一个编码它和问题的相关属性。
对第一类,除了word embedding外,我们也添加了一些手动特征来反映一个单词在上下文中的属性,包括POS、NER和它normalized之后的TF:f = (POS,NER,TF)。对于POS和NER的标签,我们运行现成的工具,并将其转换为一个one-hot表示,因为标签集很小。TF特征是一个真实的数字,衡量了单词在文章中出现的次数除以总单词数量。
对于第二个类型,我们考虑了两种表示:
Exact match: $f_{exact_match}(p_i) = I(p_i ∈ q) ∈ R$事实上,我们使用了三个简单的二进制特征,表明p是否与一个问题中的单词q精确匹配,不管是原始形式,小写或者是词根。
Aligned question embeddings:exact match特征在问题单词和篇章单词中编码了硬指向指向问题嵌入目标是编码一个在词嵌入空间中指向的软标记,所以相似的单词,例如:car和vehicle,也可以被指向。具体地,我们用:
f{align}(p_i) = \sum_j a{ij}E(q_j)【3.22】
ai,j是注意力权重,它捕捉了pi和每一个问题单词qj的相似性以及$E(q_j)∈ R^d$ 是问题中的每一个单词的word embedding。aij通过word embeddings的非线性映射之间的点乘(dot)计算得到:
a{i,j} = exp(MLP(E(p_i))^T MLP(E(q_j))) / \sum{j^i}exp(MLP(E(pi))^T MLP(E(q{j’})))
$MLP(x)=max(0, W{MLP}x + b{MLP})$ 是一个单一稠密层,带有ReLU的非线性变化,其中WMLP ∈ Rd×d and bMLP ∈ Rd.
最后,我们简单的拼接四个组件,并形成输入表示。
p ̃i = (femb(pi), ftoken(pi), fexact match(pi), falign(pi)) ∈ Rd ̃
Answer prediction
我们有了篇章p1,2,,,p的表示,以及问题q和目标来预测更像是正确答案的范围。我们应用了attention机制的想法,并且分别训练了两个分类起,一个用来预测范围的开始位置,另一个用来预测结束为止。更准确地说,我们用了一个双线性乘积来捕捉两者之间的相似性(p和q)

Training and inference
最后的训练目标方程是最小化交叉墒损失:
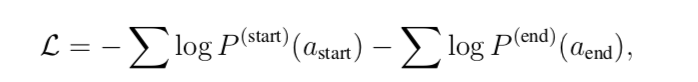

3.2.3 Extensions
在接下来的内容中,我们将为其他类型的阅读理解问题提供一些STANFORD READER的变体。所有这些模型都遵循上述的篇章编码和问题编码过程,因此我们有p1、p2、……, plp∈Rh, q∈Rh。我们只讨论了答案预测部分和训练目标。
Cloze style。类似的,我们可以用问题对文章中所有单词的双线性乘积来计算注意力函数,然后计算一个输出向量o,它对所有段落表示形式进行加权和:

Multiple choice。在这个设定中,k个假设的答案被给定,我们可以通过应用第三个BiLSTM(类似于我们的问题编码步骤)将它们编码到一个向量ai中。然后我们可以计算输出向量o(如式3.29所示),并通过另一个相似度函数,使用双线性乘积将其与每个假设的答案向量ai进行比较:
P(Y = i | p, q) = exp(aiW^(a)o) / \sum{i’}exp(a_{i’}W^(a)o) (3.31)
交叉墒损失也会被用来做训练。这个模型已经在RACE数据集上做了研究(Lai et al.(2017))
Free-form answer。对于这类问题,答案不局限于文章中的一个实体或一个范围,可以取任何单词序列,最常见的解决方案是将LSTM序列解码器合并到当前框架中。更详细地,假设答案字符串是a = (a1, a2,…ala)和一个特殊的“end-of-sequence” token⟨eos⟩添加到每个答案。我们可以再次计算输出向量o,如式3.29所示。解码器每次生成一个单词,因此条件概率可以分解为:

这类模型已经在MS MARCO (Nguyen et al., 2016)和NARRATIVEQA (Kocˇisky et al ., 2018)数据集上面研究过了。然而,由于自由形式的答题阅读理解问题更加复杂,也更难评估,我们认为这些方法与其他类型的问题相比还没有得到充分的探索。最后,我们认为提出了一种用于总结任务(summarization tasks)的copy mechanism(复制机制)(Gu et al.,2016;See et al. 2017)它允许解码器选择从源文本中复制一个单词,或者从词汇表中生成一个单词,这对于阅读理解任务也非常有用,因为答案单词仍然可能出现在段落或问题中。我们将在第6.3节中讨论一个具有复制机制的模型。
3.3 Experiments
3.3.1 Datasets
我们在CNN/DAILY MAIL (Hermann et al., 2015)和SQUAD (Raj- purkar et al., 2016)上评估了我们的模型。我们在之前的2.1.3节中已经描述过数据集的构建方式以及它们在神经阅读理解发展中的重要性。现在我们简要回顾一下这些数据集和统计数据。
CNN /DAILYMAIL 是使用CNN和Daily Mail里面的文章及其要点摘要进行构建的。一个要点被转换成一个问题,一个实体被一个占位符替换,答案就是这个实体。文本已经通过谷歌NLP pipeline运行。Tokenized,小写化以及命名实体识别和指代消歧已经被运行过了。对于每个包含至少一个命名实体的coreference链,链中的所有项都用@entityn标记替换,以表示不同的索引n(Table 2.1 (a))。平均而言,CNN和DAILY MAIL在文章中都包含了26.2个不同的实体。训练、开发和测试示例是从不同时期的新闻文章中收集的。评估使用准确度(预测正确实体的实例的百分比)这个指标。
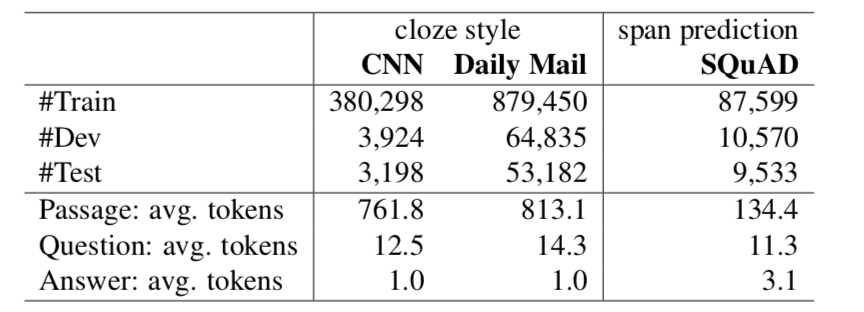
SQUAD数据集是根据维基百科上的文章收集的。抽取了536篇高质量的维基百科文章作为样本,众包工人根据每一段创建问题(删除长度小于500个字符的段落),并且要求答案必须在每一段中突出显示(表2.1 (c))。训练/开发/测试数据的由文章随机划分获得(80% vs. 10% vs. 10%)。为了评估人类的表现并使评估更可靠,他们为每个问题收集了一些额外的答案(开发集中的每个问题平均有3.3个答案)。如2.2.2节所述,我们使用精确匹配和宏观平均F1分数进行评估。请注意,SQUAD 2.0 (Rajpurkar et al., 2018)是最近提出的,它在原始数据集中添加了53,775个无法回答的问题,我们将在第4.2节中讨论它。在本论文的大部分内容中,除非另有说明,否则“SQUAD”指的是“SQUAD1.1”。
表3.2给出了更详细的数据集统计。如图所示,由于数据集的构造方式,CNN/DAILY MAIL的数据集比SQUAD大得多(几乎大一个数量级)。CNN/DAILY MAIL中使用的段落也要长得多,CNN和DAILY MAIL分别是761.8和813.1token,而SQUAD是134.4token。最后,SQUAD的答案平均只有3.1个令牌,这反映了小队的问题大部分都是陈述型,大部分的答案都是常见的名词或命名实体。
3.3.2 Implementation Details
除了不同体系结构的模型设计,实现细节对这些神经阅读理解系统的最终性能也起着至关重要的作用。在接下来的文章中,我们将重点介绍一些我们还没有涉及到的重要方面,最后给出我们在这两个数据集中使用的模型规范。
Stacked BiLSTMs。一个简单的方法是增加用于问题和篇章编码的双向LSTMs的深度。它计算ht = [ht;ht]∈R2h,然后将ht作为下一层的输入xt,传递给另一层BiLSTM,以此类推。结果表明,堆叠的BiLSTM比单层的BiLSTM效果好。在SQUAD实验中,我们使用了3层。
Dropout。在神经网络正则化中,Dropout是一种有效且应用广泛的方法。简单地说,dropout是指在训练过程中随机屏蔽掉一些单元。对于我们的模型,可以将dropout添加到每个LSTM层的嵌入、输入向量和隐藏向量中。最后,dropout的变种方法 (Gal和Ghahramani, 2016)已经被证明在RNNs规范化方面比标准dropout更好。这个想法是应用相同的dropout掩盖在每一个时间步骤的输入,输出和重复层,例如,在每一个time step中会drop相同的单位。我们建议读者在实践中使用这种变体。
Handling word embedding。常用处理字嵌入的方法之一(也是我们的默认选择)是在训练集中保持最常见的K(如K = 500、000年)种word并将所有其他word映射到一个⟨unk⟩令牌,然后使用pre-trained字嵌入的初始化K个word。通常,当训练集足够大时,我们对所有单词embeddings进行微调;当训练集相对较小时(例如,SQUAD),我们通常将所有嵌入的单词都固定为静态特性。在Chen等人(2017)的研究中,我们发现对最常见的疑问词进行微调是有帮助的,因为这些关键词的表征,如what, how, which可能对阅读理解至关重要系统。(Dhingra et al., 2017a)等研究表明,对预训练的词嵌入和对集合外单词的应对方式会对阅读理解任务的性能有很大的影响。
Model specifications。对于所有需要语言学标注的实验(lemma,part-of-speech tags,named entity tags, dependency parses),我们使用Stanford CoreNLP toolkit (Manning et al., 2014)进行预处理。为了训练所有的神经模型,我们按照它的篇章长度对所有的示例进行排序,并为每次(weights的)update随机抽取大小为32的小批样本。
对于CNN/DAILY MAIL的结果,我们使用在Wikipedia和Gi- gaword上训练过的小写的、100维的预训练好的GLOVE 词嵌入 (Pennington et al., 2014)进行初始化。Attention和输出(层)的参数使用均匀分布初始化,LSTM权值由高斯分布N(0,0.1)初始化。我们使用一个隐藏大小为h = 128的1层BiLSTM用于CNN, h = 256用于DAILY MAIL。采用vanilla stochastic gradient descent (SGD)进行优化,固定学习率为0.1。当梯度范数超过10时,我们还将概率为0.2的dropout应用于嵌入层和梯度裁剪。
对于SQUAD的结果,我们使用隐藏单元h = 128的的3层BiLSTMs对段落和问题进行编码。我们使用ADAMAX进行优化,如(Kingma和Ba, 2014)所述。约0.3的Dropout应用于word嵌入和LSTMs的所有隐藏单元。我们使用从840B Web抓取数据中训练的300维GLOVE词嵌入进行初始化,只微调了1000个最常见的问题词。
其他的实现细节可以在以下的两个github的仓库中找到:
- https://github.com/danqi/rc-cnn-dailymail for our experiments in Chen et al. (2016).
- https://github.com/facebookresearch/DrQAforourexperimentsinChenetal.(2017).
我们也想提醒读者,我们的实验结果发表在了2016年和2017年的两篇论文中,并且在很多地方有所不同。一个关键的区别是,我们在CNN /英国《每日邮报》的结果不包括手动特征 f token(π),精确匹配特性fexact匹配(pi),对齐问题嵌入falign (pi)和p̃,仅仅需要词嵌入E (pi)。另一个不同之处在于,我们之前没有涉及编码问题的attention层,而只是在两个方向上连接LSTMs的最后一个隐藏向量。我们相信这些补充在CNN/DAILY MAIL和其他完形填空任务中也很有用,但我们没有进一步研究。
3.3.3 Experimental Results
3.3.3.1 Results on CNN/DAILY MAIL
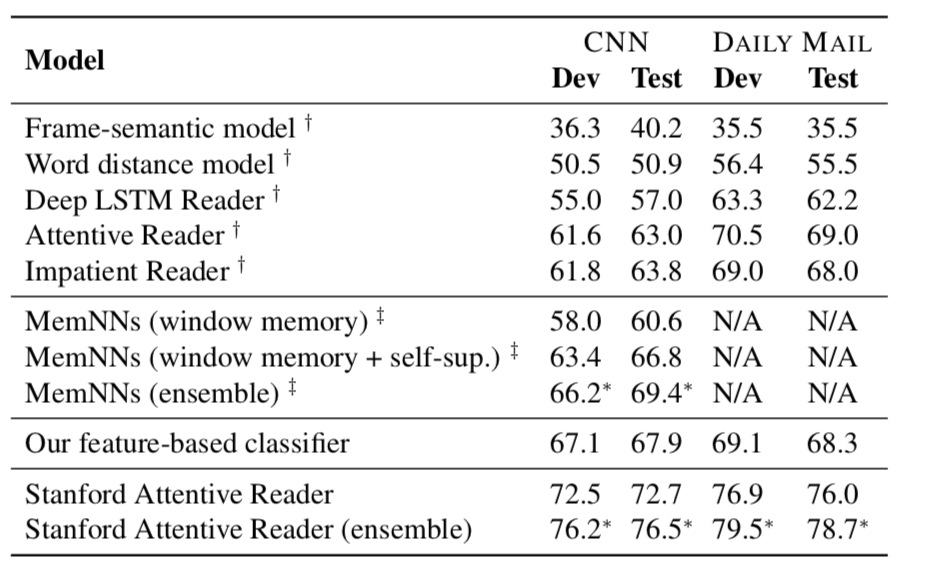
表3.3给出了我们在Chen et al.(2016)中报告的结果。我们用不同的随机种子分别运行我们的神经模型5次,并报告了每次运行的平均性能。我们还报告了综合结果,平均了5个模型的预测概率。我们还展示了我们在3.1节中描述的基于特征的分类器的结果。
Baselines。我们是最早研究这第一个大规模阅读理解数据集的小组之一。当时,Hermann et al.(2015)和Hill et al.(2016)为这项任务提出了一些基线,包括符号方法和神经模型。基线包括:
- Hermann et al.(2015)中的框架语义模型,他们运行一个最先进的语义解析器,从问题和文章中提取表示为(e1, V, e2)的实体谓词三元组,并尝试使用一些启发式规则匹配正确的实体。
- 赫尔曼等人(2015)的单词距离模型,其中他们将问题的位置持有者与每个可能的实体对齐,并计算问题与对齐实体周围的通道之间的距离度量。
- 几个基于lstm的神经模型(Hermann等人)(2015),分别命名为deep LSTM READER、attention READER和READER。深层LSTM阅读器使用深层LSTM(无注意机制)将问题和文章作为一个序列进行处理,并在最后进行预测。ATTENTIVE READER与我们的模型在本质上是相似的,因为它计算了问题向量与所有文章向量之间的注意函数是-;而IMPATIENT READER则为所有的问题词计算一个注意力函数,并在模型读取每个问题词时递归地积累信息。
- Hill等人(2016)提出的(WINDOW-BASED MEMORY NETWORKS)基于windows的内存网络是基于内存网络架构的(Weston等人,2015)。我们认为这个模型也与我们类似,最大的不同是他们的编码通道方式:他们只使用5-word上下文窗口在评估候选实体和它们使用位置编码上下文embedding。如果一个窗口包含5个单词x1,x2,…,然后将其编码为Ei(xi),得到5个独立的嵌入矩阵进行学习。它们以类似的方式编码围绕占位符的5个单词的窗口,并且忽略问题文本中的所有其他单词。此外,他们只是使用点积来计算问题和上下文嵌入之间的“相关性”。
如表3.3所示,我们的基于特征的分类器在CNN测试集上的准确率为67.9%,在DAILY MAIL测试集上的准确率为68.3%,显著优于Hermann et al.(2015)所报道的任何符号方法。我们认为它们的框架语义模型不适合这些任务,因为解析器的覆盖率很低,并且不能代表一个简单的NLP系统可以实现什么。事实上,框架语义模型甚至明显低于单词距离模型。令我们惊讶的是,我们的基于特征的分类器甚至比Hermann et al.(2015)和Hill et al.(2016)中所有的神经网络系统都表现得更好。此外,我们的单模型神经网络大大超过了之前的结果(超过5%),将最先进的精度分别提高到72.7%和76.0%。5个模型的组合始终带来进一步的2-4%的收益。
3.3.3.2 Results on SQUAD
表3.4给出了我们对开发和测试集的评估结果。自创建以来,SQUAD一直是一个非常有竞争力的基准,我们只列出了一些代表性的模式和单模式的表现。众所周知,集成模型可以进一步提高性能的几个点。我们还包括了逻辑回归基线的结果。(Rajpurkar et al., 2016)。
我们的系统可以在测试集上达到70.0%的精确匹配和79.0%的F1成绩,超过了所有已发表的结果,并且与我们的论文中SQUAD排行榜上最好的性能相匹配 (Chen et al., 2017)。此外,我们认为我们的模型在概念上比大多数现有系统更简单。与logistic回归基线F1 = 51.0相比,该模型已经接近30%的绝对改进,对于神经模型来说是一个巨大的胜利。
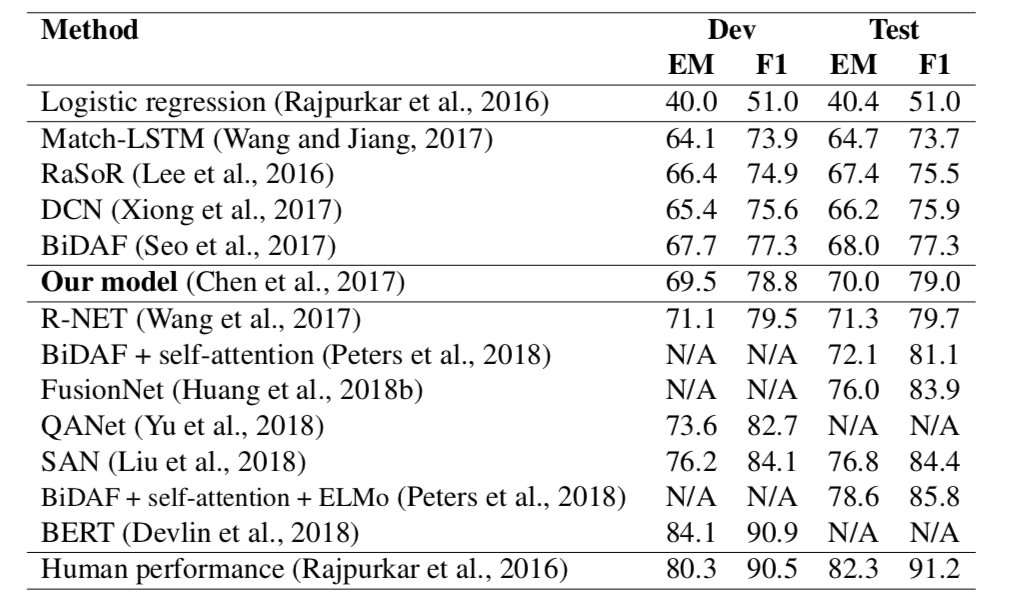
此后,SQUAD受到了极大的关注,在这个数据集上取得了很大的进步,如表3.4所示。最近的进展包括用于初始化的预训练语言模型、更细粒度的注意机制、数据增强技术技巧,甚至更好的训练目标。我们将在第3.4节中讨论它们。
3.3.3.3 Ablation studies
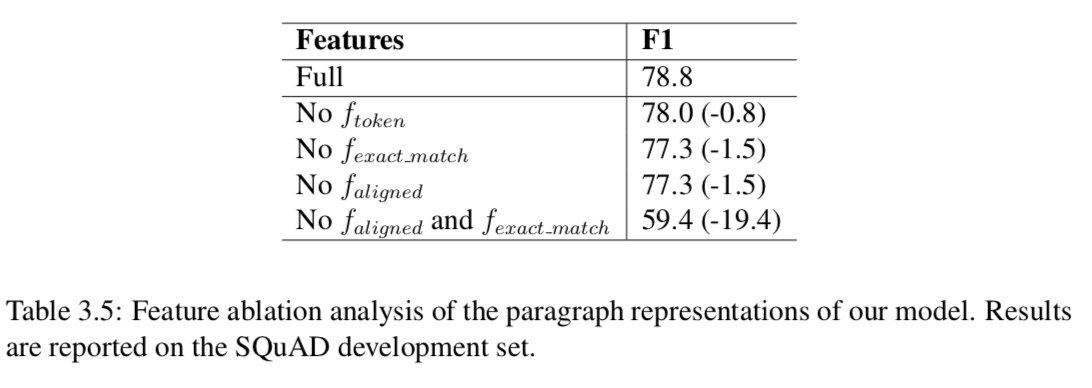
Chen等(2017)对通道表征成分进行消融分析。如表3.5所示,所有组件都对最终系统的性能有贡献。我们发现,没有对齐的问题嵌入(只有word嵌入和一些手动特性),我们的系统仍然能够实现F1超过77%。精确匹配特征的有效性还表明,该数据集上的文章和问题之间存在大量的单词重叠。更有趣的是,如果我们同时去掉伪匹配和非精确匹配,性能会显著下降,因此我们得出结论,这两个特征在特征表示方面发挥着相似但互补的作用,比如问句和短文词之间的硬对齐和软对齐。
3.3.4 Analysis: What Have the Models Learned?
在Chen et al.(2016)中,我们试图更好地理解这些模型实际学到了什么,以及解决这些问题需要多大的语言理解深度。我们通过对CNN数据集开发集中的100个随机抽样示例进行仔细的手工分析来实现这一点。
我们大致将其分为以下几类(如果一个例子满足一个以上的类别,我们将其分为前面的类别):
Exact match 占位符周围最近的单词也可以在围绕实体标记的段落中找到;答案不言自明。
Sentence-level paraphrasing 问题在篇章中作为一句话的结尾或者是一句话的转述,所以答案一定可以从那句话中找出来
Partial clue 在许多情况下,即使我们不能在问题文本和一些句子之间找到一个完全的语义匹配,我们仍然能够通过部分线索来推断答案,比如一些单词/概念重叠。
Multiple sentences 多句话必须被处理才能推测正确答案
Coreference errors 数据集中不可避免地存在许多指代错误。这一类别包括对出现在问题中的答案实体或关键实体具有关键共参考错误的示例。基本上,我们把这个类别视为“不可回答的”。
Ambiguous or hard 这个类别包括那些我们认为人类肯定不能获取正确答案的例子
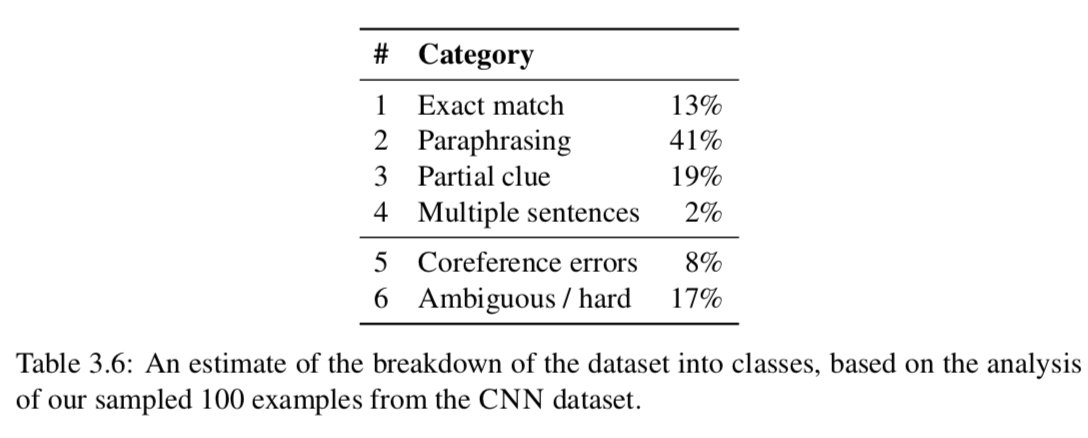
表3.6给出了每个类别的百分比估计值,图3.2给出了每个类别的一个代表性示例。我们观察到改写(paraphrasing)占41%的例子和19%的例子属于partial clue(部分线索)类别。加上最简单的Exact match精确匹配类别,我们假设大部分示例(这个子集中73%)能够通过识别最相关的(单个)句子并根据它推断出答案。此外,只有两个例子需要多个句子进行推理。这比我们预期的要低,这表明数据集需要的推理比之前认为的要少。令我们惊讶的是,根据我们的手工分析,“共参错误”和“模糊/困难”的情况占这个样本集的25%,这对于准确率远远高于75%的训练模型来说肯定是一个障碍(当然,模型有时可能会做出幸运的猜测)。事实上,我们的集成神经网络模型在开发集上已经能够达到76.5%,我们认为在这个数据集上进一步改进的前景是很小的。
在上述分类的基础上,我们进一步研究神经网络和基于特征的分类器的分类性能。如图3.3所示,我们得到以下观察结果:(i)精确匹配的情况非常简单,两个系统的tems都得到100%的正确。(ii)对于模糊/硬连接和实体连接错误的情况,符合我们的预期,这两个系统的性能都很差。(三)两种系统主要不同之处在于释义的情况,以及部分“部分线索”的情况。这清楚地显示了神经网络能够更好地学习语义匹配,包括释义或两个句子之间的词汇变化。(4)我们认为神经网络模型在所有的单句和明确的情况下都已经达到了近乎最优的性能。

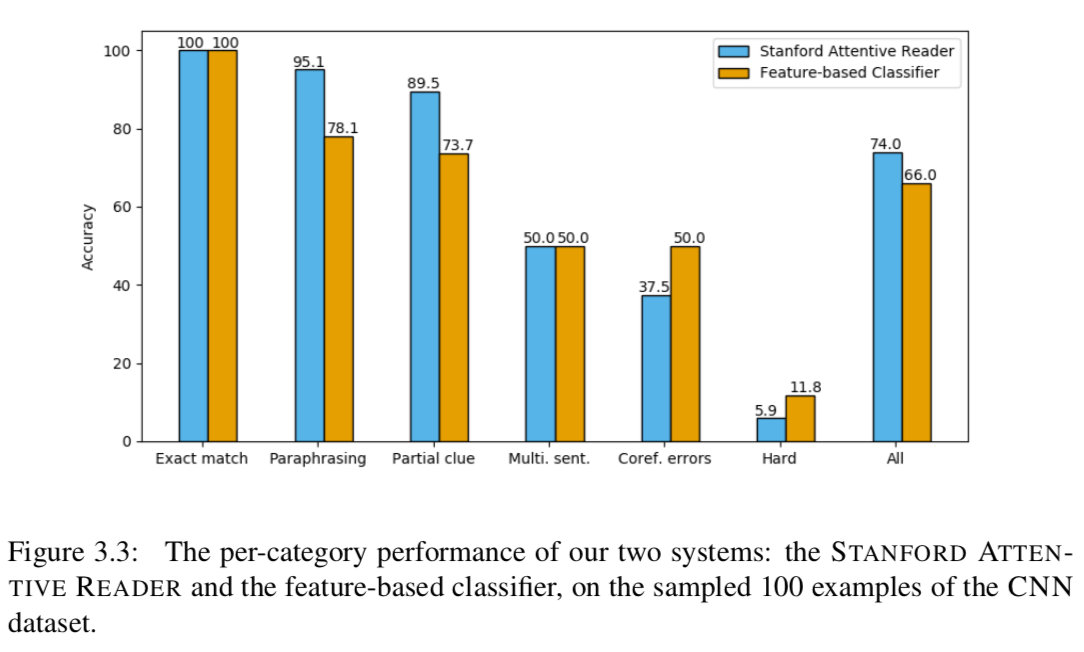
综上所述,我们发现与传统的基于特征的模型相比,神经网络在识别词汇匹配和释义方面无疑更强大;虽然目前还不清楚他们是否也搞定了需要更复杂的文本推理的例子,因为目前在这方面的数据集仍然非常有限。
3.4 Further Advances
在本节中,我们总结了神经阅读理解的最新进展。我们将它们分为以下四类:单词表示、注意机制、LSTMs的变体以及其他(如训练目标、数据扩充)。最后对其重要性进行了总结和讨论。
3.4.1 Word Representations
第一类是对疑问词和短文词的更好的单词表示,因此神经模型是建立在更好的基础上的。(译者注:原文有笔误,大意是神经模型是建立在word representations的基础上的)。从文本中学习更好的分布式单词表示或者为特定任务发现更好的词嵌入集合依然是一个活跃的研究话题。例如,Mikolov等人(2017)发现在我们的模型中将GLOVE与训练向量使用最新的FASTTEXT 向量(Bojanowski等人 2017)可以早SQUAD上面取得1个百分点的提升。不仅如此,有两个关键的想法已经被证明(非常)有用:
Character embeddings
第一个想法是使用字符级嵌入来表示单词,这对于罕见的或词汇表外的单词尤其有用。现有的研究大多采用了一种能够有效利用n-gram字符表面模式的卷积神经网络(CNN)。更具体地说,设C为字符的词汇表,每个单词类型x都可以表示为字符序列(c1,…c | x |)∀ci∈c。我们首先将C中的每个字符映射到一个dc维度的向量,所以单词x可以表示成c1,…, c |x |。
接下来,我们对宽度为w∈Rdc×w的滤波器应用卷积层,表示ci:i+j为ci,ci+1,…,ci+j的级联。因此,对于i = 1,…,|x| - w + 1,我们可以应用这个滤波器w,然后我们添加一个偏置b,应用非线性tanh如下:
fi = tanh(w^Tc{i:i+w-1} + b)
最后,我们可以在f1上应用一个最大池操作,f1…, f|x| - w+1,得到一个标量特征:
f = max_i{f_i}
这个特性本质上选择一个字符n-gram,其中n-gram 对应过滤器的宽度w。我们可以重复上面的过程,方法是重复d个不同的过滤器w1,…wd∗。因此,我们可以获得每个单词类型Ec(x)∈Rd的基于字符的单词表示。所有的字符嵌入,过滤器权重{w}和偏差{b}都是在训练中学习的。更多细节可以在Kim(2014)中找到。实际上,字符嵌入dc的维数通常取一个小值(例如20),宽度w通常取3 - 5,而100是d的一个典型值。
Contextualized word embeddings
另一个重要的概念是上下文的单词嵌入。与传统的单词嵌入(每个单词类型都映射到一个向量)不同,上下文化的单词嵌入将每个单词作为整个输入语句的函数分配给一个向量。这些词的嵌入可以更好地模拟单词使用的复杂特性(例如,语法和语义),以及这些用法如何在不同的语言环境中变化(例如,一词多义)。
ELMO在Peters et al.(2018)中详细介绍了一个具体的实现:它们的上下文单词嵌入是一个深层双向语言模型的内部状态的学习函数,该模型是在一个大型文本语料库上预先训练的。基本上,给定一个单词序列(x1, x2,…,它们运行l层正向LSTM,序列概率模型为:

这些上下文的单词嵌入通常与传统的单词类型嵌入和字符嵌入一起使用。事实证明,这种在非常大的文本语料库上(例如1B词库标记(Chelba et al., 2014))预训练的上下文词嵌入是非常有效的。Peters et al.(2018)证明,在现有的竞争模型中添加ELMo embeddings (L = 2个biLSTM图层,包含4096个单元和512个维度投影)可以直接将F1成绩从81.1提高到85.8,绝对提高4.7分。
在ELMO之前,McCann等人(2017)提出了COVE,该方法在神经机器翻译框架中学习上下文化的单词嵌入,得到的编码器可以作为单词嵌入的补充。他们也展示了4.3分的绝对进步。
最近,Radford et al。(2018)和Devlin et al。(2018)发现这些上下文词潜入不仅可以用在一个特定任务的神经结构中作为一个词表示的特征 (阅读理解模式的上下文),而且我们可以调整深层语言模型直接并进行最小修改来执行下游任务。这在我写这篇论文的时候确实是一个非常惊人的结果,我们将在第4.4.2节对此进行更多的讨论,在未来还有很多问题需要回答。此外,Devlin et al.(2018)提出了一种训练双向语言模型的聪明方法:他们在输入层随机屏蔽一些单词,而不是总是往一个方向叠加LSTMs并预测下一个单词,将双向层叠加,并在顶层预测这些被屏蔽的单词。他们发现这种训练策略在经验上非常有用。
3.4.2 Attention Mechanisms
针对神经阅读理解模型,已经提出了许多注意力机制的变种,它们的目的是在不同层次、不同粒度或分层的方式上捕捉问题和文章之间的语义相似性。在(Huang et al., 2018b)处可以找到这个方向的典型复合例子。据我们所知,目前还没有一个结论说存在一个变种是十分突出的。我们的STANFORD ATTENTIVE READER 采用了最简单的注意力形式(图3.4是不同层的attention的概览图)。除此以外,我们认为有两个想法可以在通常意义上进一步提升这些系统的性能。
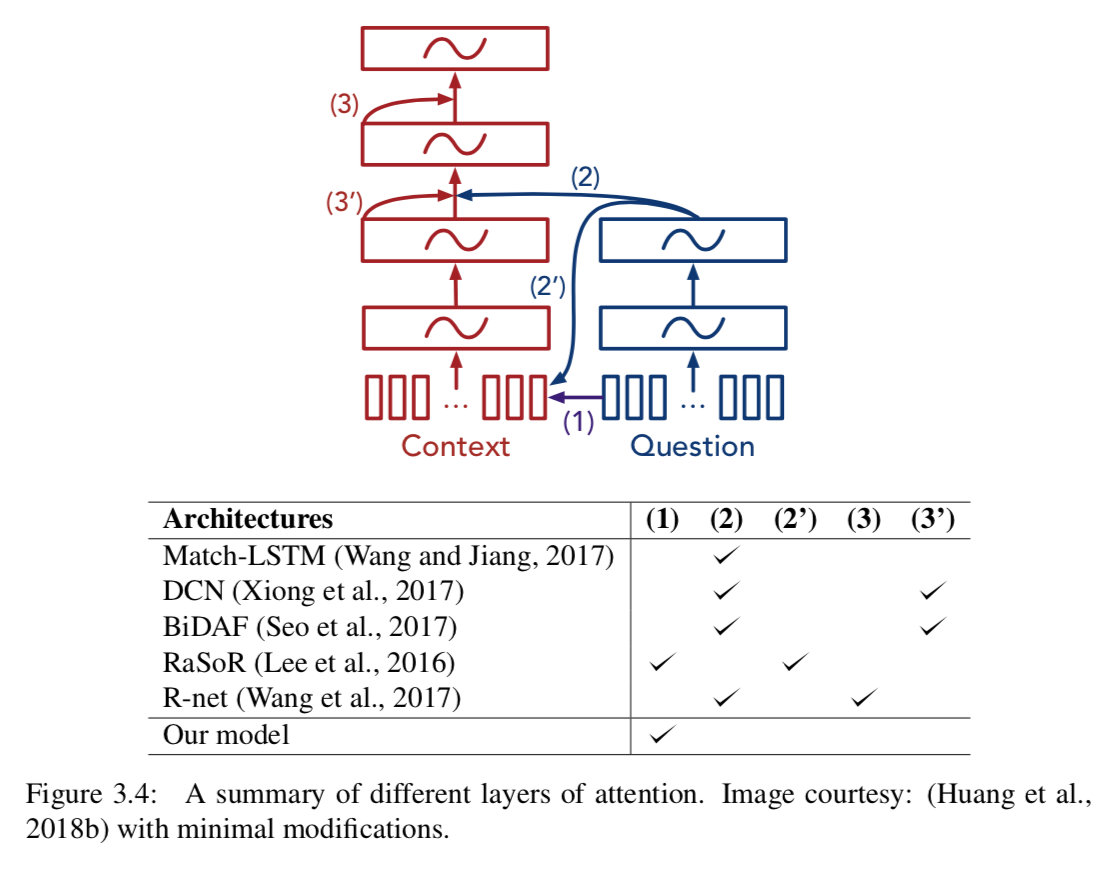
Bidirectional attention
Seo等(2017)首次提出了双向注意力机制的概念。除了我们已经拥有的(特性),关键的区别是他们有问题到段落的注意力,这表示了着哪些段落单词与每个问题单词最相似。在实践中,这可以实现为:对于问题中的每个单词,我们可以计算出所有短文单词的注意图,类似于我们在方程3.22和3.23中所做的,但方向相反:
f{q-align(q_i)} = \sum_jb{i,j}E(p_I) 公式3.39
之后,我们可以简单的将fq-align输入到问题编码器的输入层。
Seo等人(2017)的注意机制比较复杂,但我们认为是相似的。我们还认为,在这个方向上的注意力功能没有那么有用,Seo等人(2017)也证明了这一点。这是因为问题通常很短(平均10- 20个单词),使用一个LSTM进行问题编码(无需额外的注意力)通常就足够了。
Self-attention over passage
第二种观点是对段落词的自我关注,最早出现在Wang等人(2017)的文章中。直观的感觉是,文章中的单词可以与其他文章中的单词对齐,希望它可以解决相互参照的问题,并从文章中的多个地方收集(同一实体的)信息。
Wang等(2017)首先计算了这篇文章的隐藏向量:p1, p2,它们通过MLP的一个隐含层(式3.17)对p1 p2施加一个注意函数:
a{i,j} = exp(g{MLP}(pi, p_j)) / \sum{j’}exp(g{MLP}(p_i, p{j’}))
ci = \sum_j(a{i,j}p_j)
之后ci和pi被连接起来,并且输入到另一个bilstm中:$hi^{(p)} = BiLSTM(h^{(p)}{i-1}, [p_i, c_i])$, 并且可以被用作最终的篇章表示。
3.4.3 Alternative to LSTMs
目前我们讨论的所有模型都是基于递归神经网络(RNNs)的。众所周知,增加神经网络的深度可以提高模型的容量,并带来性能的提高(He et al., 2016)。我们之前还讨论了3或4层的深层BiLSTM,这通常比单层BiLSTM性能更好(第3.3.2节)。然而,随着LSTM模型深度的进一步提高,我们面临着两个挑战:1)由于梯度消失问题,优化变得更加困难;2)可扩展性成为一个问题,因为随着层数的增加,训练/推理时间呈线性增长。众所周知,由于LSTMs的顺序性,它很难并行化,因此伸缩性(scale)很差。
一方面,有一些工作尝试在层与层之间添加高速连接(Srivastava et al., 2015)或残差连接(He et al., 2016),从而简化优化过程,能够训练更多层的LSTMs。另一方面,人们开始寻找LSTMs的替代品,在消除重复结构的同时,性能仍然类似甚至更好。
这方面最值得注意的工作是谷歌研究人员提出的TRANSFORMER模型(Vaswani et al., 2017)。TRANSFORMER只构建在word嵌入和简单的位置编码之上,这些位置编码具有堆叠的自我关注层和位置明智的完全连接层。通过残差连接,该模型能够在多个层次上快速训练。它首先在L = 6层的机器翻译任务(每层由一个自我注意和一个完全连接的前馈网络组成)上表现出优越的性能,然后被Yu等人(2018)改编用于阅读理解。
该模型名为QANET (Yu et al., 2018),它堆叠了多个卷积层,以自我关注和完全连接层为中心,作为问题和段落编码的构建块,以及在最终预测之前堆叠的几个层。该模型显示了当时最先进的性能(表3.4),同时显示了显著的加速。
Lei等人(2018)的另一项研究工作提出了一种轻量级的递归单元,称为简单递归单元(SIMPLE unit, SRU),它简化了LSTM公式,同时支持cuda级优化以实现高并行化。研究结果表明,简化递归模型通过层堆积保持了较强的建模能力。他们还证明了用SRU单元替换我们模型中的LSTMs可以提高F1成绩2分,同时训练和推理速度更快。
3.4.4 Others
训练目标:通过改进训练目标也有可能取得进一步进展。对于完形填空或多项选择题,通常直接使用交叉熵或最大边际损失。然而,对于跨度预测问题,Xiong等(2018)认为预测答案两个端点的交叉熵损失与最终的评价指标存在差异,这涉及到gold answer与ground truth之间的单词重叠。例如:
- passage: Some believe that the Golden State Warriors team of 2017 is one of the greatest teams in NBA history . . .
- question: Which team is considered to be one of the greatest teams in NBA history?
- ground truth answer: the Golden State Warriors team of 2017
范围“Worriors”也是一个正确的答案,但是从跨熵训练的角度来看,它并不比跨度“历史”更好。熊等人(2018)提出了一种混合训练目标,将位置交叉熵损失和训练后的单词重叠量与强化学习相结合。基本上,他们使用经过交叉entroy loss训练的$P^{(start)} {(i)}$和$P^{(end)} {(i)}$来采样答案的开始和结束位置,然后使用F1分数作为奖励函数。
对于阅读理解问题的自由形式回答,近年来在训练更好的SEQ2SEQ模型方面取得了许多进展,尤其是在神经ma- chine翻译环境下,如句子水平训练(Ranzato et al., 2016)和最小风险训练(Shen et al., 2016)。然而,我们在阅读理解问题上还没有看到很多这样的应用。
数据增加。数据增强是一种非常成功的image识别方法,但在NLP问题中研究较少。Yu等(2018)提出了一种为阅读理解模型创建更多训练数据的简单技术。技术称为backtranslation——基本上就是他们利用两个最先进的神经机器翻译模型:一个模型从英语到法语和其他模型从法语,英语,和解释文章中的每一句话贯穿两个模型(如果需要一些修改答案)。在F1值上,他们通过在SQUAD上这样做获得了2分。Devlin等(2018)也发现,SQUAD与TRIVIAQA联合训练(Joshi等,2017)可以适度提高SQUAD上的性能。【译者注,用这种方式,理论上可以共享大多数语言的数据集】
3.4.5 Summary
到目前为止,我们已经讨论了不同方面的最新进展,总而言之,这些进展有助于当前阅读理解基准(尤其是SQUAD)的最新进展。哪些组件比其他组件更重要?我们需要把这些都加起来吗?这些最新的进展是否可以推广到其他阅读理解任务?它们如何与不同的语言理解能力相关联?我们认为这些问题中的大多数还没有一个明确的答案,仍然需要大量的调查。
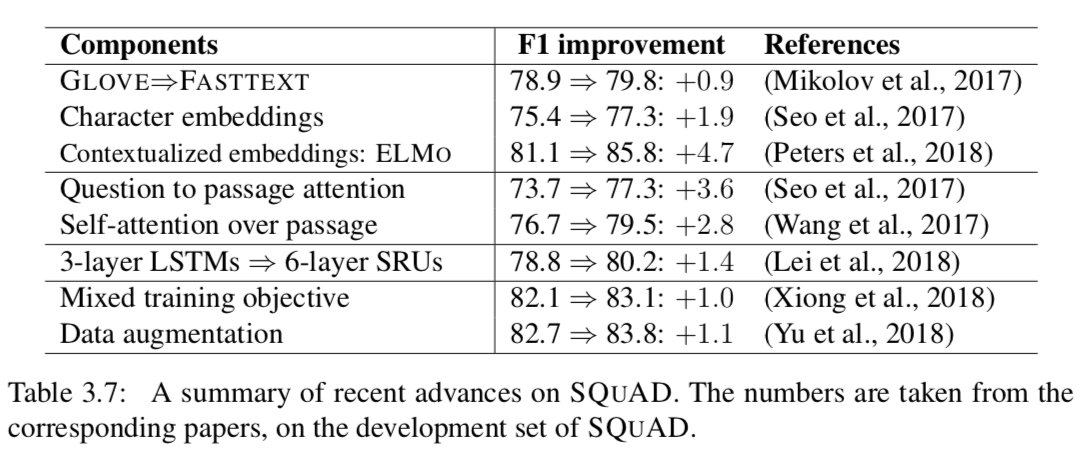
我们在表3.7中编制了对SQUAD不同组件的改进。我们想提醒读者,这些数字并不是直接可比较的,因为它们是建立在不同的模型架构和不同的实现之上的。我们希望这个表格至少反映了一些关于这些组件在SQUAD数据集中重要性的想法。正如所看到的,所有这些组件或多或少都会对最终的性能做出贡献。最重要的创新可能是使用上下文的单词嵌入(例如ELMO),而注意力函数的制定也很重要。研究这些进步是否可以推广到未来的其他阅读理解任务,将是非常重要的。

若有收获,就点个赞吧
0 人点赞
