PART I Neural Reading Comprehension: Foundations
Chapter 2 An Overview of Reading Comprehension
When a person understands a story, he can demonstrate his understanding by answering questions about the story. Since questions can be devised to query any aspect of text comprehension, the ability to answer questions is the strongest possible demonstration of understanding. If a computer is said to understand a story, we must demand of the computer the same demonstration of understanding that we require of people. Until such demands are met, we have no way of evaluating text understanding programs.
(当一个人理解一个故事的时候,他可以通过回答关于这个故事的问题来表明他的理解(程度)。因为问题可以提问文本理解的任何方面,那么回答问题的能力就是对理解程度的最可能的表示。如果说一台电脑理解了一个故事,我们必须像要求人类一样要求电脑。在这样的要求满足之前,我们无法衡量任何文本理解系统。)
Wendy Lehnert, 1977
在这一章,我们的目的是为读者提供一个阅读理解的概述。我们从阅读理解的历史开始(2.1节),从上世纪70年代开发的早期系统,到为这项任务建立机器学习模型的尝试,再到最近神经(深度学习)方法的复兴。这一领域已经完全被神经阅读理解所重塑,并且取得了令人兴奋的进展。
然后,我们在2.2节中正式将阅读理解任务定义为一个监督学习问题,并根据答案类型描述了四个不同的类别。最后,我们将讨论它们的评估指标。
接下来我们简要讨论一下阅读理解和问答(QA)的区别,特别是它们的最终目标(2.3节)。最后,我们会在2.4节中讨论大规模数据集和神经模型的相互作用是如何促进现代阅读理解的发展的。
2.1 History
2.1.1 Early Systems
建立自动阅读理解系统的历史可以追溯到四十多年前。在20世纪70年代,研究人员已经认识到把阅读理解作为一种方法来测试计算机程序对语言的理解能力的重要性。
最著名的早期作品之一是Lehnert(1977)中详细描述的QUALM。基于脚本和计划框架,Lehnert(1977)设计了一个问答的理论,并且专注于语用问题和故事上下文在问答中的重要性,来作为对人类阅读理解的建模(Schank and Abelson, 1977)。这个早期工作为语言理解设置了一个强大的愿景,但是当时构建的实际系统非常小,仅限于手工编码的脚本,并且很难推广到更广泛的领域。
由于问题的复杂性,这方面的研究在20世纪80年代和90年代大多被忽视。在20世纪90年代末,人们对阅读理解的兴趣有了一些小小的复苏,例如Hirschman等人(1999)创建了一个阅读理解数据集,以及随后在ANLP/NAACL 2000年举办了一个关于阅读理解测试作为基于计算机的理解系统评估的研讨会。数据集包括60个用于开发的故事和60个用于测试的三至六年级的故事,附有一些简单的who,what,when,where,why这样的简单问题。它只需要系统返回包含正确答案的句子。这一阶段开发的系统主要是基于规则的词包方法。例如DEEP READ 系统(Hirschman et al. 1999)中进行词干分析、语义类识别和代词解析等浅层语言处理,或者像是QUARC系统(Riloff and THElen,2000)中手动生成基于词汇和语义对应的规则或者是以上两个的组合体(Charnizak et al., 2000)。这些系统在检索正确句子时达到了30%-40%的准确率。
2.1.2 Machine Learning Approaches
在2013年至2015年之间,(人们)在将阅读理解定义为一种supervised learning问题方面做出了显著的努力。研究员以(文章,问题,回答)三元组的形式收集人类标注好的训练例子,希望我们可以训练统计模型来学习将一段话和问题形成的对映射到他们相对应的答案上面去:f(passage, question)—>answer。
在此期间,两个值得注意的数据集是MCTEST (Richardson et al., 2013)和PROCESSBANK (Berant et al., 2014)。MCTEST收集660个虚构的故事,每个故事有4个多选题(每个问题有4个假设答案,其中一个是正确的)(Table 2.1 (b))。PROCESSBANK旨在回答描述生物过程的段落中的二选择问题,并要求理解过程中实体和事件之间的关系。数据集由585个问题组成,分布在200段中。
在最初的MCTEST paper中,Richardson等人(2013)在没有利用任何训练数据的情况下,提出了几个基于规则的基线(baseline)。一种是启发式滑动窗口方法,它测量问题、答案和滑动窗口中单词之间的加权单词重叠/距离信息;另一种方法是通过将每个问答对转换为一个语句来运行现成的文本蕴涵系统。这个数据集后来启发了一系列机器学习模型(Sachan et al., 2015;Narasimhan和Barzilay, 2015;Wang et al., 2015)。这些模型大多建立在一个简单的max-margin学习框架之上,该框架具有丰富的手工设计的语言特性,包括句法依赖、语义框架、指代消解、篇章关系和单词嵌入。MC500的性能从63%略微提高到70%左右。在PROCESSBANK数据集上,Berant等人(2014)提出了一种统计模型,该模型首先学会预测流程结构,然后将问题映射到可以针对该结构执行的正式查询。同样,模型结合了大量的手工特征,最终在二分类任务上获得了66.7%的准确率。


Table 2.1: A few examples from representative reading comprehension datasets: (a) CNN/DAILY MAIL (Hermann et al., 2015), (b) MCTEST (Richardson et al., 2013), (c) SQUAD (Rajpurkar et al., 2016) and (d) NARRATIVEQA (Kocˇisky` et al., 2018).
与早期基于规则的启发式方法相比,这些机器学习模型取得了一定的进步。然而,它们的改进仍然相当有限,其缺点总结如下:
- 这些模型严重依赖于现有的语言工具,如依赖依存解析和语义角色标记(SRL)系统。然而,这些语言表示任务还远远没有解决,现成的工具通常是从单个领域(的文章)(例如,newswire文章)训练而来,在实际使用中存在泛化问题。因此,利用现有的语言注释作为特性有时会在这些基于特性的机器学习模型中增加噪音,而更高级别的注释(例如,篇章关系与词性标记),会让情况变得更糟糕。
- 模拟人类水平的理解是一个难以捉摸的挑战,而且总是很难从当前的语言表征中构建有效的特征。例如,对于图1.1中的第三个问题:How many friends does Alyssa have in this story?,当证据散布在整个文章中,基本不可能构建出一个有效特征的。
- 尽管我们可以从人类标记的阅读理解示例中训练模型,这确实激励人心,但这些数据集仍然太小,无法支持表达性统计模型。例如,用于训练依存解析器的English Penn Treebank数据集包含39,832个示例,而在MCTEST中,用于训练的示例仅为1480个——更不用说阅读理解了,作为一项综合性的语言理解任务,阅读理解更加复杂,并且需要不同的推理能力。
2.1.3 A Resurgence: The Deep Learning Era
这个领域的转折点出现在2015年。DeepMind研究人员Hermann等人(2015)提出了一种新颖而廉价的方案,用于为学习阅读理解模型创建大规模监督训练数据。他们还提出了一个神经网络模型——一个基于attention机制的LSTM模型,命名为THE ATTENTIVE READER——并证明它在很大程度上优于符号NLP方法。在实验中,在CNN数据集中,THE ATTENTIVE READER获得63.8%的准确率,而符号NLP系统最多获得50.9%的准确率。数据创建的思想如下:CNN和《每日邮报》附有一些要点,总结了文章中所包含的信息。他们将一篇新闻文章作为passage,通过使用一个placeholder 来替换一个实体(entity)的方式将其中的一个要点转换为一个完形填空式的问题,而答案就是这个被替换的实体。为了确保这个系统需要真正的理解文章来完成这个任务,而不是使用世界知识(译者,知识库,即符号系统)或者语言模型来回答问题,他们运行了实体识别和指代消解系统,并且将所有在指代链中提到的每个实体替换为一个抽象的实体标记(例如:@entity6,可以在Table2.1(a)中看到例子)。最后,他们几乎没有任何成本地收集了近100万个数据示例。
【译者:Obviously,研究怎么生成训练集也是一门学问。但我一直很好奇,致力于研究数据集来促进模型的发展,是不是就像是致力于研究更好的教材来让学生学习的更好一个道理。。。】
更进一步,我们的工作(Chen et al., 2016)研究了这个有史以来第一个大型的阅读理解数据集,并证明了一个简单、精心设计的神经网络模型(第3.2节)能够将CNN数据集的性能提升到72.4%,这是另一个8.6%的绝对提升。更重要的是,与传统的基于特征的分类器相比,神经网络模型能够更好地识别词汇匹配和其释义。然而,尽管这个半合成的数据集为训练有效的统计模型提供了一个理想的方法,但我们的结论是,由于数据的创建方法和指代误差,该数据集似乎是有噪声的,并且对于进一步的推动相关进展的帮助是有限的。
为了解决这些限制,Rajpurkar等人(2016)收集了一个名为STANFORD QUESTION ANSWER DATASET(SQUAD)的新数据集。数据集包含了536篇维基百科文章中的107,785对问答对,这些问题都是由群体工作者提出的,每个问题的答案对应相应的文章中的一段文本 (表2.1 (c))。SQUAD是第一个具有自然问题的大规模阅读理解数据集。由于其高质量和可靠的自动评估,该数据集引起了NLP社区的极大兴趣,并成为该领域的中心基准。这反过来启发了一系列新的阅读理解模型(Wang and Jiang, 2017; Seo et al., 2017; Chen et al., 2017; Wang et al., 2017; Yu et al., 2018) 并且研究的进展十分迅速,截至2018年10月,表现最好的单一的系统实现了91.8%的F1得分(Devlin et al ., 2018),而这个已经超过91.2%,我们预期的人类表现,而最初的作者在2016年构建的基于特征的分类器只获得了51.0%的F1值,如图2.1所示。
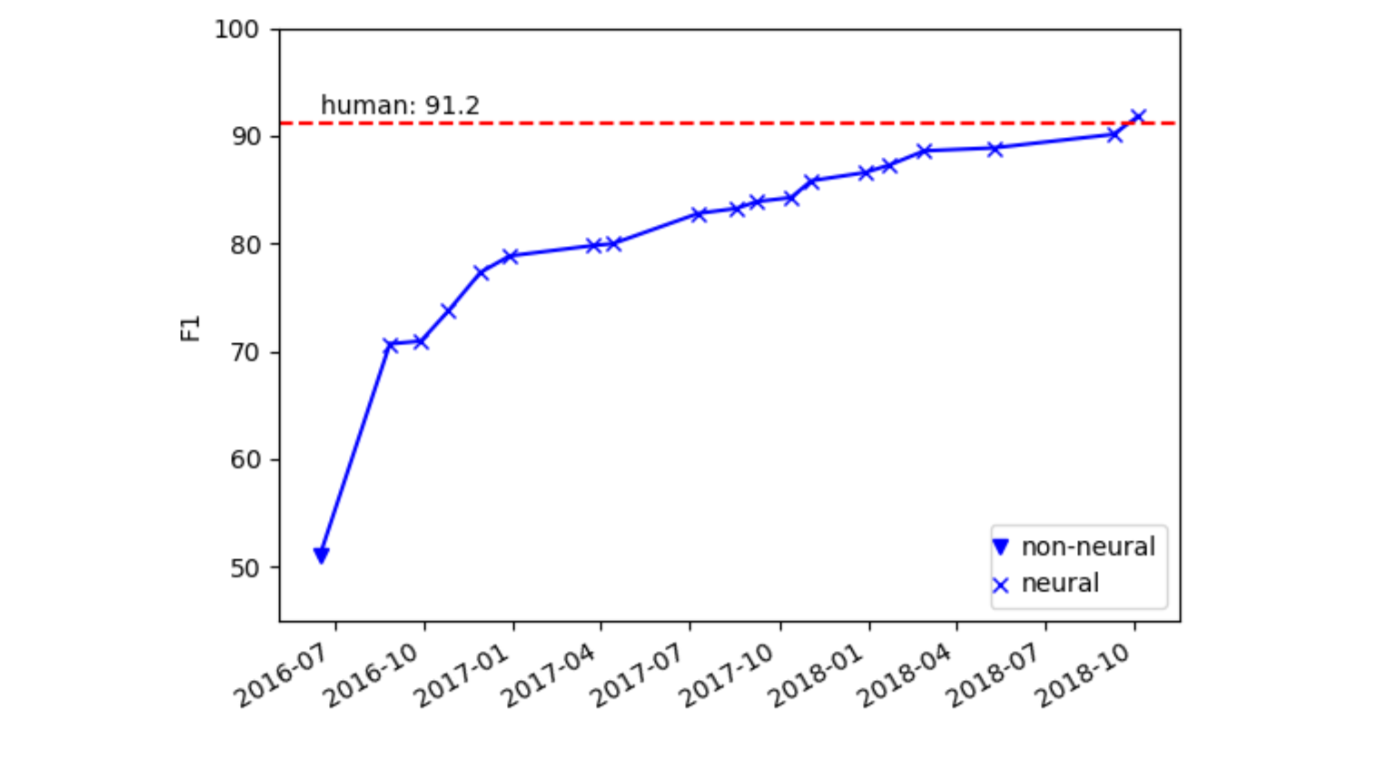
目前所有在SQUAD上面表现最好的系统都是建立在端到端神经网络或深度学习模型上的(end-to-end neural networks, or deep learning models)。这些模型往往会先从将文章和问题中的每一个单词表示为一个稠密向量开始(例如,300维)。经过几次建模或者交互层,最后进行预测。所有的参数可以使用梯度下降算法或者它的变种一起进行优化。这一类模型可以被称为神经阅读理解(neural reading comprehension),我们将会在第三章详细的阐述他。不同于基于特征的分类起,神经阅读理解模型有几个优点。
他们不依赖于任何下游的语言学特征(比如,依存分析或者指代消解),并且所有的特征是在一个统一的端到端的的框架中独立学习来的。这避免了语言学标注的噪音,并且也在可用的特征空间中提供了更好的了灵活性。
传统的符号NLP系统受困于一个严重的问题:特征通常非常稀疏,并且泛化性非常差。例如,为了回答一个问题:
- How many individual libraries make up the main school library?
而文章中的相关内容如下
“… Harvard Library, which is the world’s largest academic and private library system, comprsing 79 individual libraries with over 18 million volumes”
所以一个系统必须基于标记好的特征来学习comprising与make up的一致性,例如下面的特征: $$ pwi = comprising ∧ qw_j = make ∧ qw{j+1} = up. $$ 这里并没有足够的数据来给这些特征赋予正确的权重。这在所有的非神经NLP模型中是一个共有的问题。利用低维,稠密的词向量共享相似词语之间在统计上的强度,可以有效的缓解稀疏性。
这些模型从从构建大量手工特征的劳动中解脱出来。因此,神经模型在概念上更简单,(研究)重点可以转移到神经结构的设计(译者注:可以从构建手工特征中解放,转而研究神经网络结构)。由于现代深度学习框架如TENSORFLOW和PYTORCH的发展,已经取得了很大的进步,现在开发新的模型又快又容易。
毫无疑问,在SQUAD上面达到人类表现程度是不可思议,并且可以说是我们在过去几年在NLP社区中看到的最大成果之一。然而,解决SQUAD任务并不能等于解决机器阅读理解。我们需要承认SQUAD是有限的。因为问题必须用文章中的一段文本来回答,而且大多数SQUAD的例子相对非常简单,并且不需要复杂的推理。
这个领域还在进一步发展。围绕着创建大规模、更具挑战性的阅读理解数据集这一主题,近年来出现了大量的数据集:TRIVIAQA (Joshi et al., 2017), RACE (Lai et al., 2017), QANGAROO (Welbl et al., 2018), NARRATIVEQA (Kocˇisky` et al., 2018), MULTIRC (Khashabi et al., 2018), SQuAD 2.0 (Rajpurkar et al., 2018), HOTPOTQA (Yang et al., 2018)等。这些数据从各种来源收集(Wikipedia, newswire articles, fictional stories or other Web resources),并且以不同的方式构建。他们的目的是应对许多之前没有被解决的挑战:独立于段落的问题,需要多个句子甚至多个文档来回答的问题,基于长文档(比如一本书)的问题,或者不能从段落中回答的问题。在撰写本文时,这些数据集大多还没有得到解决,并且最先进的方法和人类的水平之间仍然存在很大的差距。阅读理解已成为当今自然语言处理中最活跃的领域之一,仍有许多待解决的问题。我们将在4.2节中更详细地讨论阅读理解数据集的最新发展。
2.2 Task Definition
2.2.1 Problem Formulation
阅读理解的任务可以表述为一个监督学习问题:
给定一组训练实例{(pi, q_i, a_i)}^n{i=1} ,目标是学习一个预测器f,它以一段文本p和一个相应的问题q作为输入,给出答案a作为输出。
f:(p, q) →a (2.1)
令p=(p1,p_2, … , p{lp}),q = (q_1,q_2,…,q{l_q}),其中l_p和l_q分别表示文本(passage)和问题(question)的长度。V为预定义词汇表,则对于i=1,。。。。,l_p,p_i∈V,且i=1,。。。。,l_q,q_i∈V。在这里,我们只把文本p看作一个由lp单词序列表示的短段落。将其扩展到多段形式(Clark and Gardner, 2018)非常简单,其中p是一组段落,或者将其分解为更小的语言单元,如句子。
根据答案类型的不同,答案a可以采取完全不同的形式。一般来说,我们可以把现有的阅读理解任务分为四类:
完形填空类型(Cloze style):问题包含一个placeholder(占位符)。例如:
RTottenham manager Juande Ramos has hinted he will allow _ to leave if the Bulgaria striker makes it clear he is unhappy.
在这些任务中,系统必须基于文本来猜测哪些词或实体来完善句子(问题)。并且答案要么是选择从一组预定义的候选集中选择要么是从一个完整的词汇表中选择。比如说,,在WHO-DID-WHAT数据集中 (Onishi et al ., 2016),答案必须是文本中的一个人名,而其候选集的大小平均为3.5。
多项选择类型(Multiple choice):在这个类别下,正确答案从k个假设答案中选择(比如:k=4) A={a1, …, ak} where ak = (ak,1,ak,2,…ak,la,k),ak,I < V
正确的答案可以是一个单词,一个短语或者是一句话。给出的假设答案中有一个是正确的,所以a必须从{a1,…ak}中选择。
范围预测类型(Span prediction):这个类别也被称为抽取式问答(extractive question answering)并且答案必须是文本中的一个范围。因此,答案可以表示为(a_start, a_end),其中1<=a_start<=a_end<=lp。并且答案对英语pastart,…paend。
自由形式回答类型(Free-form answer):最后一种类型允许答案是任何形式的文本(即,任意长度的单词序列),形式上:a∈V。
表2.1给出了每个类型的问题所属典型数据集的示例:CNN/DAILY MAIL (Hermann et al., 2015) (cloze style), MCTEST (Richardson et al., 2013) (multiple choice), SQUAD (Rajpurkar et al., 2016) (span prediction) and NARRA- TIVEQA (Kocˇisky` et al., 2018) (free-form answer).
2.2.2 Evaluation
我们已经正式定义了四种不同类别的阅读理解任务,接下来我们将讨论它们的评估指标。
【译者 注:对于任何任务来说,衡量结果的好坏都是非常重要的一件事。如果有量化的机制来评估好坏,可以更好帮助我们作出正确的决策】
对于多项选择题或完形填空题,评估准确性非常简单:系统给出正确答案的问题的百分比,因为答案是从一小组假设答案中选择的。
对于范围预测任务,我们需要将预测的答案与正确答案进行比较。通常,我们使用Rajpurkar等人(2016)提出的两种评估指标,即精确匹配和部分得分:
精准匹配(Exact match,EM)如果预测的答案等于正确答案,则精确匹配(EM)将分配满分1.0分,否则将分配满分0.0分。
F1得分(F1 score)计算预测答案和正确答案之间的平均单词重叠。预测答案和正确答案被看作一堆token,所以token-level的F1得分计算如下:
F1 = 2×Precision×Recall/(Precision+Recall)
Rajpurkar等人(2016)(提出评估指标之后)之后,在评估中所有标点符号都被忽略,对于英语文章,a, an,以及the也被忽略。
为了使评估更可靠,收集每个问题的多个正确答案也很常见。因此,精确的匹配分数只需要匹配任何一个正确答案,而F1分数是计算所有正确答案的最大值,然后对所有问题求平均值。
最后,对于自由形式的回答阅读理解任务,目前还没有最理想的评价标准。一种常见的方法是使用在自然语言生成(NLG)任务中使用的标准评估指标,如机器翻译或摘要,包括BLEU (Papineni et al., 2002)、Meteor (Banerjee和Lavie, 2005)和ROUGE (Lin, 2004)。
2.3 Reading Comprehension vs. Question Answering
阅读理解与问答有着密切的关系。我们可以把阅读理解看作是问答的一个实例,因为它很本质上是基于一篇短文的问答问题。然而,尽管阅读理解和一般的问答问题在问题的形成、方法和评价上有许多共同的特点,但我们认为它们最终目标强调了不同的东西:
问答的最终目标是建立一个能够自动回答人类提出的问题计算机系统,系统可以依赖任何资源。这些资源可以是结构化的知识库、非结构化的文本集合(百科全书、词典、新闻专线文章和一般Web文档)、半结构化的表,甚至是其他模式。为了提高QA系统的性能,人们在(1)如何搜索和识别相关资源,(2)如何集成来自不同信息片段的答案,甚至(3)研究人类在现实世界中通常会问哪些类型的问题上进行了大量的工作。
然而,阅读理解(reading comprehension)强调的是文本理解(text understanding)和一些被认为是衡量语言理解程度的尖锐问题。因此,要回答这个问题,需要对给定的段落有深刻的理解。由于这一关键的区别,这一领域的早期作品大多集中在虚构的故事(Lehnert, 1977)(后来扩展到Wikipedia或Web文档),所以所有回答理解问题的信息都来自文章本身,而不是任何世界知识。这些问题也是专门为测试文本理解的不同方面而设计的。这种区别类似于人们通常在搜索引擎上问的问题与在人类阅读理解测试中通常会提出的问题。
类似地,早期的工作(Mitchell et al.,2009)使用术语微观阅读(micro-reading)和宏观阅读(macro-reading)来区分这两种情况。微阅读侧重于阅读单个文本文档,旨在提取该文档的完整信息内容(类似于我们的阅读理解设定),而宏观阅读则采用大文本集合(如Web)作为输入,提取文本中表达的事实而形成一个很大的集合,而不需要提取每一个事实。尽管宏观阅读则需要考察语言理解的更深层次,但是宏观阅读可以通过分析文本中事实的简单措辞,有效地利用跨文档的信息冗余。
本文主要研究阅读理解。在第五章,我们将回到更一般的问题回答,讨论其相关工作,并证明阅读理解也可以帮助建立问题回答系统。
2.4 Datasets and Models
从2.1.3节可以看出,近年来阅读理解的成功主要是由两个关键部分驱动的:大型阅读理解数据集和端到端神经阅读理解模型。他们共同努力推进这一领域的发展,并推动建立更好阅读理解系统的边界:
一方面,大规模阅读理解数据集的创建使得训练神经模型成为可能,同时也展示了它们相对于符号NLP系统的竞争力。这些数据集的可用性进一步吸引了我们研究社区的大量关注,并激发了一系列建模创新。受益于所有这些努力,已经取得了巨大的进展。
另一方面,了解现有模型的性能有助于进一步认识现有数据集的局限性。这促使我们寻求更好的方法来构建更具挑战性的数据集,以实现文本的机器压缩的最终目标。
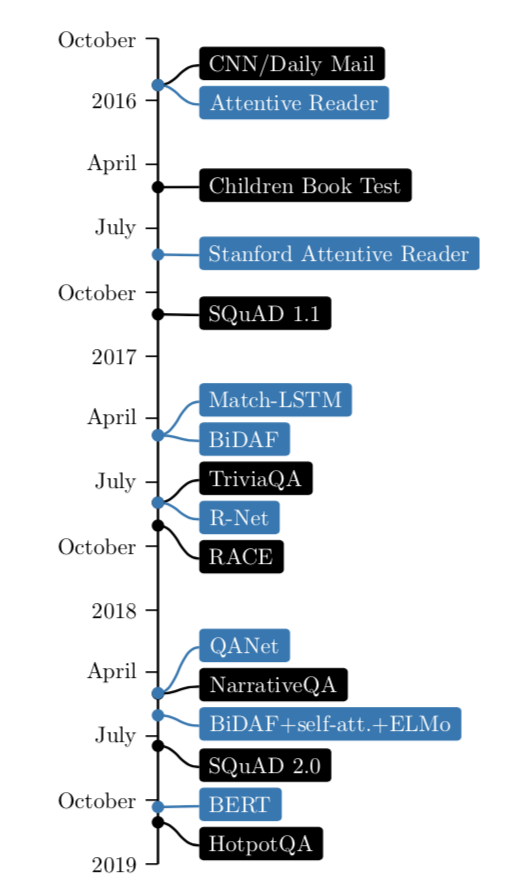
图2.2:最近神经阅读理解领域的数据集(黑色)和模型(蓝色)的发展。对于时间轴,除了BERT (Devlin et al., 2018),我们使用了相应论文发表的日期。
图2.2显示了2016年以来关键数据集和模型的最新开发时间轴。正如所看到的,尽管只有三年的时间,这个领域已经取得了惊人的进展。在建立更好的数据集和更有效的模型方面的创新交替出现,并对该领域的发展作出了贡献。在未来,我们认为继续发展这两个部分都同样重要。
在下一章中,我们将主要关注建模方面,并会使用我们前面描述的两个表示数据集:CNN/DAILY MAIL和SQUAD。在第4章,我们将讨论更多关于数据集和模型的进展和未来的工作。

若有收获,就点个赞吧
0 人点赞
