- Preface 译者 注
- 摘要
- Acknowledgements
- Chapter 1 Introduction
- Chapter 2 An Overview of Reading Comprehension
- Chapter 3 Neural Reading Comprehension Models
- Chapter 4 The Future of Reading Comprehension
- Chapter 5 Open Domain Question Answering
- Chapter 6 Conversational Question Ansering
- Chapter 7 Conclusions
- Bibliography
- 结束-感想
- 译者介绍
- Docs »
- Chapter 6 Conversational Question Ansering
- View page source
Chapter 6 Conversational Question Ansering¶
在最后一章,我们讨论了如何从神经阅读理解中构建一个通用知识的问答系统。然而,大多数现在的QA系统被限制于回答独立的问题,例如,每次我们问一个问题,系统返回一个结果而不具备考虑上下文的能力。在这一章中,我们打算处理另一个具有挑战性的问题Conversational Question Answering。在这个问题下,机器必须理解一个文本篇章并且回答一系列出现在对话中的问题。
人类通过一系列相互关联的问题和答案的对话来收集信息。因此,为了帮助机器收集信息,有必要使它们能够回答会话问题。图6.1显示了正在阅读一篇文章的两个人之间的对话,一个充当提问者,另一个充当回答者。在这个对话中,第一个问题之后的每个问题都依赖于对话的历史。例如,Q5 who?只有一个词,不知道已经说了些什么是不可能回答的。提出简短的问题是一种有效的人类对话策略,但是对于机器来说,这些问题确实很难解析。因此,会话问答结合了对话和阅读理解的挑战。
我们相信建造一个能够回答这样的对话问题的系统能够在我们未来的对话AI系统中扮演一个重要的角色。为了解决这个问题,我们需要建造有效的datasets以及对话QA模型,并且我们将会在这一章中描述它们二者。
 image-20190727225457740
image-20190727225457740
本章组织如下。我们首先在第6.1节讨论相关工作,然后在第6.2节中介绍COQA (Reddy et al., 2019),这是一个会话性的问题回答挑战,用于测量机器参与问答式对话的能力。我们的数据集包括127k问题以及答案,来自七个不同领域的8k个文本段落对话。我们定义任务并描述数据集收集过程。我们还对数据集进行了深入的分析,发现会话问题具有现有阅读理解数据集中不存在的挑战性现象,如指代和语用推理。接下来,我们将描述我们在6.3节中为COQA构建的几个强大的会话和阅读理解模型,并在6.4节中给出实验结果。最后,我们讨论会话问答的未来工作(6.5节)。
6.1 Related Work¶
对话性问题的回答与dialogue直接相关。自然语言理解的主要目标之一是建立对话代理或对话系统,以便用自然语言与人类对话。最常见的两类对话系统是:任务导向和闲谈对话。任务导向的对话系统是为特定的任务而设计的,用于进行简短的对话(例如,预订机票或预订餐馆)。它们是根据任务完成率或任务完成时间来评估的。相比之下,闲谈聊天对话系统是为扩展的、非正式的对话而设计的,没有特定的目标。通常,用户参与和交互的时间越长,这些系统就越好。
回答问题也是对话系统的一个核心任务,因为人类与对话主体互动最常见的需求之一就是寻找信息,提出各种话题的问题。基于qa的对话技术已经在自动化的个人助理系统中得到了广泛的发展,比如亚马逊的ALEXA、苹果的SIRI或谷歌assistant,这些系统要么基于结构化的知识库,要么基于非结构化的文本集合。现代对话系统大多建立在深度神经网络之上。对于不同类型对话系统的神经方法的全面调查,我们建议读者参考(Gao et al., 2018)。
我们的工作和(Das et al., 2017)的Visual Dialog任务以及(Saga et al ., 2018)的Complex Sequential Question Answering 任务非常相关,这两个任务分别在图像和知识图谱上面进行了会话性的问答,后者关注通过套用模版获得的问题。图6.2分别展示了每个任务的一个例子。我们关注的是一段文字的对话,这需要阅读理解的能力。
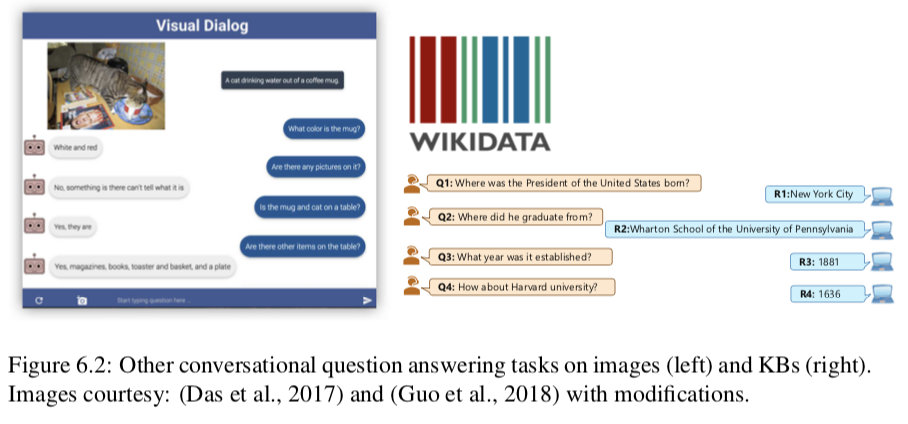 image-20190727225554291
image-20190727225554291
另一个相关的研究是sequential question answering(Iyyer et al., 2017; Talmore and Berant, 2018),在这个问题中一个复杂的问题被拆解为一系列简单的问题。例如,问题What super hero from Earth appeared most recently? 可以被拆解为以下三个问题:1,Who are all of the super heroes? 2, Which of them come from Earch? And 3, Of thos, who appeared most recently? 因此,他们的关注点是如何通过连续的问答回答一个复杂的问题,而我们更感兴趣的是自然存在的各种话题的对话,而问题可以依赖于对话的历史。【译者注:他们研究的是解决一个复杂的问题,但是自然对话往往直接是由一系列的问题回答构成的,这才是我们(cdq)要解决的问题】
6.2 CoQA: A Conversational QA Challenge¶
在这个小节,我们介绍COQA,用于建造Conversional Question Answering systems的新数据集。我们开发COQA有三个主要目标。第一个是关注人类对话中问题的本质。就像在图6.1中可以看到的一个例子,在这个对话中,第一个问腿之后的每一个问题都依赖于对话历史。现在,没有大型阅读理解数据集包含依赖于对话数据集的问题并且这个是COQA开发的主要目的。
第二个目标是保证对话中的回答的自然性。就像我们在之前的章节中讨论过的,大多数现存的阅读理解数据集要么将答案限制在给定篇章的一个连续范围内,要么就允许存在不太像人类说出的自由形式的答案(e.g. NARRATIVEQA)。我们的愿望是1)答案不应该只基于范围获取,这样任何问题都可以问,对话也可以自然进行。例如,对于Q4 How many?如图6.1所示。2)仍然支持具有强力人类性能的可靠的自动评估。因此,我们提出答案可以是自由形式的文本(抽象的答案),而提取范围作为实际答案的依据。因此,Q4的答案就是简单的Three,而它的基本原理是跨越多个句子的。
COQA的第三个目标是支持构建性能可靠的跨领域QA系统。目前的阅读理解数据集主要集中在单一领域,难以对现有模型的泛化能力进行测试。因此,我们从七个不同的领域收集数据——儿童故事、文学、初中和高中英语考试、新闻、维基百科、科学文章和Reddit。最后两个用于域外评估。
6.2.1 Task Definition¶
我们首先正式的定义我们的任务。给定一个段落P,对话由n个回合组成,每个回合由(Qi, Ai, Ri), i = 1,…n,其中Qi和Ai表示第i个回合的问题和答案,Ri是支持答案Ai的基本原理,并且必须是文章的单个跨度。这个任务被定义为根据到目前为止的对话回答下一个问题Qi: Q1, A1,…Qi−1 Ai−1。值得注意的是,我们收集Ri的目的是希望它们能够帮助理解答案是如何产生的,并改进我们的模型的培训,而在评估过程中没有提供这些模型。
对于图6.3中的示例,对话以问题Q1开始。根据文章中的证据R1,我们用A1回答Q1。在这个例子中,回答者只写了Governor作为答案,但选择了一个更长的理由,The Virginia governor’s race。当我们讲到Q2时where?,我们必须回顾谈话的历史,否则它的答案可能是Virginia or Richmond。在我们的任务中,会话历史对于回答许多问题是必不可少的。我们使用会话历史Q1和A1来回答Q2和A2基于证据R2。对于一个无法回答的问题,我们给出unkonwn作为最终答案,不强调任何理由。
 image-20190727232350596
image-20190727232350596
在这个例子中,我们观察到焦点的实体随着谈话的进展而变化。提问者在Q4中用his代表Terry,在Q5中用he代表Ken。如果不能正确地解决这些问题,我们将得到不正确的答案。问题的会话性质要求我们从多个句子中推理(当前的问题和之前的问题或答案,以及文章中的句子)。常见的情况是,一个问题可能需要跨越多个句子的基本原理(例如图6.1的Q1 Q4和Q5 )。我们在6.2.3中描述了附加的问答类型。
6.2.2 Dataset Collection¶
我们将数据集收集过程详细描述如下。每段对话都有两个注释者,一个提问者和一个回答者。这种设置比使用一个注释器同时充当提问者和回答者有几个优点:1)当两个注释器谈论一篇文章时,他们的对话流与自言自语相比是自然的;2)当一个注释者回答一个模糊的问题或一个不正确的答案时,另一个注释者可以升起一个标志,我们用它来识别坏工人;3)当两个注释者有不同意见时,他们可以通过单独的聊天窗口讨论指导方针。这些措施有助于防止垃圾邮件,并获得高协议数据
我们使用Amazon Mechanical Turk (AMT)对通道a上的工人进行配对,并使用ParlAI Mturk API (Miller et al., 2017)。平均来说,每一篇文章需要3.6美元用于收集对话,另外4.5美元用于为开发和测试数据收集另外三个答案。
Collection interface。我们为提问者和回答者提供了不同的界面(图6.4和图6.5)。提问者的角色是提出问题,而回答者的角色是除了强调基本原理之外,还要回答问题。为了增加词汇的多样性,我们希望提问者避免在文章中使用精确的词汇。当他们输入一个已经出现在文章中的单词时,我们提醒他们如果可能的话重新解释问题。对于答案,我们希望答题者坚持使用文章中的词汇,以限制可能答案的数量。我们鼓励这一点,自动复制突出显示的文本到答案框中,并允许他们编辑复制的文本,以生成一个自然的答案。我们发现78%的答案至少有一次修改,比如改变一个单词的大小写或添加标点符号。
 image-20190727233055468
image-20190727233055468
 image-20190727233125305
image-20190727233125305
Passage selection。我们从七个不同的领域选择段落:儿童故事从mct(理查森et al ., 2013),文学从项目Gutenberg4,初中和高中英语考试从种族(赖et al ., 2017),从CNN新闻文章(Hermann et al ., 2015),从维基百科的文章,文章从AI2科学问题(Welbl et al ., 2017)和Reddit的文章写作提示数据集(风扇et al ., 2018)。
并不是所有这些领域的文章都适合生成有趣的转换。只有一个实体的文章常常会引发完全集中在那个实体上的问题。我们选择了包含多个实体、事件和代词引用的段落——ing Stanford CORENLP (Manning et al., 2014)。我们把长篇大论的文章截短到前几段,大约有200个字。
表6.1显示了域的分布。我们保留科学和Reddit做的主要领域外的评估。对于每个在域的数据集,我们分手有100个通道的数据(在开发集,100通道的测试集,训练集,其余的。相比之下,对于每个范围之外的数据集,我们只有100个篇章测试集没有任何training或者developing set。
Collecting multiple answers:COQA中的一些问题可能有多个有效答案。例如,图6.3中Q4的另一个答案是共和党候选人。为了解释答案的变化,我们为开发和测试数据中的所有问题收集了三个额外的答案。由于我们的数据是对话式的,问题影响答案,答案又影响后续问题。在前面的例子中,如果最初的答案是共和党候选人,那么下面的问题是他属于哪个党派?一开始就不会发生。当我们将已有对话中的问题展示给新回答者时,很可能会偏离原来的答案,从而使对话变得不连贯。因此,重要的是使它们与最初的答案达成共识。
我们通过将收集答案的任务转换为预测原始答案的游戏来实现这一点。首先,我们向新回答者显示一个问题,当她回答时,我们显示原始答案,并要求她验证她的答案是否与原始答案匹配。对于下一个问题,我们让她猜出最初的答案,并再次验证。我们重复这个过程,直到对话结束。在我们的实验中,当我们使用这个验证设置时,人类F1得分增加了5.4%。
6.2.3 Dataset Analysis¶
什么使得COQA数据集与现有的阅读理解数据集(如SQUAD)相比更具会话性?对话是如何从一个转到另一个的?COQA中的问题表现出什么样的语言现象?我们在下面回答这些问题。
Comparison with SQUAD 2.0: 下面,我们将对COQA和SQUAD 2.0进行深入比较(Rajpurkar等,2018)。图6.6显示了fre- quent三元组前缀的分布。虽然在SQUAD 2.0中不存在COQA的引用,但是COQA的几乎每个部分都包含COQA的引用(他、他、她、it、他们),这表明COQA是高度可会话的。由于答案的自由形式,我们期望在COQA中有比SQUAD 2.0更丰富的问题。尽管有近一半的SQUAD 2.0问题由什么问题主导,但是COQA的分布分布在多个问题类型中。前缀did、was、is、does和does在COQA中经常出现,但在SQUAD 2.0中完全没有。
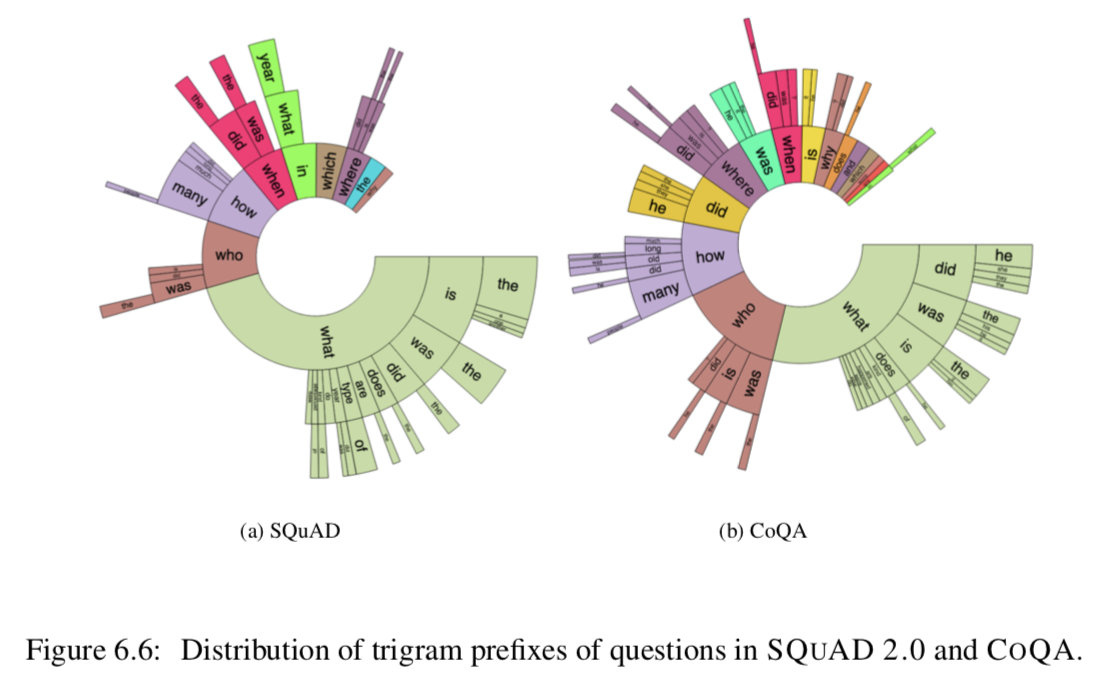 image-20190727233159345
image-20190727233159345
因为一个对话散布在多轮中,我们期望对话的问答能够被缩短到一个独立的交互中。事实上,COQA的问题能够备用一两个单词构造(Who? When? Why?)。就像在Table6.2中看到的,COQA中的为问题长度平均为5.5个单词,但是SQUAD的平均长度为10.1。而COQA中的答案通常比SQUAD中的短2.0。
表6.3提供了关于SQUAD 2.0和COQA中答案类型的见解。尽管SQUAD2.0的原始版本并没有任何不可回答的问题,SQUAD单一地集中在获取他们以导致了比COQA中更高的频率。SQUAD2.0中全部都是提取答案,而COQA中有66.8%的答案可以在忽略标点和大小写之后可以被提取。这高于我们的预期。我们的猜想是人类因为工资这样的人为因素会影响工人提出的能够通过选择文本更快回答的问题值得注意的是,COQA有11.1%以及8.7%的问题是yes或者no这样的答案,而SQUAD2.0一个都没有。这两个数据集都有大量的命名实体和名词短语作为答案。
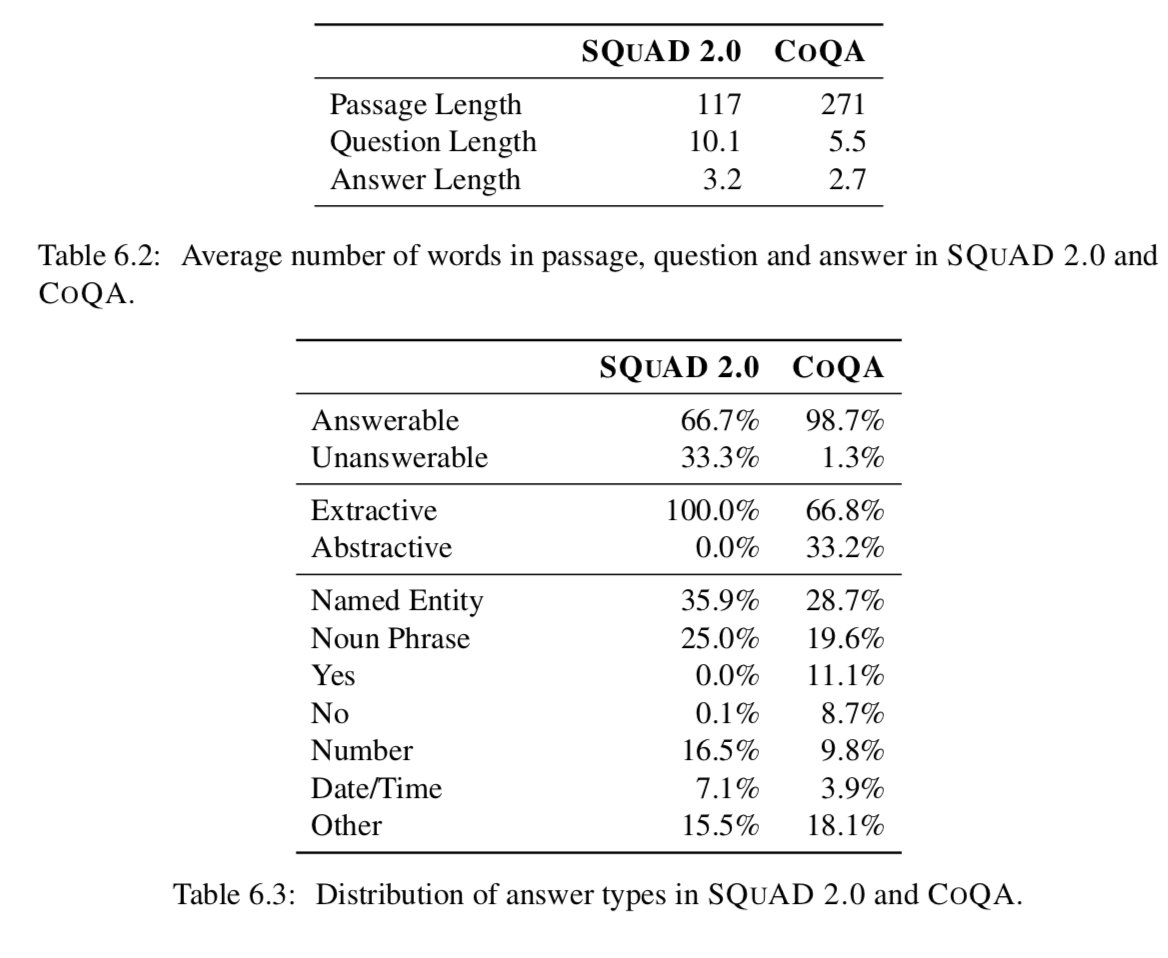 image-20190727233220008
image-20190727233220008
Conversation flow:连贯的谈话必须有平稳的转折。我们希望文章的叙述结构能影响我们的对话流。我们将文章分成10个统一的块,并根据基本原理的跨度来确定某个转弯的兴趣块及其转换。
图6.7描绘了前10个回合的对话流。开始的时候,人们往往会把注意力集中在开始的几句话上,随着谈话的进行,注意力会转移到后面的几句话上。此外,转弯过渡是平滑的,焦点通常保持在同一块或移动到相邻块。最频繁的转换发生在第一个和最后一个块上,同样,这些块也有不同的外部转换。【译者:看起来我们可以通过一个window来圈定上下文的范围】
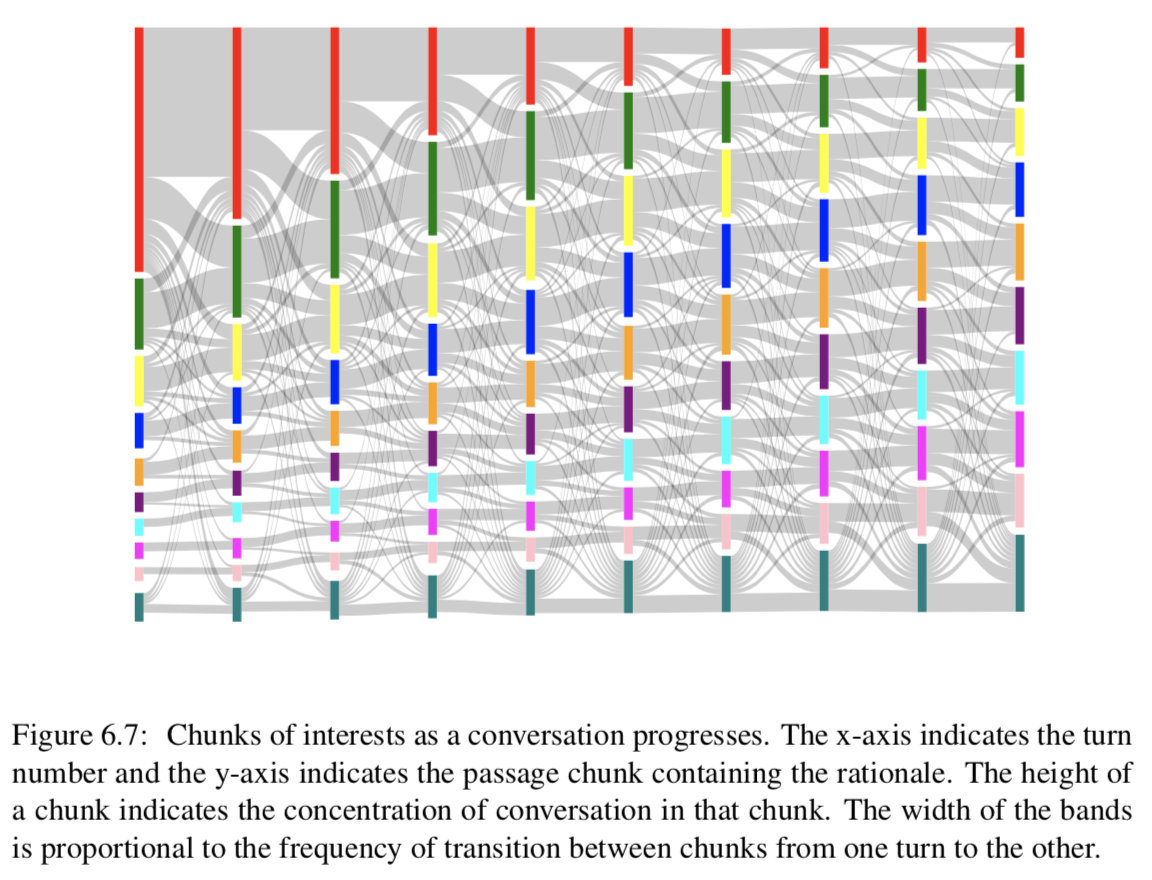 image-20190727233248789
image-20190727233248789
Linguistic phemnomena。我们进一步分析了它们与篇章和会话历史的关系问题。我们在开发集中抽取了150个问题,并对各种现象进行了注释,如表6.4所示。
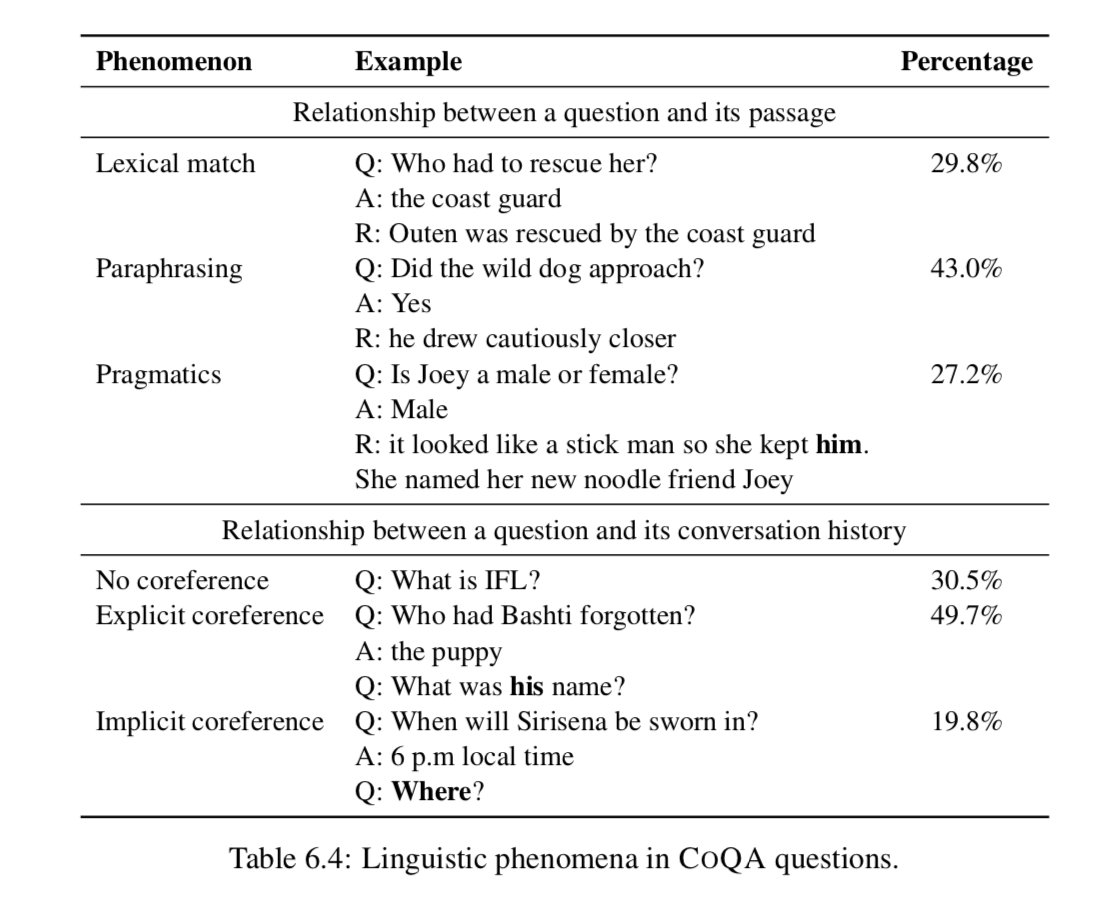 image-20190727233300785
image-20190727233300785
如果一个问题至少包含一个出现在文章中的实义词,我们将其归类为lexical match(词汇匹配)。这些问题约占问题总数的29.8%。如果没有词汇匹配,而是对rational的释义,我们将其归类为paraphrasing(释义)。这些问题包括同义、反义、下义、否定等现象。这些构成了43.0%的问题。剩下的27.2%的问题,不是词汇匹配,我们将他们归类到prgmatics(实际的实用的)这些包括常识类现象和假定现象。例如,问题was he loud and boisterous? 并不是he dropped his feet with the lithe softness of a cat的背后原理的直接转述,但是组成这个世界知识的原理可以回答这个问题。
对于一个问题和它的会话历史之间的关系,我们将问题分为依赖于会话历史还是独立于会话历史。如果不确定,则询问是否包含显式标记。
因此,约有30.5%的问题不依赖于与会话历史的相互参照,而是可以自己回答。几乎一半的问题(49.7%)包含明确的共同参照标记,如he, she, it。它们要么引用对话中引入的实体,要么引用对话中引入的事件。其余19.8%没有显式的协引用标记,而是隐式地引用实体或事件。
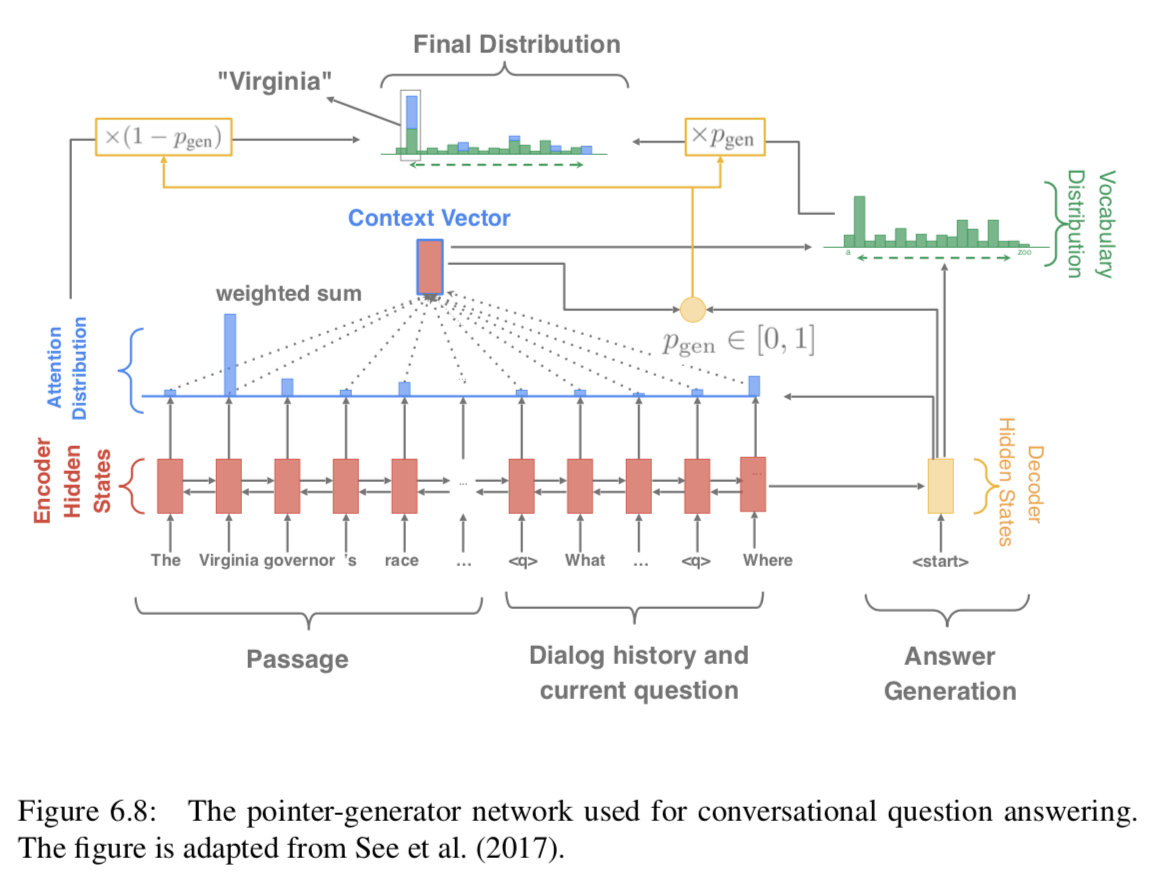 image-20190727233328873
image-20190727233328873
6.3 Models¶
给出一个段落p,对话历史{q1, a1,…qi - 1, ai - 1} and a question qi, the task is to predict the answer ai。我们的任务可以建模为会话响应生成问题或阅读理解问题。我们评估来自每一类模型的强基线,以及COQA上这两种模型的组合。
6.3.1 Conversational Models¶
会话模型的基本目标是根据会话历史预测下一个话语。序列到序列(seq2seq)模型(Sutskever et al., 2014)在生成会话响应方面显示出了良好的结果(Vinyals和Le, 2015;李等,2016;张等,2018)。由于他们的成功,我们使用了一个标准的序列到序列模型,其中包含一个生成答案的注意机制。我们附加了段落、会话历史(最后n轮的问题/答案对)和当前的问题,p qi−n ai−n…
此外,由于答案很可能出现在原文中,我们在解码器中采用了一种复制机制,用于总结任务(Gu et al., 2016;See et al., 2017),它允许(可选地)从文章和对话历史中复制一个单词。我们将这个模型称为Pointer-Generator网络(See et al., 2017), PGNET。图6.8展示了PGNET的完整模型。正式说来,我们用 {h̃i}表示编码器隐藏向量,ht表示在timestep t时候的解码器状态,以及Xt作为输入向量,注意力方程给予 {h̃i}、ht和α来计算(equation 3.13)。上下文向量用公式3.14计算:$c = \sum_i\alpha_ih̃_i$ qi−1
ai−1 qi,并将其输入一个双向LSTM编码器,其中
是用作分隔符的特殊令牌。然后,我们使用LSTM解码器生成答案,该解码器负责处理编码器的状态。和
对于复制机制,它首先计算生成概率pgen∈[0,1],pgen∈[0,1]控制从完整词汇表V(而不是复制一个单词)生成单词的概率:
p{gen} = σ (w{(c)}^Tc + w{(x)}^Tx_t + w{(h)}^Th_t + b ). (6.1)
生成单词w的最后概率分布计算如下:
P(w)=p{gen}P{vocab}(w)+(1−p{gen}) \sum{i:w_i=w} \alpha_i (6.2)
where Pvocab(w) is the original probability distribution (computed based on c and ht) and {wi} refers to all the words in the passage and the dialogue history. For more details, we refer readers to (See et al., 2017).
6.3.2 Reading Comprehension Models¶
我们评估的第二类模型是神经阅读理解模型。特别是跨预测问题的模型不能直接应用,因为大部分COQA问题在文中没有一个跨作为答案,如图6.1中的Q3、Q4、Q5。因此,我们针对这个问题修改了我们在3.2节中描述的STANFORD细心读者模型。由于模型在训练过程中需要文本跨度作为答案,所以我们选择了词汇重叠程度最高的跨度(F1分)作为黄金答案。如果答案在故事中出现多次,我们就用基本原理找到正确的答案。如果在文章中没有出现任何答案,我们就回到另一个未知的标记作为答案(大约17%)。我们在每个问题前加上过去的问题和答案,以说明会话历史,类似于会话模型。
6.3.3 A Hybrid Model¶
最后一个模型是一个混合模型,结合了上述两种模型的优点。阅读理解模型可以预测一个答案的文本跨度,但不能生成与文章不重叠的答案。因此,我们将斯坦福大学的细心读者与PGNET相结合来解决这个问题,因为PGNET可以有效地生成自由形式的答案。在这个混合模型中,我们使用阅读理解模型首先指向文本中的答案证据,然后PGNET nat- uralize将证据转化为最终答案。例如,对于图6.1中的Q5,我们期望阅读理解模型首先预测出她的孙女Annie下午过来的原因,Jessica非常高兴见到她。她的女儿媚兰和媚兰的丈夫约什也要来。,然后PGNET从R5生成A5 Annie, Melanie和Josh。
我们基于经验表现对这两个模型进行了一些更改。对于STANFORD ATTENTIVE READER模型,我们只使用基本原理作为非抽取答案的问题的答案。对于PGNET,我们只提供当前的问题和斯坦福关注读者模型的跨度预测作为编码器的输入。在培训期间,我们将oracle span输入PGNET。
6.4 Experiments¶
6.4.1 Setup¶
对于SEQ2SEQ和PGNET实验,我们使用OPENNMT工具包(Klein et al., 2017)。在阅读理解实验中,我们使用了与SQUAD相同的实现(Chen et al., 2017)。我们对开发数据调优超参数:会话历史中使用的轮数、层数、每层包含的单元数和dropout比率。我们使用GLOVE (Pennington et al., 2014)对会话模型初始化单词映射矩阵,使用基于经验性能的FASTTEXT (Bojanowski et al., 2017)对阅读理解模型初始化单词投影矩阵。我们在训练期间更新映射矩阵,以便学习分隔符(如)的嵌入。
在SEQ2SEQ和PGNET的所有实验中,我们都使用了OPEN- NMT的默认设置:两层LSTMs,编码器和解码器都有500个隐藏单元。利用SGD对模型进行优化,初始学习率为1.0,衰减率为0.5。所有层的dropout比率为0.3。
在所有的阅读理解实验中,我们发现最好的配置是3层LSTMs,每层包含300个隐藏单元。所有LSTM层的dropout率为0.4,word嵌入层的dropout率为0.5。
6.4.2 Experimental Results¶
表6.5给出了模型在开发和测试数据上的结果。参照测试集的结果,SEQ2SEQ模型表现最差,不管这些答案是否出现在文章中,都会生成频繁出现的答案,这是会话模型的一个众所周知的行为(Li et al., 2016)。PGNET通过关注文章中的词汇量来缓解频繁应答问题,并且性能优于SEQ2SEQ17.8分。然而,它仍然落后于STANFORD ATTENTIVE READER 8.5分。原因之一可能是PGNET在回答问题之前必须记住整篇文章,这是STANFORD ATTENTIVE READER避免的巨大开销。但STANFORD ATTENTIVE READER在回答自由形式的问题时却不幸地失败了(参见表格6.6中的Abstractive)。当STANFORD ATTENTIVE READER 送入PGNET的时候,我们增强了STANFORD ATTENTIVE READER和PGNET——STANFORD ATTENTIVE READER在产生自由形式的答案方面,PGNET在关注篇章背后的原理方面。这个组合要优于PGNET和STANFORD ATTENTIVE READER分别21.0以及12.5分。
 image-20190727233626211
image-20190727233626211
Models vs. Human:测试数据的人为性能为88.8 F1,很好地说明COQA的问题有具体的答案。我们最好的模型比人类落后23.7分,这表明用目前的模型很难完成这项任务。我们预计,使用最先进的阅读理解模型 (Devlin et al., 2018) 可能会将结果提高几个百分点。
In-domain vs Out-of-domain:与域内数据集相比,所有模型在域外数据集上的性能都更差。最好的模型下降了6.6点。对于领域内的研究,最好的模型和人类都发现文学领域比其他领域更难,因为文学词汇要求精通英语。对于域外结果,Reddit域显然更困难。这可能是因为Reddit需要对较长的段落进行推理(参见表6.1)。
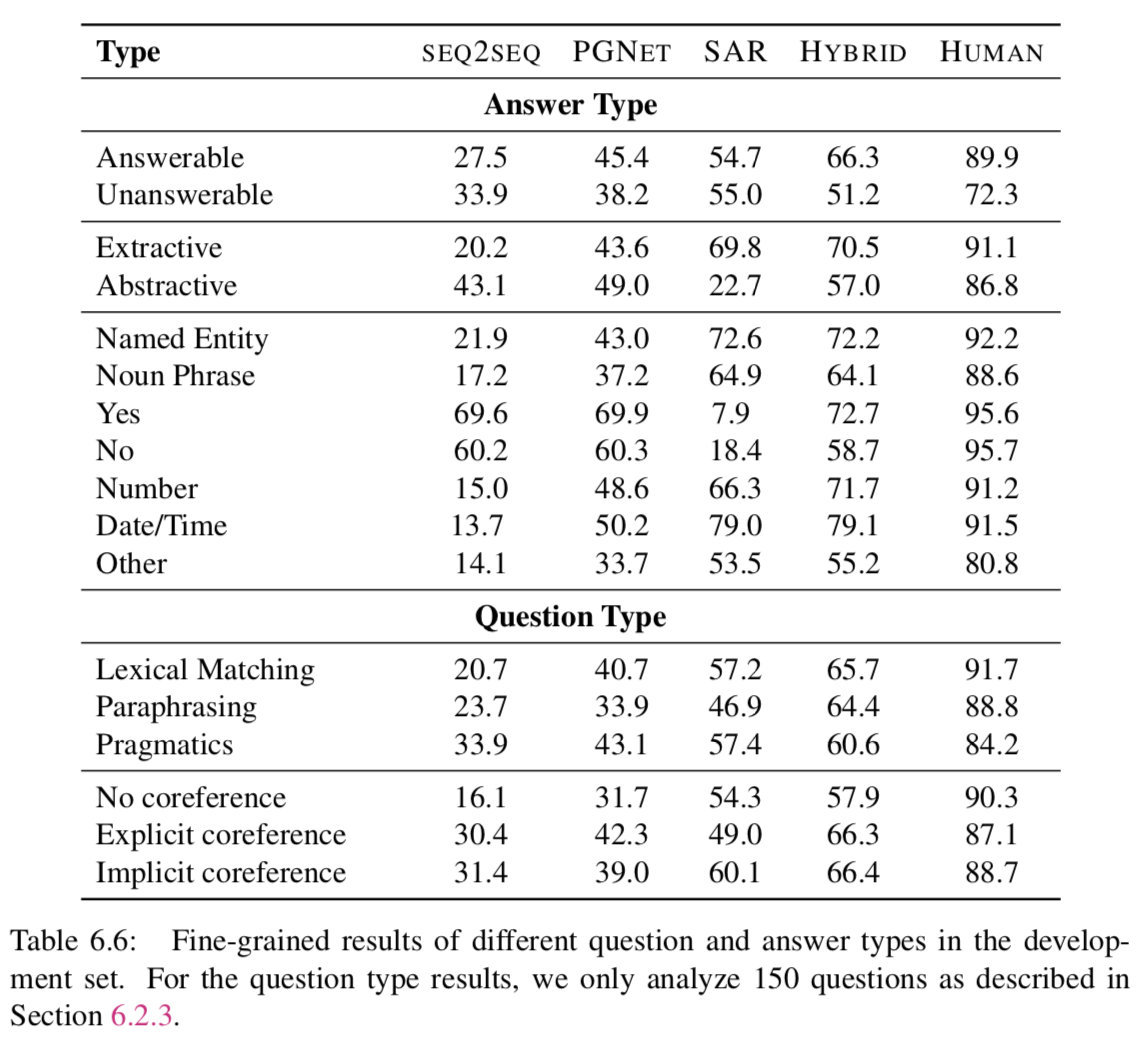 image-20190727233640836
image-20190727233640836
虽然人类在儿童故事方面取得了很高的成绩,但模型的表现却很差,这可能是因为与其他领域相比,该领域的训练例子较少。人类和模型都觉得维基百科很简单。【译者,这就很扯淡了,,,很明显high-level 的读者应该向下兼容,然而在这里模型却不是这样,说明并没有“学会”语言,只是在“模仿”。想象一下,看得懂NLP paper的人,不一定看得懂英语童话故事。似乎也有一定的合理性。。。比如,dog day基本不会出现在学术论文中,虽然NLP的论文确实有可能在分析语言现象,但是小孩子的读本就有可能了】
6.4.3 Error Analysis¶
表6.6给出了开发集中模型和人员的细粒度结果。我们观察到,在无法回答的问题上,人类的分歧最大。有时,即使文章中没有给出答案,人们也会猜测答案,例如,图6.1中Annie的年龄可以根据她祖母的年龄来猜测。人类对抽象答案的认同低于对提取式答案的认同。这是符合预期的,因为我们的评估指标是基于单词重叠而不是单词的含义。例如,Did Jenny like her new room? 人类的答案,she loved it 以及yes都是可以被接受的答案。
为抽象的回答寻找完美的评价指标仍然是一个具有挑战性的问题(Liu et al., 2016),超出了我们的工作范围。对于我们的模型的性能,SEQ2SEQ和PGNET在抽象答案的问题上表现良好,而STANFORD ATTENTIVE READER由于各自的设计,在抽取答案的问题上表现良好。组合模型对这两种类型都进行了改进。
在词法问题类别上,人类发现词汇匹配且伴随着解释的问题是最容易的,而涉及到语用学的问题是最难的——这是符合预期的,因为涉及词汇匹配以及解释的问题和篇章之间有相似性,因为使得回答他们要比语用问题相对简单。最好的模型也遵循同样的趋势。虽然人类发现没有指代性的问题比那些有指代性的问题(显式或隐式)更容易,但是模型的行为是断断续续的。目前还不清楚为什么人类发现隐式引用比显式引用更容易。有一种推测是,隐式引用直接依赖于前一个回合,而显式引用可能对对话有长距离依赖。
Importance of conversation history. 最终,我们检验了数据集中对话历史的重要性。表6.7显示了使用不同数量的先前回合作为会话历史的结果。所有模型都成功地利用了历史,但最多只能利用一个前一回合的历史(PGNET除外)。令人惊讶的是,使用更多的对话回合可能会降低性能。
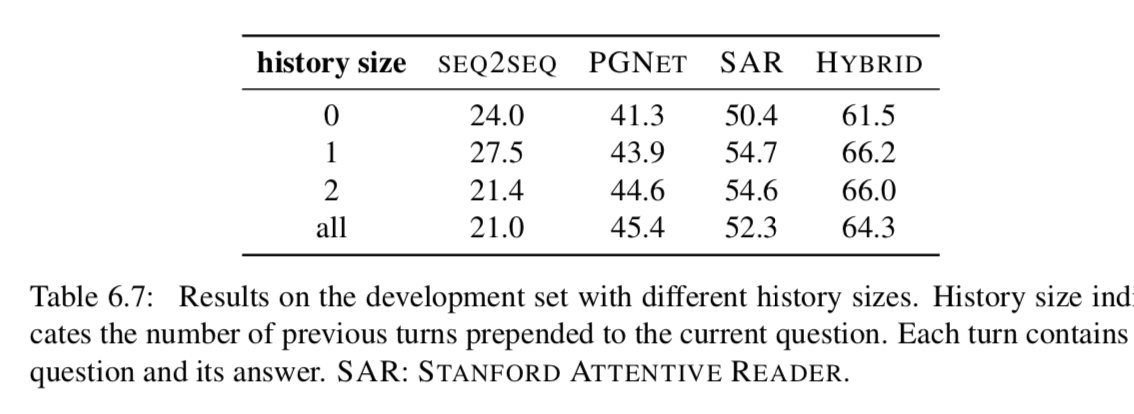 image-20190727233710538
image-20190727233710538
我们还对人类进行了一项实验,以衡量他们的表现和之前显示的轮次之间的平衡。基于短问答可能依赖于会话历史的启发,我们抽取了300个一两个单词的问题作为样本,并收集了这些问题的答案,这些问题的答案与前面显示的不同。
当我们不显示任何历史记录时,人类性能下降到19.9 F1,而完整历史记录显示时为86.4 F1。当显示前一个问题和答案时,他们的性能提升到79.8 F1,说明前一个转弯在理解当前问题上发挥了重要作用。如果显示最后两个问题和答案,则可以达到85.3 F1,几乎接近显示完整历史记录时的性能。这表明,对话中的大多数问题在两个回合内都有有限的依赖性。
6.5 Discussion¶
到目前为止,我们已经讨论了COQA数据集和几个基于会话模型和阅读理解模型的竞争性基线。我们希望我们的努力能够成为构建会话QA代理的第一步。
一方面,我们认为COQA的性能还有很大的提升空间:我们的混合动力系统F1成绩为65.1%,仍然落后于人类的23.7分(88.8%)。我们鼓励我们的研究团队研究这个数据集,并推动会话问题回答模型的极限。我们认为有几个方面需要进一步改进:
- 我们构建的所有基线模型都只使用对话历史,方法很简单,就是将前面的问题和答案与当前的问题连接起来。我们认为应该有更好的方式把历史和当前的问题联系起来。对于表6.4中的问题,我们应该建立模型来真正理解问题中他的名字是什么?指的是小狗,而问题在哪里?意味着西里塞纳将在哪里宣誓就职?事实上,最近的一个模型FLOWQA (Huang et al., 2018a)提出了一种解决方案,可以沿着会话流有效地堆叠单轮模型,并在COQA上展示了最先进的性能。
- 我们的混合模型旨在结合跨度预测阅读理解模型和指针生成网络模型的优点,解决抽象答案的不足。然而,我们将其实现为管道模型,因此第二个组件的性能取决于阅读理解模型能否从文章中提取正确的证据。我们认为构建一个端到端模型是可取的,它可以提取基本原理,同时将基本原理重写为最终的答案。
- 我们认为我们收集的原理可以被在训练模型的时候更好的利用。
另一方面,COQA当然有其局限性,我们应该在未来探索更具挑战性和更有用的数据集。一个明显的限制是,COQA中的转换只是问答对的转换。这意味着回答者只负责回答问题,而她不能问任何澄清问题或通过对话与提问者沟通。另一个问题是COQA很少有(1.3%)无法回答的问题,我们认为这在实际的逆向QA系统中是至关重要的。
在我们的工作之外,Choi等人(2018)还创建了一个文本段落问答形式的对话数据集。在我们的界面中,我们向提问者和回答者都显示了一段话,而他们的界面只显示了提问者的标题和对回答者的完整段落。由于他们的设置鼓励回答者为下面的问题透露更多的信息,他们的答案平均长达15.1个单词(我们的是2.7个)。在我们的测试集中,人类的性能是88.8 F1,而他们的性能是74.6 F1。此外,虽然COQA的答案可以是抽象的,但它们的答案仅限于提取文本范围。我们的数据集包含了来自七个不同领域的文章,而他们的数据集仅来自维基百科上关于人的文章。与此同时,Saeidi等人(2018)还为税收和签证法规等监管文本创建了对话式QA数据集。他们的回答仅限于“是”或“不是”,同时也有一个积极的特点,即当某个问题无法回答时,他们可以提出澄清性的问题。
© Copyright 2019, Junyi Li (original:chendanqi)
Built with Sphinx using a theme provided by Read the Docs.

若有收获,就点个赞吧
0 人点赞
