一、简介
优势: ·支持标准SQL,兼容MySQL协议以及分布式Join。 ·水平扩展,不依赖外部组件,方便缩扩容。 ·支持多种聚合算子,物化视图。 ·MPP架构,分片分桶的复合存储模型。 ·支持高并发查询,QPS可达千、万量级。 ·支持宽表和多表Join查询,数据查询秒级/毫秒级。 ·支持地图GEO函数。 ·运维简单,易用性强。 ·复杂的场景查询。 劣势: ·缺乏单列数据更新能力。 ·周边生态还不是很完善。
三、数据模型
1、明细模型
说明
StarRocks建表默认采用明细模型,排序列使用稀疏索引,可以快速过滤数据。明细模型用于保存所有历史数据,并且用户可以考虑将过滤条件中频繁使用的维度列作为排序键,比如用户经常需要查看某一时间,可以将事件时间和事件类型作为排序键
建模语句
在建表时指定模型和排序键。 DUPLICATE KEY(box_id)
use dwd;CREATE TABLE IF NOT EXISTS detail (event_time DATETIME NOT NULL COMMENT "datetime of event",event_type INT NOT NULL COMMENT "type of event",user_id INT COMMENT "id of user",device_code INT COMMENT "device of ",channel INT COMMENT "")DUPLICATE KEY(event_time, event_type)DISTRIBUTED BY HASH(user_id) BUCKETS 8PROPERTIES ("replication_num"="1");注:副本默认为3,当只有一台机器时,建表会报:need 3。因此这里可以指定副本
2、聚合模型
说明
在数据分析中,很多场景需要基于明细数据进行统计和汇总,这个时候就可以使用聚合模型了。比如:统计app访问流量、用户访问时长、用户访问次数、展示总量、消费统计等等场景。 适合聚合模型来分析的业务场景有以下特点: (1)业务方进行查询为汇总类查询,比如sum、count、max (2)不需要查看原始明细数据 (3)老数据不会被频繁修改,只会追加和新增 (4)一般就是ads指标层进行统计
建模语句
指定聚合模型 pv BIGINT SUM mt BIGINT MAX
CREATE TABLE IF NOT EXISTS aggregate_tbl (site_id LARGEINT NOT NULL COMMENT "id of site",DATE DATE NOT NULL COMMENT "time of event",city_code VARCHAR(20) COMMENT "city_code of user",pv BIGINT SUM DEFAULT "0" COMMENT "total page views",mt BIGINT MAX)DISTRIBUTED BY HASH(site_id) BUCKETS 8;
3、更新模型
说明
(1)已经写入的数据有大量的更新需求 (2)需要进行实时数据分析 (3)适合那种维度变化不快的,比如拉链表场景 (4)采用的是merge策略。无法谓词下推和索引无法使用,使得影响查询性能。
建模语句 ```sql CREATE TABLE IF NOT EXISTS update_detail ( create_time DATE NOT NULL COMMENT “create time of an order”, order_id BIGINT NOT NULL COMMENT “id of an order”, order_state INT COMMENT “state of an order”, total_price BIGINT COMMENT “price of an order” ) UNIQUE KEY(create_time, order_id) DISTRIBUTED BY HASH(order_id) BUCKETS 8
<a name="CMILL"></a>## 4、主键模型- **说明**> (1)更适合频繁更新场景,存储引擎会主键索引建立,对内存要求较高,可更好配合flink进行cdc方案。> (2)冷热数据处理,老数据变化慢,而新数据变化快,只会加载最近几天的索引等场景。> (3)大宽表:对于列很多,但总体数据量不大,比如用户画像表。> (4)通过主键索引找出数据:当于把update改写为delete+insert,区别更新模式的Merge on Read。- **建模语句**```sqlCREATE TABLE users (user_id BIGINT NOT NULL,NAME STRING NOT NULL,email STRING NULL,address STRING NULL,age TINYINT NULL,sex TINYINT NULL) PRIMARY KEY (user_id)DISTRIBUTED BY HASH(user_id) BUCKETS 4
5、排序键(Sort Key)
- 说明
为了加快查询数据:会把表中指定的列进行排序 明细模型:DUPLICATE KEY 指定的列 聚合模型:AGGREGATE KEY 指定的列 更新模型:UNIQUE KEY 指定的列 注意: 1、排序键的数据和建表语句的顺序不能乱,都要按照顺序在前面 2、使用时和mysql索引规则一样,缺少最佳左前缀原则,索引会失效 3、使用排序键本质就是在进行二分查找, 所以排序键最好不超过3个, 字节数不超过36字节, 不包含FLOAT/DOUBLE类型的列; VARCHAR类型列只能出现一次, 并且是末尾位置;
6、物化视图
说明
为了同时满足对固定维度的聚合分析和对原始明细数据任意维度的分析多种场景。
建模语句 ```sql CREATE MATERIALIZED VIEW test_detail_view AS SELECT user_id,MAX(event_type),COUNT(device_code),SUM(channel) FROM detail GROUP BY user_id;
<a name="mVYqC"></a># 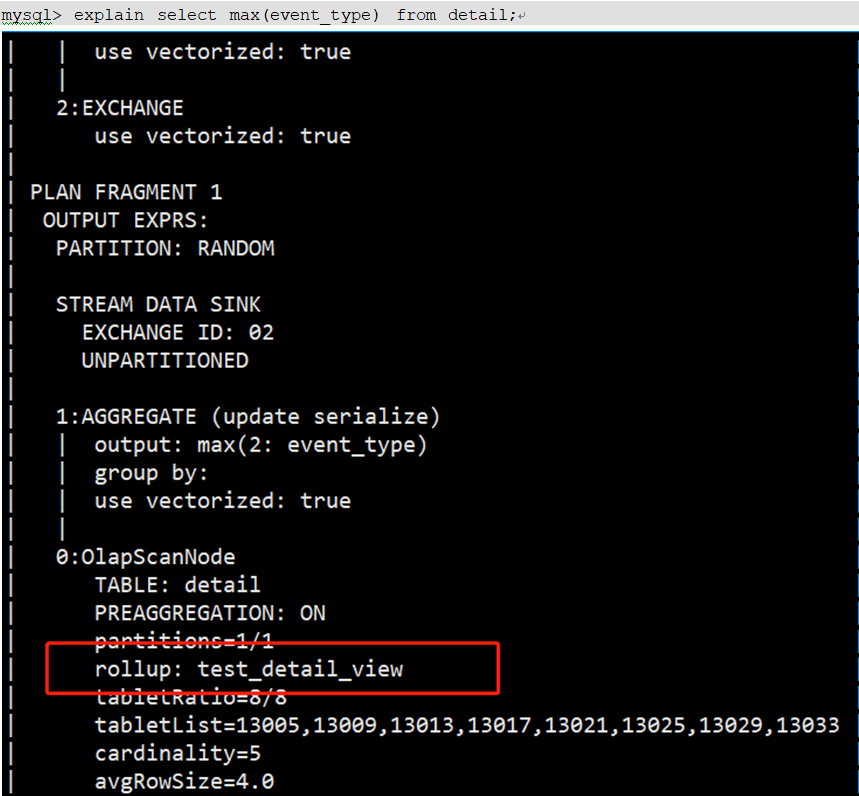- 特点> 那么建立物化视图,就可以帮助用户对于不同场景都起到加速查询的作用。目前物化视图支持的函数如下有:count、max、min、sum、percentile_approx、hill_union、bitmap_union<a name="JAzpS"></a>## 7、Bitmap索引- **原理**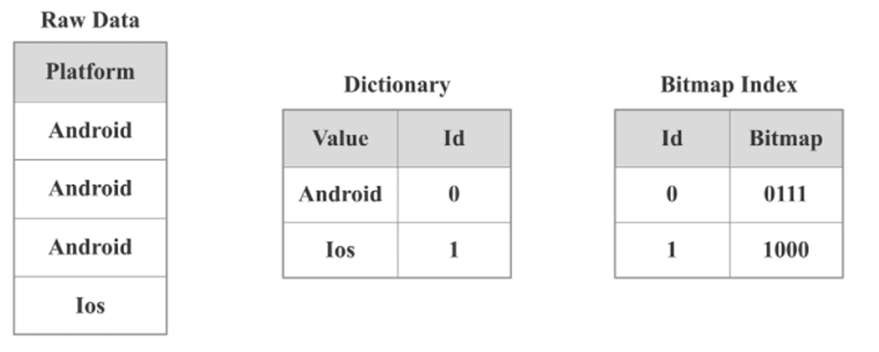> (布隆过滤器)Bitmap是元素为bit的,取值为0、1两种情形的, 可对某一位bit进行置位(set)和清零(clear)。然后将id通过hash算法置到多个bitmap里,如果全为1,则判断为大概率来过(hash碰撞,可降低hash碰撞率),如果有一个为0则肯定没来过。如上图生成一个向量(从左到右)。- **说明**> 使用Bitmap可以大大减少判断过滤时间,提高查询效率> (1)当需要对表数据进行非前置列(排序键)进行过滤时,可以创建bitmap索引加速效率。> (2)对表数据进行多列过滤,也可以考虑对多列分别创建bitmap索引加速效率- **使用方法**```sql(1) 创建测试表CREATE TABLE IF NOT EXISTS user_dup (user_id INT,sex INT ,age INT)DUPLICATE KEY(user_id)DISTRIBUTED BY HASH(user_id) BUCKETS 8(2) 创建bitmapCREATE INDEX user_sex_index ON user_dup(sex) USING bitmap;(3)查看索引SHOW INDEX FROM user_dup;

- 注意
(1)对于明细模型,所有列都可以建Bitmap 索引;对于聚合模型,只有Key列可以建Bitmap 索引 (2)Bitmap索引, 应该在取值为枚举型, 取值大量重复, 较低基数, 并且用作等值条件查询或者可转化为等值条件查询的列上创建. (3)不支持对Float、Double、Decimal 类型的列建Bitmap 索引。 (4)如果要查看某个查询是否命中了Bitmap索引,可以通过查询的Profile信息查看。
8、Bloom Filter 索引
- 说明
Bloom Filter(布隆过滤器)是用于判断某个元素是否在一个集合中的数据结构,优点是空间效率和时间效率都比较高,缺点是有一定的误判率。
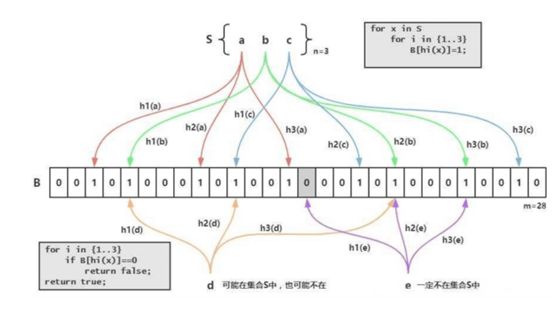
布隆过滤器是由一个Bit数组和n个哈希函数构成。Bit数组初始全部为0,当插入一个元素时,n个Hash函数对元素进行计算, 得到n个slot,然后将Bit数组中n个slot的Bit置1。 当我们要判断一个元素是否在集合中时,还是通过相同的n个Hash函数计算Hash值,如果所有Hash值在布隆过滤器里对应的Bit不全为1,则该元素不存在。当对应Bit全1时, 则元素的存在与否, 无法确定. 这是因为布隆过滤器的位数有限, 由该元素计算出的slot, 恰好全部和其他元素的slot冲突. 所以全1情形, 需要回源查找才能判断元素的存在性。
- Bloom Filter 索引 ```sql CREATE TABLE test_bf( id INT, event_type INT, email INT, sex INT, age INT )DUPLICATE KEY(id) DISTRIBUTED BY HASH(id) BUCKETS 8 PROPERTIES(“bloom_filter_columns”=”event_type,sex”);
<a name="Yit4H"></a># 五、使用技巧<a name="DcerP"></a>## 5.1、外部表<a name="UJrS4"></a>### 5.1.1、mysql外部表> 星型模型中,数据一般划分为维度表和事实表。维度表数据量少,但会涉及 UPDATE 操作。目前 StarRocks 中还不直接支持 UPDATE 操作(可以通过 Unique 数据模型实现),在一些场景下,可以把维度表存储在 MySQL 中,查询时直接读取维度表。```sql#用户表use ods;create external table ods_t_user(id bigint not null comment 'UID',phone varchar(256) not null comment '手机号',password varchar(256) null comment '密码',nickname varchar(256) null comment '昵称',)ENGINE=mysqlPROPERTIES("host" = "192.168.5.135","port" = "3306","user" = "admin","password" = "jeffTH3TZ","database" = "j1_user","table" = "t_user");

若有收获,就点个赞吧
0 人点赞
