一、简介
1、概述
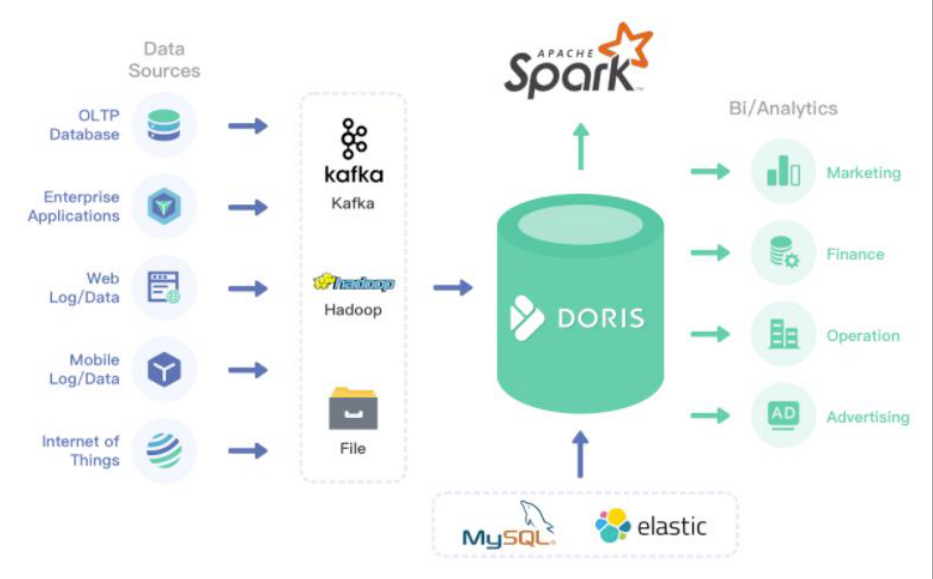
Apache Doris 是一个现代化的 MPP(Massively Parallel Processing,即大规模并行处理) 分析型数据库产品。仅需亚秒级响应时间即可获得查询结果,有效地支持实时数据分析。 Apache Doris 的分布式架构非常简洁,易于运维,并且可以支持 10PB 以上的超大数据集。
核心特性
2、架构
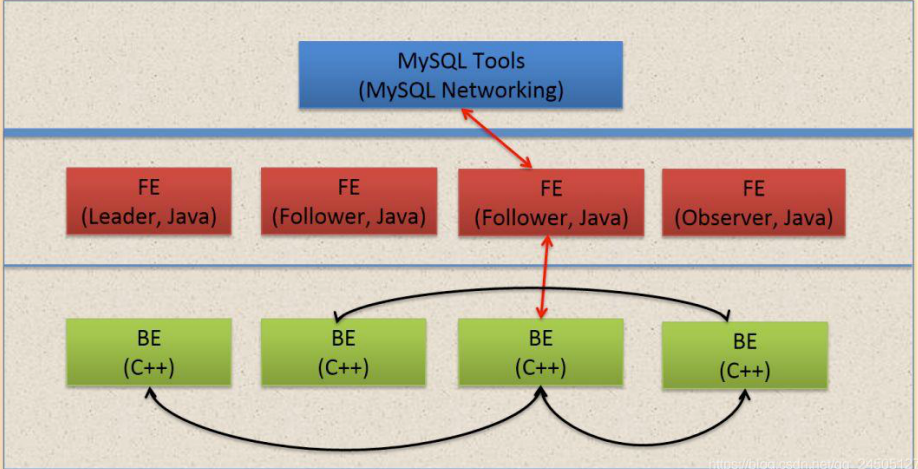
FE(Frontend):存储、维护集群元数据;负责接收、解析查询请求,规划查询计划,
调度查询执行,返回查询结果。主要有三个角色
(1)Leader 和 Follower:主要是用来达到元数据的高可用,保证单节点宕机的情况下, 元数据能够实时地在线恢复,而不影响整个服务。
(2)Observer:用来扩展查询节点,同时起到元数据备份的作用。如果在发现集群压力 非常大的情况下,需要去扩展整个查询的能力,那么可以加 observer 的节点。observer 不 参与任何的写入,只参与读取。
注意:FE的磁盘空间主要用于存储元数据,包括日志和image。通常从几百MB到几个GB 不等。
BE(Backend):负责物理数据的存储和计算;依据 FE 生成的物理计划,分布式地执行查询。
数据的可靠性由 BE 保证,BE 会对整个数据存储多副本或者是三副本。副本数可根据 需求动态调整。
注意:BE的磁盘空间主要用于存放用户数据,总磁盘空间按照用户总数据量*3(3副本)计算,然后再预留额外40%的空间用作后台compaction以及一些中间数据的存放。
MySQL Client
Doris 借助 MySQL 协议,用户使用任意 MySQL 的 ODBC/JDBC 以及 MySQL 的客户 端,都可以直接访问 Doris。 、
Broker
Broker 为一个独立的无状态进程。封装了文件系统接口,提供 Doris 读取远端存储系统 中文件的能力,包括 HDFS,S3,BOS 等。
总结:一台机器上可以部署多个BE实例,但是只能部署一个FE。但是一个副本必须存储在一台机器上。
二、数据存储
1、基本概念
在Doris中,数据都以关系表(Table)的形式进行逻辑上的描述。
1.1、Row & Column
一张表包括Row和Column。Row即用户的一行数据,Colomn用于描述一行数据中的字段。
非聚合模型:Column 只分为排序列和非排序列。存储引擎会按照排序列 对数据进行排序存储,并建立稀疏索引,以便在排序数据上进行快速查找。
聚合模型:Column 可以分为两大类:Key 和 Value。从业务角度看,Key 和 Value 可以分别对应维度列和指标列。从聚合模型的角度来说,Key 列相同的行, 会聚合成一行。其中 Value 列的聚合方式由用户在建表时指定。
1.2、Partition & Tablet
在 Doris 的存储引擎中,用户数据首先被划分成若干个分区(Partition),划分的规则通 常是按照用户指定的分区列进行范围划分,比如按时间划分。而在每个分区内,数据被进一 步的按照 Hash 的方式分桶,分桶的规则是要找用户指定的分桶列的值进行 Hash 后分桶。 每个分桶就是一个数据分片(Tablet),也是数据划分的最小逻辑单元。
- Tablet 之间的数据是没有交集的,独立存储的。Tablet 也是数据移动、复制等操作
的最小物理存储单元。
- Partition 可以视为是逻辑上最小的管理单元。数据的导入与删除,都可以或仅能针
对一个 Partition 进行。
2、建表示例
2.1、语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [database.]table_name(column_definition1[, column_definition2, ...][, index_definition1[, index_definition12,]])[ENGINE = [olap|mysql|broker|hive]][key_desc][COMMENT "table comment"];[partition_desc][distribution_desc][rollup_index][PROPERTIES ("key"="value", ...)][BROKER PROPERTIES ("key"="value", ...)];
1)复合分区:既有分区也有分桶
第一级称为 Partition,即分区。用户可以指定某一维度列作为分区列(当前只支持整型 和时间类型的列),并指定每个分区的取值范围。
第二级称为 Distribution,即分桶。用户可以指定一个或多个维度列以及桶数对数据进 行 HASH 分布。
2)单分区:只做 HASH 分布,即只分桶
2.2、例子
单分区
CREATE TABLE student(id INT,name VARCHAR(50),age INT,count BIGINT SUM DEFAULT '0')AGGREGATE KEY (id,name,age)DISTRIBUTED BY HASH(id) buckets 10PROPERTIES("replication_num" = "1");
Range分区
CREATE TABLE student2(dt DATE,id INT,name VARCHAR(50),age INT,count BIGINT SUM DEFAULT '0')AGGREGATE KEY (dt,id,name,age)PARTITION BY RANGE(dt) 或 partition by range(date, user_id)(PARTITION p202007 VALUES LESS THAN ('2020-08-01'),PARTITION p202008 VALUES LESS THAN ('2020-09-01'),PARTITION p202009 VALUES LESS THAN ('2020-10-01'))DISTRIBUTED BY HASH(id) buckets 10PROPERTIES("replication_num" = "1");
场景
- 有时间维或类似带有有序值的维度,可以以这类维度列作为分区列。分区粒度可以根据导入频次、分区数据量等进行评估。
- 历史数据删除需求:如有删除历史数据的需求(比如仅保留最近N天的数据)。使用复合分区,可以通过删除历史分区来达到目的。也可以通过在指定分区内发送DELETE于禁进行删除。 解决数据倾斜的问题:每个分区可以单独指定分桶数量。如按天分区,当每天的数据量差异很大的时,可以通过指定分区的分桶数,合理规划不同分区的数据,分桶列建议选择区分度大的列
List分区
engine = olapaggregate key(user_id, date, timestamp, city, age, sex)partition by list(city) 或 partition by list(user_id, city)(partition p_cn values in ('Beijing', 'Shanghai', 'Hong Kong'),partition p_usa values in ('New York', 'San Francisco'),partition p_jp values in ('Tokyo'))distributed by hash(user_id) buckets 10properties('replication_num' = '3','storage_medium'='SSD','storage_cooldown_time'='2022-01-01 00:00:00');
3、分桶
分桶列必须为key列,可以为多列 一个Partition的Bucket数量一旦指定,不可更改 分桶列多适用于低并发高吞吐量,因为数据分布在多个桶中,并发查询多个桶,单个查询速度快 分桶列少适用于高并发,因为一个查询可能只命中一个桶,多个查询之间查询不同的桶,磁盘的IO影响小,所以并发就高。 分桶理论上是没有上限的。
4、Partition和Bucket设置
一个表的Tablet数量,推荐略多于整个集群的磁盘数量 单个Tablet的数据量建议在 1G - 10G 的范围内。如果单个Tablet数据量过小,则数据的聚合效果不佳,且元数据管理压力大。如果数据量过大,则不利于副本的迁移、同步,且会增加Schema Change或者Rollup操作失败重试的代价(这些操作失败重试的粒度是Tablet) 当Tablet数量和数据量冲突时,数据量优先。比如一个很小的集群,表的数据量很大,则需要很多Tablet(远多于集群的磁盘数量)
5. 建表语句properties设置
5.1、replication_num
- Tablet副本数量默认为3
- 副本数量可以在运行时修改。强烈建议保持奇数
- 最大副本数取决于物理机的ip数量,而不是BE数量。如一台物理机有2个ip,部署了3个BE,则最大副本数只能是2
- 对于数量小且更新不频繁的维度表,可以设置更多replication_num,提升本地join的概率
5.2、storage_medium & storage_cooldown_time
存储介质和存储热数据时间。
6. ENGINE
默认的表ENGINE是olap,由Doris负责管理。其它表引擎如mysql、es等,Doris只负责元数据映射,不储存数据,以便进行数据读取
7、数据模型
Doris 的数据模型主要分为 3 类:Aggregate、Uniq、Duplicate
7.1、Aggregate 模型
分为 Key(维度列)和 Value(指标列)
- SUM:求和,多行的 Value 进行累加。
- REPLACE:替代,下一批数据中的 Value 会替换之前导入过的行中的 Value。
- REPLACE_IF_NOT_NULL :当遇到 null 值则不更新。
- MAX:保留最大值。
- MIN:保留最小值。
局限性:任何还未聚合(compact)的数据(比如说两个不同导入批次的数据),必须通过某种方式,以保证对外展示的一致性。
7.2、Uniq 模型
Uniq 模型完全可以用聚合模型中的 REPLACE 方式替代。其内部的实现方式和数据存 储方式也完全一样。
7.3、Duplicate 模型
明细数据存储
7.4、数据模型选择
因为数据模型在建表时就已经确定,且无法修改。所以,选择一个合适的数据模型非常
重要。
(1)Aggregate 模型可以通过预聚合,极大地降低聚合查询时所需扫描的数据量和查询 的计算量,非常适合有固定模式的报表类查询场景。但是该模型对 count(*) 查询很不友好。 同时因为固定了 Value 列上的聚合方式,在进行其他类型的聚合查询时,需要考虑语意正确 性。
(2)Uniq 模型针对需要唯一主键约束的场景,可以保证主键唯一性约束。但是无法利 用 ROLLUP 等预聚合带来的查询优势(因为本质是 REPLACE,没有 SUM 这种聚合方式)。
(3)Duplicate 适合任意维度的 Ad-hoc 查询。虽然同样无法利用预聚合的特性,但是不 受聚合模型的约束,可以发挥列存模型的优势(只读取相关列,而不需要读取所有 Key 列)
8、动态分区
旨在对表级别的分区实现生命周期管理 (TTL),减少用户的使用负担。 目前实现了动态添加分区及动态删除分区的功能。动态分区只支持 Range 分区。
8.1、作用
用户会将表按天进行分区划分,每天定时创建和删除相应分区,FE后台启动线程定时执行。
8.2、使用
注意:目前仅支持对单分区列的分区表设定动态分区规则,在建表/运行时指定。
PROPERTIES("dynamic_partition.prop1" = "value1","dynamic_partition.prop2" = "value2",...)
8.3、参数指定
CREATE TABLE `dwd_event_del_moment` (`event_time` datetime NULL COMMENT "事件时间",`mid` varchar(50) NULL COMMENT "帖子id",`user_id` bigint(20) NULL COMMENT "用户id") ENGINE=OLAPUNIQUE KEY(`event_time`, `mid`, `user_id`)COMMENT "删帖事件"PARTITION BY RANGE(`event_time`)(PARTITION p20220508 VALUES [('2022-05-08 00:00:00'), ('2022-05-09 00:00:00')),PARTITION p20220509 VALUES [('2022-05-09 00:00:00'), ('2022-05-10 00:00:00')),PARTITION p20220510 VALUES [('2022-05-10 00:00:00'), ('2022-05-11 00:00:00')),PARTITION p20220511 VALUES [('2022-05-11 00:00:00'), ('2022-05-12 00:00:00')),PARTITION p20220512 VALUES [('2022-05-12 00:00:00'), ('2022-05-13 00:00:00')),PARTITION p20220513 VALUES [('2022-05-13 00:00:00'), ('2022-05-14 00:00:00')),PARTITION p20220514 VALUES [('2022-05-14 00:00:00'), ('2022-05-15 00:00:00')),PARTITION p20220515 VALUES [('2022-05-15 00:00:00'), ('2022-05-16 00:00:00')),PARTITION p20220516 VALUES [('2022-05-16 00:00:00'), ('2022-05-17 00:00:00')),PARTITION p20220517 VALUES [('2022-05-17 00:00:00'), ('2022-05-18 00:00:00')),PARTITION p20220518 VALUES [('2022-05-18 00:00:00'), ('2022-05-19 00:00:00')))DISTRIBUTED BY HASH(`user_id`) BUCKETS 8PROPERTIES ("replication_allocation" = "tag.location.default: 3","dynamic_partition.enable" = "true", -- 开启动态分区"dynamic_partition.time_unit" = "DAY",-- 分区调度单位"dynamic_partition.time_zone" = "Asia/Shanghai",-- 时区"dynamic_partition.start" = "-7", -- 往前推七天,如果未设置,默认最小值,即不删除历史分区"dynamic_partition.end" = "3", -- 往后推两天"dynamic_partition.prefix" = "p", -- 分区前缀"dynamic_partition.replication_allocation" = "tag.location.default: 3","dynamic_partition.buckets" = "8","dynamic_partition.create_history_partition" = "false",-- 历史分区"dynamic_partition.history_partition_num" = "-1", -- 未设置"dynamic_partition.hot_partition_num" = "0","dynamic_partition.reserved_history_periods" = "NULL","in_memory" = "false","storage_format" = "V2");
8.4、示例
分区列 time 类型为 DATE,创建一个动态分区规则。按天分区,只保留最近 7 天的分 区,并且预先创建未来 3 天的分区
CREATE TABLE dw_ht_data.`dws_user_ta_follow_1d` (`event_time` date NULL COMMENT "统计日期",`user_id` bigint(20) NULL COMMENT "用户id",`user_fans_cnt` bigint(20) NULL COMMENT "用户粉丝数,即用户被关注次数") ENGINE=OLAPUNIQUE KEY(`event_time`, `user_id`)COMMENT "按天统计用户粉丝关注数"PARTITION BY RANGE(`event_time`) ()DISTRIBUTED BY HASH(`user_id`) BUCKETS 8PROPERTIES ("replication_allocation" = "tag.location.default: 3","dynamic_partition.enable" = "true","dynamic_partition.time_unit" = "DAY","dynamic_partition.time_zone" = "Asia/Shanghai","dynamic_partition.start" = "-31","dynamic_partition.end" = "3","dynamic_partition.prefix" = "p","dynamic_partition.replication_allocation" = "tag.location.default: 3","dynamic_partition.buckets" = "8","dynamic_partition.create_history_partition" = "true","dynamic_partition.history_partition_num" = "-1","dynamic_partition.hot_partition_num" = "0","dynamic_partition.reserved_history_periods" = "NULL","in_memory" = "false","storage_format" = "V2")
9、Rollup
ROLLUP 在多维分析中是“上卷”的意思,即将数据按某种指定的粒度进行进一步聚 合。
9.1、基本概念
Base表基础上,我们可以创建任意多个 ROLLUP 表。这些 ROLLUP 的数据是基于 Base 表产生的,并且在物理上是独立存储的。获取更粗粒度的聚合数据。
9.2、聚合模型中的ROLLUP
建立好ROLLUP后,在进行查询时,DORIS会自动命中这个ROLLUP表,从而只需要扫描极少的数据量,即可完成这次聚合查询。
9.4、非聚合模型中的ROLLUP
和上面作用不同,这里已经失去了上卷的含义,而仅仅作为调整列顺序,从而命中前缀索引(改变前缀索引)。
9.5、前缀索引(ROLLUP可以调整前缀索引)
与其他数据库不一样,Doris不支持在任意列上创建索引,底层的数据存储,在排序的基础上,实现的一种根据给定前缀列,快速查询数据的索引方式 注意:将一行数据的前 36 个字节 作为这行数据的前缀索引。当遇到 VARCHAR 类型 时,前缀索引会直接截断。
9.6、总结
- ROLLUP 最根本的作用是提高某些查询的查询效率(无论是通过聚合来减少数据 量,还是修改列顺序以匹配前缀索引)。
- ROLLUP 是附属于 Base 表的,可以看做是 Base 表的一种辅助数据结构。用户可以 在 Base 表的基础上,创建或删除 ROLLUP,但是不能在查询中显式的指定查询某 ROLLUP。是否命中 ROLLUP 完全由 Doris 系统自动决定
- ROLLUP 的数据是独立物理存储的。因此,创建的 ROLLUP 越多,占用的磁盘空 间也就越大。同时对导入速度也会有影响(导入的 ETL 阶段会自动产生所有 ROLLUP 的数据),但是不会降低查询效率(只会更好)。
- 查询能否命中 ROLLUP 的一个必要条件(非充分条件)是,查询所涉及的所有列 (包括 select list 和 where 中的查询条件列等)都存在于该 ROLLUP 的列中。否则,查询只能命中 Base 表。
10、物化视图
物化视图就是包含了查询结果的数据库对象,可能是对远程数据的本地 copy,也可能 是一个表或多表 join 后结果的行或列的子集,也可能是聚合后的结果。说白了,就是预先存 储查询结果的一种数据库对象。
10.1、适用场景
- 分析需求覆盖明细数据查询以及固定维度查询两方面。
- 查询仅涉及表中的很小一部分列或行。
- 查询包含一些耗时处理操作,比如:时间很久的聚合操作等。
- 查询需要匹配不同前缀索引。
注意:物化视图只存逻辑不存数据。物化视图是Rollup的一个超集。
三、查询
1、Broadcast Join
系统默认实现Join的方式,是将小表进行条件过滤后,将其广播到大表所在得饿各个节点上,形成一个内存Hash表,然后流失读出大表的数据进行Hash Join。
Doris 会自动尝试进行 Broadcast Join,如果预估小表过大则会自动切换至 Shuffle Join。 注意,如果此时显式指定了 Broadcast Join 也会自动切换至 Shuffle Join。
显式使用
JOIN [broadcast]
2、Shuffle Join(Partitioned Join)
如果当小表过滤后的数据量无法放入内存的话,此时 Join 将无法完成,通常的报错应 该是首先造成内存超限。可以显式指定 Shuffle Join,也被称作 Partitioned Join。即将小表和 大表都按照 Join 的 key 进行 Hash,然后进行分布式的 Join。这个对内存的消耗就会分摊 到集群的所有计算节点上。
显式使用
JOIN [shuffle]
3、 Colocation Join
目的:旨在为Join查询提供本性优化,来减少数据在节点上的传输耗时,加速查询。
原理
Version:0.9 StartHTML:0000000105 EndHTML:0000001800 StartFragment:0000000141 EndFragment:0000001760
Colocation Join 功能,是将一组拥有 CGS 的表组成一个 CG。保证这些表对应的数据分 片会落在同一个 be 节点上,那么使得两表再进行 join 的时候,可以通过本地数据进行直接 join,减少数据在节点之间的网络传输时间。Colocation Group(CG):一个 CG 中会包含一张及以上的 Table。在同一个 Group 内的 Table 有着相同的 Colocation Group Schema,并且有着相同的数据分片分布。
Colocation Group Schema(CGS):用于描述一个 CG 中的 Table,和 Colocation 相关的通用 Schema 信息。包括分桶列类型,分桶数以及副本数等。
说明:一个表的数据,最终会根据分桶列值 Hash、对桶数取模的后落在某一个分桶内。假设 一个 Table 的分桶数为 8,则共有 [0, 1, 2, 3, 4, 5, 6, 7] 8 个分桶(Bucket),我们称这样一 个序列为一个 BucketsSequence。每个 Bucket 内会有一个或多个数据分片(Tablet)。当表 为单分区表时,一个 Bucket 内仅有一个 Tablet。如果是多分区表,则会有多个。
注意:
- 分桶列的类型和数量需要完全一致,并且桶数一致。
- 所有分区(Partition)的副本数必须一致。
DISTRIBUTED BY HASH(`k2`) BUCKETS 8PROPERTIES ("colocate_with" = "group1");
四、数据导入
1、Stream load
```sql 用户也可以通过其他 HTTP client 进行操作。
curl —location-trusted -u user:passwd [-H “”…] -T data.file -XPUT http://fe_host:http_port/api/{db}/{table}/_stream_load
Header 中支持属性见下面的 ‘导入任务参数’ 说明
格式为: -H “key1:value1”
实例:详细解释见官网```sqlcurl --location-trusted -u dw_rw -H "columns: id,jid,cn" -H "column_separator:," -T total_appstart_count.csv http://10.10.2.229:8030/api/test/ext_total_appstart_count/_stream_load
doris常用操作
DDL
1、外部表
CREATE EXTERNAL TABLE test.`external_ads_user_area_tag` (`user_id` bigint(20) NOT NULL COMMENT '用户id',`user_tag` int(11) NOT NULL COMMENT '地区码(1:中国大陆,2:中国香港台湾,3:外国(除中国大陆港台外的其他国家))',`update_time` datetime DEFAULT NULL COMMENT '更新时间') ENGINE=ODBCCOMMENT "ODBC"PROPERTIES ("host" = "10.10.2.58","port" = "3306","user" = "dw_rw_lang_partner","password" = "zu1lf5qB7LIkzP+","driver" = "MySQL","odbc_type" = "mysql","database" = "ads_im_public","table" = "ads_user_area_tag");
DML
1、增加列
ALTER TABLE ods_ht_data.user_offline_labels_1dADD COLUMN chat_cnt_30d BIGINT REPLACE_IF_NOT_NULLCOMMENT "30d内单聊数";ALTER TABLE ods_ht_data.user_offline_labels_1dADD COLUMN send_num_30d BIGINT REPLACE_IF_NOT_NULLCOMMENT "30d内发送消息量";ALTER TABLE ods_ht_data.user_offline_labels_1dADD COLUMN post_moment_num_30d BIGINT REPLACE_IF_NOT_NULLCOMMENT "30d内发帖数";
2、删除列
ALTER TABLE ods_ht_data.user_offline_labels_30minDROP COLUMN chat_cnt_30d ;ALTER TABLE ods_ht_data.user_offline_labels_30minDROP COLUMN send_num_30d ;ALTER TABLE ods_ht_data.user_offline_labels_30minDROP COLUMN post_moment_num_30d ;
3、修改动态分区属性
ALTER TABLE dw_ht_data.dwd_ta_entertargetprofilepage SET("dynamic_partition.start" = "-31");

若有收获,就点个赞吧
0 人点赞
