一 Kudu概述
1 定义
Kudu 是一个针对 Apache Hadoop 平台而开发的列式存储管理器。
2 基础架构
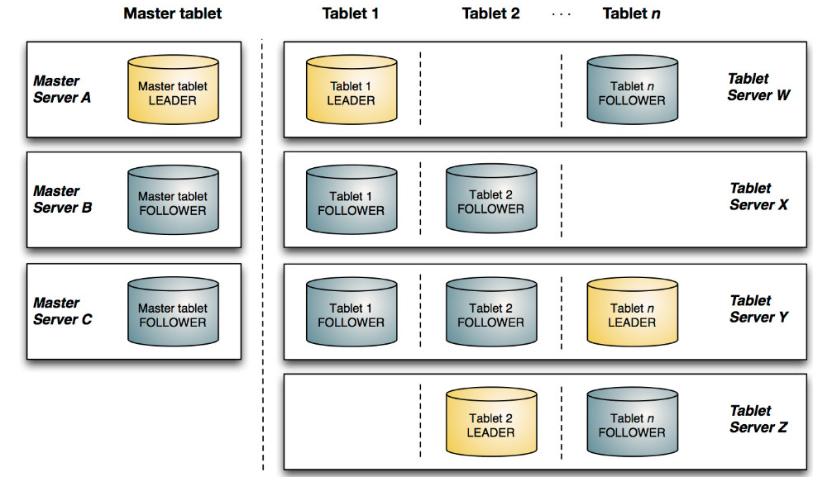
Kudu也采用了Master-Slave形式的中心节点架构,管理节点被称作Kudu Master,数据节点被称作Tablet Server(可对比理解HBase中的RegionServer角色)。一个表的数据,被分割成1个或多个Tablet,Tablet被部署在Tablet Server来提供数据读写服务。 Kudu Master在Kudu集群中,发挥如下的一些作用:
- 用来存放一些表的Schema信息,且负责处理建表等请求。
- 跟踪管理集群中的所有的Tablet Server,并且在Tablet Server异常之后协调数据的重部署。
存放Tablet到Tablet Server的部署信息。
Tablet与HBase中的Region大致相似,但存在如下一些明显的区别点: Tablet包含两种分区策略:
一种是基于Hash Partition方式,在这种分区方式下用户数据可较均匀的分布在各个Tablet中,但原来的数据排序特点已被打乱。
- 另外一种是基于Range Partition方式,数据将按照用户数据指定的有序的Primary Key Columns的组合String的顺序进行分区。而HBase中仅仅提供了一种按用户数据RowKey的Range Partition方式。
二 使用案例
1 创建表
从 Impala 在 Kudu 中创建一个新表类似于将现有的 Kudu 表映射到 Impala 表,但需要自己指定模式和分区信息。 在 CREATE TABLE 语句中,必须首先列出构成主键的列。此外,主键列隐式标记为 NOT NULL 。 创建新的 Kudu 表时,需要指定一个分配方案。
CREATE TABLE kudu_table(id INT,name STRING,PRIMARY KEY(id))PARTITION BY HASH PARTITIONS 16STORED AS KUDU;
注意:主键必须放在第一个,也可指定联合主键,但是不能为null且顺序不能乱。
2 Impala 连接 Kudu
通过 Kudu API 或其他集成(如 Apache Spark )创建的表不会在 Impala 中自动显示。要查询它们,必须先在 Impala 中创建外部表以将 Kudu 表映射到 Impala 数据库中:
CREATE EXTERNAL TABLE my_mapping_tableSTORED AS KUDUTBLPROPERTIES ('kudu.table_name' = 'kudu中的tableName');
3 查询其他表来创表
使用 CREATE TABLE … AS SELECT 语句查询 Impala 中的任何其他表或来创建表。 以下示例将现有表 old_table 中的所有行导入到 Kudu 表 new_table 中。 new_table 中的列的名称和类型将根据 SELECT 语句的结果集中的列确定。
注意,必须另外指定主键和分区。
CREATE TABLE new_tablePRIMARY KEY (id)PARTITION BY HASH(id) PARTITIONS 8STORED AS KUDUAS SELECT id, name FROM old_table;
4 Kudu表的在Impala创建注意
创建 Kudu 表时不支持以下 Impala 关键字:
- PARTITIONED
- LOCATION
- ROW FORMAT
5 将数据插入 Kudu 表
Impala 允许使用 SQL 语句将数据插入 Kudu表 。 插入单个值: INSERT INTO table_name VALUES (1001, “zhangsan”); 插入多个值: INSERT INTO table_name VALUES (1002, “lisi”), (3, “wangwu”); 插入其他表的值: INSERT INTO table_name select * from other_table;
注意:kudu表的update操作不能更改主键的值,其他与标准SQL语法相同。

若有收获,就点个赞吧
0 人点赞
