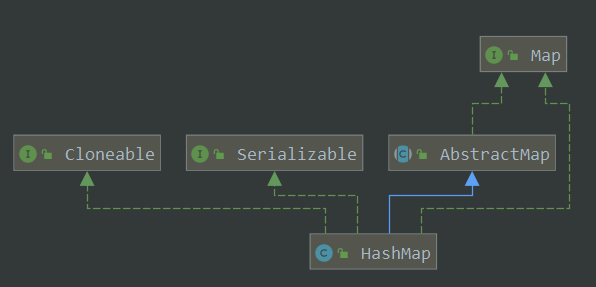
概述 HashMap是Java的一个基于哈希表实现的用于映射(键值对)处理的数据类型 。在Java中它用链表数组实现了哈希表,并且在JDK1.8引入了红黑树的数据结构作了优化。
原理
HashMap是基于哈希表实现的哈希映射。哈希表(Hash Table)的原理就是把关键字(key),通过一个散列函数,又叫哈希函数,获得一个散列码,再根据这个散列码对数据长度取余,将结果当作数组下标,然后将value存储到对应的位置下。当获取值的时候,同样通过key处理得到数组下标,直接去到该下标处获取对应的value值。
当发生哈希碰撞,即是不同的key通过处理得到相同的下标时,由于Java里是用链表数组实现的哈希表,每个列表被称为一个桶,因此在发生哈希碰撞时,通过计算出来的值找到对应的桶,再向这个桶里,即链表后加上该value值。
在JDK1.8开始,HashMap引入了红黑树,在每个桶的容量达到8,即链表长度达到8时,会将该链表转换为另一种数据结构来存储数据——红黑树。
属性
//默认初始容量static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;//最大容量 2^30static final int MAXIMUM_CAPACITY = 1 << 30;//默认负载因子static final float DEFAULT_LOAD_FACTOR = 0.75f;static final int TREEIFY_THRESHOLD = 8;static final int UNTREEIFY_THRESHOLD = 6;static final int MIN_TREEIFY_CAPACITY = 64;//阈值,等于capacity * loadFactory,决定了HashMap能够放进去的数据量int threshold;//负载因子 默认值为0.75,它决定了bucket填充程度;final float loadFactor;//结点表transient Node<K,V>[] table;//Entry集transient Set<Map.Entry<K,V>> entrySet;//表大小transient int size;
结点
//结点static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;V value;Node<K,V> next;Node(int hash, K key, V value, Node<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}}//红黑树节点static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {TreeNode<K,V> parent; // red-black tree linksTreeNode<K,V> left;TreeNode<K,V> right;TreeNode<K,V> prev; // needed to unlink next upon deletionboolean red;TreeNode(int hash, K key, V val, Node<K,V> next) {super(hash, key, val, next);}}
哈希函数
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}public native int hashCode();
在HashMap里的hash函数,是通过关键字key,调用本地native方法hashCode()获取哈希码,再对自己右移16位的值进行或运算所得到的。
构造器
/***构造一个指定初始容量和加载因子的HashMap*@param initialCapacity 初始容量*@param loadFactor 加载因子*/public HashMap(int initialCapacity, float loadFactor) {//如果传入初始容量不合法,抛异常if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);//如果传入初始容量大于最大容量,则取最大容量if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;//判断负载因子是否非法,抛异常if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " +loadFactor);//保存加载因子this.loadFactor = loadFactor;//计算初始容量的最小二次幂this.threshold = tableSizeFor(initialCapacity);}public HashMap(int initialCapacity) {this(initialCapacity, DEFAULT_LOAD_FACTOR);}public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted}/***构造一个HashMap,将Map里的元素添加进去*/public HashMap(Map<? extends K, ? extends V> m) {this.loadFactor = DEFAULT_LOAD_FACTOR;putMapEntries(m, false);}
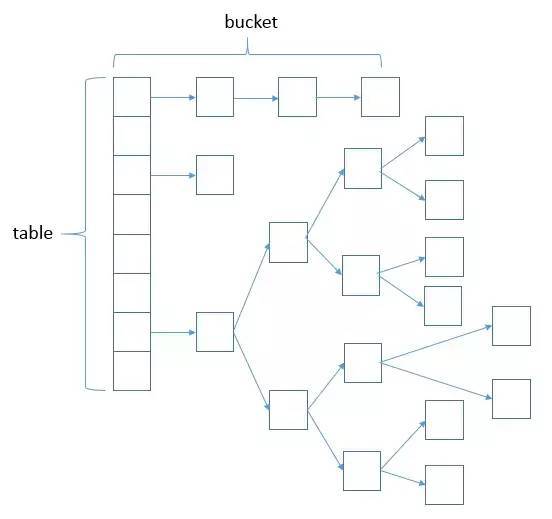
对于HashMap来说,它的容量capacity都是2的幂,但是方法传入的值却未必是2的幂,因此,在构造器里有这么一个方法 tableSizeFor,它用一个算法实现了求capacity的最小二次幂。
/***求大于或等于cap的最小二次幂*/static final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;}
对于n为0时
对这个方法进行分析,如果n为0,在执行 int n = cap - 1; 后,再经过下面的无符号右移,最终n还是为0。此时经过return语句,返回的是 n+1,最终还是1,没有变化。
对于n不为0时
我们假设cap为10,二进制数是 0000 1010,n为 0000 1001,经过 n |= n >>> 1; 无符号右移一位,即将最高位的1右移一位,然后和原数作或运算,会使得最高位右边一位的数也为1,即0000 1100.
接下来继续 n |= n >>> 2; 右移两位,再进行或运算,会使得最高两位右边两位也为1,即0000 1111.
以此类推,重复此操作,对于该例子后面的操作对原数其实已无影响,最终一直都是0000 1111。
最终返回 n+1,即0001 0000,得所求最小二次幂。
因此这个算法的逻辑就是对原数通过二进制的这种运算,把它第一个1位之后的位数全部变为1,再+1求得原数的最小二次幂。操作做到右移16位的目的,使得该数最高支持32位。(但需要注意的是,这时已经是负数了,但是在调用这个方法之前已经进行了判断,如果capacity大于MAXIMUM_CAPACITY(2^30),就为MAXIMUM_CAPACITY,因此在操作完后最多30个1,即2^30)。
为什么要-1
这个方法的第一句是将cap-1,其目的是为了让原本就是二次幂的数变成不是二次幂。如果cap原本就是二次幂,在做完这些操作之后会得到该数的两倍,这不是我们想要的结果。
/***向HashMap里插入Map里全部元素*/final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {int s = m.size();//不是空mapif (s > 0) {//如果是空表if (table == null) { // pre-size//根据元素个数计算需要容量//在HashMap里的机制是达到阈值使便进行扩容,因此需要通过这步计算//算出在哪个容量下刚好达到阈值,再进行加一确保现有元素大小小于阈值,无需扩容float ft = ((float)s / loadFactor) + 1.0F;//判断所需容量是否大于最大容量,是则取最大容量int t = ((ft < (float)MAXIMUM_CAPACITY) ?(int)ft : MAXIMUM_CAPACITY);//如果预估所需容量大于现有容量,则根据预估容量计算最小二次幂if (t > threshold)threshold = tableSizeFor(t);}//如果所需容量大于现有容量,则需要扩容else if (s > threshold)resize();//循环填入元素for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {K key = e.getKey();V value = e.getValue();putVal(hash(key), key, value, false, evict);}}}
添加元素
/***添加键值对key-value*/public V put(K key, V value) {return putVal(hash(key), key, value, false, true);}/***将map里全部元素添加进去*/public void putAll(Map<? extends K, ? extends V> m) {putMapEntries(m, true);}/***final方法,添加值方法* onlyIfAbsent 是标志是否不对相同key的value进行覆盖,为真则不覆盖* 若 evict为true,代表是在创建hashMap后才调用这个函数,例如putAll函数*若 evict为false代表是在创建HashMap时调用这个函数,例如参数为Map的构造方法*/final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {//结点数组,结点Node<K,V>[] tab; Node<K,V> p; int n, i;//保存当前的哈希表(链表数组),如果为null,或空表,则进行扩容if ((tab = table) == null || (n = tab.length) == 0)//保存扩容后的数组大小 (==0)n = (tab = resize()).length;//i 保存数组length-1与hash值 作与运算后的值,如果数组内该下标内无已存结点,则填入结点if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {//否则,该下标内已有结点Node<K,V> e; K k;//如果待插入结点和已有结点 哈希值相同,且值相同或引用同一个对象,保存该结点if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;//否则,判断该结点是否是一个树节点(红黑树),如果是,则,添加到红黑树中else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);//否则,是普通结点,值不同else {//循环遍历该结点链表for (int binCount = 0; ; ++binCount) {//如果后继结点为空,按照链表方式连接上去if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);//如果该链表长度达到阈值,则不能再用链表存储,转为红黑树if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}//如果遍历链表时发现待插入结点和已有结点哈希值相同且值相同或引用同一对象,则循环结束if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}//如果e不为null,即该key在数组里有对应的位置,写入if (e != null) { // existing mapping for key//保存旧valueV oldValue = e.value;//如果旧value为null,则填入if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;//size+1,如果大于阈值,扩容if (++size > threshold)resize();afterNodeInsertion(evict);return null;}
获取元素
/***根据key值找value值*/public V get(Object key) {Node<K,V> e;return (e = getNode(hash(key), key)) == null ? null : e.value;}/***根据hash和key找结点*/final Node<K,V> getNode(int hash, Object key) {Node<K,V>[] tab; Node<K,V> first, e; int n; K k;//如果表不为空,且定位到的桶不为空if ((tab = table) != null && (n = tab.length) > 0 &&(first = tab[(n - 1) & hash]) != null) {//如果列表头结点的哈希值符合且 key值相同,则返回头结点if (first.hash == hash && // always check first node((k = first.key) == key || (key != null && key.equals(k))))return first;//如果下一个结点不为null,即该桶为链表if ((e = first.next) != null) {//判断该桶是否转换为红黑树,如果是,调用getTreeNode()方法if (first instanceof TreeNode)return ((TreeNode<K,V>)first).getTreeNode(hash, key);//否则,遍历链表do {//如果某结点hash符合且key相同,则返回该结点if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;} while ((e = e.next) != null);}}return null;}
扩容机制
/***扩容方法*/final Node<K,V>[] resize() {//保存旧哈希表Node<K,V>[] oldTab = table;//保存旧容量int oldCap = (oldTab == null) ? 0 : oldTab.length;//保存旧阈值int oldThr = threshold;int newCap, newThr = 0;//如果旧容量大于0if (oldCap > 0) {//且大于或等于最大容量,则将Integer最大值作为阈值//如果旧容量已经超过规定的最大容量,那么旧把阈值设置为Integer的最大值,防止溢出?if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;//返回旧表return oldTab;}//如果旧容量*2小于最大容量且旧容量 大于默认初始容量(16)//即正常情况下,扩容直接将容量扩大一倍,对应阈值也扩大一倍else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)//新阈值为旧阈值*2newThr = oldThr << 1; // double threshold}//如果旧阈值大于0,将旧阈值作为新容量//该情况下是旧容量为0,直接将旧的阈值作为容量else if (oldThr > 0) // initial capacity was placed in thresholdnewCap = oldThr;//旧容量小于等于0,旧阈值也小于等于0,即还未初始化的情况,还是空表else { // zero initial threshold signifies using defaults//新容量为默认容量 16,新阈值为0.75*16newCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}//如果新阈值为0,计算newCap * loadFactor为新阈值if (newThr == 0) {float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}//记录新阈值threshold = newThr;//建新表,保存新表@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab;//如果旧表不是nullif (oldTab != null) {//循环保存旧表数据到新表里for (int j = 0; j < oldCap; ++j) {Node<K,V> e;if ((e = oldTab[j]) != null) {oldTab[j] = null;if (e.next == null)//该情况下桶只有一个结点,不成链表,直接复制newTab[e.hash & (newCap - 1)] = e;//如果该桶是红黑树,调用split()方法来复制元素else if (e instanceof TreeNode)((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else { // preserve order//为链表的情况Node<K,V> loHead = null, loTail = null;Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;do {next = e.next;//原索引if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}//原索引+oldCapelse {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);//原索引放入桶里if (loTail != null) {loTail.next = null;newTab[j] = loHead;}//原索引+oldCap放入桶里if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;}
在上面的扩容机制中,对于后面移动元素时,在JDK1.8之前的做法是根据新容量和结点的hash重新计算获得新的数组下标,再填入新表对应位置。但在JDK1.8的设计是通过一个方法得到新的下标值,而不用重新计算。
通过例子来看,假如我们的容量由16扩容为32(因为HashMap的扩容是扩容至原容量的两倍)
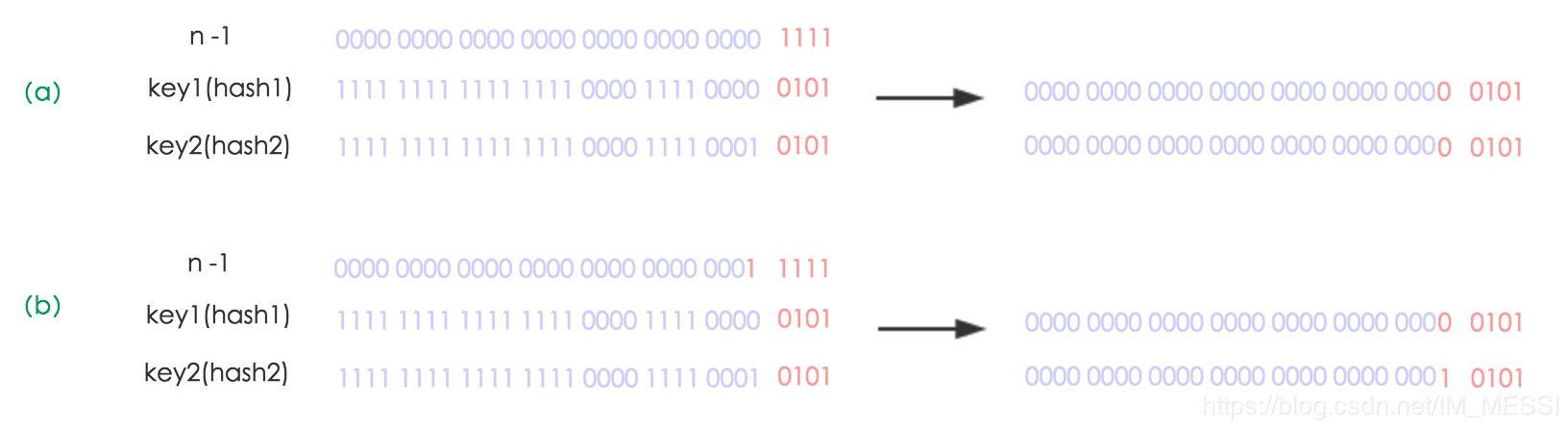
原容量下(n==16) n-1==1111计算出来的数组索引值与 扩容后的容量(n==32) n-1==11111计算出来的数组索引值,从二进制数我们可以看到新旧的区别就是 容量新增位的1对key值对应位进行与运算后,造成的影响要么是0要么是1。如果是0即数组索引不变,如果是1即数组索引比原索引多了二次幂那么大,而这新的索引就是 原索引+oldCap。
因此,我们在扩充HashMap的时候,新的索引只有两种情况,要么就是原索引,要么就是“原索引+oldCap”,所以我们不需要重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”。可以看看下图为16扩充为32的resize示意图:
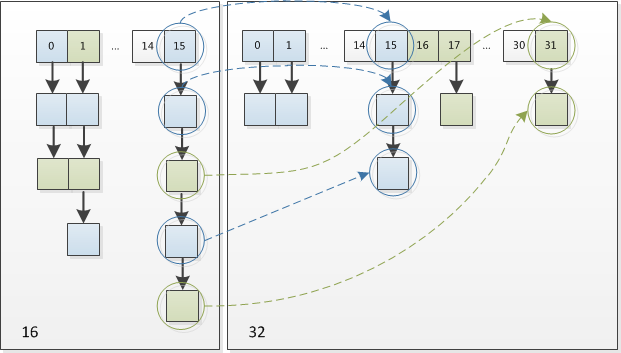
并且,由于新增那位是0还是1可以认为是随机的,所以在扩容后,重新填入元素时,将会均匀地把原冲突的结点分散到新的桶里了,这也是JDK1.8的优化点。
有一点注意区别,JDK1.7中rehash的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置,因为他采用的是头插法,先拿出旧链表头元素。但是从上图可以看出,JDK1.8不会倒置,采用的尾插法。
删除元素
/**
*根据关键字删除结点
*/
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
/**
*删除结点方法
*/
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
//表不为空,且key值对应索引位置不为null
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
//在头结点找到对应的元素,保存结点
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
//否则遍历下一个结点
else if ((e = p.next) != null) {
//判断是否是红黑树,是调用getTreeNode()
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
//不是,循环遍历链表找结点
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
//如果找到匹配的结点
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
//如果是红黑树,调用removeTreeNode()
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
//不是就直接按链表方法删除
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
几个问题
为什么容量必须要是二次幂大小?
这需要考虑到 HashMap 在通过哈希值计算索引下标的做法,是通过 (n - 1) & hash 来计算的,而当 n 为二次幂时,这个计算公式和通过哈希值对数组大小取模得到的结果是一样的。但是为什么这样做的,
第一个好处是 & 运算是位运算,速度比 % 取模运算快;
第二个好处是能保证索引值肯定是在容量内的,不会超出数组长度;
第三个好处体现在扩容机制上,因为容量一直保证是2次幂,因此在扩容后,同样是上面那个索引值计算公式,扩容后的元素下标只会有两种情况,一个是原下标不变,一个是原下标 + 旧容量大小。造成这个不同是因为扩容之后的 n - 1 相当于在前面多一个位变成 1 ,与运算之后的下标结果只会是最高位还是 0 或者变成了 1。这样可以避免在1.8之前根据新容量和结点的hash重新计算获得新的数组下标,再填入新表对应位置的复杂操作,而且可以使得添加的元素均匀分布在HashMap中的数组上,减少hash碰撞。
&运算速度快,至少比 % 取模运算块 能保证 索引值 肯定在 capacity 中,不会超出数组长度 (n - 1) & hash,当n为2次幂时,会满足一个公式:(n - 1) & hash = hash % n

若有收获,就点个赞吧
0 人点赞
