Mycat2与其他数据库不同之处是率先业界实现了开源版本的基于calcite实现的以SQL为后端目标语言的查询引擎,从2020年1月左右发布第一版开始,经历一年的改进,积累了不少经验.它在使用过程中可能出现一些慢SQL.这些SQL可能本身就对分布式查询没有很好的相性.这种情况可能需要更改SQL暂时解决问题,后续的版本会提供Hint或者自定义执行计划的方式多种方式处理这些问题.
要对SQL调优,首先要了解Mycat2对SQL的分析流程有了解
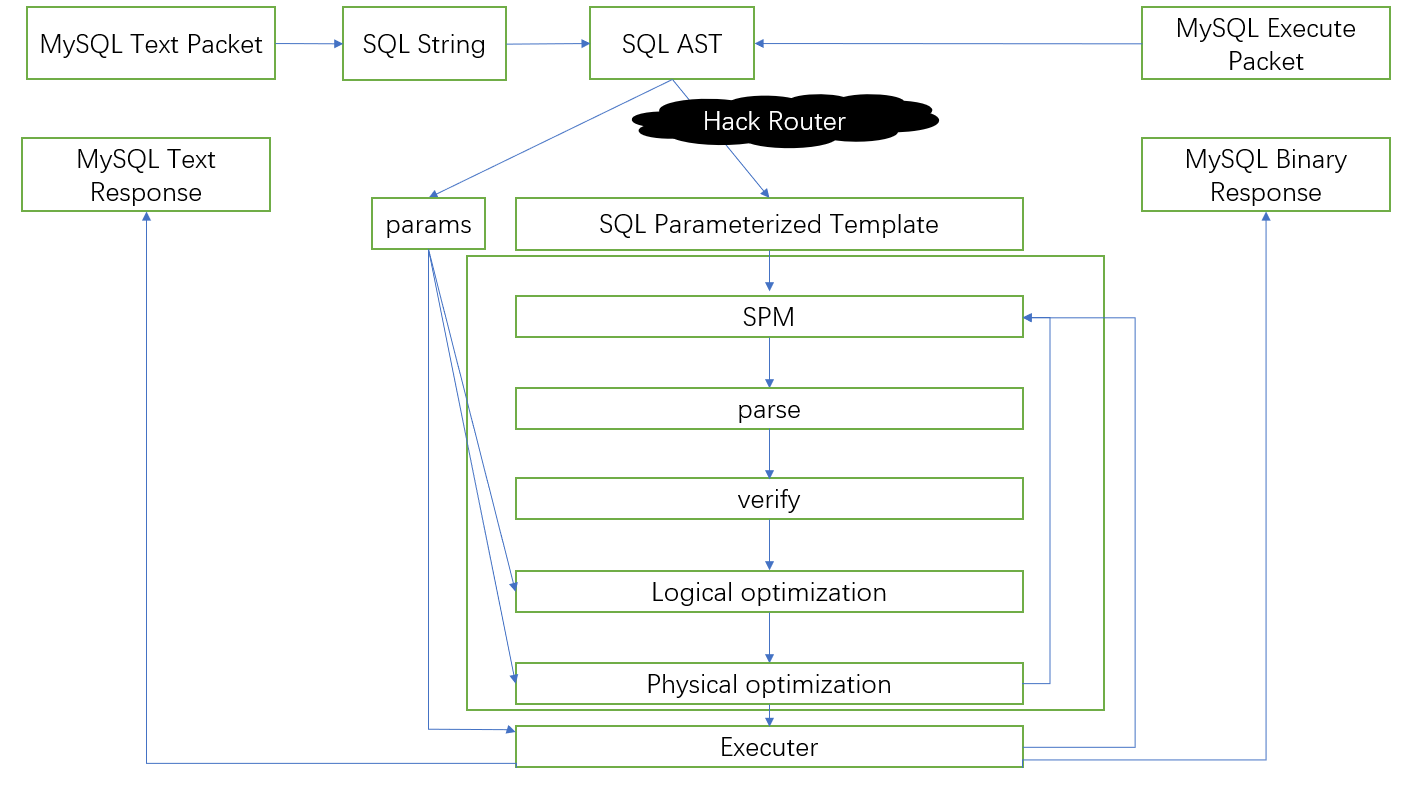
Mycat2服务器在收到SQL文本或者预处理模板与相应参数,都会被转成语法树对象,一般情况下,会经过HackRouter进行一些约束检查,
HackRouter
是一个基于规则的路由器,它针对SQL中的一些特定语法特征,进行瞬速的SQL匹配路由.严格意义上,它不是查询引擎,是路由.如果它不能处理的情况,将会交给后续的定制Calcite查询引擎进行处理.一般来说,它处理读写分离SQL,单表SQL,一般不涉及跨节点合拼的SQL.
Mycat Calcite查询引擎
Mycat Calcite查询引擎是基于Apache Calcite针对MySQL语法语义定制的查询引擎,具备标准的SQL语义,能处理标准SQL,优化并生成执行计划.它不依赖HackRouter也能处理读写分离SQL.原生支持各种join各种子查询.Mycat对它进行深入定制,使其支持能对分库分表SQL进行分析优化,最终生成分布式执行计划.
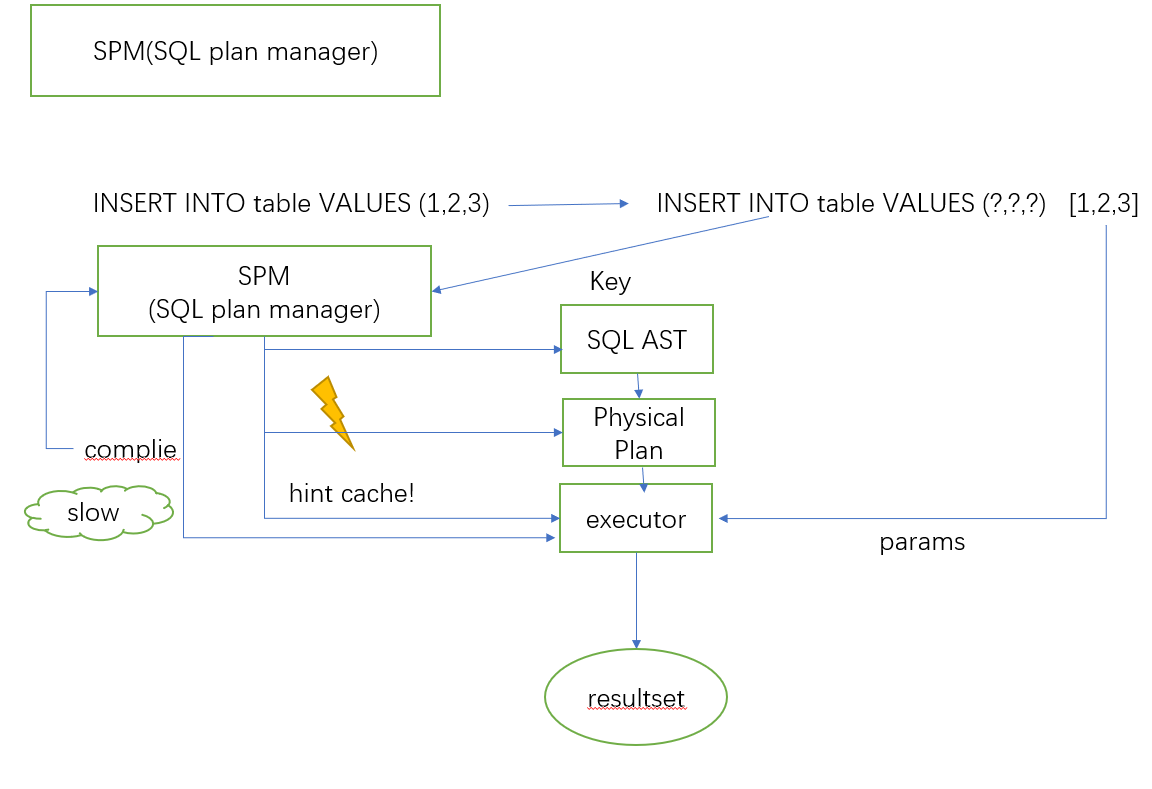
因为Calcite的SQL分析步骤比较繁琐,所以Mycat2引入了SPM,对生成的执行计划进行缓存管理.具体流程如下:
SQL语法树对象通过参数化分析生成两部分,参数化SQL模板和常量值数组.
select 1 => select ? + [1]<br /> select 2 => select ? + [2]
select ? => fun(args[])-> args[0]
参数化SQL模板通常直接对应物理执行器,对物理执行器输入常量值数组,执行器就可以执行,输出结果集.对于相同的参数化SQL模板对应相同的执行器.通过应用不同的常量数组,就可以得到不同的结果集.这样就大大减少相同SQL语法的SQL的分析时间.
而对参数化SQL模板进行分析生成物理执行器的过程是比较耗时的,具体流程是:
1.把MySQL语法树转成标准SQL语法树.把MySQL语法树中存在特殊语法元素以标准SQL的语法表达,便于后续SQL编译器编译.
2.标准SQL语法树通过SQL编译器把SQL语法树编译成逻辑关系表达式.
3.规则优化器把逻辑关系表达式进行一些规则优化得到新的逻辑关系表达式,比如解子查询,下推谓词,常量折叠等.这些规则是实现语义的等价转换,这些转换一般带有明确的转换方向.
4.使用Mycat SQL重写器对逻辑关系表达式引入View节点,View节点用于区分Mycat运算部分的关系表达式与MySql运算部分的关系表达式
5.使用代价优化器把上一步输出的关系表达式应用物理优化规则完全转换为物理关系表达式
6.物理关系表达式使用代码生成器生成执行代码并编译成执行器工厂
执行SQL的时候根据参数化SQL模板获得执行器工厂,为每个会话生成执行器,然后执行器应用常量值数组,就可以输出结果集.
Calcite在Mycat2中仅仅充当SQL编译器与优化器作用.Mycat数据库是计算与计算节点和存储节点组合架构,存储节点一般要承担少量的计算任务,这种计算任务是以SQL语法元素传递表达的.Mycat的优化器(不只是calcite)有自己内置的策略分配Mycat的计算任务与存储节点的计算任务,尽可能在节省机器情况下,针对广泛使用的场景提供最好的性能.
Mycat2的执行器
Mycat2的执行器以三种技术结合制作而成,
1.linq4j的接口作为火山模型执行器
2.RxJava的接口作为Push模型执行器,该接口原生支持并行,并发,异步语义
3.使用动态代码生成编译执行器
混合编译
Mycat2的代码生成器会根据每个关系表达式的一些约束,尽可能的在数据源节点使用Push模型执行器进行生成,当判断不满足Push模型的语义或者不支持Push模型的执行器的时候,则会加入转换执行器把Push模型执行器转换成火山模型执行器.这样就可以在满足SQL支持力度的同时保证尽可能多的性能扩展点.
Mycat2中的临时表
在一些算子需要把SQL对应的结果集数据全量完整拉到Mycat2中进行保存来支持迭代器反复迭代,对于有这种要求的关系表达式,Mycat2会自动添加MycatMatierial物理算子缓冲数据.要注意的,它的输入节点的数据行不能过大,否则会把内存(硬盘空间)耗尽.
分区裁剪
Mycat2是一款分库分表型的分布式数据库,分区裁剪是极为重要的优化,这里描述的一个分区就是一个物理表.通过分析谓词中的拆分键与拆分值,结合分片规则,在执行SQL扫描表数据的时候,去掉不需要扫描的物理表,可以减少扫描表的完成时间.
Mycat2的规则分片(对应1.6的分片规则)
一般支持范围扫描,当检查到谓词中带有between < >等运算符,Mycat会把他们组成范围区间进行扫描。
Mycat2的Hash分片
Hash型的分片不支持范围扫描,但可以使用分库分表指定一个大范围(分库),小范围(分表)进行范围查询
分片条件
支持分片语法,并自动进行化简
=between>=><<=column = literal or column2 = literal //1.20 2021-7-26column in (literal,literal) //1.20 2021-7-26
确保分区剪裁
当where 语句只有一个拆分键而且是等值查询的时候,分区剪裁是可以生效的。如果SQL比较复杂,可以尝试使用子查询构造单独的select语句带有分片字段,使优化器准确识别拆分键
例如select * from t1 inner join (select id from t2 where id = 1) on t1.id = t2;
更多优化规则可以看
https://dev.mysql.com/doc/refman/8.0/en/optimization.html
Mycat2正参考它逐步完善
Explain语句
Mycat2支持Explain语句,仅支持select,delete,insert,update语句。
其他语法也一定程度上支持explain语句,但是不在实现目标之内,可能存在不能运行的情况。
语法
explain statement
结果
plansql:SELECT *FROM db1.`travelrecord`rel:View(relNode=[SELECT *FROM `db1`.`travelrecord`],distribution=[{targetName='c0', schemaName='db1_0',tableName='travelrecord_0'},{targetName='c0', schemaName='db1_0',tableName='travelrecord_1'},...])
一般来说包含三个方面信息
1.Mycat接收到的sql
2.下推的关系表达式以及最终执行的sql模板
3.一个或多个存储节点的信息

若有收获,就点个赞吧
0 人点赞
