发现一些用户有个普遍认识,分库分表配置繁琐,而且需要大量文档来描述配置.这是错误的.
1.21以后原型库不是必须的,就是没有配置原型库或者数据源配置错误错的情况下,mycat2也能够启动,但原型库的是单表的默认存储节点,所以,大部分场景是需要原型库.
本文仅描述最核心的内容
1.启动服务
2.添加数据源(2个SQL)
4.添加集群(1个SQL)
5.学会建库(1个SQL)
6.学会创建单表,分片表,全局表(3个SQL)
具体配置关系可以看
Mycat2配置映射关系(表)
[
](https://www.yuque.com/ccazhw/ml3nkf/le5tug)
入门Mycat2

右侧的MySQL在Mycat2的配置里面叫做prototype,专门用于响应兼容性SQL和系统表SQL。
什么是兼容性SQL?
客户端或者所在应用框架运行所需必须的SQL,但是用户一般接触不到,它们会影响客户端的启动,运行。而Mycat对于这种SQL尽可能不影响用户使用。
什么prototype服务器?
分库分表中间件中用于处理MySQL的兼容性SQL和系统表SQL(比如用于显示库,表的sql)的服务器,这个配置项可以指向一个服务器也可以是一个集群,Mycat依赖它处理非select,insert,update,delete语句。当这个服务器是与第一个存储节点是同一个服务器/集群的时候,人们一般叫它做0号节点。
prototype.cluster.json
{"clusterType":"MASTER_SLAVE","heartbeat":{"heartbeatTimeout":1000,"maxRetry":3,"minSwitchTimeInterval":300,"slaveThreshold":0},"masters":["prototypeDs"],"maxCon":200,"name":"prototype","readBalanceType":"BALANCE_ALL","switchType":"SWITCH"}
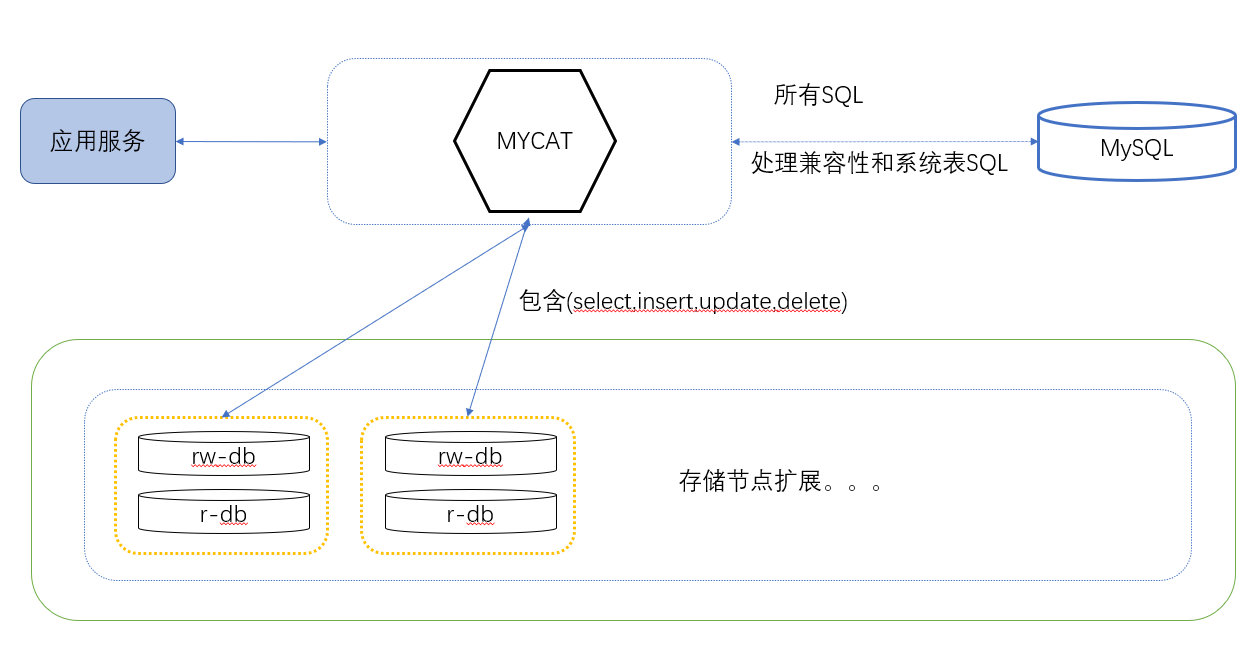
入门(按顺序把下面的SQL在客户端执行一遍)
前提:
准备两个MySQL服务器(prototype服务器),端口3306,3307 ,用户名:root 密码:123456
Mycat2的jar包

所以配置的顺序应该是自下而上,先建立数据源,再建立集群,最后配置表
但是做数据分布设计的时候是自上而下的,请不要混淆
Mycat服务器级别配置
保证配置文件夹有server.json,内容至少是
{"server":{"ip":"127.0.0.1","mycatId":1,"port":8066,"serverVersion": "5.7.33-mycat-2.0" //注意设置模拟的MySQL版本,与后端,客户端版本对应}}
启动请参考文档(安装与启动)
https://www.yuque.com/ccazhw/ml3nkf/1faac0f0187f3dda0acfbeeb9cc6656c
启动过程中,Mycat会在配置文件夹生成默认配置,加载上述的MySQL中的系统表,并建立用于连接mycat的用户名为root 密码为123456
此时使用客户端登录Mycat即可
Mycat可以在控制台创建库
//在mycat终端输入CREATE DATABASE db1
建库语句执行两个操作
1.更改mycat的整个库配置
2.在prototype服务器执行此SQL(1.21之后没有这个步骤)
Mycat可以在控制台操作
切换逻辑库
//在mycat终端输入USE `db1`;
建表语句执行两个操作
1.更改mycat的整个库配置
2.在prototype服务器执行此SQL
删除逻辑库
//在mycat终端输入DROP DATABASE db1
建表语句执行两个操作
1.更改mycat的整个库配置
2.在prototype服务器执行此SQL(1.21之后没有这个步骤)
创建单表
//在mycat终端输入CREATE TABLE db1.`travelrecord` (`id` bigint NOT NULL AUTO_INCREMENT,`user_id` varchar(100) DEFAULT NULL,`traveldate` date DEFAULT NULL,`fee` decimal(10,0) DEFAULT NULL,`days` int DEFAULT NULL,`blob` longblob,PRIMARY KEY (`id`),KEY `id` (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;
建表语句执行两个操作
1.更改mycat的整个库配置
2.在prototype服务器执行此SQL(1.21之后没有这个步骤)
使用注释动态配置Mycat
如果使用MySQL官方客户端添加 **-c** 参数避免客户端过滤注释
添加存储数据源
//在mycat终端输入/*+ mycat:createDataSource{"name":"dw0","url":"jdbc:mysql://127.0.0.1:3306/mysql","user":"root","password":"123456"} */;/*+ mycat:createDataSource{"name":"dr0","url":"jdbc:mysql://127.0.0.1:3306/mysql","user":"root","password":"123456"} */;/*+ mycat:createDataSource{"name":"dw1","url":"jdbc:mysql://127.0.0.1:3307/mysql","user":"root","password":"123456"} */;/*+ mycat:createDataSource{"name":"dr1","url":"jdbc:mysql://127.0.0.1:3307/mysql","user":"root","password":"123456"} */;
jdbc:mysql://127.0.0.1:3306/mysql
此处的mysql按需配置
dw0与dr0,dw1与dr1是主从关系,是mysql的binlog同步数据,mycat不负责同步数据
添加集群配置
//在mycat终端输入/*! mycat:createCluster{"name":"c0","masters":["dw0"],"replicas":["dr0"]} */;/*! mycat:createCluster{"name":"c1","masters":["dw1"],"replicas":["dr1"]} */;
删除表
//在mycat终端输入drop table db1.travelrecord
删表语句执行两个操作
1.更改mycat的整个库配置
2.在prototype服务器执行此SQL(1.21之后没有这个步骤),而不会在其他存储节点执行
创建全局表
//在mycat终端输入CREATE TABLE db1.`travelrecord` (`id` bigint NOT NULL AUTO_INCREMENT,`user_id` varchar(100) DEFAULT NULL,`traveldate` date DEFAULT NULL,`fee` decimal(10,0) DEFAULT NULL,`days` int DEFAULT NULL,`blob` longblob,PRIMARY KEY (`id`),KEY `id` (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8 BROADCAST;
建全局表语句执行操作
1.更改mycat的整个库配置
2.在prototype服务器执行此SQL(1.21之后没有这个步骤,用于客户端显示逻辑表,因为此物理表与逻辑表相同名字)
3.根据当前集群名字首字母为c的集群纳入到全局表的存储节点中
4.根据存储节点信息建立物理库,物理表
创建分片表(分库分表)
//在mycat终端输入CREATE TABLE db1.`travelrecord` (`id` bigint NOT NULL AUTO_INCREMENT,`user_id` varchar(100) DEFAULT NULL,`traveldate` date DEFAULT NULL,`fee` decimal(10,0) DEFAULT NULL,`days` int DEFAULT NULL,`blob` longblob,PRIMARY KEY (`id`),KEY `id` (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8 dbpartition by mod_hash(id) tbpartition by mod_hash(id) tbpartitions 2 dbpartitions 2;
dbpartition by mod_hash(id) tbpartition by mod_hash(id) tbpartitions 2 dbpartitions 2;就是分库分表语法
建分片表语句执行操作
1.更改mycat的整个库配置
2.在prototype服务器执行此SQL(1.21之后没有这个步骤,用于客户端显示逻辑表,因为此物理表与逻辑表相同名字)
3.根据当前集群名字首字母为c的集群纳入到分片表的存储节点中
4.根据存储节点信息建立物理库,物理表
默认分片表的自增序列是雪花算法
显示存储节点,用于显示逻辑表的数据在哪里
//在mycat终端输入/*+ mycat:showDataNodes{//1.18前"schemaName":"db1","tableName":"normal"} */;/*+ mycat:showTopology{//1.18后"schemaName":"db1","tableName":"normal"} */;
上述的原型库与c0实际上是同一个数据库使用创建了两个数据源进行连接
由于直接更改本地配置比较繁琐,所以mycat2实现了使用注解来更改配置.可以把注解写成脚本,在客户端导入此脚本就可以,Mycat2支持多语句执行
通过注解配置
在mycat2能正常启动的情况下,根据当前配置自动创建分片表,全局表的物理表(但不自动创建单表的物理表),如果物理表不存在
//在mycat终端输入/*+ mycat:repairPhysicalTable{} */;//1.20-2020-7-17后,实验
检查存储节点上的表结构是否一致
CHECK TABLE db1.travelrecord2;
[
上面介绍的方式是让用户从SQL操作入门Mycat2的,需要执行SQL后观察生成的配置文件是怎样的,然后理解.因为SQL的语法和表达对配置不是特别友好,实际使用上还需要调整配置文件的.如果调整过配置文件了就不要再执行SQL改表,这样会使配置被SQL生成的配置覆盖.另外Mycat的Alter语句在生产上的表是不能用的,需要用专门的软件执行Alter的.
](https://www.yuque.com/ccazhw/ml3nkf/f9f24306bbd3992c1baff00cdb0956a4)

若有收获,就点个赞吧
0 人点赞
