Mycat2支持使用SQL直接建表,请看[简介]入门Mycat2,可以通过建立SQL执行脚本,在客户端执行即可.
把这个PPT看几遍
http://dl.mycat.org.cn/2.0/mycat2%e6%98%a0%e5%b0%84%e5%85%b3%e7%b3%bb.pdf
配置的schema的逻辑库逻辑表必须在原型库(prototype)中有对应的物理库物理表,否则不能启动
建表语句是可选配置的,不配置会在原型库中读取
文档和mycat历史问题,sharding拼写错误成shading,请注意更正
所有targetName的地方都可以写数据源或者集群
schema配置
{库名}.schema.json保存在schemas文件夹
1.21新增虚拟表后的关系,此前没有虚拟表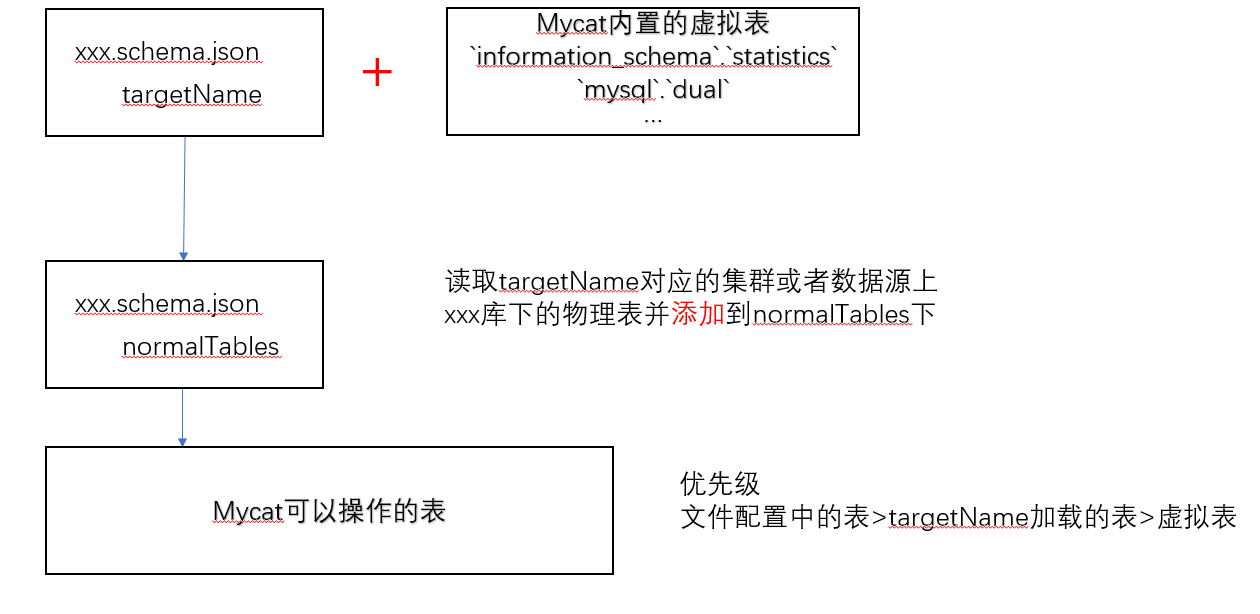
库配置
{"customTables": {},"globalTables": {},"normalTables": {},"schemaName": "test","shardingTables": {},"targetName": "prototype"}
简化后得
//test.schema.json{"schemaName": "test","targetName": "prototype"}//test1.schema.json{"schemaName": "test1","targetName": "prototype1"}
targetName自动从prototype目标加载test库下的物理表或者视图作为单表,prototype必须是mysql服务器
该配置对应1.6的schema上配置dataNode用于读写分离
单表配置(可用于建立物理视图,与单表配置没有区别,但是可能存在sql解析失败导致加载视图失败,此时,需要提供建表语句,即把建视图语句以建表语句方式表达,写上字段信息)
1.18前
{
"schemaName": "mysql-test",
"normalTables": {
"role_edges": {
"createTableSQL":null,//可选
"dataNode": {
"schemaName": "mysql",//物理库
"tableName": "role_edges",//物理表
"targetName": "prototype"//指向集群,或者数据源
}
}
......
1.18后
{
"schemaName": "mysql-test",
"normalTables": {
"role_edges": {
"createTableSQL":null,//可选
"locality": {
"schemaName": "mysql",//物理库,可选
"tableName": "role_edges",//物理表,可选
"targetName": "prototype"//指向集群,或者数据源
}
}
......
mysql-test(mycat服务器逻辑库).role_edges 映射为prototype(mysql服务器物理库).mysql.role_edges
如果本地配置不生效,可以尝试先通过注释配置一个表,比如
create database db1;
create table ….
来触发它更新
全局表配置
1.18前
{
"schemaName": "mysql-test",
"globalTables": {
"role_edges": {
"dataNodes": [{"targetName": "c0"},{"targetName": "c1"}]
}
......
1.18后
{
"schemaName": "mysql-test",
"globalTables": {
"role_edges": {
"broadcast": [{"targetName": "c0"},{"targetName": "c1"}]
}
......
分片表配置
分片表配置-hash型自动分片算法
{
"customTables": {},
"globalTables": {},
"normalTables": {},
"schemaName": "db1",
"shardingTables": {
"travelrecord": {
"function": {
"properties": {
"dbNum": "2",//分库数量
"tableNum": "2",//分表数量
"tableMethod": "hash(id)",//分表分片函数
"storeNum": 2,//实际存储节点数量
"dbMethod": "hash(id)",//分库分片函数
"mappingFormat": "c${targetIndex}/db1_${dbIndex}/travelrecord_${tableIndex}"
}
}
}
}
}
mappingFormat格式
targetName/schemaName/tableName
数据库/物理库名/物理分表名
targetIndex,dbIndex,tableIndex总是从0开始计算,支持groovy运算生成目标名,库名,表名
上述配置自动使用c0,c1两个集群作为存储节点
分片表配置-自定义分片算法
1.18前
{
"customTables": {},
"globalTables": {},
"normalTables": {},
"schemaName": "db1",
"shardingTables": {
"travelrecord": {
"function": {
"clazz": ,//具体自定义分片算法
"properties": {
...分片算法参数
}
},
"dataNode":{
"targetNames":"c$0-1",
"schemaNames":"db1_$0-1",
"tableNames":"t1_$0-1"
}
}
}
}
1.18后
{
"customTables": {},
"globalTables": {},
"normalTables": {},
"schemaName": "db1",
"shardingTables": {
"travelrecord": {
"function": {
"clazz": ,//具体自定义分片算法
"properties": {
...分片算法参数
}
},
"partition":{
"targetNames":"c$0-1",//集群或者数据源
"schemaNames":"db1_$0-1",//物理库
"tableNames":"t1_$0-1"//物理表
}
}
}
}
partition配置存储节点,在分片算法无法使用的时候就扫描这些存储节点,所以分片算法无法正确配置的时候仍然可以查询,但是可能插入报错
需要注意的是在此处
partition中的生成表达式不支持groovy运算只支持$0-1语法生成
partition中的targetName-schemaName-tableName不能重复
"targetNames":"c$0-1",//数据库名
"schemaNames":"db1_$0-1",//物理库名
"tableNames":"t1_$0-1"//物理分表名
样例
{
"customTables":{},
"globalTables":{},
"normalTables":{},
"schemaName":"db1",
"shardingTables":{
"sharding":{
"createTableSQL":"CREATE TABLE db1.`sharding` (\n `id` bigint NOT NULL AUTO_INCREMENT,\n `user_id` varchar(100) DEFAULT NULL,\n `create_time` date DEFAULT NULL,\n `fee` decimal(10,0) DEFAULT NULL,\n `days` int DEFAULT NULL,\n `blob` longblob,\n PRIMARY KEY (`id`),\n KEY `id` (`id`)\n) ENGINE=InnoDB DEFAULT CHARSET=utf8",
"function":{
"clazz":"io.mycat.router.mycat1xfunction.PartitionByHotDate",
"properties":{
"lastTime":90,
"partionDay":180,
"dateFormat":"yyyy-MM-dd",
"columnName":"create_time"
},
"ranges":{}
},
"partition":{
"schemaNames":"db1",
"tableNames":"sharding_$0-1",
"targetNames":"c0"
}
}
}
}
for (String target : targets) {
for (String schema : schemas) {
for (String table : tables) {
....生成存储节点
}
}
}
2021-8-15后
规则型自定义分区
/*+ mycat:createTable{
"schemaName":"db1",
"shardingTable":{
"createTableSQL":"CREATE TABLE db1.`sharding` (\n `id` bigint NOT NULL AUTO_INCREMENT,\n `user_id` varchar(100) DEFAULT NULL,\n `create_time` date DEFAULT NULL,\n `fee` decimal(10,0) DEFAULT NULL,\n `days` int DEFAULT NULL,\n `blob` longblob,\n PRIMARY KEY (`id`),\n KEY `id` (`id`)\n) ENGINE=InnoDB DEFAULT CHARSET=utf8",
"function":{
"clazz":"io.mycat.router.mycat1xfunction.PartitionByHotDate",
"properties":{
"dateFormat":"yyyy-MM-dd",
"lastTime":30,
"partionDay":30,
"columnName":"create_time"
}
},
"partition":{
"data":[["c0","db1","t2","0","0","0"],["c1","db1","t2","1","1","1"]] }
},
"tableName":"sharding"
} */;
hash型自定义分区
单库分表例子
{
"customTables": {},
"globalTables": {},
"normalTables": {},
"schemaName": "db1",
"shardingTables": {
"travelrecord": {
"function": {
"properties": {
"dbNum": "1",
"tableNum": "10",
"tableMethod": "hash(id)",
"storeNum": 1,
"dbMethod": "hash(id)",
"mappingFormat": "prototype/db1/travelrecord_${tableIndex}"
}
}
}
}
}
data属性用于完全自定义分区
/*+ mycat:createTable{
"schemaName":"db1",
"shardingTable":{
"createTableSQL":"create table travelrecord(id int)",
"function":{
"properties":{
"dbNum":2,
"mappingFormat":"c${targetIndex}/db1_${dbIndex}/travelrecord_${tableIndex}",
"tableNum":2,
"tableMethod":"mod_hash(id)",
"storeNum":2,
"dbMethod":"mod_hash(id)"
}
},
"partition":{
"data":[["c0","db1","t2","0","0","0"],["c1","db1","t2","1","1","1"]] }
},
"tableName":"sharding"
} */;
[“c0”,”db1”,”t2”,”0”,”0”,”0”]
集群/数据源,物理库,物理表,分库下标,分表下标,全局分区下标
["c0","db1","t2","0","0","0"]
集群名字或者数据源名字
物理库名字
物理表名字
总物理库下标
每物理表下标
总物理分表下标
当data属性配置后,会覆盖
"schemaNames":
"tableNames":
"targetNames":
这三个属性,另外它也会覆盖内置自动hash生成的分区配置
可以使用以下命令查看配置的分区
/*+ mycat:showTopology{
"schemaName":"db1",
"tableName":"sharding"
} */;

若有收获,就点个赞吧
0 人点赞
