浏览器对XMLDOM的支持
序:
曾几何时,XML一度成为存储和通过因特网传输结构化数据的标准。透过XML的发展,能够清晰地看到Web技术发展的轨迹。DOM规范的制定,不仅是为了方便在web浏览器中使用XML,也是为了在桌面及服务器应用程序中处理XML数据。此前,由于浏览器无法解析XML数据,很多开发人员都要动手编写自己的XMl解析器。而自从DOM出现后,所有浏览器都内置了对XML的原生(XML DOM),同时也提供了一系列相关的技术支持。
浏览器对XML DOM的支持
在正式的规范诞生以前,浏览器提供商实现的XML解决方案不仅对XML的支持程度参差不齐,而且对同一特性的支持也各部相同。DOM2级是第一个提到动态创建XML DOM概念的规范。DOM3级进一步增强了XML DOM,新增了解析和序列化等特性。然而,当DOM3级规范的各项条款尘埃落定之后,大多数浏览器也都实现了各自不同的解决方案。
1 DOM2级核心

2 DOMParser类型
DOMParser: DOM解析器
在解析XML之前,首先必须创建一个DOMParser的实例。
然后再调用**parseFromString()**方法:这个方法接受两个参数;1、要解析的XML字符串/2、内容类型(内容类型始终应该是“text/xml”)。返回的值是一个Document的实例。
例子: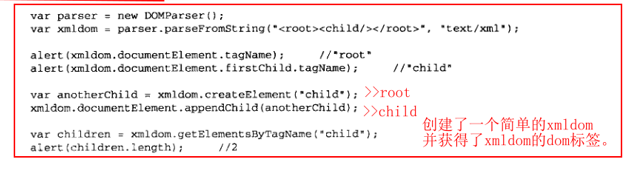
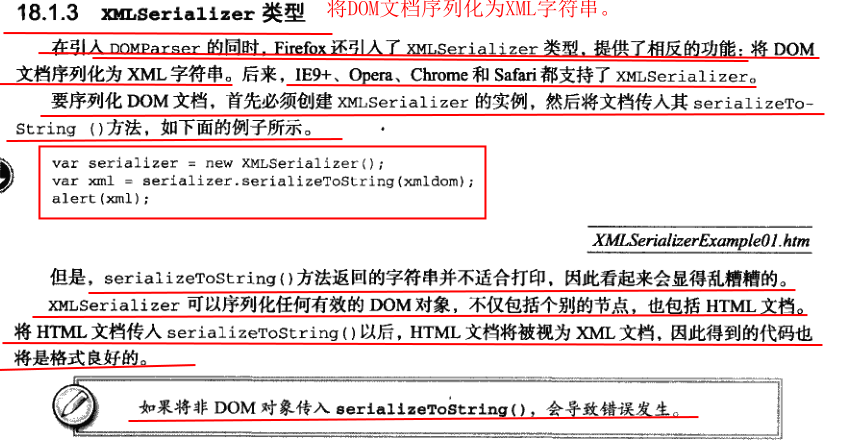
3 XMLSeriallzer类型
浏览器对XPath的支持
XPath的设计用来在DOM文档中查找节点的一种手段,因而对XML处理也很重要。但是,DOM3级以前的标准并没有就Xpath的API作出规定;XPath是在DOM3级XPath模块中首次跻身推荐标准行列的。很多浏览器都实现了这个推荐标准。但IE则以自己的方式实现了XPath。
更多请查看:http://www.w3school.com.cn/xpath/index.asp
浏览器对XSLT的支持

小结



若有收获,就点个赞吧
0 人点赞
