
评价
TODO
Chapter 1 — 概述
并发与并行的区别
从大的概念来看并发是问题域的概念,而并行是方法域的概念。
从确定性来看,并发是具有不确定性,而并行是具备来确定性的。
作为程序员操作的是并发,而并行是操作系统层级确定的。当我们写多进程或者多线程程序的时候实际上我们是在写并发程序。
举个例子来说明,
你吃饭吃到一半,电话来了,你一直到吃完了以后才去接,这就说明你不支持并发也不支持并行。
你吃饭吃到一半,电话来了,你停了下来接了电话,接完后继续吃饭,这说明你支持并发。(不一定是同时的)
你吃饭吃到一半,电话来了,你一边打电话一边吃饭,这说明你支持并行。
串行、并发、并行的区别通过如图所示非常容易理解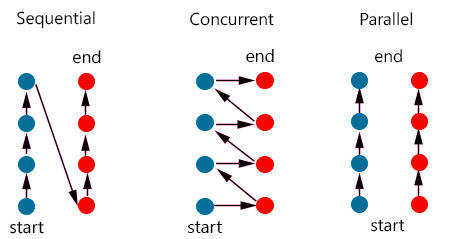
并行架构
现在计算机在不同层次上都使用了并行技术,
位级并行(bit-level):64位计算机的运行速度并32的更快
指令级并行(instruction-level):计算机处理问题是通过指令实现的,每个指令都是交给CPU执行。在1978年的 Intel 8086 处理器都只能一次执行单指令。 Intel首次在486芯片中开始使用,原理是:当指令之间不存在相关时,它们在流水线中是可以重叠起来并行执行。现代CPU的并行技术有很多,而从程序员的角度来看都是透明的。
数据级并行(multipe-data level):也称为“单指令多数据”,可以并行的在大量数据上施加同一操作。比如图像处理或者音频处理等。举个例子,给图片增加亮度,就是对图片的每个像素都增加同一个操作。
任务级并行(task-level):大家平常认为的并行进行,多处理器,多处理器系统最明显的分类特征是其内存模型(共享内存模型或者分布式内存模型)
并发的优势
1.让系统可以及时的相应用户,提升用户体验。
2.增加了系统的容错性,比如一个程序分别执行A、B、C三个任务,B任务出现了bug,但是其并发性使得A、C都能继续支持,特别是在分布式的情况,这样的容错性是非常必要的。
七个模型
线程与锁、函数式编程、Clojure、actor、CSP、数据级并行、Lambda
需要关注的问题:
1.这些模型适用于解决并发问题、并行问题还是都可以?
2.这些模型是哪个层级的的并行架构
3.这些模型是否有利于提升容错性?使用适用于分布式场景?
Chapter 2 — 线程与锁
Day1 互斥及内存模型
第一把锁 synchronized
内存可见性
内置锁
Day2 超越内置锁
可中断的锁
超时
交替锁:这个思路很有意思
原子变量
Day3 站在巨人的肩膀上
使用线程池
CopyOnWrite
生产-消费模式
锁分段技术
FAQ
1.Java内存模型是如何保证初始化时线程安全的?
初始化过程中第一步就是对类初始化过程加锁,可以参考oracle的文档,刚好手上买了一本Java虚拟机规范(Java SE 8版本),这里贴上中文翻译
同样openjdk也遵循了同样的规范来实现(参考文档)
2.是否必须通过加锁才能在线程之间安全的公开对象?
线程之间没有共享对象?无锁是否存在?只是降低了锁的粒度,在不同层面和抽象程度解决了锁的问题。
3.虚假唤醒是什么?什么时候会发生虚假唤醒?
如下图是我们使用条件变量时的使用范例,
举个例子,我们现在有一个生产者-消费者队列和三个线程。
1) 1号线程从队列中获取了一个元素,此时队列变为空。
2) 2号线程也想从队列中获取一个元素,但此时队列为空,2号线程便只能进入阻塞(cond.wait()),等待队列非空。
3) 这时,3号线程将一个元素入队,并调用cond.notify()唤醒条件变量。
4) 处于等待状态的2号线程接收到3号线程的唤醒信号,便准备解除阻塞状态,执行接下来的任务(获取队列中的元素)。
5) 然而可能出现这样的情况:当2号线程准备获得队列的锁,去获取队列中的元素时,此时1号线程刚好执行完之前的元素操作,返回再去请求队列中的元素,1号线程便获得队列的锁,检查到队列非空,就获取到了3号线程刚刚入队的元素,然后释放队列锁。
6) 等到2号线程获得队列锁,判断发现队列仍为空,1号线程“偷走了”这个元素,所以对于2号线程而言,这次唤醒就是“虚假”的,它需要再次等待队列非空。
使用while去做判断而不是使用if的原因:因为等待在条件变量上的线程被唤醒有可能不是因为条件满足而是由于虚假唤醒。
4.阿姆达尔定律
这篇博客总结的不错。并发的性能平时几乎不关注,在实际工作场景下资源的瓶颈更多不在于代码的性能,而代码性能带来的问题更多不是并发性能的问题而是架构上的问题。当然不关注并发的性能在来日的某一个时刻也可能为此付出其他的代价。
5.药丸方法
?
小结
1.更多的关于java并发编程的,个人觉得《java并发编程实战》写的更加详细也更加深入,是本值得一读的好书。
2.在使用线程域锁模型的程序中,大多数潜藏的竞态条件并不是来自于问题本身的不确定性,而是隐藏于解决方案的细节中。而这些方案可能就隐藏着无数的坑,同时该方案又依赖了其他的方案或者提供给其他方案使用,这样的并发问题发生的时候定位问题在语言层面却无法提供有效的工具供开发者使用,往往只能靠开发者的经验。
优点
1.适用面广,是很多其他技术的基础,适用于解决很多问题,其在“本质”上也更接近于硬件工作方式的形式化,效率很高。在正确使用的情况下能够解决从小到大不同粒度的问题。
2.可以轻松的集成到大多数编程语言中,事实也很多语言都会支持线程与锁模型。
缺点
1.开发者的无助。虽然很多语言可能都尽力去提供更好的基础并发工具包,但是这远远不够。这并不是说其有多难编写,而是难以验证代码的正确性,难以测试
2.容易发生不易察觉的错误,由于难以测试,程序员并不是知道代码是否是正确的,即使一段代码已经运行了几个月
3.可维护性差,由于难以测试当代码进行交接时无法验证其正确性的自动化测试就派不上用场,而新的维护者会在各种同步、互斥变量头晕目眩。
reference
1.The Java Memory Model
2.Java Initialization
Chapter 3 — 函数式编程
Day1 抛弃可变状态
隐藏的可变状态
很多我们以为线程安全的类实际并不是,在并发编程中隐藏和逃逸仅仅是两种可变状态带来的风险。
书中提到的SimpleDateFormat例子,在阿里的Java开发规约中是有提到的。除了加锁、使用DateUtils工具外,同时也可以使用ThreadLocal来处理。
Clojure 旋风之旅
详细的代码示例看不太懂
Day2 函数式并行
简单介绍了Clojure的reducres库,如何使用reduce及fold的实现原理
1.Clojure 的化简器(reducer),很多思想与java8中的lambda很相似。
一个简化器并不代表函数返回的结果,而是代表如何产生结果的描述—被传给reduce或fold之前,化简器并不会进行求值**。这样做有两个好处:
- 嵌套函数返回简化器比返回懒惰序列的效率更高,因为其不用构造处于中间状态的序列
- 对整个嵌套链的集合操作,可以使用fold进行并行化
2.fold函数使用了Fork/Join 分而治之的思想
Day3 函数式并发
1.函数式编程中函数具有透明性,不会产生副作用。对函数的求值顺序进行调整不会影响程序的正确性。
2.利用这一特性可以让代码在其依赖的数据准备好时才运行,这也被称为数据流式编程,Clojure提供future模型和promise模型对其进行支持
3.Clojure是一门不纯粹的函数式编程语言
FAQ
1.Clojure并不支持尾调用消除,什么是尾调用消除?
非常好的回答
各个语言的支持情况?
C/C++等也都不支持,只能人肉自行处理;
java不支持,关于JVM的支持情况可以参考该问题
2.Lazy Evaluation
3.函数式编程的数学基础和理论基础?
可以参考阮一峰的《函数式编程入门教程》,当然我觉得他在阐述范畴论上的部分内容并不是很严谨,但是可以暂时作为入门的文章做了解。
4.dataflow programming了解以及和reacting programming的区分?
可参考这个两个问题的描述和回答,我个人的理解是响应式编程是数据流编程的一种形式,但是两个描述的侧重点不同,一个是事件源,一个是数据。
小结
对于没有真正学过Clojure的人在细节上很难理解,但在看了前两小结看完我有依然不明白函数式编程的不可变状态是指哪里以及如何实现的(难道其内部就不能是线程-锁模式实现的!?)?书中只是一味的介绍语言细节。本章总结的部分提到不应该介绍数学概念,这个观点我实在不能赞同。
优点
1.由于函数式代码不使用可变状态,函数的透明性可以将程序并行化,并且很多在线程与锁模型中的并发bug都会得到解决
2.函数式编程最大的好处是我们可以确信程序是按照我们预想的方式运行。代码也更加简单,易于测试。
缺点
性能上的差异?
reference
Chapter 4 — Clojure之道:分离标识与状态
Day1
混搭的力量
函数式编程对于某些问题非常适用,但是对于某些状态易变得问题则不然。
原子变量
纯粹的函数式编程语言完全不支持可变量。Clojure并不是纯函数式编程语言,其同样也提供了用于并发的可变数据类型。
atom就是在java的atomic上建立的,和java的原子变量很像。
持久数据结构
这里的持久数据结构并不是说持久到存储介质上,而是数据结构被修改时总是保留其之前的版本,这样可以为代码提供一致的数据视角,也就是不会在并发情况引入问题。
从原理来看更像是共享数据,在极端情况下会退化到全部复制。
Clojure的集合都是持久化的,非函数式语言实现持久化数据结构需要人肉实现,在语言层面没有办法提供帮助。函数式的数据结构天生就是持久的。这个实现的过程有点意思
标识与状态
命令式语言中,一个变量混合了标识与状态,而函数式语言中,与标识不同,状态实际上是一系列随时间变化的值。
Day2 代理和软件事物内存
1.原子变量可以对单一值进行隔离的、同步的更新
2.代理可以对单一值进行隔离的、异步的更新
3.引用可以对多个值进行一致的、同步的更新
Day3 深入学习
原子变脸还是STM?自行选择,而作者更推荐原子变量,这样足够简单
小结
优点
Clojure的函数式可以享受函数式编程的便利,同时也可以突破函数式的禁锢。Clojure的持久数据结构将可变量的标识与状态分离开来,而传统命令式语言的变量混淆了标识与状态这两个概念。
缺点
Clojure的主要缺点在于不支持分布式编程,也无法提供容错性。
FAQ
1.函数式语言的持久化数据结构是如何实现的?比如Clojure
参考reference 1
2.对STM的简单了解,主流语言对STM的支持?
参考 reference 3,大部分主流语言都支持STM的实现,但是有证据表明:STM模型并不是适合命令式编程语言
3.无锁编程是否存在?NO
Reference
1.understanding clojure’s persistentvector implementation
2.Haskell STM
3.Software transactional memory
4.STM 软件事务内存——本质是为提高并发,通过事务来管理内存的读写访问以避免锁的使用
Chapter 5 — Actor
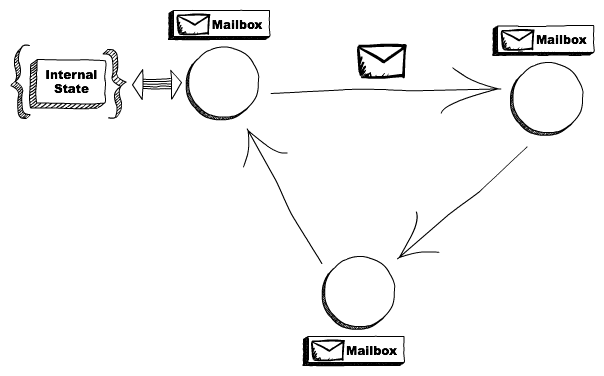
本章很多细节都在介绍Clojure如何应用Actor,但是对其原理和定义介绍的比较少,可以参考下面的两篇文章做了解。
The actor model in 10 minutes
Actor模型
重点知识
1.actor和mailbox的基本概念
2.error-kernel模式。软件设计有两种方式:一种方式是,使软件过于简单,明显地没有缺陷;另一种方式是,使软件过于复杂,没有明显的缺陷。
3.“任其崩溃”哲学了解
4.OTP具体是什么?没太了解
小结
优点
1.Actor之间通过消息传递,单个actor内部所有的事件都是串行的,而并发只需要关注消息流即可。这使得单个actor可以被测试,当出现并发问题时可以把重点放在信息流上。
2.支持分布式式
3具备容错性
缺点**
1.依然会碰到死锁这一类的共性问题
2.可能会遇到信箱溢出等问题
3.补充一点:actor模型更适合在一致性需求不是很高的情况下且对性能需求较高时使用,因为它是一个弱一致性强隔离性的方案。而传统的线程与锁模型是倾向于强一致弱隔离的。
FAQ
1.Actor底层依然是锁与线程,其是更上一层的抽象,这里把它和线程锁模型做比较是不是不合适?当然如果两者都放在同一维度来处理同一问题才有意义。贴一个知乎上问题的回答,感觉这个比喻比较恰当。
Reference
1.What is the Actor Model & When Should You Use it?
2.Differences between the Actor Model and Communicating Sequential Processes (CSP)
3.Erlang is not a implementation of the Actor model Re: Go vs Erlang for distribution
4.Let it crash: 因为误解,所以瞎说
Chapter 6 — CSP
本章很多细节都在介绍Clojure如何应用CSP,但是对其原理和定义介绍的比较少,参考reference中的相关介绍反而能获取得更多。
重点知识
1.Do not communicate by sharing memory; instead, share memory by communicating.
2.CSP更加关注channel
**
Reference
Chapter 7 — 数据并行
重点知识
1.现代GPU是一个强力的数据并行处理器,其用于数学计算时性能超过了CPU,这种做法称为给予图形处理器的通用计算。
2.数据并行可以通过多种方式来实现,流水线和多ALU是其中的两种,但现实中一般是多种技术方案混合使用。
3.流水线:可以通过让流水线饱和来获得更好的性能
4.ALU:主要搭配足够宽的内存总线,多个ALU就可以同时获取多个操作数,这样施加在大量数据上的运算就可以并行了
小结
优点
1.数据并行非常适用于处理大量数值数据,尤其适合于科学计算、工程计算及仿真领域,比如流体力学、神经网络等
2.GPU不仅是强大的数据并行处理器,在能耗方面也表现出众
缺点**
1.GPGPU编程仅在有限的领域内适用,并不是一个通用的解决方案。更多在计算机视觉、图像处理、游戏等领域应用。
FAQ
1.GPU编程更多地是解决算力的问题,但是书中提到的GPGPU是小规模应用?其规模性如何扩展?
Chapter 8 — Lambda架构
Day1
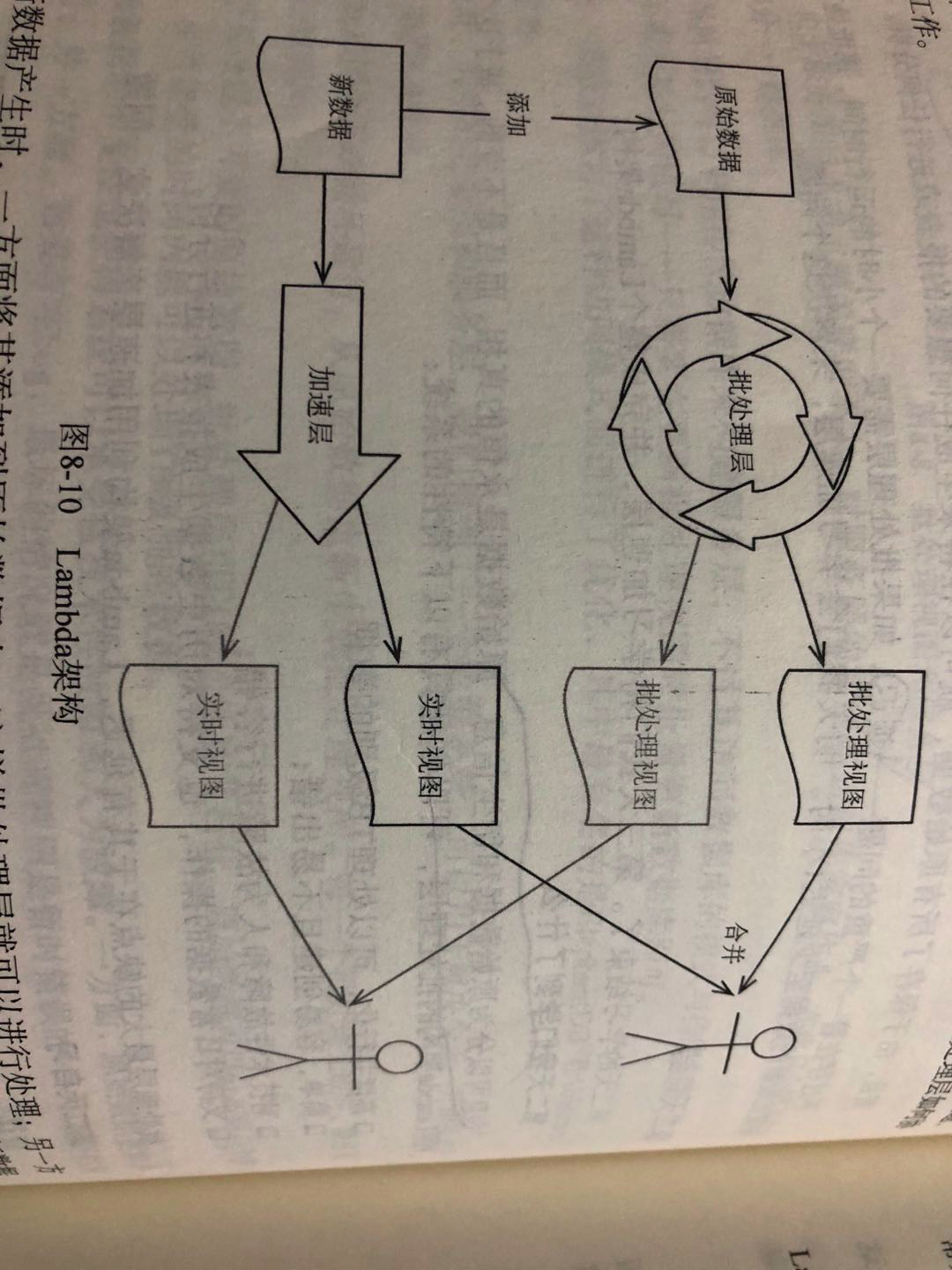
Lambda架构是站在大规模数据场景来解决问题的,不但解决了规模庞大的问题,还可以构建出对硬件错误和人为错误进行容错的系统。Lambda架构中两个主要的组件是:批处理层与加速层。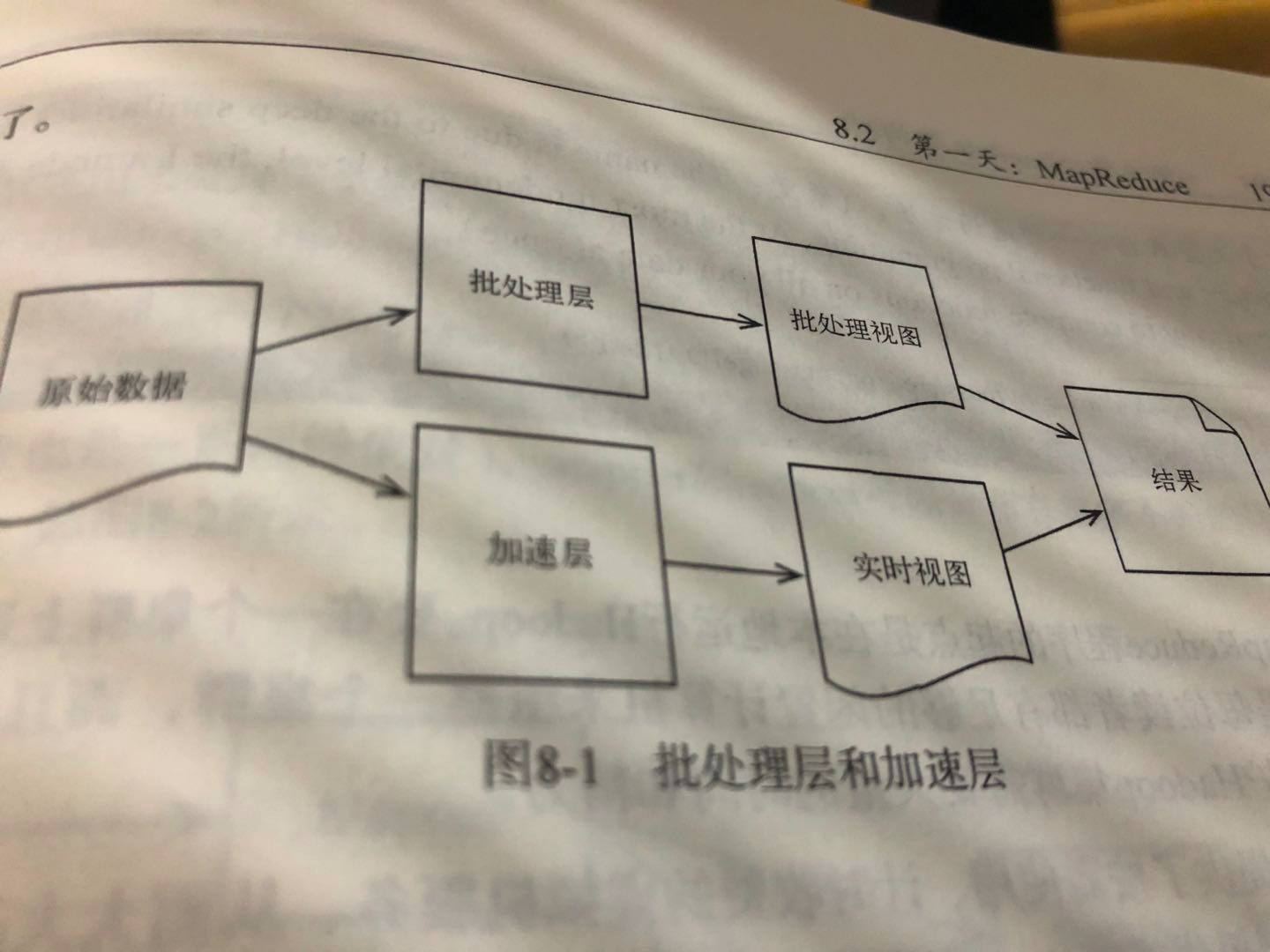
MapReduce
批处理层使用MapReduce这类批处理技术从历史数据中对批处理视图进行预计算。其分为两个步骤:对一个数据结构进行映射(map)操作,然后进行化简(reduce)操作,这样易于并行化。
Hadoop就是用来处理大量数据的工具,天生具有处理错误和从错误中恢复的能力。
**
Day2 批处理层
1.传统数据系统的缺陷:传统数据系统一般使用数据作为存储和数据处理工具,扩展性较差、维护成本高、复杂度高、人为错误导致的数据恢复困难。
2.原始数据是永恒的真相,这是Lambda架构的基础。不变性和并行计算是天作之合。
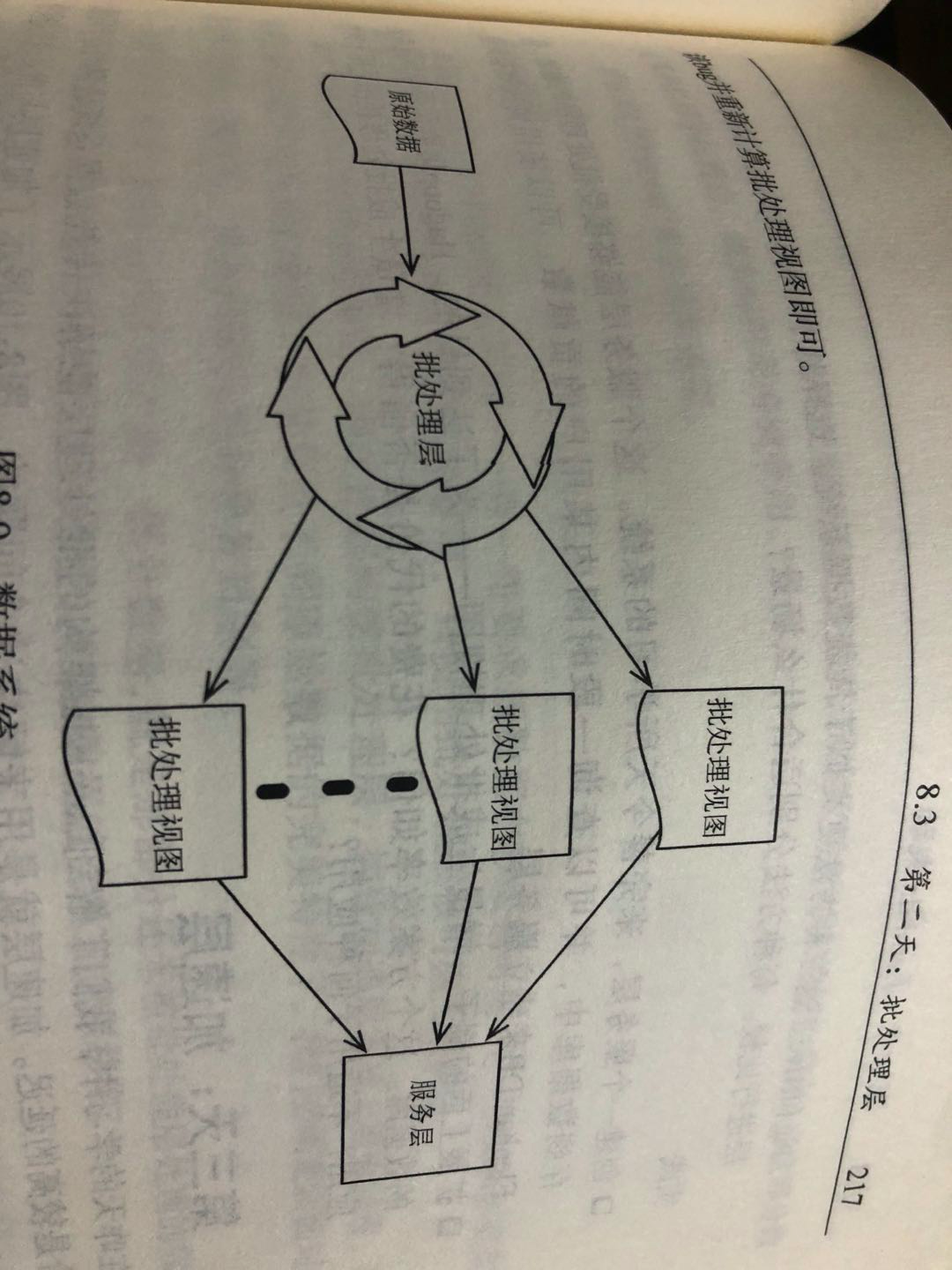
3.批处理层最大的缺点在于其延迟。
Day3 加速层
JStorm在阿里内部已经基本弃用了,大部分都在使用Blink(基于Flink的自研架构)
小结
优点
1.Lambda架构主要用于解决大规模数据的问题。
2.通过批处理层与加速层满足了离线和实时的需求。
缺点
1.当数据量不够大时,其成本将高于收益。
2.离线和实时基于两套引擎来支持,这样当处理逻辑有修改时则需要分别在两个系统中修改,维护成本较高。
FAQ
Reference
1.常用的几种大数据架构剖析
2.Lambda Architecture
3.nathan的博客
4.Simplifying the (complex) Lambda Architecture
5.Lambda Architecture for Real Time Big Data Analytic
6.Lambda Architecture for Batch and Stream Processing-AWS
总结
1.本书其实只介绍了4种通用的并发编程模型,分别是线程与锁、不可变、Actor、CSP;介绍了2种并行编程技术并且,分别是GPGPU编程和Lambda架构。
2.书在介绍各种模型的时候过于注重语言细节了,但对模型的定义与数学基础提的相对较少。
3.通过这本书主要是可以扩展很多之前未了解过的内容,特别是相关经典论文需要集中精力多看看。
Reference
1.Golang 的并发与 Erlang、Scala、Node.js 和 Python 的并发模型相比有何特点
2.请问,多个线程可以读一个变量,只有一个线程可以对这个变量进行写,到底要不要加锁?
3.Scalable Read-mostly Synchronization Using Passive Reader-Writer Locks
4.Benign Data Races: What Could Possibly Go Wrong?
5.Locks, Actors, And Stm In Pictures

若有收获,就点个赞吧
0 人点赞
