- HashMap 根据键的 hashCode 值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。
- HashMap 最多只允许一条记录的键为 null,允许多条记录的值为 null。
- HashMap 非线程安全,即任一时刻可以有多个线程同时写 HashMap,可能会导致数据的不一致。
- 如果需要满足线程安全,可以用 Collections 的 synchronizedMap 方法使HashMap 具有线程安全的能力,或者使用 ConcurrentHashMap
以下基于 JDK1.7 分析。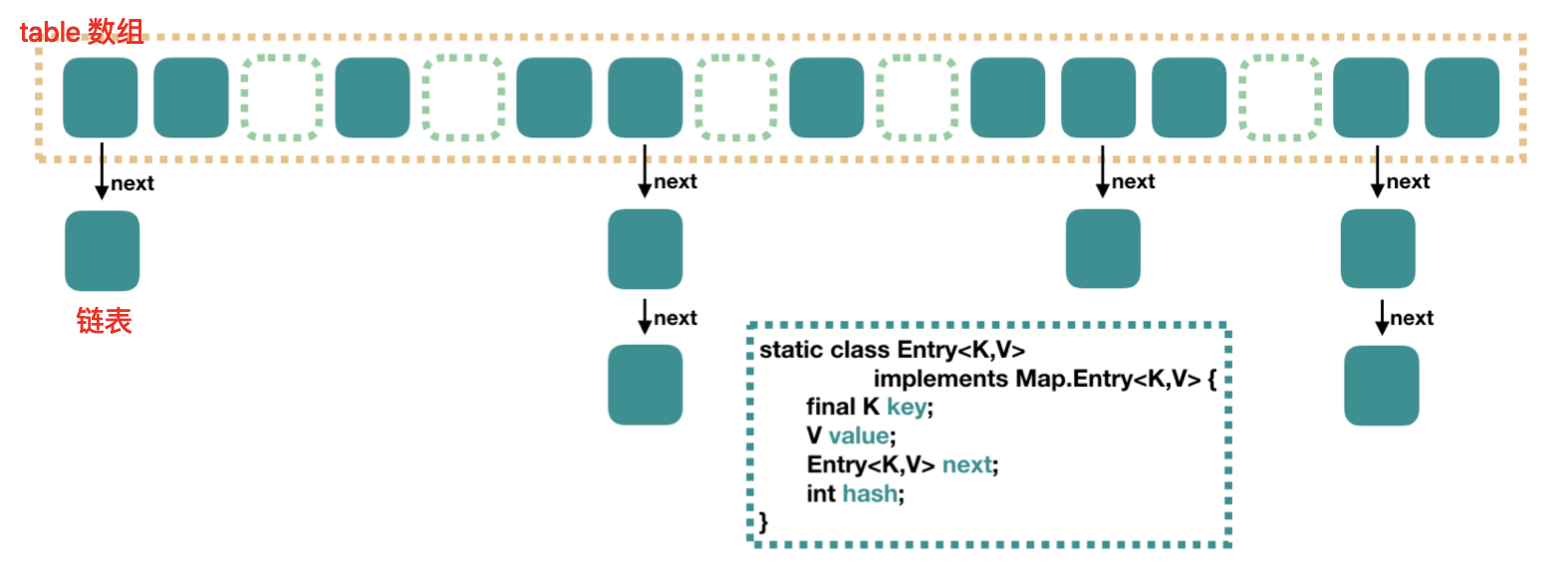
1. 基本方法
HashMap 里面是一个数组,然后数组中每个元素是一个单向链表。上图中,每个绿色的实体是嵌套类 Entry 的实例,Entry 包含四个属性:key, value, hash 值和用于单向链表的 next。
其中有两个重要的参数:
- 容量(capacity),始终保持 2^n,可以扩容,扩容后数组大小为当前的 2 倍
- 负载因子(loadFactor)
容量的默认大小是 16,负载因子是 0.75,当 HashMap 的 size > 16*0.75 时就会发生扩容(容量和负载因子都可以自由调整)。
1.1 put 方法
首先会将传入的 Key 做 hash 运算计算出 hashcode,然后根据数组长度取模计算出在数组中的 index 下标。
由于在计算中位运算比取模运算效率高的多,所以 HashMap 规定数组的长度为 2^n 。这样用 2^n - 1 做位运算与取模效果一致,并且效率还要高出许多。
由于数组的长度有限,所以难免会出现不同的 Key 通过运算得到的 index 相同,这种情况可以利用链表来解决,HashMap 会在 table[index]处形成链表,1.7 采用头插法将数据插入到链表中(1.8是尾插法)。
1.2 get 方法
get 和 put 类似,也是将传入的 Key 计算出 index ,如果该位置上是一个链表就需要遍历整个链表,通过 key.equals(k) 来找到对应的元素。
1.3 遍历方式
Iterator<Map.Entry<String, Integer>> entryIterator = map.entrySet().iterator();while (entryIterator.hasNext()) {Map.Entry<String, Integer> next = entryIterator.next();System.out.println("key=" + next.getKey() + " value=" + next.getValue());}
Iterator<String> iterator = map.keySet().iterator();while (iterator.hasNext()){String key = iterator.next();System.out.println("key=" + key + " value=" + map.get(key));}
map.forEach((key,value)->{System.out.println("key=" + key + " value=" + value);});
强烈建议使用第一种 EntrySet 进行遍历。
第一种可以把 key value 同时取出,第二种还得需要通过 key 取一次 value,效率较低, 第三种需要 JDK1.8 以上,通过外层遍历 table,内层遍历链表或红黑树。
1.4 notice
在并发环境下使用 HashMap 容易出现死循环。
并发场景发生扩容,调用 resize() 方法里的 rehash() 时,容易出现环形链表。这样当获取一个不存在的 key时,计算出的 index 正好是环形链表的下标时就会出现死循环。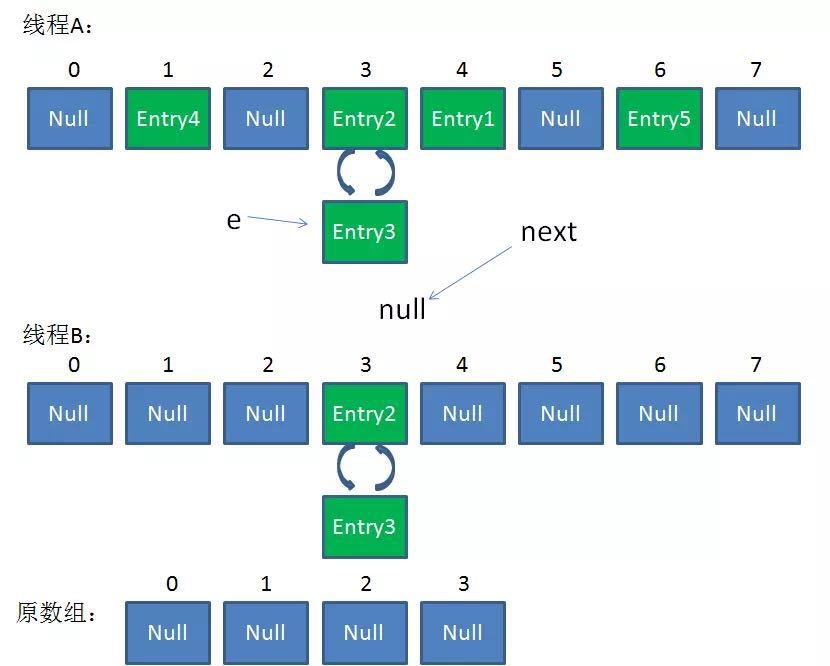
所以 HashMap 只能在单线程中使用,并且尽量的预设容量,尽可能的减少扩容。
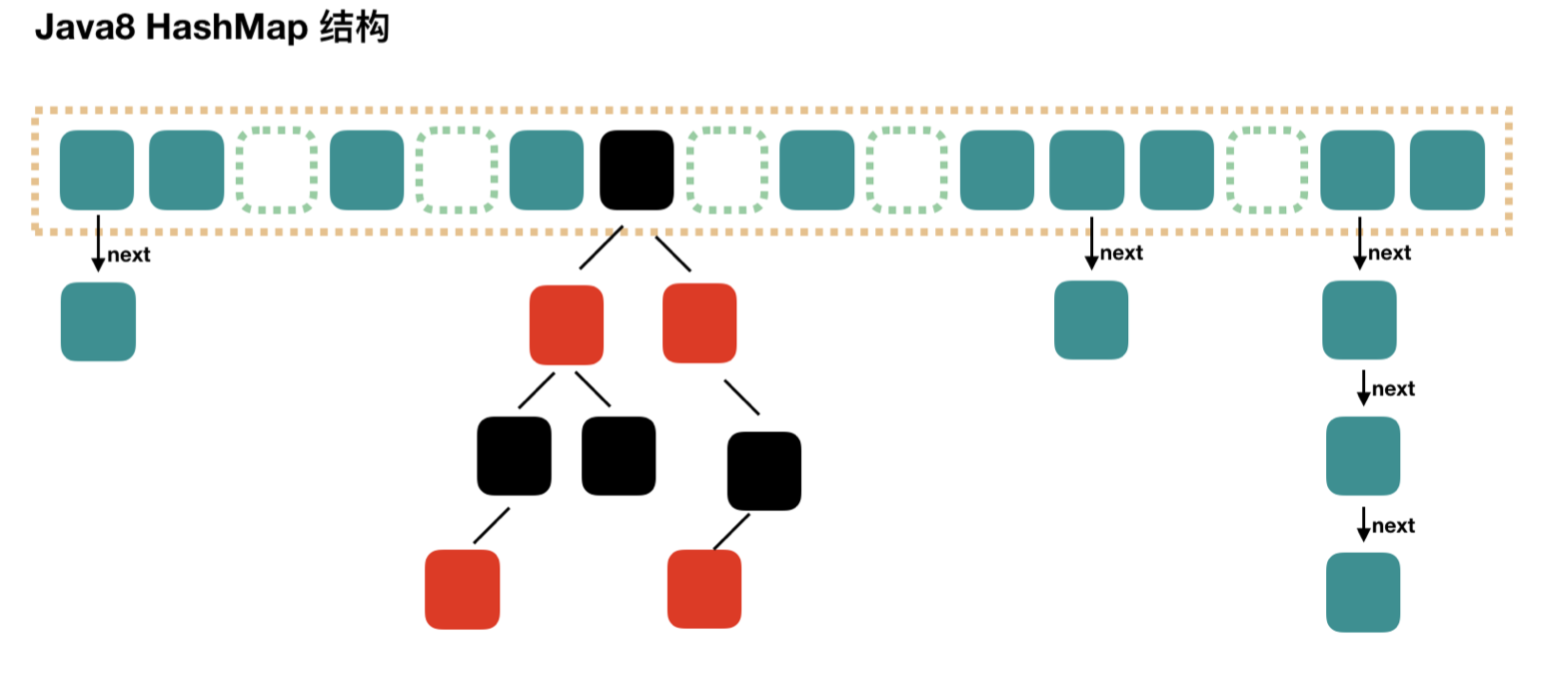
在 JDK1.8 中对 HashMap 进行了优化: 当 hash 碰撞之后写入链表的长度超过了阈值(默认为8)并且 table 的长度不小于64(否则扩容一次)时,链表将会转换为红黑树。所以其由数组+链表+红黑树组成。
根据 Java7 HashMap 的介绍,我们知道,查找的时候,根据 hash 值我们能够快速定位到数组的具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决于链表的长度,为 O(n)。为了降低这部分的开销,在 Java8 中,当链表中的元素超过了 8 个以后,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为 O(logN);
多线程场景下推荐使用 ConcurrentHashMap。
2. HashMap 深入连环炮
2.1 结构和底层原理
由 **数组 + 链表 + 红黑树** 组合构成的数据结构。
大概如下,数组里面每个地方都存了 Key-Value 这样的实例,在 Java7 叫 Entry 在 Java8 中叫 **Node**。
因为他本身所有的位置都为 null,在 put 插入的时候会根据 key 的 hash 去计算一个 index 值。
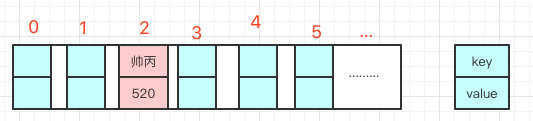
就比如我 put(”帅丙“,520),我插入了为”帅丙“的元素,这个时候我们会通过哈希函数计算出插入的位置,计算出来 index 是 2 那结果如下。
hash(“帅丙”)= 2
2.2 为啥需要链表,链表又是怎么样子的呢?
我们都知道数组长度是有限的,在有限的长度里面我们使用哈希,哈希本身就存在概率性,就是”帅丙“和”丙帅“我们都去 hash 有一定的概率会一样,就像上面的情况我再次哈希”丙帅“极端情况也会 hash 到一个值上,那就形成了链表。(两个对象 hash 值相同会放到一个链表上)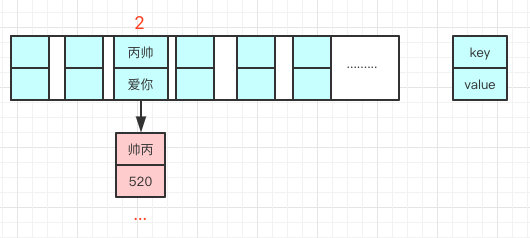
每一个节点都会保存自身的 hash、key、value、以及下个节点。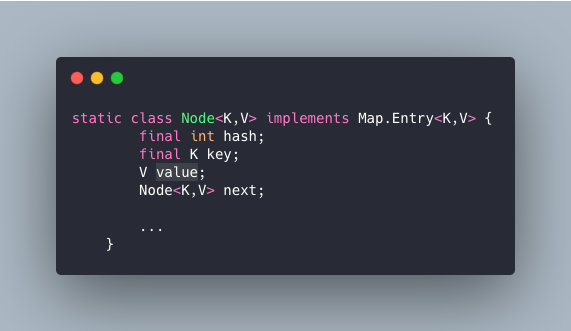
说到链表我想问一下,你知道新的Entry节点在插入链表的时候,是怎么插入的么?
java8 之前是头插法,就是说新来的值会取代原有的值,原有的值就顺推到链表中去,就像上面的例子一样,因为写这个代码的作者认为后来的值被查找的可能性更大一点,提升查找的效率。
但是,在java8之后,都是所用尾部插入了。
为啥改为尾部插入呢?
首先我们看下 HashMap 的扩容机制:帅丙提到过了,数组容量是有限的,数据多次插入的,到达一定的数量就会进行扩容,也就是 resize。
什么时候 resize 呢?
有两个因素:
Capacity:HashMap 当前长度。LoadFactor:负载因子,默认值0.75f。
怎么理解呢,就比如当前的容量大小为 100,当你存进第76个的时候,判断发现需要进行 resize 了,那就进行扩容,但是 HashMap 的扩容也不是简单的扩大点容量这么简单的。
扩容?它是怎么扩容的呢?
HashMap 的扩容 分为两步
- 1. 扩容:创建一个新的 Entry 空数组,长度是原数组的 2 倍。
- 2. ReHash:遍历原 Entry 数组,把所有的 Entry 重新 Hash 到新数组。
为什么要重新Hash呢,直接复制过去不香么?
小姐姐:是因为长度扩大以后,Hash 的规则也随之改变。
Hash 的公式 —-> index = HashCode(Key) & (Length - 1)
原来长度(Length)是 8 你位运算出来的值是 2 ,新的长度是16你位运算出来的值明显不一样了。
扩容前:
扩容后: 
说完扩容机制我们言归正传,为啥之前用头插法,java8之后改成尾插了呢?
我先举个例子吧,我们现在往一个容量大小为 2 的 put 两个值,负载因子是 0.75 是不是我们在 put 第二个的时候就会进行 resize?2*0.75 = 1 所以插入第二个就要 resize了
现在我们要在容量为 2 的容器里面用不同线程插入A,B,C,假如我们在 resize 之前打个短点,那意味着数据都插入了但是还没 resize 那扩容前可能是这样的。
我们可以看到链表的指向 A->B->C
Tip:A的下一个指针是指向B的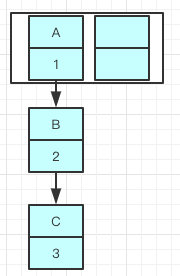
因为 resize 的赋值方式,也就是使用了单链表的头插入方式,同一位置上新元素总会被放在链表的头部位置,在旧数组中同一条 Entry 链上的元素,通过重新计算索引位置后,有可能被放到了新数组的不同位置上。
就可能出现下面的情况,大家发现问题没有?B的下一个指针指向了A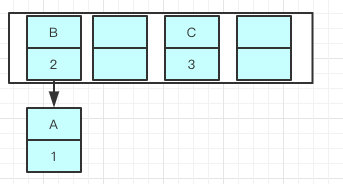
一旦几个线程都调整完成,就可能出现环形链表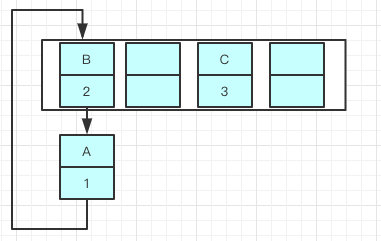
如果这个时候去取值,悲剧就出现了 — Infinite Loop。
小伙子有点东西呀,但是你都都说了头插是JDK1.7的那1.8的尾插是怎么样的呢?
因为 java8 之后链表有红黑树的部分,大家可以看到代码已经多了很多 if else 的逻辑判断了,红黑树的引入巧妙的将原本 O(n) 的时间复杂度降低到了O(logn)。
Tip:红黑树的知识点同样很重要,还是那句话不打没把握的仗,限于篇幅原因,我就不在这里过多描述了,以后写到数据结构再说吧,不过要面试的仔,还是要准备好,反正我是经常问到的。
使用头插会改变链表的上的顺序,但是如果使用尾插,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了。
就是说原本是A->B,在扩容后那个链表还是A->B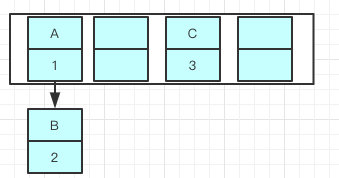
Java7 在多线程操作 HashMap 时可能引起死循环,原因是扩容转移后前后链表顺序倒置,在转移过程中修改了原来链表中节点的引用关系。
Java8在同样的前提下并不会引起死循环,原因是扩容转移后前后链表顺序不变,保持之前节点的引用关系。
那是不是意味着Java8就可以把HashMap用在多线程中呢?
我认为即使不会出现死循环,但是通过源码看到 put/get 方法都没有加同步锁,多线程情况最容易出现的就是:无法保证上一秒 put 的值,下一秒 get 的时候还是原值,所以线程安全还是无法保证。
那我问你HashMap的默认初始化长度是多少?
我记得我在看源码的时候初始化大小是**16**
你那知道为啥是16么?
在 JDK1.8 1<<4 就是 16,为啥用位运算呢?直接写16不好么?
这样是为了位运算的方便,位与运算比算数计算的效率高了很多,之所以选择16,是为了服务将 Key 映射到 index 的算法。
我前面说了所有的key我们都会拿到他的 hash,但是我们怎么尽可能的得到一个均匀分布的 hash 呢?
是的我们通过 Key 的 HashCode 值去做位运算。
我打个比方,key为”帅丙“的十进制为766132那二进制就是 10111011000010110100
我们再看下index的计算公式:index = HashCode(Key) & (Length- 1)

15 的的二进制是1111,那 10111011000010110100 &1111 十进制就是 4
之所以用位与运算效果与取模一样,性能也提高了不少!
那为啥用16不用别的呢?
因为在使用不是 2 的幂的数字的时候,Length-1 的值的所有二进制位全为1,这种情况下,index 的结果等同于HashCode 后几位的值(10111011000010110100 &1111)。只要输入的 HashCode 本身分布均匀,Hash 算法的结果就是均匀的。这是为了实现均匀分布。
为啥我们重写equals方法的时候需要重写 hashCode 方法呢? 你能用HashMap给我举个例子么?
因为在java中,所有的对象都是继承于 Object类。Ojbect 类中有两个方法 equals、hashCode,这两个方法都是用来比较两个对象是否相等的。
在未重写equals方法我们是继承了 object 的equals方法,那里的 equals 是比较两个对象的内存地址,显然我们 new 了 2 个对象内存地址肯定不一样
- 对于值对象,==比较的是两个对象的值
- 对于引用对象,比较的是两个对象的地址
大家是否还记得我说的 HashMap 是通过 key 的 hashCode 去寻找 index 的,那 index 一样就形成链表了,也就是说”帅丙“和”丙帅“的index都可能是2,在一个链表上的。
我们去 get 的时候,他就是根据 key 去 hash 然后计算出 index,找到了2,那我怎么找到具体的”帅丙“还是”丙帅“呢?用 equals!是的,所以如果我们对 equals 方法进行了重写,建议一定要对 hashCode 方法重写,以保证相同的对象返回相同的 hash 值,不同的对象返回不同的 hash 值。
不然一个链表的对象,你哪里知道你要找的是哪个,到时候发现 hashCode 都一样,这不是完犊子嘛。
你们是怎么处理HashMap在线程安全的场景么?
一般都会使用 HashTable 或者 ConcurrentHashMap,但是因为前者的并发度的原因基本上没啥使用场景了,所以存在线程不安全的场景我们都使用的是 ConcurrentHashMap。
HashTable我看过他的源码,很简单粗暴,直接在方法上锁,并发度很低,最多同时允许一个线程访问,ConcurrentHashMap 就好很多了,1.7和1.8有较大的不同,不过并发度都比前者好太多了。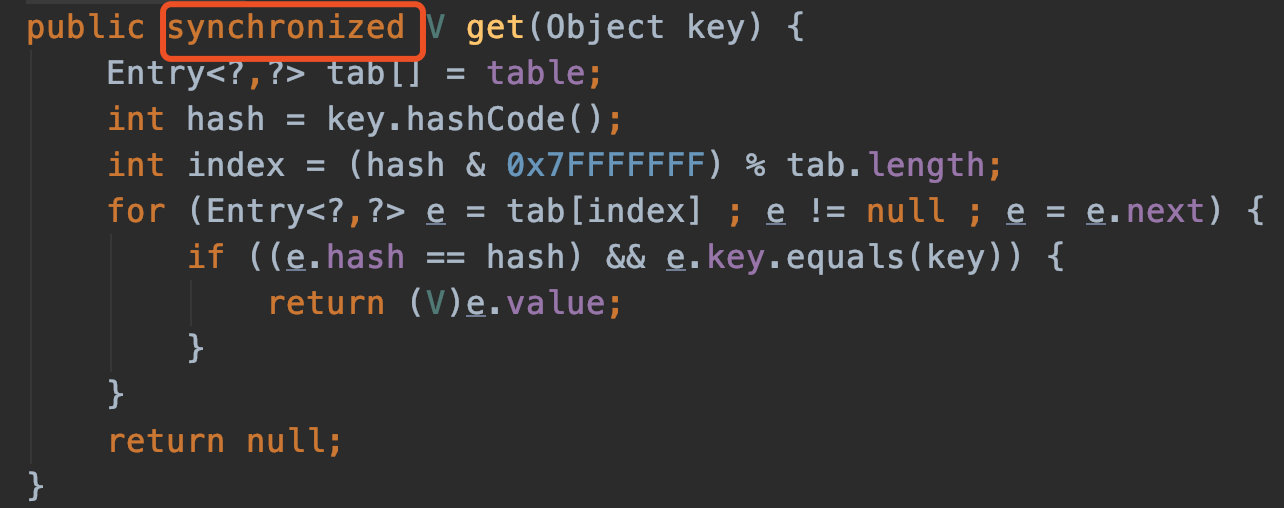
3. HashMap hash 和默认容量分析
在Java中,保存数据有两种比较简单的数据结构:数组和链表。数组的特点是:寻址容易,插入和删除困难;而链表的特点是:寻址困难,插入和删除容易。HashMap就是将数组和链表组合在一起,发挥了两者的优势,我们可以将其理解为链表的数组。在HashMap中,有两个比较容易混淆的关键字段:size 和 capacity ,这其中capacity 就是 Map的容量,而 size 我们称之为Map中的元素个数。简单打个比方你就更容易理解了:HashMap就是一个“桶”,那么容量(capacity)就是这个桶当前最多可以装多少元素,而元素个数(size)表示这个桶已经装了多少元素。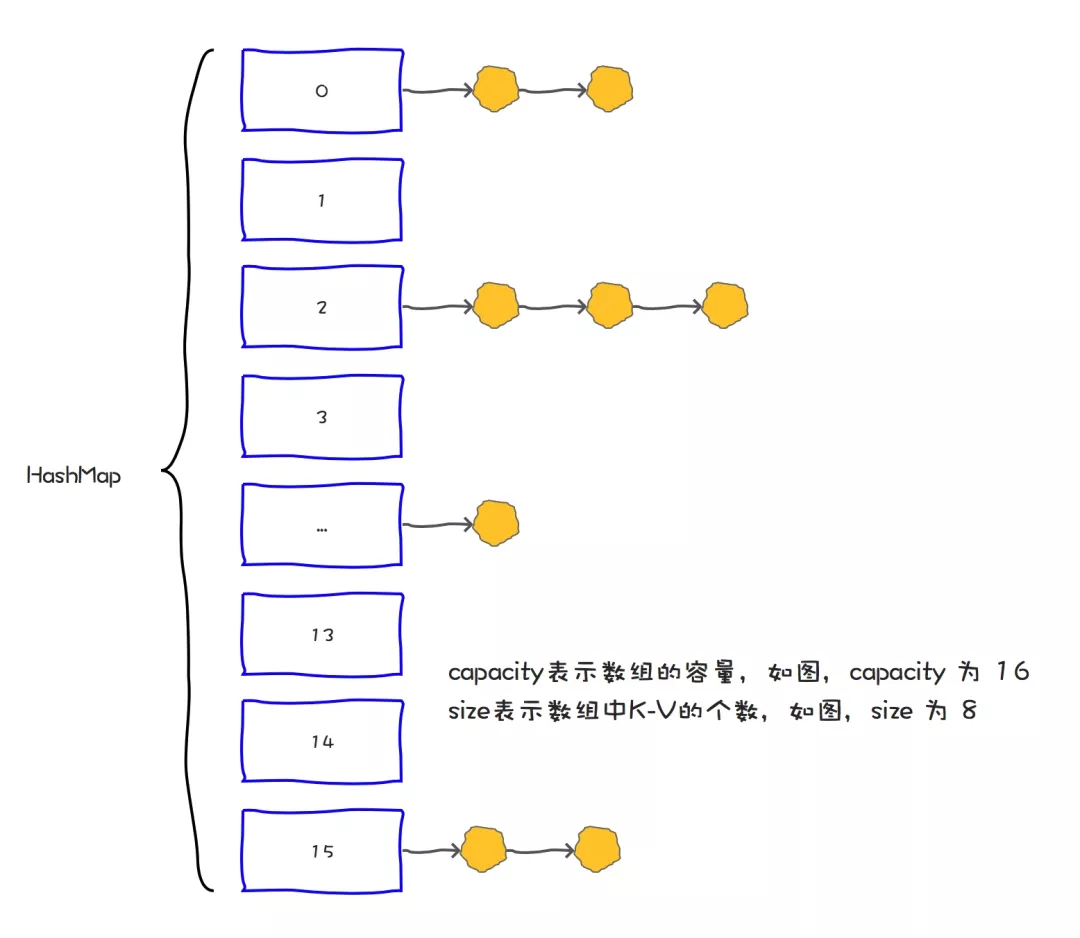
Map<String, String> map = new HashMap<String, String>();map.put("hollis", "hollischuang");Class<?> mapType = map.getClass();Method capacity = mapType.getDeclaredMethod("capacity");capacity.setAccessible(true);System.out.println("capacity : " + capacity.invoke(map));Field size = mapType.getDeclaredField("size");size.setAccessible(true);System.out.println("size : " + size.get(map));
输出结果:
capacity : 16、size : 1
上面我们定义了一个新的 HashMap,并向其中 put 了一个元素,然后通过反射的方式打印 capacity 和 size,其容量是16,已经存放的元素个数是1。通过前面的例子,我们发现了,当我们创建一个HashMap的时候,如果没有指定其容量,那么会得到一个默认容量为16的 Map,那么,这个容量是怎么来的呢?又为什么是这个数字呢?
3.1 容量与哈希
要想讲清楚这个默认容量的缘由,我们要首先要知道这个容量有什么用?我们知道,容量就是一个HashMap中”桶”的个数,那么,当我们想要往一个 HashMap 中 put 一个元素的时候,需要通过一定的算法计算出应该把他放到哪个桶中,这个过程就叫做哈希(hash),对应的就是 HashMap 中的 hash 方法。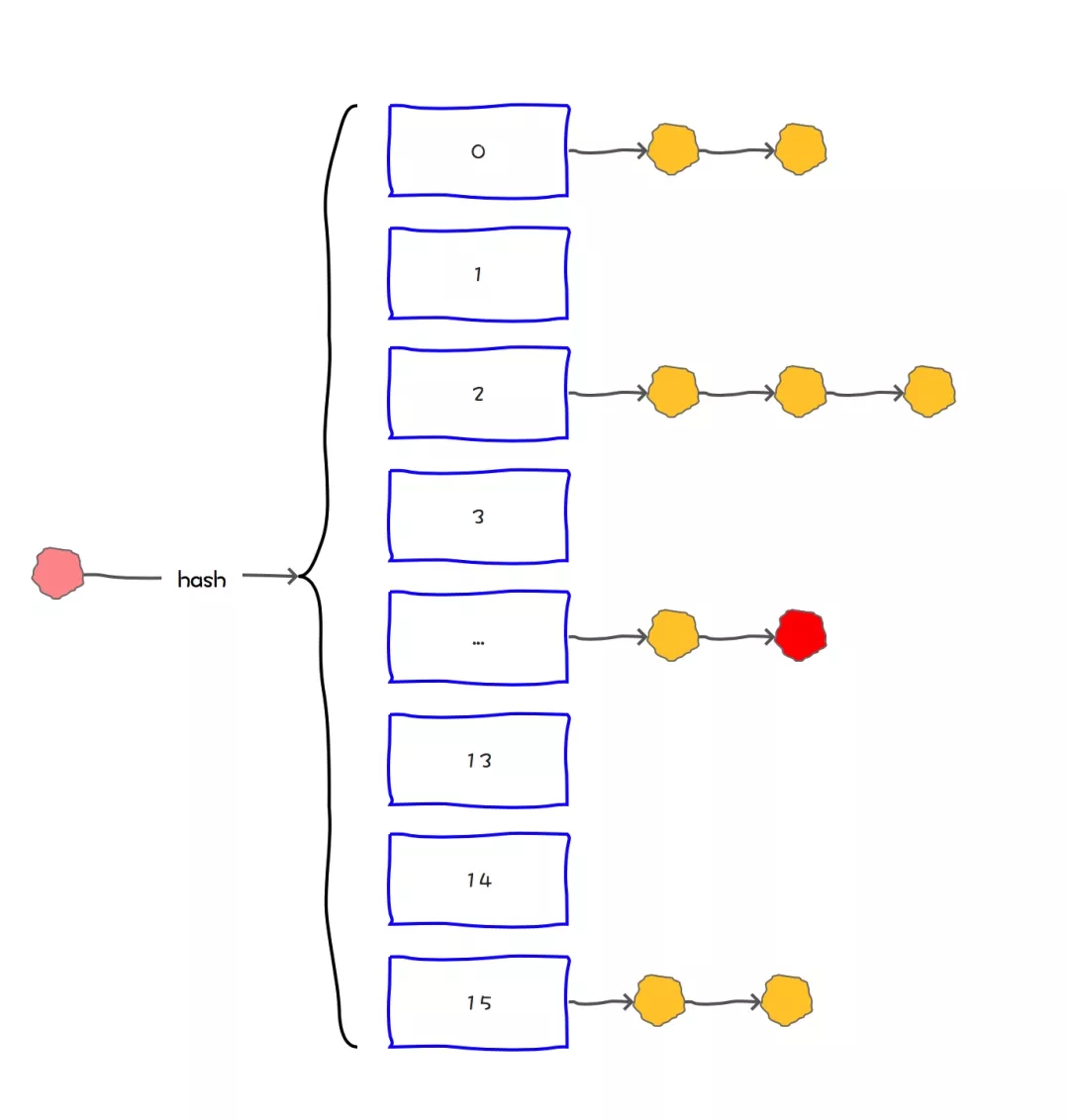
我们知道,hash 方法的功能是根据 Key 来定位这个 K-V 在链表数组中的位置的。也就是 hash 方法的输入应该是个 Object 类型的 Key,输出应该是个 int 类型的数组下标。如果让你设计这个方法,你会怎么做?其实简单,我们只要调用 Object 对象的 hashCode() 方法,该方法会返回一个整数,然后用这个数对 HashMap 的容量进行取模就行了。但是考虑到效率等问题,HashMap 的 hash 方法实现还是有一定的复杂的。
3.2 hash的实现
接下来就介绍下 HashMap 中 hash方法的实现原理。(下面部分内容参考自我的文章:全网把Map中的hash()分析的最透彻的文章,别无二家。具体实现上,由两个方法 int hash(Object k) 和 int indexFor(int h, int length)来实现。
hash: 该方法主要是将 Object 转换成一个整型。indexFor: 该方法主要是将hash生成的整型转换成链表数组中的下标。
为了聚焦本文的重点,我们只来看一下 indexFor 方法。我们先来看下Java 7(Java8 中虽然没有这样一个单独的方法,但是查询下标的算法也是和 Java 7 一样的)中该实现细节:
static int indexFor(int h, int length) {return h & (length-1);}
indexFor 方法其实主要是将 hashcode 换成链表数组中的下标。其中的两个参数 h 表示元素的 hashcode 值,length 表示 HashMap 的容量。那么 return h & (length-1)是什么意思呢?其实,他就是取模。Java 之所有使用位运算(&)来代替取模运算(%),最主要的考虑就是效率。
位运算(&)效率要比代替取模运算(%)高很多,主要原因是位运算直接对内存数据进行操作,不需要转成十进制,因此处理速度非常快。
那么,为什么可以使用位运算(&)来实现取模运算(%)呢?这实现的原理如下:
X % 2^n = X & (2^n – 1)
假设 n 为 3,则2^3 = 8,表示成2进制就是1000。2^3 -1 = 7 ,即0111。
此时 X & (2^3 – 1) 就相当于取X的2进制的最后三位数。从2进制角度来看,X / 8相当于 X >> 3,即把X右移3位,此时得到了X / 8的商,而被移掉的部分(后三位),则是X % 8,也就是余数。
上面的解释不知道你有没有看懂,没看懂的话其实也没关系,你只需要记住这个技巧就可以了。或者你可以找几个例子试一下。6 % 8 = 6 ,6 & 7 = 610 % 8 = 2 ,10 & 7 = 2
运算过程如下如: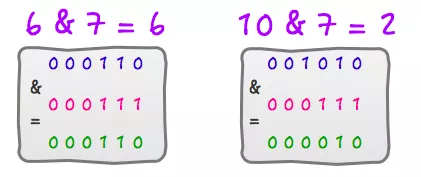
所以,return h & (length-1);只要保证 length 的长度是 2^n 的话,就可以实现取模运算了。
所以,因为位运算直接对内存数据进行操作,不需要转成十进制,所以位运算要比取模运算的效率更高,所以HashMap 在计算元素要存放在数组中的 index 的时候,使用位运算代替了取模运算。
之所以可以做等价代替,前提是要求 HashMap 的容量一定要是 2^n ,因为只有这样,X % 2^n = X & (2^n – 1) 才成立。
那么,既然是2^n ,为啥一定要是16呢?为什么不能是4、8或者 32 呢?
关于这个默认容量的选择,JDK并没有给出官方解释,笔者也没有在网上找到关于这个任何有价值的资料。(如果哪位有相关的权威资料或者想法,可以留言交流)根据作者的推断,这应该就是个经验值(Experience Value),既然一定要设置一个默认的2^n 作为初始值,那么就需要在效率和内存使用上做一个权衡。这个值既不能太小,也不能太大。太小了就有可能频繁发生扩容,影响效率。太大了又浪费空间,不划算。所以,16 就作为一个经验值被采用了。
在JDK 8中,关于默认容量的定义为: static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 ,其故意把16写成1<<4,就是提醒开发者,这个地方要是2的幂。 值得玩味的是: 注释中的 aka 16 也是1.8中新增的,
那么,接下来我们再来谈谈,HashMap 是如何保证其容量一定可以是 2^n 的呢?如果用户自己设置了的话又会怎么样呢?关于这部分,HashMap 在两个可能改变其容量的地方都做了兼容处理,分别是指定容量初始化时以及扩容时。
3.3 指定容量初始化
当我们通过 HashMap(int initialCapacity) 设置初始容量的时候,HashMap 并不一定会直接采用我们传入的数值,而是经过计算,得到一个新值,目的是提高 hash 的效率。(1->1、3->4、7->8、9->16)
在JDK 1.7 和 JDK 1.8 中,HashMap 初始化这个容量的时机不同。 JDK 1.8 中,在调用 HashMap 的构造函数定义 HashMap 的时候,就会进行容量的设定。 而在 JDK 1.7中,要等到第一次 put 操作时才进行这一操作。
看一下JDK是如何找到比传入的指定值大的第一个2的幂的:
int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
上面的算法目的挺简单,就是:根据用户传入的容量值(代码中的cap),通过计算,得到第一个比他大的2的幂并返回。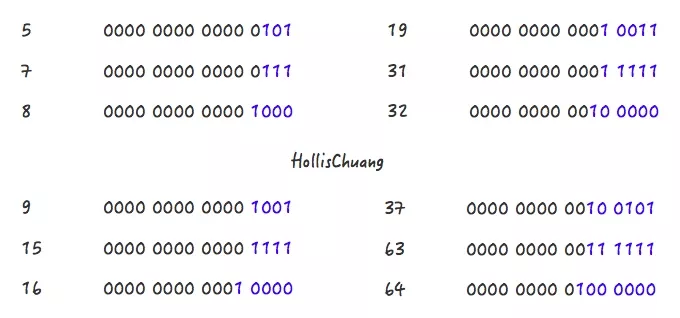
请关注上面的几个例子中,蓝色字体部分的变化情况,或许你会发现些规律。5->8、9->16、19->32、37->64都是主要经过了两个阶段。
Step 1,5->7 Step 2,7->8 Step 1,9->15 Step 2,15->16 Step 1,19->31 Step 2,31->32
对应到以上代码中,Step1:
n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;
对应到以上代码中,Step2:
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
Step 2 比较简单,就是做一下极限值的判断,然后把Step 1得到的数值+1。
Step 1 怎么理解呢?其实是对一个二进制数依次向右移位,然后与原值取或。其目的对于一个数字的二进制,从第一个不为0的位开始,把后面的所有位都设置成1。随便拿一个二进制数,套一遍上面的公式就发现其目的了:
1100 1100 1100 >>>1 = 0110 0110 01101100 1100 1100 | 0110 0110 0110 = 1110 1110 11101110 1110 1110 >>>2 = 0011 1011 10111110 1110 1110 | 0011 1011 1011 = 1111 1111 11111111 1111 1111 >>>4 = 1111 1111 11111111 1111 1111 | 1111 1111 1111 = 1111 1111 1111
通过几次无符号右移和按位或运算,我们把 1100 1100 1100 转换成了 1111 1111 1111 ,再把 1111 1111 1111 加 1,就得到了 1 0000 0000 0000,这就是大于 1100 1100 1100 的第一个 2 的幂。
好了,我们现在解释清楚了 Step 1 和 Step 2 的代码。就是可以把一个数转化成第一个比他自身大的 2 的幂。
但是还有一种特殊情况套用以上公式不行,这些数字就是2的幂自身。如果数字4套用公式的话。得到的会是 8,不过其实这个问题也被解决了,具体验证办法及JDK的解决方案见全网把Map中的hash()分析的最透彻的文章,别无二家。这里就不再展开了。
总之,HashMap 会根据用户传入的初始化容量,利用无符号右移和按位或运算等方式计算出第一个大于该数的 2 的幂。
3.4 扩容
除了初始化的时候会指定 HashMap 的容量,在进行扩容的时候,其容量也可能会改变。HashMap 有扩容机制,就是当达到扩容条件时会进行扩容。HashMap 的扩容条件就是当 HashMap 中的元素个数(size)超过临界值(threshold)时就会自动扩容。
在 HashMap 中,threshold = loadFactor * capacity。loadFactor 是装载因子,表示 HashMap 满的程度,默认值为 0.75f,设置成 0.75 有一个好处,那就是 0.75 正好是 3/4,而 capacity 又是 2 的幂。所以,两个数的乘积都是整数。
对于一个默认的 HashMap 来说,默认情况下,当其 size 大于 12(16*0.75) 时就会触发扩容。下面是 HashMap 中的扩容方法(resize)中的一段:
if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // double threshold}
从上面代码可以看出,扩容后的 table 大小变为原来的两倍,这一步执行之后,就会进行扩容后 table 的调整,这部分非本文重点,省略。
可见,当HashMap中的元素个数(size)超过临界值(threshold)时就会自动扩容,扩容成原容量的2倍,即从16扩容到32、64、128 …
所以,通过保证初始化容量均为 2 的幂,并且扩容时也是扩容到之前容量的2倍,所以,保证了 HashMap 的容量永远都是2的幂。
3.5 Hashmap 中的链表大小超过 8 个时会自动转化为红黑树,当链表小于 6 时重新变为链表,为啥呢?
根据泊松分布,在负载因子默认为 0.75 的时候,单个 hash 槽内元素个数为 8 的概率小于百万分之一,所以将7作为一个分水岭,等于 7 的时候不转换,大于等于 8 的时候才进行转换,小于等于 6 的时候就化为链表。
3.6 总结
- HashMap 作为一种数据结构,元素在 put 的过程中需要进行 hash 运算,目的是计算出该元素存放在 hashMap 中的具体位置。
- hash运算的过程其实就是对目标元素的 Key 进行 hashcode,再对Map的容量进行取模,而JDK 的工程师为了提升取模的效率,使用位运算代替了取模运算,这就要求Map的容量一定得是2的幂。
- 而作为默认容量,太大和太小都不合适,所以16就作为一个比较合适的经验值被采用了。
- 为了保证任何情况下Map的容量都是2的幂,HashMap在两个地方都做了限制。
- 首先是,如果用户制定了初始容量,那么HashMap会计算出比该数大的第一个2的幂作为初始容量。
- 另外,在扩容的时候,也是进行成倍的扩容,即4变成8,8变成16。
4. HashMap常见面试题:
- HashMap的底层数据结构?
- HashMap的存取原理?
- Java7和Java8的区别?
- 为啥会线程不安全?
- 有什么线程安全的类代替么?
- 默认初始化大小是多少?为啥是这么多?为啥大小都是2的幂?
- HashMap的扩容方式?负载因子是多少?为什是这么多?
- HashMap的主要参数都有哪些?
- HashMap是怎么处理hash碰撞的?
- hash的计算规则?

若有收获,就点个赞吧
0 人点赞
