代码:https://github.com/JohnGiorgi/DeCLUTR
参考:https://blog.csdn.net/TgqDT3gGaMdkHasLZv/article/details/108924221
Abstract
本文提出了一个简单并且易于实现的不对模型敏感的深度学习指标,并且该学习方法不需要任何标注的数据,损失函数为对比学习的损失函数加上MLM的损失函数。本文主要关注于对比学习在句子层面表征的应用(sentence embedding)。最近,受到CV领域的对比学习框架启发,本文提出了一个类似于BYOL利用正样本进行对比学习的NLP领域应用。这里注意的是编码器是共享权重,并非权值更新。
Model
我们的方法通过对比损失来学习文本表示,通过最大化从同一文档中附近采样的文本片段(跨度)之间的一致性来学习文本表示。如图所示,该方法包括以下组件: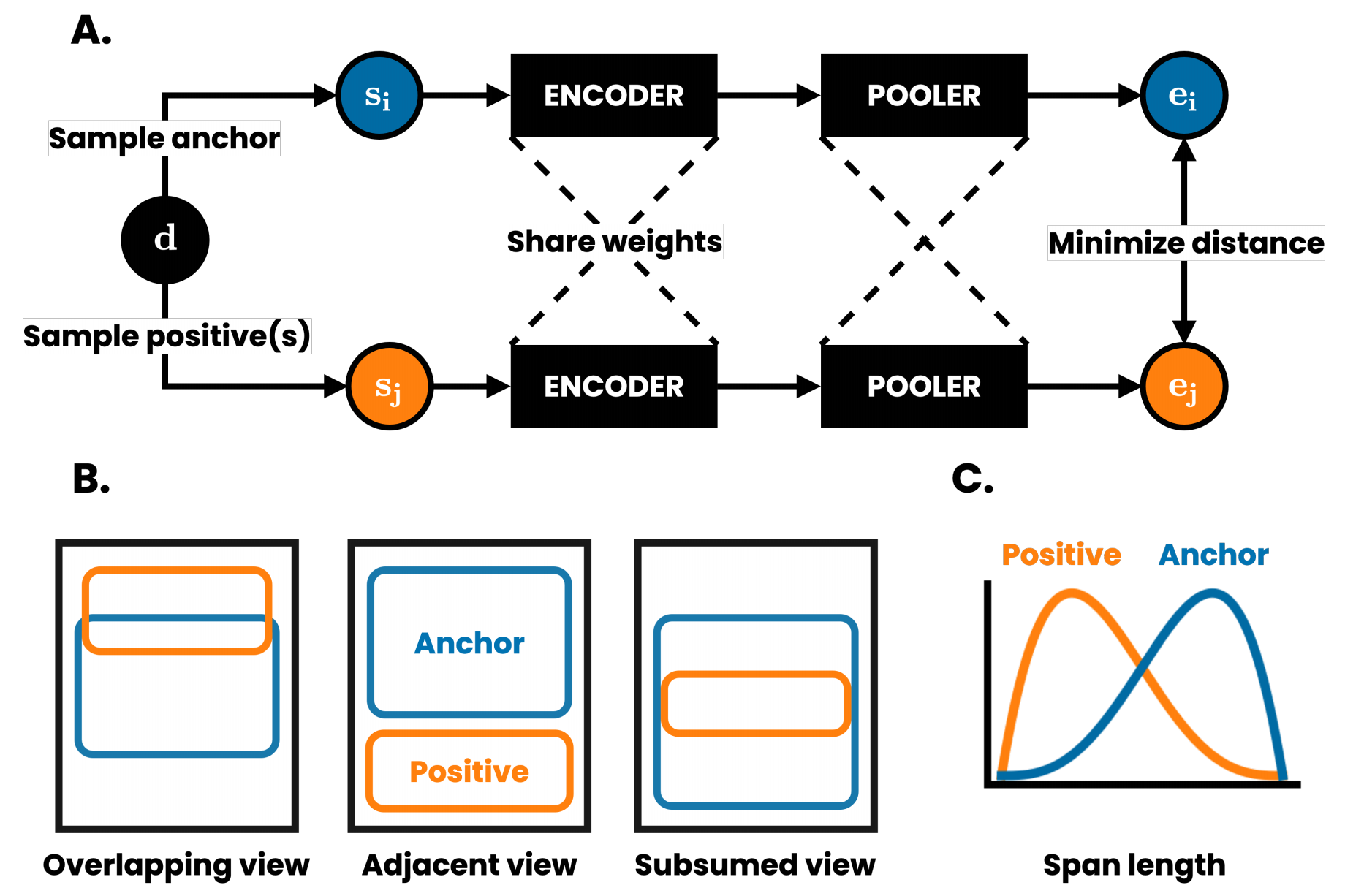

5. 在计算出对比学习的loss之后,再加入MLM的loss,对模型进行反向梯度传播更新参数。
- data loading step,在大小为n的batch中,从每个文档中随机抽取成对anchor-positive,设A为每个文档抽样的anchor-positive数量, P为每个anchor抽样的positive spans数量, i {1…… AN} 为任意anchor span的指标。我们把anchor和它对应的positive spans分别表示为 si 和si+pAN。抽样程序旨在最大限度地增加抽样语义相似的anchor-positive pair的机会。
- 编码器 f(·),它将输入区间中的每个标记映射到一个单词嵌入。这里用的是transformer-based language models。
- pooler g(·),它将
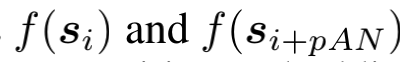 映射到定长嵌入
映射到定长嵌入 及其对应的均值正嵌入
及其对应的均值正嵌入
- 对比损失函数。


若有收获,就点个赞吧
0 人点赞
