Introduction
Multi-View在DGI的基础上,对全局和局部互信息进行了新的扩展。他的依据主要是《Learning Representations by Maximizing Mutual Information Across Views》中所提出的对DIM的改进方法:Augmented Multi-scale DIM (AMDIM)。这篇文章提出可以用不同的增强数据的方式,定义局部和全局的互信息损失。在DIM是一个视图生成的“Real”和“Fake”之间的对比,而在AMDIM则是在不同增强视图之间“Real”和“Fake”之间的对比,也就是更好地利用全局信息。
所谓Multi-View在图像上是各种图片增强的方式,MVRLG则提出将ADJ、PPR、Heat Kernel看作Graph不同的Multi-View。他的核心代码其实就是DGI的代码,区别在于定义了两个GCN,每个GCN对应一种View,衡量正负例的区别时,通过交换正例在不同View下的结果,同交换负例在不同View下的结果,协同训练节点的embedding,同时也可以生成Graph的表示,进行Graph Classification。
————————————————
版权声明:本文为CSDN博主「About Nature」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_27372101/article/details/113364126
Model
模型框架
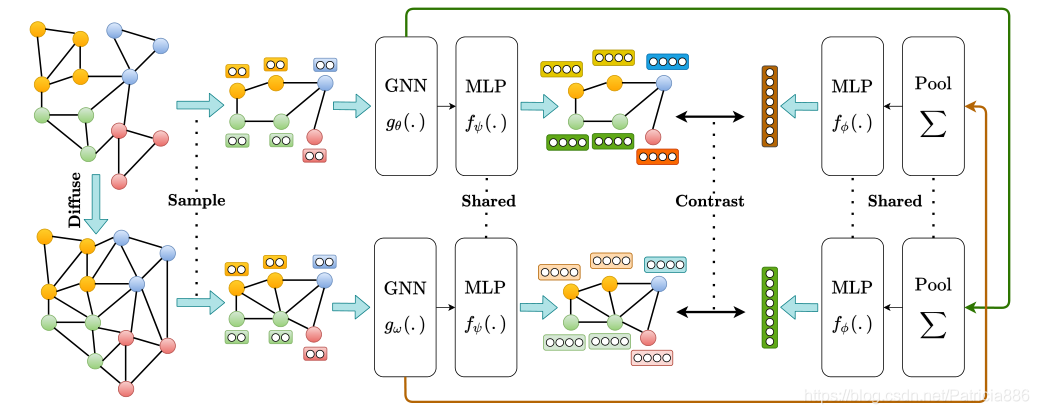
Multi-View的模型,从左侧开始,定义不同的diffusion(ADJ、PPR、Heat Kernel),并在diffusion上进行采样,并借用DGI的框架,构造两个GNN。通过对特征的重排,生成负例。交换两个GNN的输入,即文章提到的共享MLP,将一个diffusion下的输入作为另一个GNN的输入,再与交换的负例进行对比学习。
也就是先对图结构进行增强,然后采样,对采样后的子图进行编码,得到节点表示,将编码后的表示送入read out层,汇集成图表示。最后将节点表示与图表示进行对比,学习到更丰富的表征。
更详细的解读见:https://blog.csdn.net/Patricia886/article/details/114922324
虽然这篇文章的目的是Multi-View,但还是在两个View之间进行的实验,论文中提到,将View增加之后的效果有可能会变差。但直觉上说,每个view对应的是观察事件的一个角度,应该可以无限拓展。

若有收获,就点个赞吧
0 人点赞
