Introduction
知识蒸馏(knowledge distillation):通过补充来自教师模型(容量大、数据丰富)的额外反馈来改善学生模型的表现。
早期方法:通过最小化学生模型和教师模型输出预测分布的KL散度
存在问题:信息量有限,解释性弱(无法包含结构等重要信息),泛化性差。
Abstract
我们提出了Wasserstein(WCoRD),它利用了原始的Wasserstein距离和对偶形式的KD。这双重形式用于全局知识转移,产生一个对比学习目标,最大限度地提高教师和学生网络之间的互信息的下限。原始形式用于小批量的局部对比知识转移(允许在每个batch的多个实例之间进行匹配,而不是一对一匹配),有效匹配了教师网络和学生网络之间的特征分布。
Background
Knowledge Distillation
x-输入;y-独热标签;zT,zS 教师和学生模型在softmax层之前的logit representations
;
学生网络的训练涉及两个损失:
ρ-温度;α-平衡重量,教师网络是预先训练的;loss的第一项加强了标签监督,这在分类任务中通常通过交叉熵损失实现;loss的第二项是KL散度,为了让学生网络更像教师网络
Wasserstein Distance
Wasserstein Distance (也叫Earth Mover’s Distance,
or Optimal Transport Distance)
Method
我们提出了一个基于Wasserstein的KD学习框架,其中(i)对偶形式用于全局对比知识转移和(ii)原始形式用于本地对比知识转移
Global Contrastive Knowledge Transfer
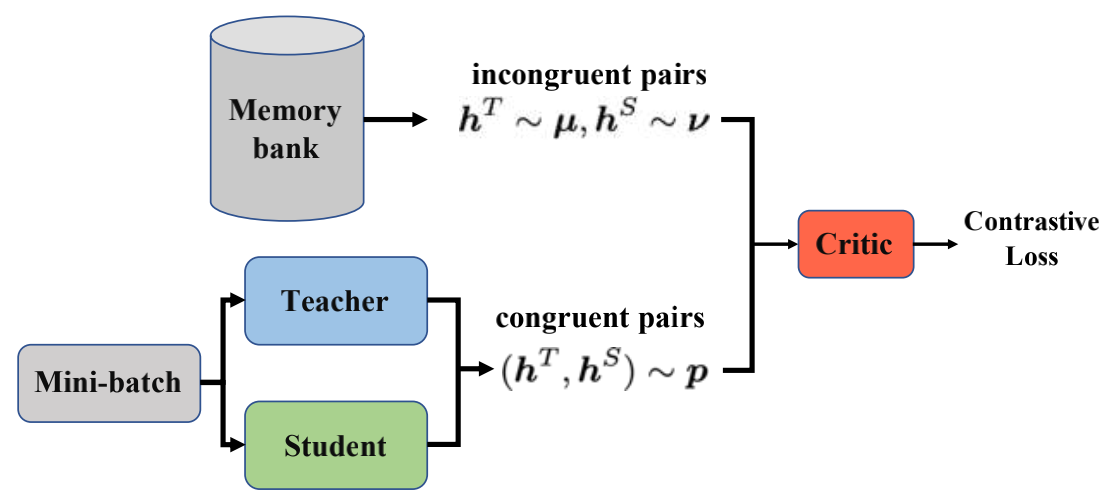
Global Contrastive Knowledge Transfer
(GCKT)
最大化特征表示hS, hT之间的交互信息(在logit层之前)
利用噪声对比估计Noise Contrastive Estimation (NCE)来近似MI


然后我们可以最大化(8)的右侧,以增加MI的下限。虽然q(η=1 | hT,hS)没有封闭形式,但神经网络g(称为参数φ的critic)可以用来估计一个同余对是来自联合分布还是边缘分布。这与GAN的鉴别器具有相似的作用。可以通过以下步骤学习critic g:
加入EM距离的双重形式之后:

Local Contrastive Knowledge Transfer


Unifying Global and Local Knowledge Transfer

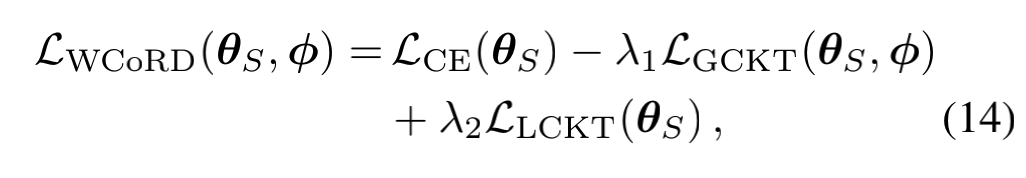

若有收获,就点个赞吧
0 人点赞
