论文:https://link.zhihu.com/?target=https%3A//arxiv.org/abs/2006.09882
自监督模型SwAV
Abstract
它将表征提取任务构建为一种「在线聚类」,保证同一张图像不同的增强结果编码之间的一致性。Swav 采用了与 AMDIM 相同的方法(仅仅使用最后的特征图),但是它不依赖于显式的成对特征比较,而是通过一组 K 个预先计算出的编码计算相似度。
实际上,这意味着 Swav 会生成 K 个聚类,对于每个编码的向量而言,它会对这些聚类进行比较,从而学习出新的表征,这份工作可以看做将 AMDIM 和论文「Unsupervised Learning byPredicting Noise」的思想进行了融合。
贡献:我们提出了一种可扩展的在线聚类损失,该算法在ImageNet上的性能提高了+2%,并且可以在大批量和小批量环境下工作,而无需大型内存库或momentum编码器。
•我们引入多裁剪策略以增加图像的视图数量,而无需计算或内存开销。我们观察到,在ImageNet上,这种策略在几种自监督方法上的一致性提高在2%到4%之间。
•将这两种技术贡献结合到一个模型中,我们使用标准ResNet在ImageNet上将自我监督的性能提高了+4.2%,并且在多个下游任务上优于受监督的ImageNet预训练。这是第一种不需要对特征进行微调的方法,也就是说,只在确定特征的基础上使用线性分类器。
Method
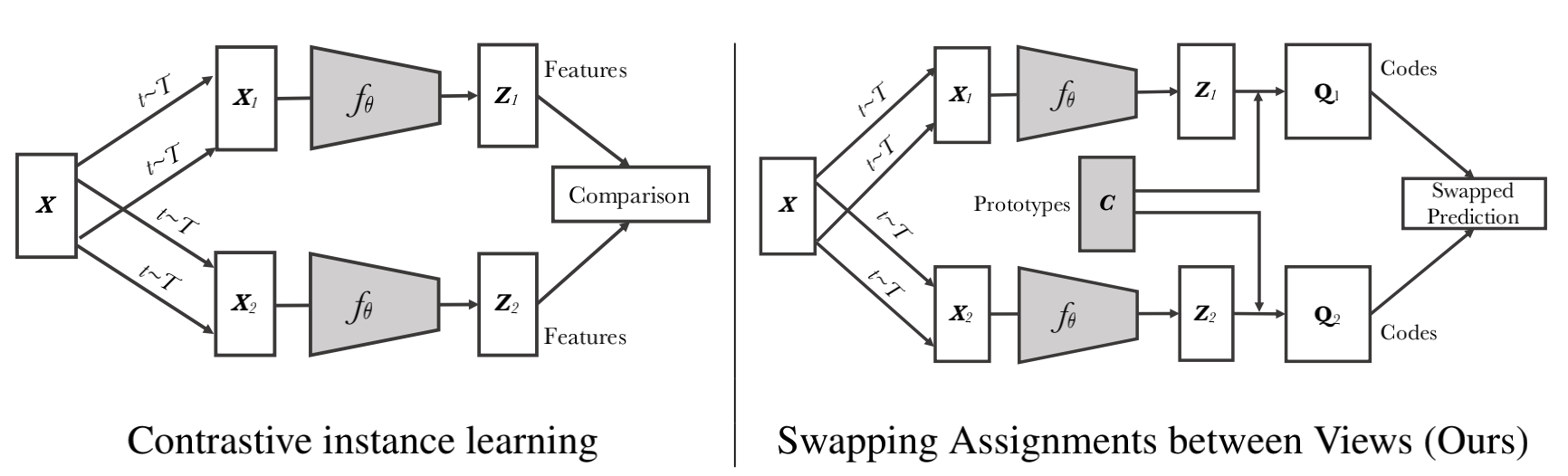
图1:对比实例学习(左)与SwAV(右)。在应用于实例分类的对比学习方法中,直接比较同一图像的不同变换的特征。在SwAV中,我们首先通过将特征分配给原型向量来获得“codes”。然后,我们解决了一个“swapped”预测问题,从一个数据增强视图获得的代码通过另一个视图进行预测。因此,SwAV不直接比较图像特征。Prototypes向量与ConvNet参数一起通过反向传播学习。

若有收获,就点个赞吧
0 人点赞
