2021-5-7
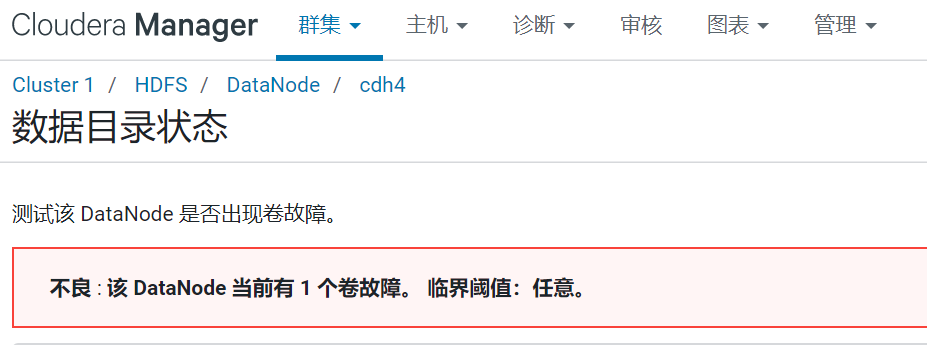
问题:cdh cm界面HDFS爆红:不良 : 该 DataNode 当前有 1 个卷故障。 临界阈值:任意。(Linux磁盘修复)
问题:CM报错卷故障
1.cm界面情况
- 报错卷故障
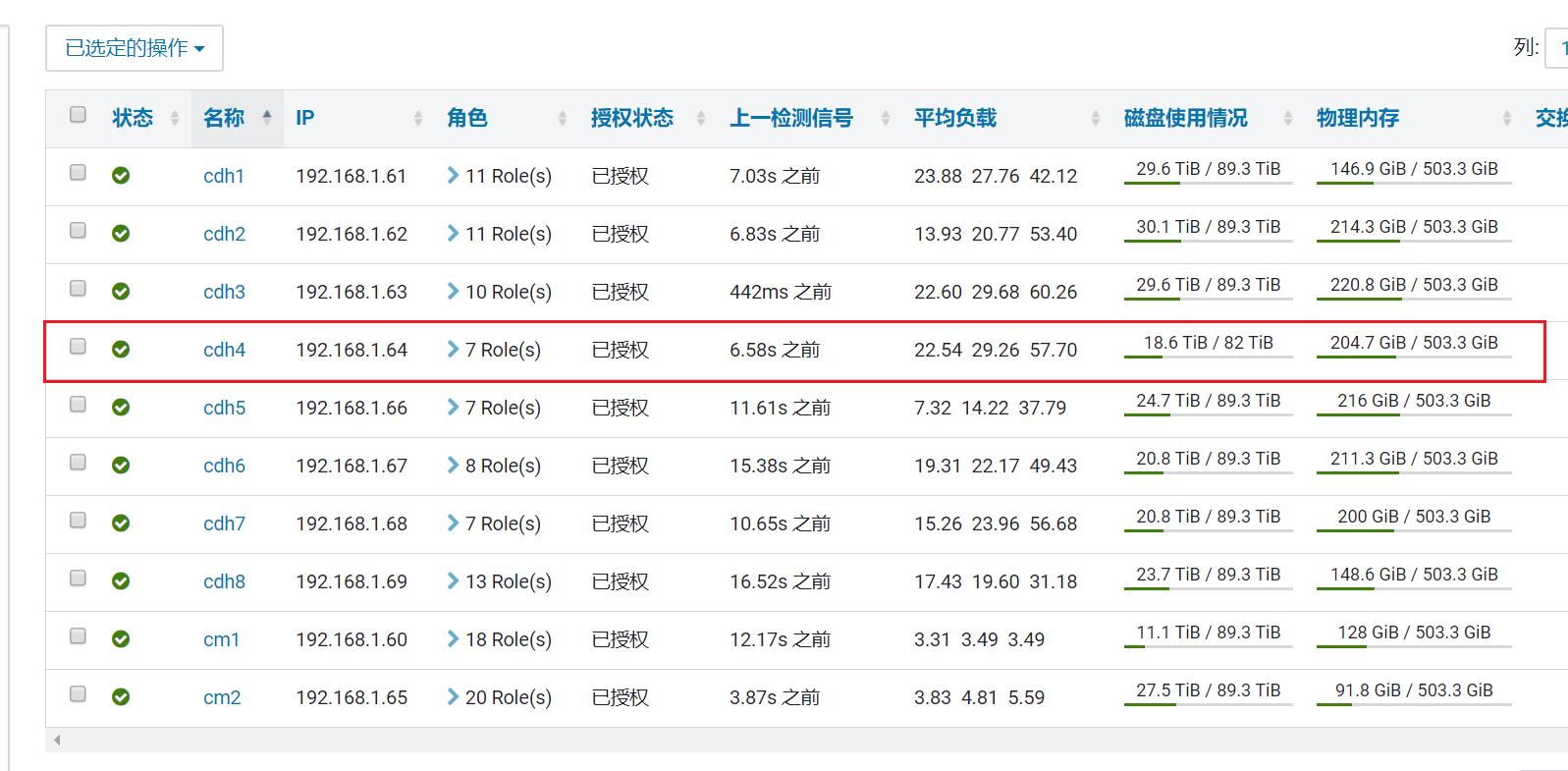
- 检查该节点,发现存储大小和其他节点不一致
2.Linux情况
- 目录无法访问

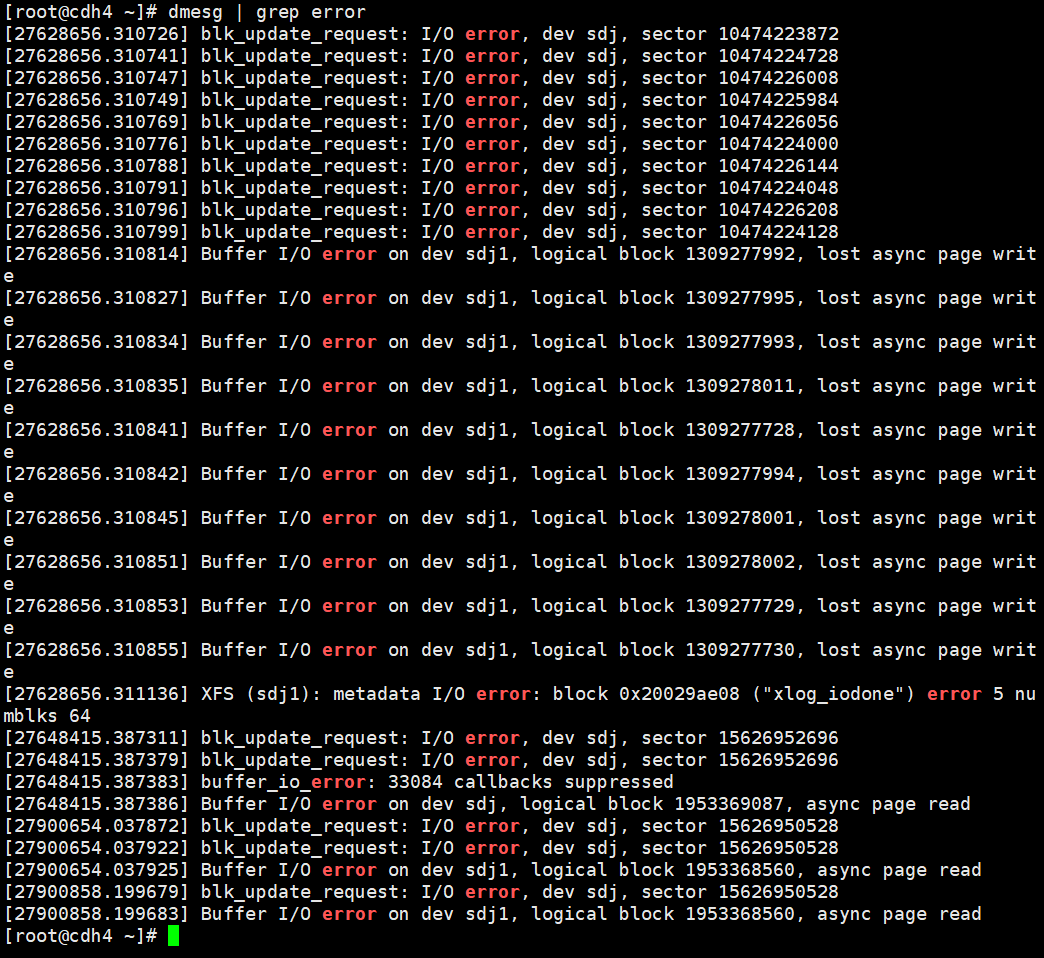
- dmesg检查发现错误
dmesg | grep error
解决办法
移除挂载
umount /data10 #可以移除挂载盘,或者移除挂载目录均可。
umount -vl /data10 # 如果出现目录忙,请加参数
df -TH查看磁盘的类型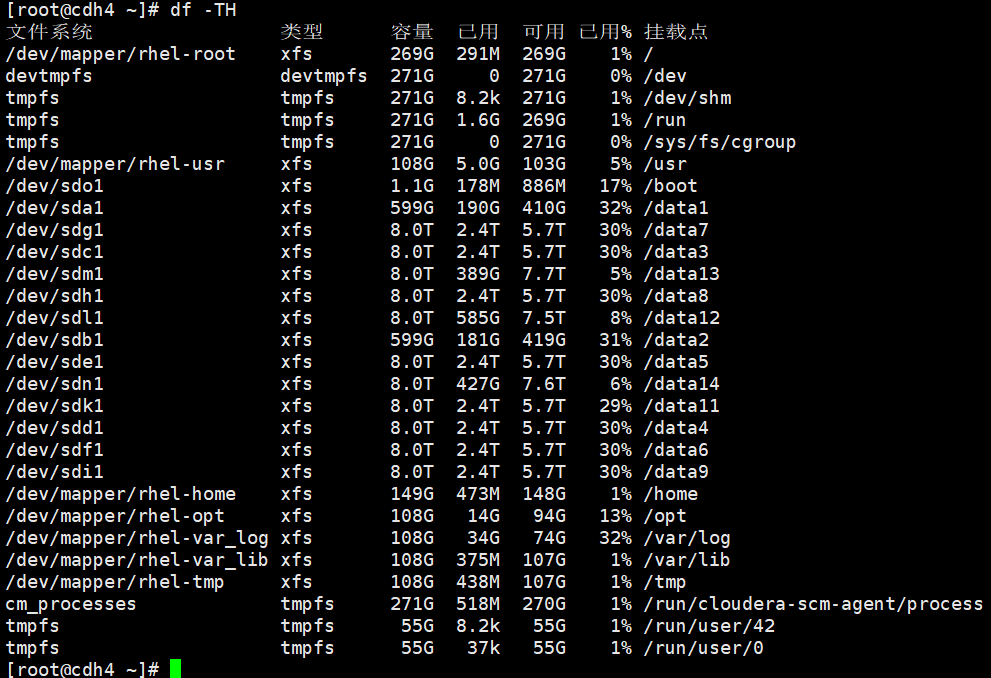
使用
fsck命令修复磁盘(ext3、ext4文件系统等)fsck -t ext3 -y /dev/sdj1
如果是
xfs文件系统系统,则使用xfs_repair命令修复xfs_repair /dev/sdj1
重新挂载
mount /dev/sdj1 /data10
2021-12-12
常用操作:检查HDFS块命令与修复丢失块
检查块:
sudo -u hdfs hdfs fsck /
检查对应哪些Block发生了损坏(显示具体的块信息和文件路径信息)
sudo -u hdfs hdfs fsck -list-corruptfileblocks
使用命令查看块信息,还可以查看更多详细信息:
sudo -u hdfs hdfs fsck xxx -files -locations -blocks -racks
对应参数的含义:
- files 文件分块信息,
- blocks 在带-files参数后才显示block信息
- locations 在带-blocks参数后才显示block块所在datanode的具体IP位置,
- racks 在带-files参数后显示机架位置
- 方式一:delete方式暴力删除
最终删除损坏块的文件,然后对应的业务系统数据重刷
命令:
sudo -u hdfs hdfs fsck / -delete
注:该命令仅仅只是删除损坏块所对应的文件,而不是删除损坏的那个块
如果仅仅删除损坏块对应的文件,那么对应的数据丢了多少我们是不知道的,如何去确保数据补回来呢? 这是需要思考的。 如果是日志类的数据,丢一点点是没有关系的,那就没事 如果对应的数据是业务数据,比如订单数据,那是不能丢的,数据重刷和维护都是需要报告的
- 方式二:debug方式优雅处理
手动修复Block的命令(最多重试10次):
hdfs debug recoverLease -path /blockrecover/bigdata.md -retries 10
这样做是基于这样的思考:1个block有对应的三个副本,其中一个副本损坏了,但是有另外两个副本存在,是可以利用另外两个副本进行修复的,因此我们可以使用debug命令进行修复
- 方式三:配置参数自动修复
在HDFS中实际上也可以配置块的自动修复的,当数据块损坏后,DataNode节点在执行directoryscan操作之前,都不会发现损坏directoryscan操作间隔6h进行
dfs.datanode.directoryscan.interval : 21600
在DataNode向NameNode进行blockreport之前,都不会恢复数据块;blockreport操作是间隔6h
dfs.blockreport.intervalMsec : 21600000
- 方法四:设置副本数
设置3个副本模式
sudo -u hdfs hadoop fs -setrep -R 3 /
如果副本数较多的话,会占用大量资源和时间。

若有收获,就点个赞吧
0 人点赞
