2021-5-1
问题:节点尝试创建太多动态分区时发生致命错误
1、异常描述:
- MR执行失败任务超过20%,进程结束。
- 节点尝试创建太多动态分区时发生致命错误。动态分区的最大数目由hive.exec.max配置单元.动态分区以及hive.exec.max配置单元.dynamic.partitions.pernode每个节点. 最大值设置为:100
- total number of created files now is 100385, which exceeds 100000. Killing the job.
2、异常截图: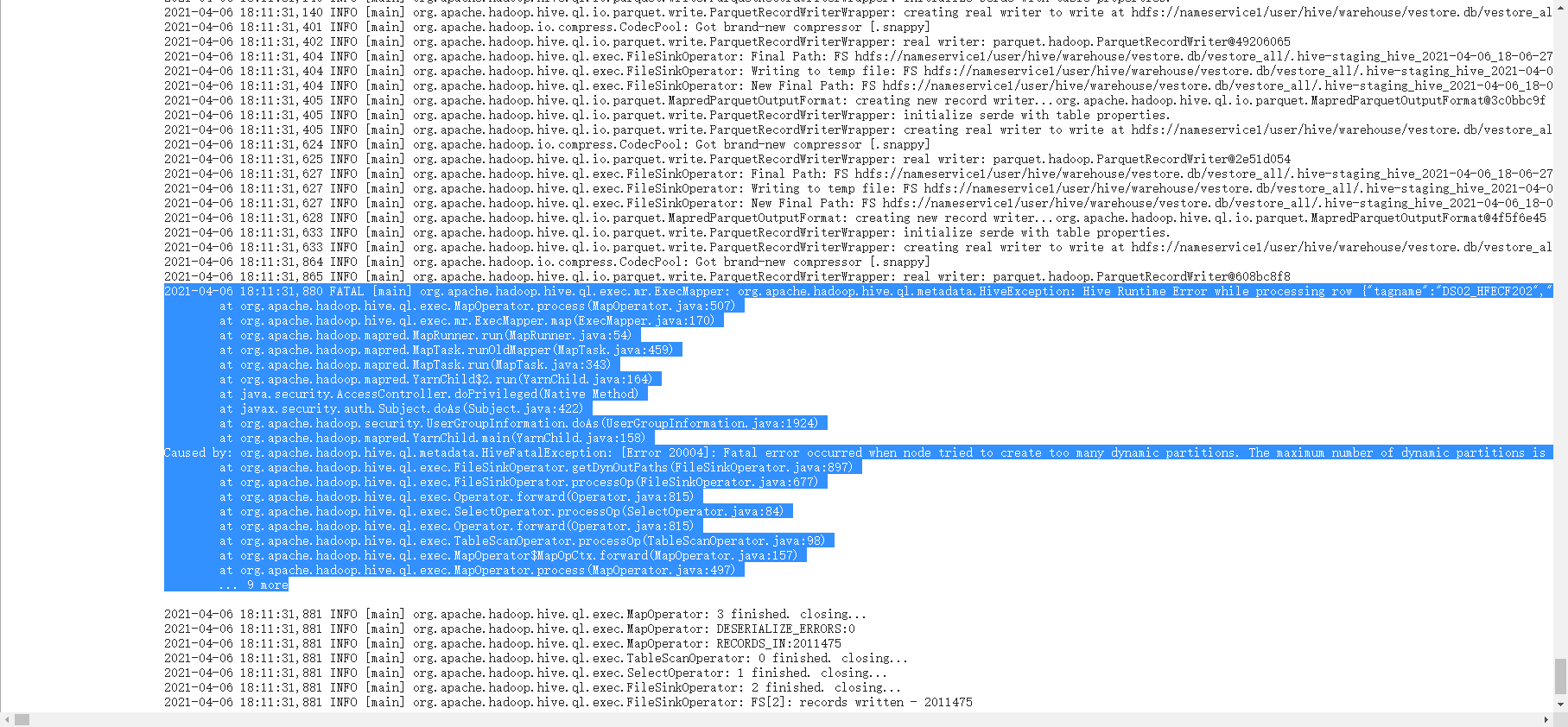
2021-04-06 18:11:31,880 FATAL [main] org.apache.hadoop.hive.ql.exec.mr.ExecMapper: org.apache.hadoop.hive.ql.metadata.HiveException: Hive Runtime Error while processing row {"tagname":"DS02_HFECF202","point_time":"2020-10-19 06:50:06.000","value_double":0.61538,"status":0}at org.apache.hadoop.hive.ql.exec.MapOperator.process(MapOperator.java:507)at org.apache.hadoop.hive.ql.exec.mr.ExecMapper.map(ExecMapper.java:170)at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:54)at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:459)at org.apache.hadoop.mapred.MapTask.run(MapTask.java:343)at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:422)at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1924)at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)Caused by: org.apache.hadoop.hive.ql.metadata.HiveFatalException: [Error 20004]: Fatal error occurred when node tried to create too many dynamic partitions. The maximum number of dynamic partitions is controlled by hive.exec.max.dynamic.partitions and hive.exec.max.dynamic.partitions.pernode. Maximum was set to: 100at org.apache.hadoop.hive.ql.exec.FileSinkOperator.getDynOutPaths(FileSinkOperator.java:897)at org.apache.hadoop.hive.ql.exec.FileSinkOperator.processOp(FileSinkOperator.java:677)at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:815)at org.apache.hadoop.hive.ql.exec.SelectOperator.processOp(SelectOperator.java:84)at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:815)at org.apache.hadoop.hive.ql.exec.TableScanOperator.processOp(TableScanOperator.java:98)at org.apache.hadoop.hive.ql.exec.MapOperator$MapOpCtx.forward(MapOperator.java:157)at org.apache.hadoop.hive.ql.exec.MapOperator.process(MapOperator.java:497)... 9 more

INFO : 2021-04-07 10:41:07,984 Stage-1 map = 100%, reduce = 26%, Cumulative CPU 697045.71 secINFO : 2021-04-07 10:41:42,345 Stage-1 map = 100%, reduce = 27%, Cumulative CPU 698726.2 secINFO : 2021-04-07 10:42:03,198 Stage-1 map = 100%, reduce = 28%, Cumulative CPU 700485.6 secINFO : 2021-04-07 10:42:24,093 Stage-1 map = 100%, reduce = 29%, Cumulative CPU 702572.46 secINFO : 2021-04-07 10:42:49,162 Stage-1 map = 100%, reduce = 30%, Cumulative CPU 705569.34 secERROR : [Fatal Error] total number of created files now is 100087, which exceeds 100000. Killing the job.INFO : MapReduce Total cumulative CPU time: 8 days 3 hours 59 minutes 29 seconds 340 msecERROR : Ended Job = job_1617708913766_0003 with errorsERROR : FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTaskINFO : MapReduce Jobs Launched:INFO : Stage-Stage-1: Map: 5366 Reduce: 1099 Cumulative CPU: 705569.34 sec HDFS Read: 1538438367542 HDFS Write: 117851554854 FAILINFO : Total MapReduce CPU Time Spent: 8 days 3 hours 59 minutes 29 seconds 340 msecINFO : Completed executing command(queryId=hive_20210407095757_325032e7-7ce2-4355-9f3d-5ef53b593f51); Time taken: 2759.992 seconds
3、解决方案:
3.1 方法一:解决Hive创建文件数过多的问题
今天将临时表里面的数据按照天分区插入到线上的表中去,出现了Hive创建的文件数大于100000个的情况,我的SQL如下:
insert into table vestore_all partition(year,mounth,day) select trim(tagname),from_unixtime(unix_timestamp(point_time),'yyyy-MM-dd HH:mm:ss'),cast(value_double as double),cast(status as int),from_unixtime(unix_timestamp(point_time),'yyyy'),from_unixtime(unix_timestamp(point_time),'MM'),from_unixtime(unix_timestamp(point_time),'dd') from vestore_tmp;
vestore_tmp表里面一共有1435G左右的数据,一共可以分成10*31=310个分区,SQL运行的时候创建了5366个Mapper,0个Reducers。程序运行到一般左右的时候出现了以下的异常,并最终导致了SQL的运行失败。
[Fatal Error] total number of created files now is 100385, which exceeds 100000. Killing the job.
这个错误的原因是因为Hive对创建文件的总数有限制(hive.exec.max.created.files),默认是100000个,而这个SQL在运行的时候每个Map都会创建310个文件,对应了每个分区,所以这个SQL总共会创建5366 * 310 = 1663460个文件,运行中肯定会出现上述的异常。为了能够成功地运行上述的SQL,最简单的方法就是加大hive.exec.max.created.files参数的设置。
在执行插入数据到分区时,添加参数设置:
set hive.exec.dynamic.partition=true;set hive.exec.dynamic.partition.mode=nonstrict;# set hive.exec.max.dynamic.partitions.pernode=10000;# set hive.exec.max.dynamic.partitions=10000;set hive.exec.max.created.files=2000000;
但是这有个问题,这会导致在iteblog中产生大量的小文件,因为vestore_tmp表的数据就有1435G左右,那么平均每个文件的大小=1435G*1024/1663460= 0.0883363591550142MB,可想而知,160多万个这么小的小文件对Hadoop来说是多么不好。那么有没有好的办法呢?有!
我们可以将day相同的数据放到同一个Reduce处理,这样最多也就产生31个文件,将day相同的数据放到同一个Reduce可以使用DISTRIBUTE BY day实现,所以修改之后的SQL如下:
insert into table vestore_all partition(year,mounth,day) select trim(tagname),from_unixtime(unix_timestamp(point_time),'yyyy-MM-dd HH:mm:ss'),cast(value_double as double),cast(status as int),from_unixtime(unix_timestamp(point_time),'yyyy'),from_unixtime(unix_timestamp(point_time),'MM'),from_unixtime(unix_timestamp(point_time),'dd') from vestore_tmp DISTRIBUTE BY day;
修改完之后的SQL运行良好,并没有出现上面的异常信息,但是这里也有个问题,因为这31个分区的数据分布很不均匀,有些Reduce的数据有100多G,而有些Reduce只有几G,直接导致了这个SQL运行的速度很慢!
能不能将1435G多的数据均匀的分配给Reduce呢?可以!我们可以使用DISTRIBUTE BY rand()将数据随机分配给Reduce,这样可以使得每个Reduce处理的数据大体一致。我设定每个Reduce处理3G的数据,对于1435G多的数据总共会起478左右的Reduces,修改的SQL如下:
set hive.exec.dynamic.partition=true;set hive.exec.dynamic.partition.mode=nonstrict;set hive.exec.max.dynamic.partitions.pernode=10000;set hive.exec.max.dynamic.partitions=10000;set hive.exec.max.created.files=200000;set hive.exec.reducers.bytes.per.reducer=3221225472;insert into table vestore_all partition(year,mounth,day) select trim(tagname),from_unixtime(unix_timestamp(point_time),'yyyy-MM-dd HH:mm:ss'),cast(value_double as double),cast(status as int),from_unixtime(unix_timestamp(point_time),'yyyy'),from_unixtime(unix_timestamp(point_time),'MM'),from_unixtime(unix_timestamp(point_time),'dd') from vestore_tmp DISTRIBUTE BY rand();
这个SQL运行的时间很不错,而且生产的文件数量为Reduce的个数分区的个数(287310),≈9W个文件。
2021-5-2
问题:总分配超过堆内存的50.00%(1,431,830,528字节)将131个写入器的行组大小扩展为8.14%
异常详情: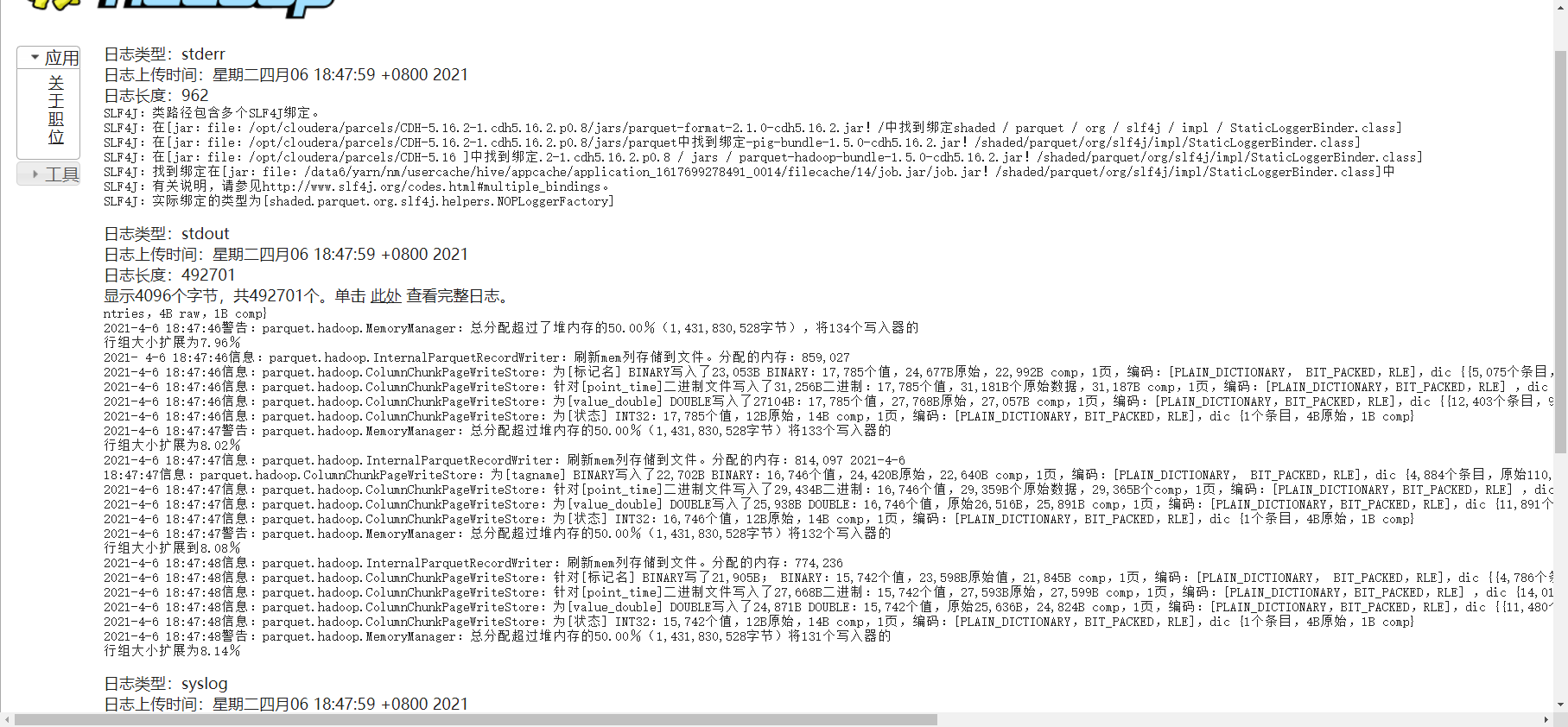
解决方案:
- 修改增加ResourceManager最大容器内存:yarn.scheduler.maximum-allocation- mb=32GB
- 修改增加NodeManager容器内存:yarn.nodemanager.resource.memory-mb=80GB
2021-5-3
问题:HIVE SQL执行时候报return code 2错误解决方案
18/07/29 00:53:04 ERROR operation.Operation: Error running hive query:org.apache.hive.service.cli.HiveSQLException: Error while processing statement: FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTaskat org.apache.hive.service.cli.operation.Operation.toSQLException(Operation.java:374)at org.apache.hive.service.cli.operation.SQLOperation.runQuery(SQLOperation.java:180)at org.apache.hive.service.cli.operation.SQLOperation.access$100(SQLOperation.java:72)at org.apache.hive.service.cli.operation.SQLOperation$2$1.run(SQLOperation.java:232)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:415)at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1693)at org.apache.hive.service.cli.operation.SQLOperation$2.run(SQLOperation.java:245)at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)at java.util.concurrent.FutureTask.run(FutureTask.java:262)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)at java.lang.Thread.run(Thread.java:745)
目前具体报错原因未知,可在执行sql语句前加上这句解决上面问题:
set hive.support.concurrency=false;
2021-5-31
问题:hive2连接但无法使用,show database、show tables报错
报错信息:Error: Error running query: j ava. lang . NoClassDefFoundError: Could not initialize class org . apache . at las .hive . hook .HiveHook ( state=,code= 0)
解决方式:将atlas配置文件复制到最近的一个hiveserver2运行配置服务
如果还是无效,重启该节点的hiveserver2服务,将配置文件复制到最新的运行配置目录下。
2021-07-12
问题:无法插入带分区的hive
报错:AnalysisException: Not enough partition columns mentioned in query. Missing columns are: splittime
原因:分区未指定
解决:指定partiton字段
INSERT INTO dcs_wtr31_bakuppartition(splittime)SELECT * FROM realtimedcs.wtr31;
2021-11-15
问题:Hive\Impala\Kudu无法支持中文
解决:修改MySQL中元数据库的表字段字符集。
修改数据库注释,支持中文表示:
ALTER TABLE DBS MODIFY COLUMN `DESC` VARCHAR (4000) CHARACTER SET utf8;FLUSH PRIVILEGES;
修改表名注释,支持中文表示
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;FLUSH PRIVILEGES;
修改分区参数,支持分区建用中文表示
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;FLUSH PRIVILEGES;
修改表注释字符集
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;FLUSH PRIVILEGES;
修改字段注释字符集
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;FLUSH PRIVILEGES;

若有收获,就点个赞吧
0 人点赞
