关键词:缓存,分布式,一致性哈希,数据倾斜,缓存雪崩
最近在学习 groupcache 和 geecache,按照 geecache 的源码敲了一下,很有收获,许多之前感觉比较抽象的概念经过落地实现后,才真正的觉得自己懂了。希望再用本文进行一遍总结。github-mycache
1. 分布式缓存
协同工作
对于开销很大的数据请求操作,将第一次请求的数据暂存,之后遇到相同的请求,就直接返回暂存的数据,由此来提升数据获取的效率,这个就是缓存的基本概念。比如第二次打开相同的网页会更快,就是因为浏览器或者 CDN 有网页资源的缓存。
在设计一个缓存的时候,要解决几个问题:
- 淘汰策略。缓存大小是有限制的,达到上限后如何对缓存中的数据进行淘汰?根据局部性原理,最近不使用的,未来也大概率不使用,所以一种比较好的策略就是使用 LRU,优先删除最近使用少的数据。
- 并发控制。并发访问缓存的时候,对于修改操作需要用锁来保证数据安全。
- 水平拓展。单台机器资源有限,现在大部分场景都是采用分布式来提高总体性能,增加多台机器来执行相同的功能就是水平拓展。相对应的,垂直拓展就是指提升当前机器的性能,如增加带宽、存储等。
对于分布式,我之前概念非常模糊,认为是多台机器之间协同工作就是分布式。这种理解比较泛了,所以我冥冥之中感觉机器应该会有一个特殊标识,这样相互之间就会辨别,哈哈就是一种似懂非懂的感觉。现在我进一步理解为:分布式应该是多进程之间协同工作。真正工作的是进程,相互通信的也是进程,这样就很容易想到使用 RPC 或者 HTTP 协议等网络协议来通信。这里,我曾经构想的“特殊标识”,实际就是 IP 地址和端口号。
所以,一个分布式节点可以看作是一个进程,向外提供一个网络接口,通过网络通信来协同工作。分布式缓存的大体工作流程如下: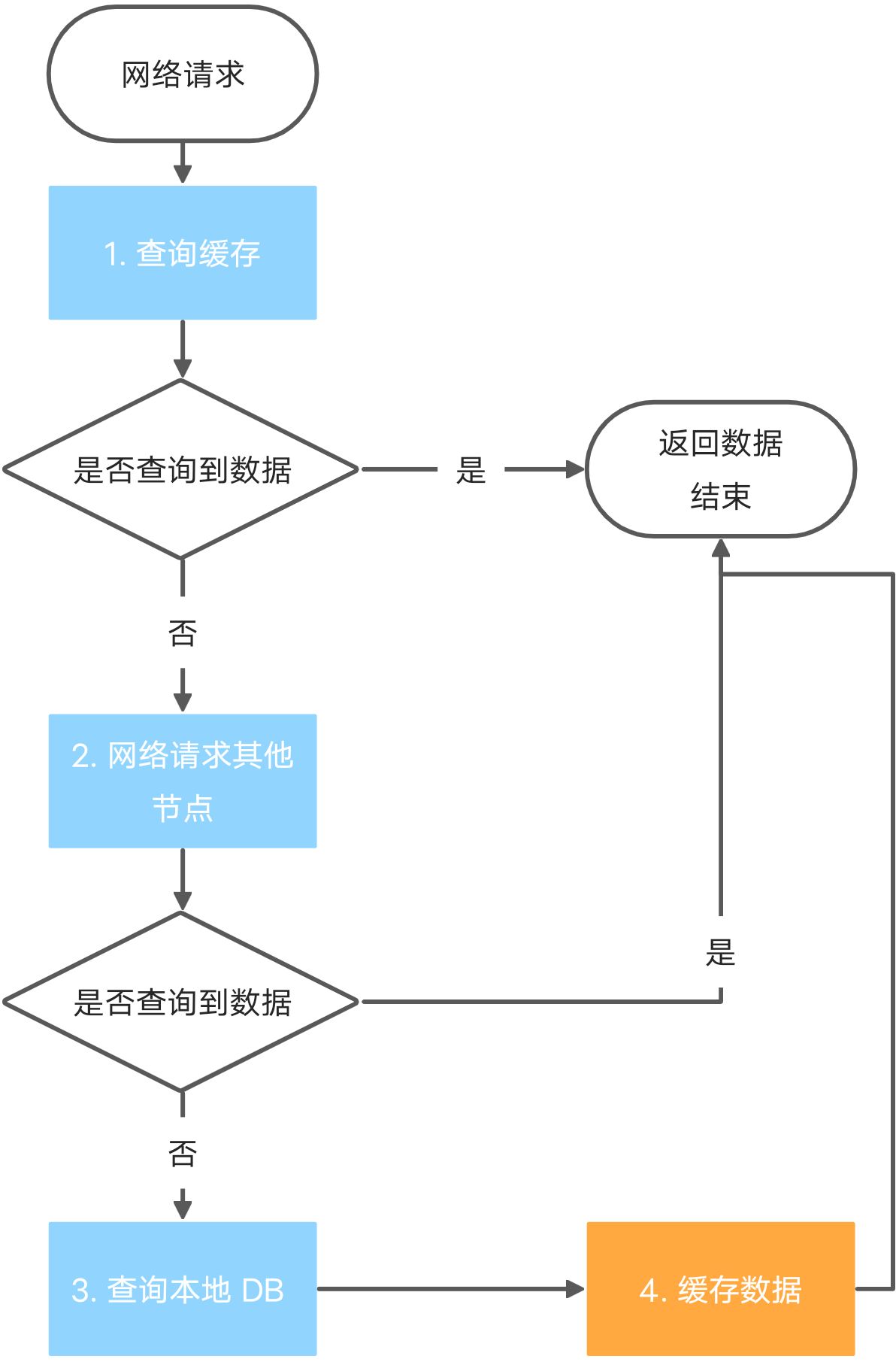
可以发现,只有在查询本地 DB 的时候,才会将新数据暂存到缓存中,而从其他节点获取到的数据则不用!因为分布式的目的就是将不同的 key 缓存在不同的节点上,增加总的吞吐量。如果从其他节点获取到的数据都备份一次,那么每一个节点上的都缓存了相同的数据,就失去意义了。应该将所有的节点视作一个总的缓存,例如,每一个节点能够缓存 1G 的数据,那么 4 个节点理论上可以缓存 4G 的不同数据。但对于热点数据,这种拷贝还是有意义的,可以另作设计。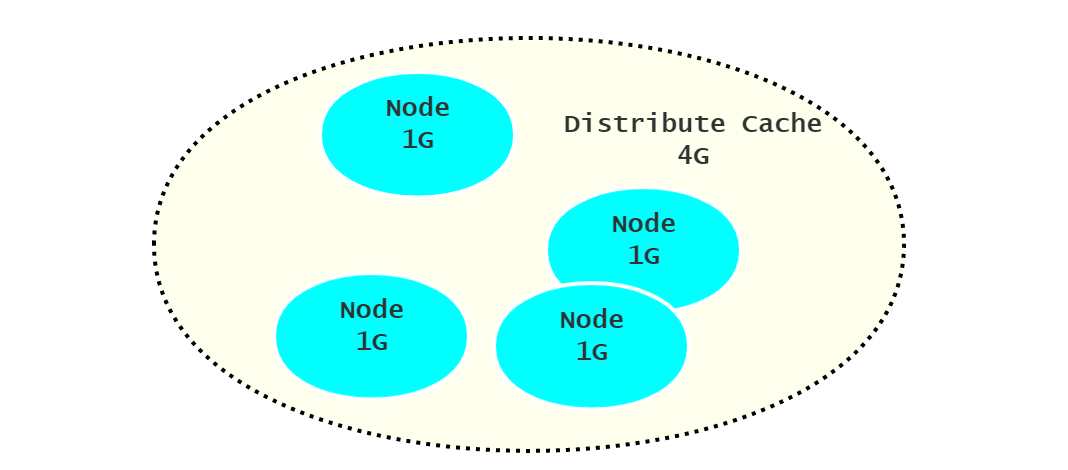
2. 一致性哈希
定位节点
既然采用分布式架构,那么就不得不知道一致性哈希了。从工作流程可以知道,一个节点没有存储缓存值时,需要向其他节点请求数据,那么向谁请求数据呢?
一种方式是随机选取,这意味着多次请求到同一个节点是一个小概率事件。例如有节点 1~10,那么第一次请求到节点 1 的概率为 1/10,第二次仍然是 1/10,但是有 9/10 的概率选择到了其他节点,这就意味着需要再次从数据源获取数据。这种方式,一是缓存效率低下,二是各个节点存储了许多相同的数据,浪费了缓存的空间。
第二种方式就是哈希,对 key 值进哈希运算后对总数取余,这样任何一个节点任意时刻,只要是请求相同的 key 都会定位到同一个节点。这样就有效地提高了解决了随机选取出现的问题。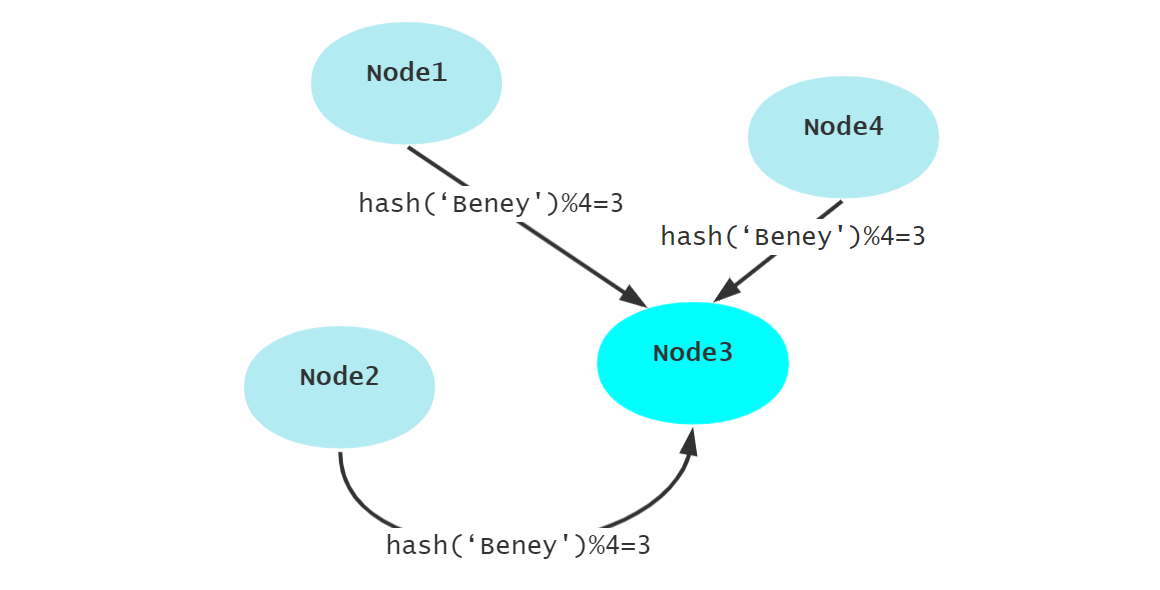
但是,简单地求哈希解决了缓存的性能问题,却没有考虑节点数目变动的问题。无论是节点增加或是减少,都会导致取余的值改变,在节点比较多的情况下,就容易导致大量的缓存失效,引发大量的查询数据源操作。缓存雪崩就是指大量缓存失效,造成 DB 压力骤增。故进一步出现了一致性哈希,来解决节点选取的问题。
2.1 算法原理
一致性哈希,将 key 的哈希值映射到 32 位的空间中,所有的这些位置逻辑上是一个环,首尾相连。
- 每一个节点占用环上的一个位置。
- 请求 key 时,计算 key 的哈希值定位到环上的某个位置,该位置顺序向后第一个节点,就是要选择的节点。
结合下图的例子来具体看看: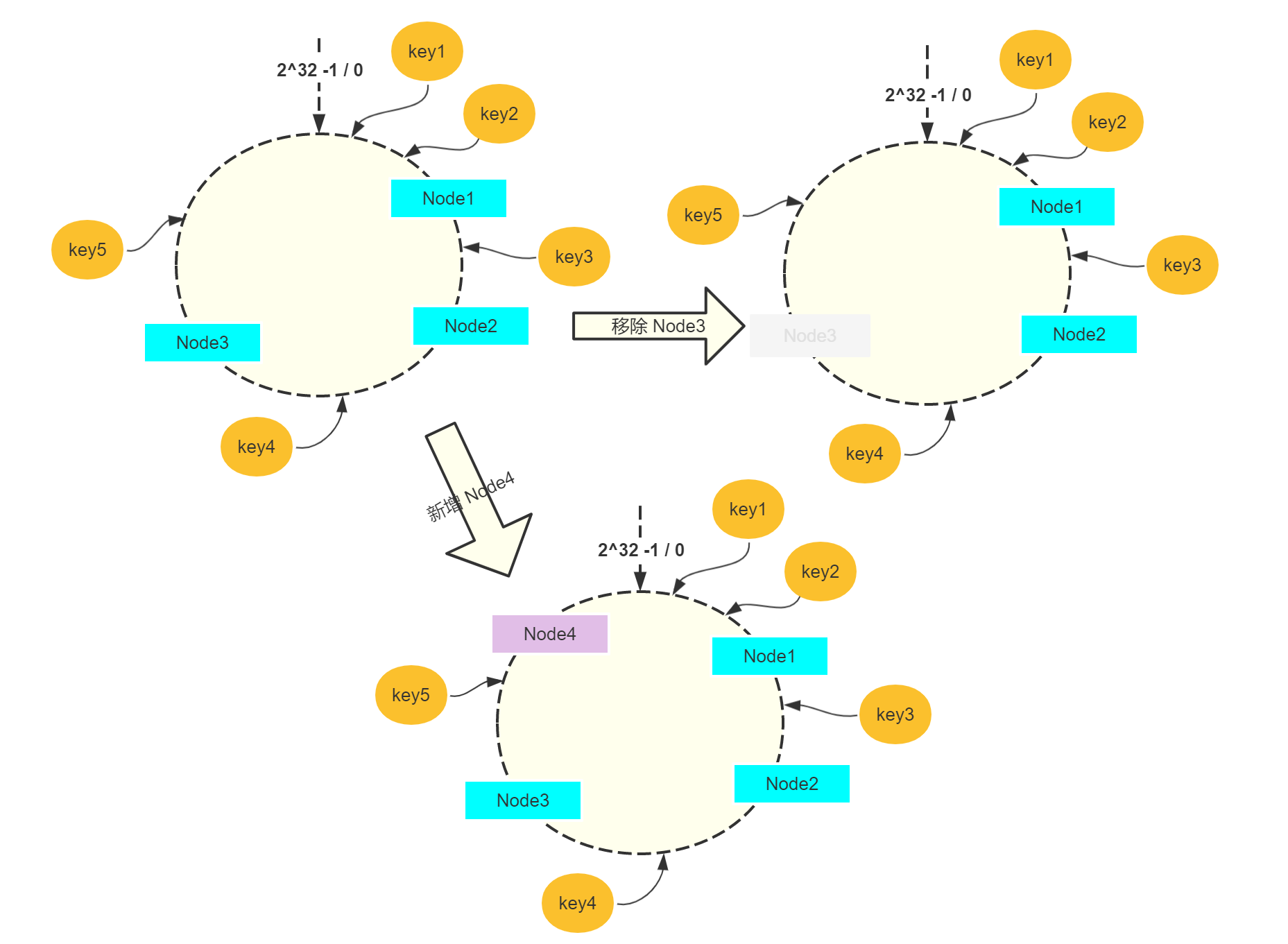
最初始如左上角,环上有三个节点,key1、key2、key5 通过哈希映射到环上,最终选取的是 Node1;同理 key3 选取的是 Node2,key4 选取的是 Node3。
那么移除节点如 Node3 时,只有 key4 需要重新选取到 Node1;新增节点如 Node4 的时候,只有 key5 需要重新选取到 Node4。故通过一致性哈希可以有效减少节点重新选取的频率,防止缓存大量失效。
2.2 数据倾斜
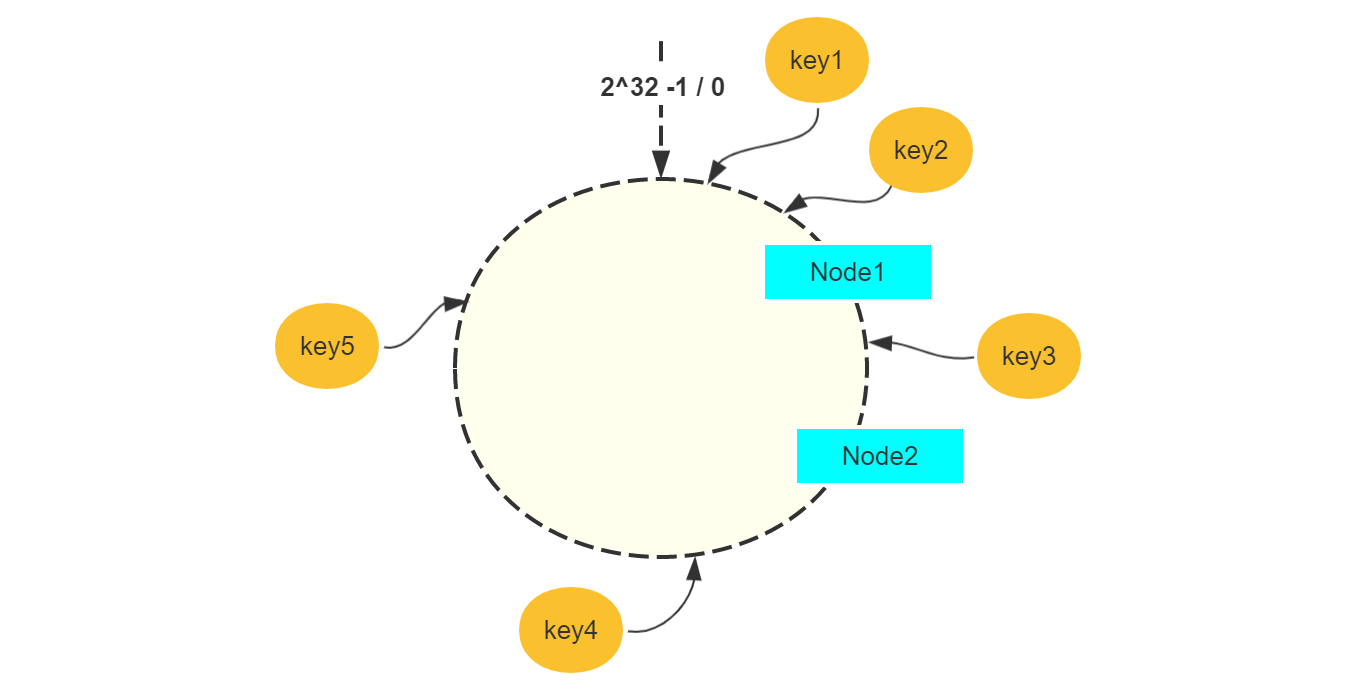
在节点数比较少的时候,会出现数据倾斜的问题。如上图,只有两个服务节点,其中 key1、key2、key4、key5 都是访问 Node1,而只有一个 key3 访问 Node2。这样就造成了各个节点的负载不均衡,不能够充分地提高总体的性能。
本质的原因其实已经提到,就是节点数比较少,所以一种解决方案是增加虚拟节点来拓充节点数。虚拟节点不提供服务,仅用于负载均衡,最终仍然是请求实际的节点获取数据。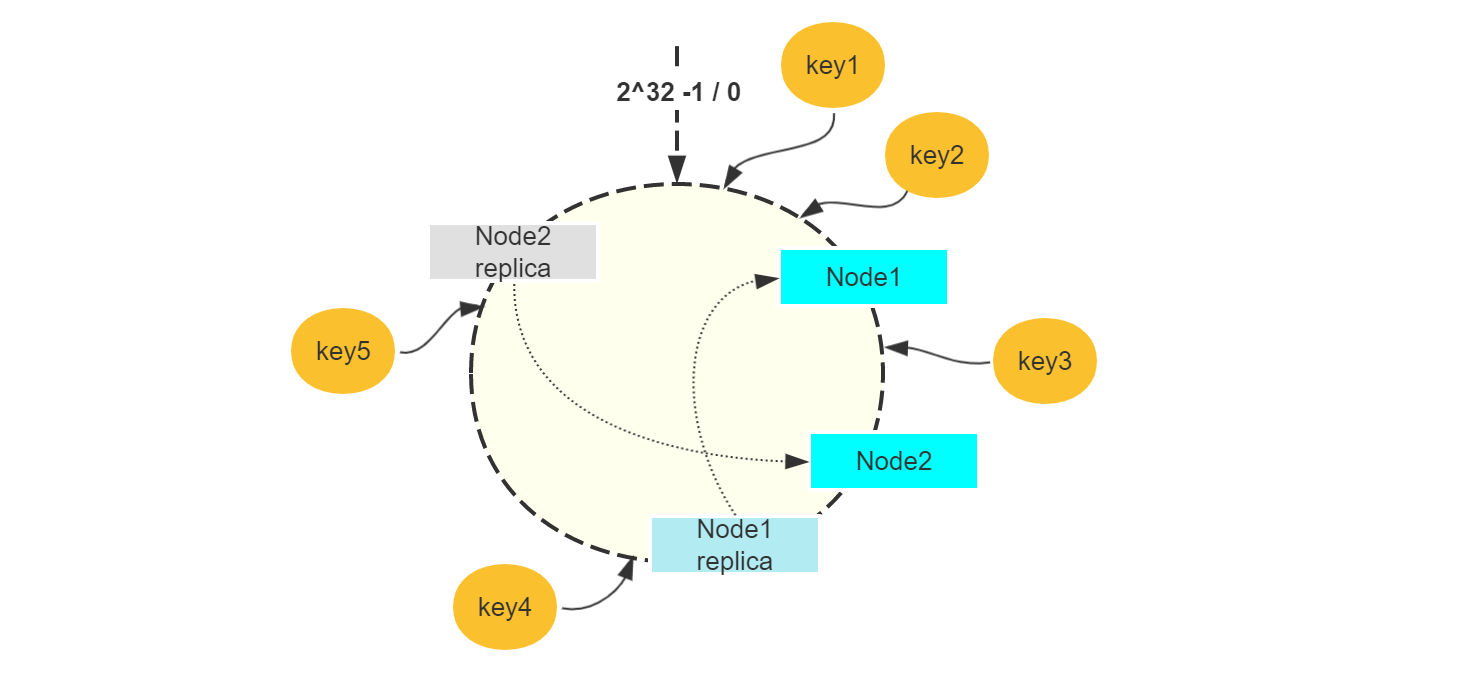
如图假设为每一个节点设置 1 个虚拟节点,这样实际上访问 Node1 的就有 key1、key2,访问 Node2 的就有 key3、key4、key5。实际上,设置更多的虚拟节点,这种负载均衡会更加明显。
3. 缓存雪崩
大量缓存失效,数据源压力骤增
之前由于节点选取策略的不当,导致了缓存雪崩,这可以使用一致性哈希进行解决(大量缓存失效)。合理地选取了节点后,站在缓存的角度,仍然可能存在多个请求并发到达的情况,导致本节点发起大量的数据库请求操作(数据源压力骤增)。
在设计缓存这个层面考虑,就是进行并发控制。在并发访问数据源的时候,只放行其中一个请求去访问数据库,其余的共同享用该请求的访问结果。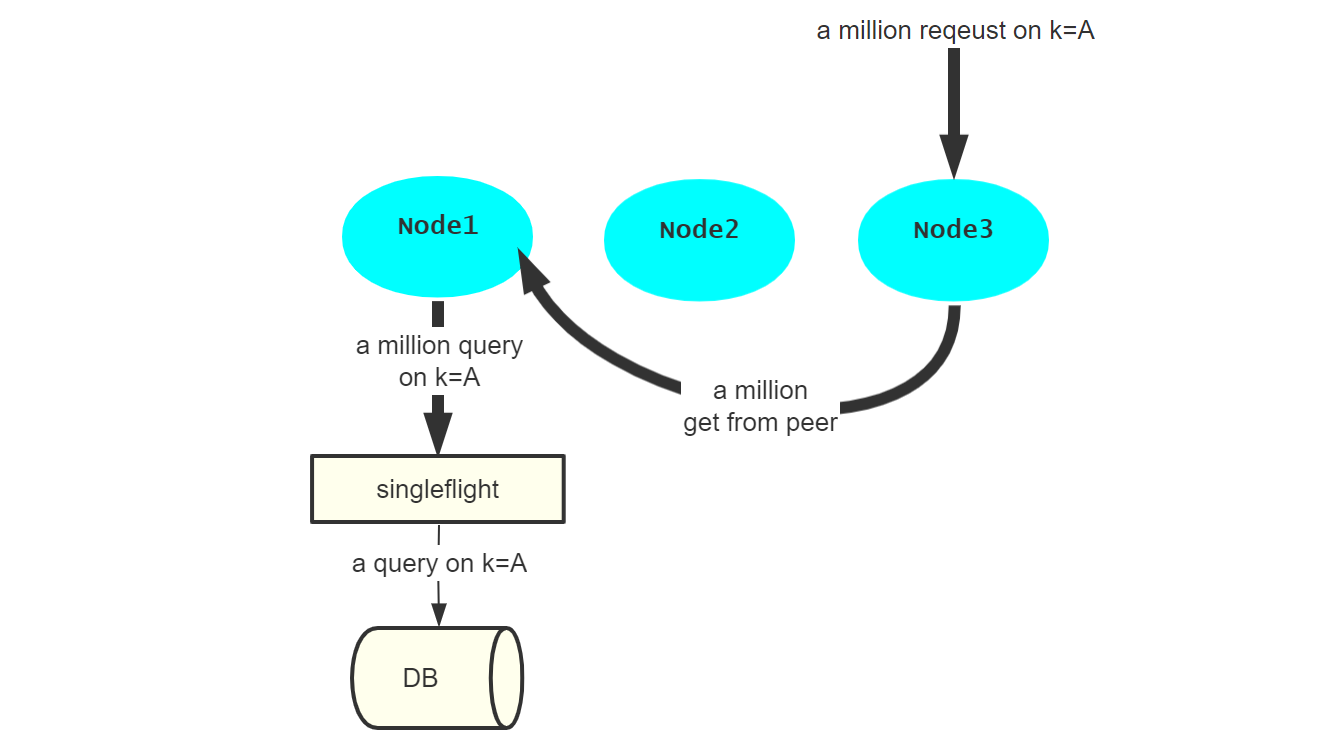
4. 总结
- 分布式其实可以看作是多进程协同工作,通过网络接口来进行通信。
- 使用一致性哈希来选择节点,相同的 key 尽量命中同一个节点,节点数目变动的时候尽量少缓存失效。
- 一致性哈希将哈希值分布在一个环上(2^32 大小),哈希值所在位置的第一个顺序节点,就是要选择的节点。
- 在节点数目少的时候,一致性哈希会出现负载不均衡的问题,通过增加虚拟节点来解决。
- 缓存层面上解决缓存雪崩,一是采用一致性哈希,而是进行并发请求控制,只放行一个请求。
虽然说了这么都是文字上的概念,但是编码实现过后再总结,真的有一种文字无法表达的清晰感。
最后放上 mycache 的大体工作流程,画的幸苦就不想浪费了,hh。通信是基于 HTTP 协议的,首先客户发起一个对 Tom 的请求。收到请求后,首先查询当前节点的缓存。发现在缓存 scores 中没有找到 Tom 的值,则通过内部的 URL 请求另外一个节点。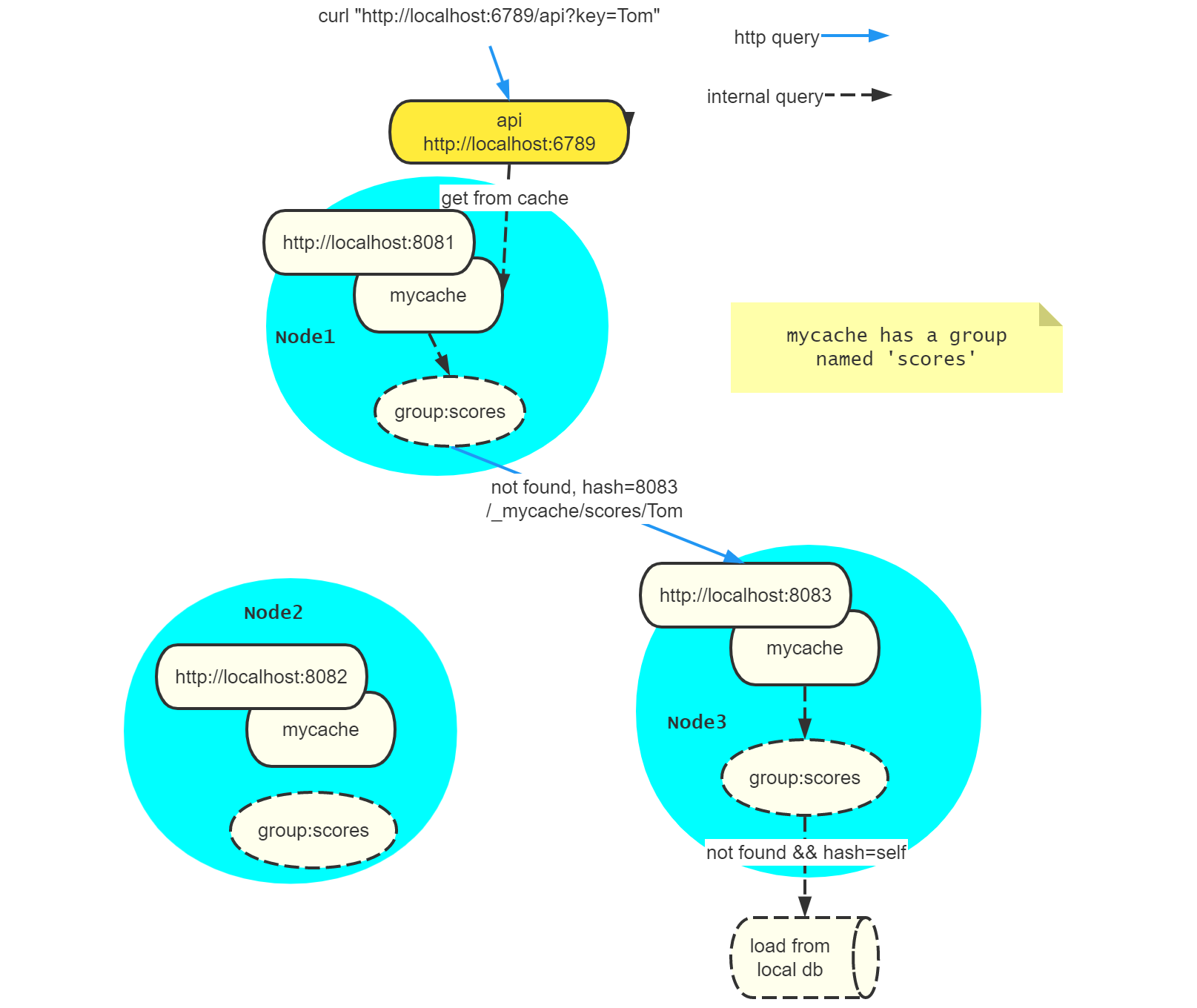

若有收获,就点个赞吧
0 人点赞
