Kafka 是一个分布式的基于发布订阅模式的消息队列,应用于大数据实时处理的情况。
消息队列
优点概述
- 解耦,允许独立修改拓展消息队列两端的处理过程;系统部分组件失效时,不会影响到整个系统的运作,等组件恢复之后再从消息队列中拿来数据继续处理。
- 缓冲,解决生产消息和消费消息处理速度不一致的问题。
- 异步处理,提高响应的效率。
- 灵活,更好处理峰值。在访问量剧增的情况下,由于消息队列的解耦合,可以动态地拓展处理消息的服务,同时也缓冲了数据访问的压力。
两种模式
1. 点对点模式
消息一对一,消费者主动拉取消息,消息被使用后就从队列中删除,即消费者不能够消费到已经消费过的消息。所以消息队列实际上是支持多个消费者的,但是对于一个消息而言,只有一个消费者能够使用。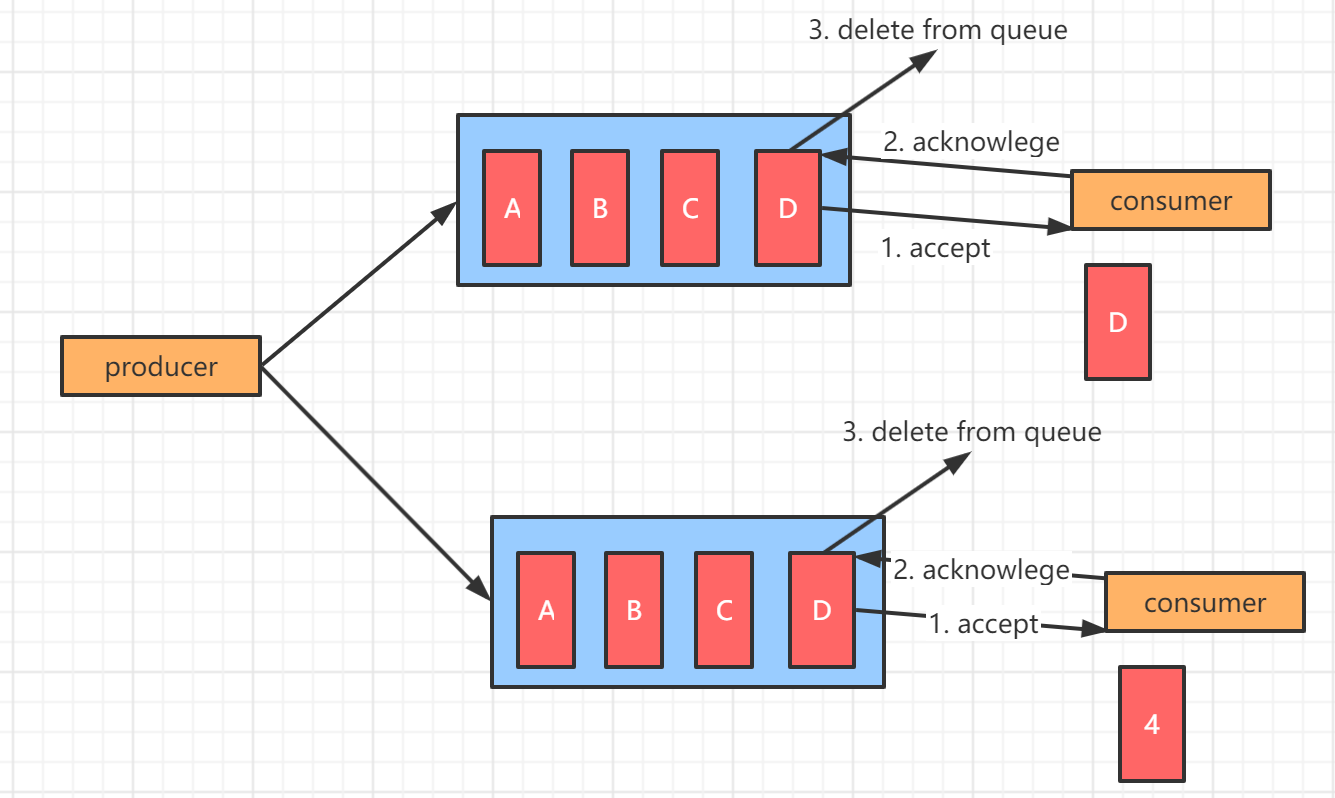
2. 发布订阅模式
消息一对多,消息生产者发布消息到队列 topic 中,队列主动将消息推送给所有的订阅者/订阅者主动从队列中拉取消息。此时的 topic 非常类似文件系统中的文件夹,而消息就类似文件夹中的文件,最大的不同就是消息并不会像文件一样持久化,而是有一定的存活时间的。
发布订阅中又可以继续细分为两种:
- 消费者主动拉取模式,好处是消费者获取消息速度可以由自己的处理能力来决定,但是其坏处则是消费者需要去轮询消息队列是否有新消息。
- 队列主动推送模式,好处是能够及时得到新消息,坏处则是无法把控消费者的处理能力导致消费者处理能力不足或者过剩。
Kafka 使用的就是发布订阅者模式中的消费者拉取模式。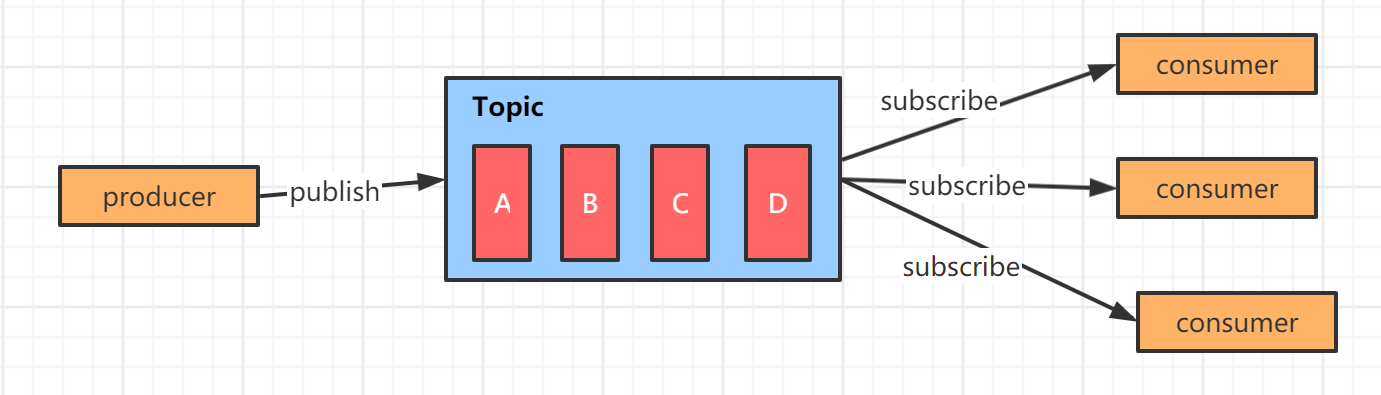

若有收获,就点个赞吧
0 人点赞
