不同的问题,都有不同的解决模型,将这些模型简单梳理一下,建立起自己的思维系统,之后遇到这种问题就能够更快做出反应,并且能够站在更加系统性的视角。
加锁 & 不加锁
线程操作资源,加锁是为了保护资源,限制访问资源的线程数。所以加锁的目标是资源类,常用的做法就是将资源再一次进行封装,添加上锁相关的工具。
// Task is a wrapper around S that adds synchronization.class Task {private Lock lock;private S source;}
加锁保护资源。当资源会被多线程操作,但需要保证一致性,才需要考虑加锁。对于例子,若 chunk 分配给了某一个线程单独处理,那么对该 chunk 的操作不需要加锁。
加锁控制并发度。当需要线程数超过并发限度,才需要考虑加锁。对于例子,若在设计 API 过程中最多开了 pCount 个线程,那么没有必要通过加锁来控制并发度。
同步 & 互斥
同步是为了控制操作的顺序,互斥是为了控制资源被独占。并发设计模型实际上就是同步模型,核心为生产者消费者模型。
生产者消费者模型
设计一个 API,helper(T[], int chunkSize, int pCount, Processor p)。在 pCount 的并发限度下处理数据 arr。arr 在处理之前,先分块,每一块的大小最多 chunkSize。
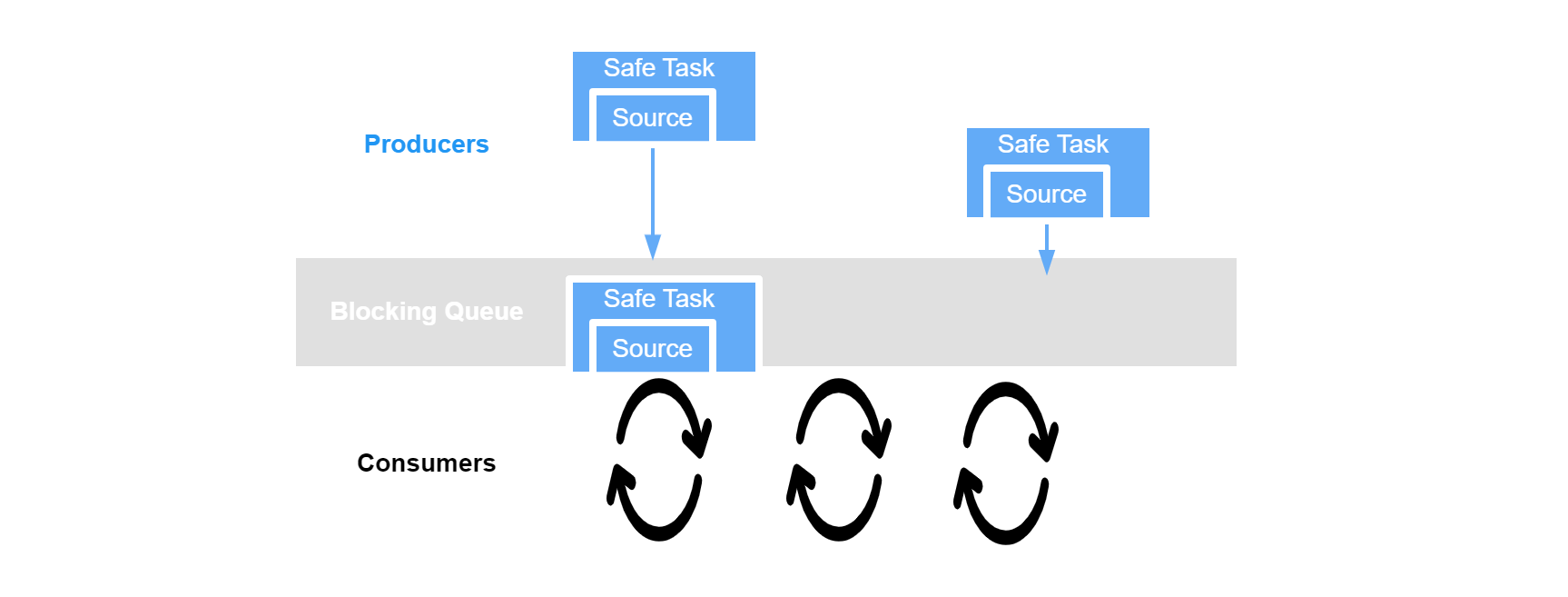
生产者生产任务,消费者取来任务执行。任务从生产者到消费者需要一个中转空间,供生产者放置任务、消费者获取任务,所以生产者消费者往往需要结合阻塞队列来实现。下面使用生产者消费者模型来解决这个问题:
// helper(T[], int chunkSize, int pCount, Processor p)@FunctionalInterfaceinterface Processor<T> {void process(T t);}class Slice<T> {final T[] arr;final int st, en;public Slice(T[] arr, int st, int en) {this.arr = arr;this.st = st;this.en = en;}}class Task<T> {private final Slice<T> content;public Task(Slice<T> content) {this.content = content;}public void run(Processor<T> p, AtomicInteger cnt) {for (int i = content.st; i < content.en; i++) {p.process(content.arr[i]);cnt.incrementAndGet();}}}class Helper<T> {private BlockingQueue<Task<T>> q = new LinkedBlockingQueue<>();private AtomicInteger cnt = new AtomicInteger(0);public void help(T[] arr, int size, int pc, Processor<T> p) {// consumefor (int i = 0; i < pc; i++) {new Thread(() -> {while (cnt.get() < arr.length) {Task<T> task = q.poll();if (task != null) {task.run(p, cnt);}}}).start();}// produceint i;for (i = 0; i < arr.length - size; i += size) {Task<T> task = new Task<>(new Slice<>(arr, i, i + size));q.offer(task);}if (i < arr.length) {Task<T> task = new Task<>(new Slice<T>(arr, i, i + size));q.offer(task);}}}
- Java 中一切皆对象,所以将操作的逻辑抽象为一个接口 Processer,处理的数据抽象为泛型 T
- 由于初始结构为一个数组,可以用切片的思想来进行分片,但是 Java 没有原生的分片,故定义一个分片类 Slice。那么此时的 Slice,就是最原始的资源。
- 将资源封装为任务 Task,也就是加上线程安全的保护措施。由于这里我考虑每一个分片仅由一个线程负责,所以不存在数据竞争,无需加锁。在执行任务的时候,我增加了一个 cnt 变量,用于记录完成的任务数,方便最后让线程退出。
- 实现生产者消费者模型,阻塞队列用于存储任务。生产者往队列中放任务,消费者从队列中取任务。
等待通知模型
等待通知模型最适用于控制逻辑顺序,等待的是线程,通知的也是线程。对于上一个例子,任务之间的执行实际上没有顺序要求,所以不适合使用等待通知模型。为了不使例子复杂化,使用实现阻塞队列的例子。阻塞队列存在逻辑顺序,队列非空才能够取数据,队列非满才能放数据。(BlockingQueue 三种实现方式)
class BlockingQueue<T> {private Queue<T> q = new LinkedList<>();private Lock lock = new ReentrantLock();private Condition notEmpty = lock.newCondition();private Condition notFull = lock.newCondition();private int size;private int capacity;public T poll() {T task = null;lock.lock();try {while (size == 0) {notEmpty.await();}task = q.poll();size--;notFull.signal();} finally {lock.unlock();}return task;}public void offer(T task) {lock.lock();try {while (size == capacity) {notFull.await();}q.offer(task);size++;notEmpty.signal();} finally {lock.unlock();}}}
总结
核心点在于认清:线程操作任务,任务是资源的安全包装。在解决问题主要记住两个模型:
- 生产者消费者模型,是绝大多数线程执行任务的抽象,常常结合阻塞队列使用。
- 等待通知模型,适用于有逻辑顺序约束的情况。

若有收获,就点个赞吧
0 人点赞
