- Python环境安装
- pip的使用
- 运行python程序
- Python
- #开头右边的都是注释,解析器会忽略注释
- 变量类型的基本使用
- Number 数值
- int
- float
- boolean 布尔
- 男 True
- string 字符串,使用的是单引号 或者双引号
- 单引号和双引号的嵌套
- 错误:单引号套单引号 双引号套双引号(就近原则)
- s6 = ‘’行还是不行呢’’
- s7 = “”行还是不行呢””
- list 列表
- 应用场景:当获取到了很多个数据的时候 那么我们可以将他们存储到列表中 然后直接使用列表访问
- tuple 元组
- dict 字典
- 应用场景:scrapy框架使用
- 格式:变量的名字 = {key:value,key1:value1}
- 单个变量赋值
- 同时为多个变量赋值(使用等号连接)
- 多个变量赋值(使用逗号分隔)
- 示例:+=
- 示例:*=
- 示例:*=,运算时,符号右侧的表达式先计算出结果,再与左边变量的值运算
- 在控制台上输入一个年龄 如果您的年龄大于18了 那么打印可以去网吧了
- 数据类型高级
- append 追加 在列表的最后来添加一个对象/数据
- insert 插入
- index的值就是你想插入数据的那个下标
- extend
- 判断一下在控制台输入的那个数据 是否在列表中
- 定义一个字典
- 访问person的name
- 使用[]的方式,获取字典中不存在的key的时候 会发生异常 keyerror
- print(person[‘sex’])
- 不能使用.的方式来访问字典的数据
- print(person.name)
- 使用.get来获取数据
- 使用.get的方式,获取字典中不存在的key的时候 会返回None值
- 给字典添加一个新的key value
- 如果使用变量名字[‘键’] = 数据时 这个键如果在字典中不存在 那么就会变成新增元素
- 如果这个键在字典中存在 那么就会变成这个元素
- (1) 遍历字典的key
- 字典.keys() 方法 获取的字典中所有的key值 key是一个变量的名字 我们可以随便起
- for key in person.keys():
- print(key)
- (2) 遍历字典的value
- 字典.values()方法 获取字典中所有的value值 value也是一个变量 我们可以随便命名
- for value in person.values():
- print(value)
- (3) 遍历字典的key和value
- for key,value in person.items():
- print(key,value)
- (4) 遍历字典的项/元素
- 使用一个变量来接受函数的返回值
- 案例练习
- 定义一个函数 然后让函数计算两个数值的和 并且返回这个计算之后的结果
Python环境安装
Python下载
测试安装是否成功
pip的使用
pip 是一个现代的、通用的Python包管理工具,提供了对 Python 包的查找、下载、安装、卸载的功能,便于我们对Python的资源包进行管理。 在安装Python时,会自动下载并且安装pip。
使用pip管理Python包
安装:pip install <包名>
删除:pip uninstall <包名>
显示已安装的包:pip list
以指定的格式显示已安装的包:pip freeze
修改pip下载源
运行安装命令会默认从 https://files.pythonhosted.org/ 网站上下载python包。 这是个国外的网站,遇到网络情况不好的时候,可能会下载失败,我们可以修改下载源。
修改下载源:pip install 包名 -i 国内源地址
示例: pip install ipython -i [https://pypi.mirrors.ustc.edu.cn/simple/](https://pypi.mirrors.ustc.edu.cn/simple/)
国内常用的pip下载源列表:
- 阿里云 http://mirrors.aliyun.com/pypi/simple/
- 中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
- 豆瓣(douban) http://pypi.douban.com/simple/
- 清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
- 中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/
运行python程序
终端运行
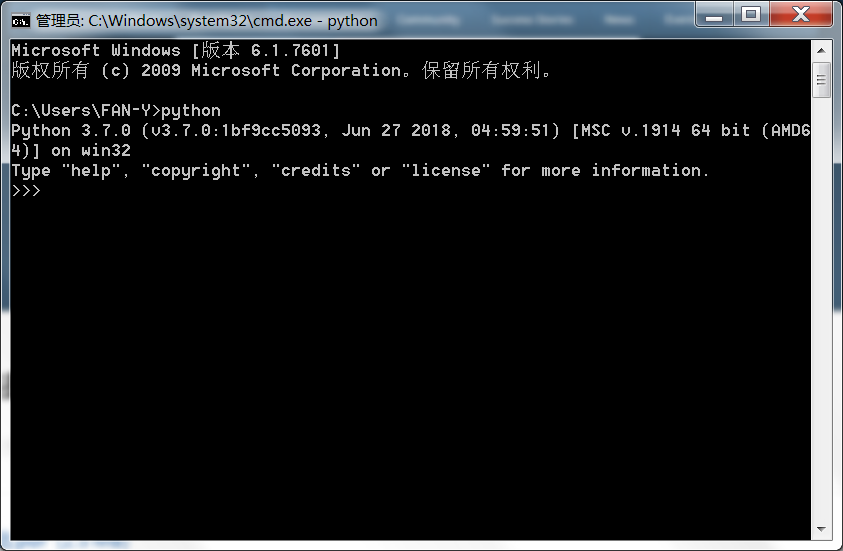
- python解释器中运行
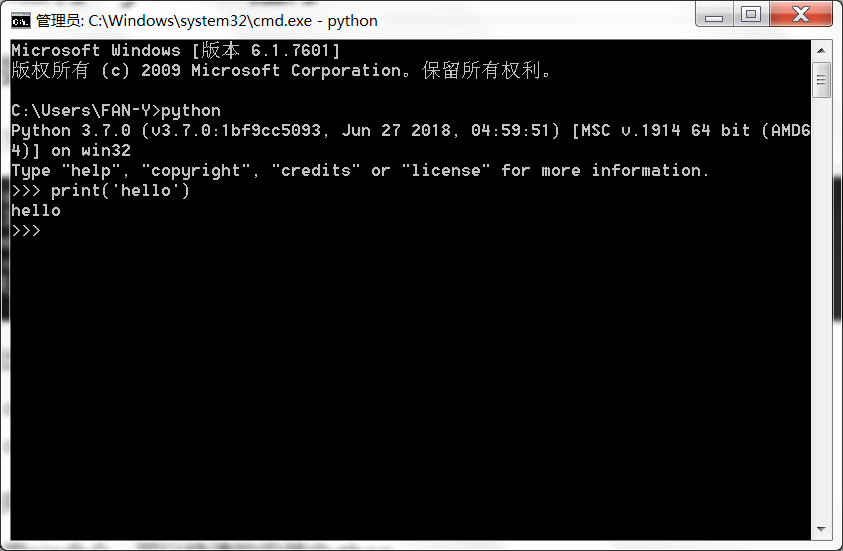
退出python环境
exit()ctrl+z+enter
- ipython解释器中运行
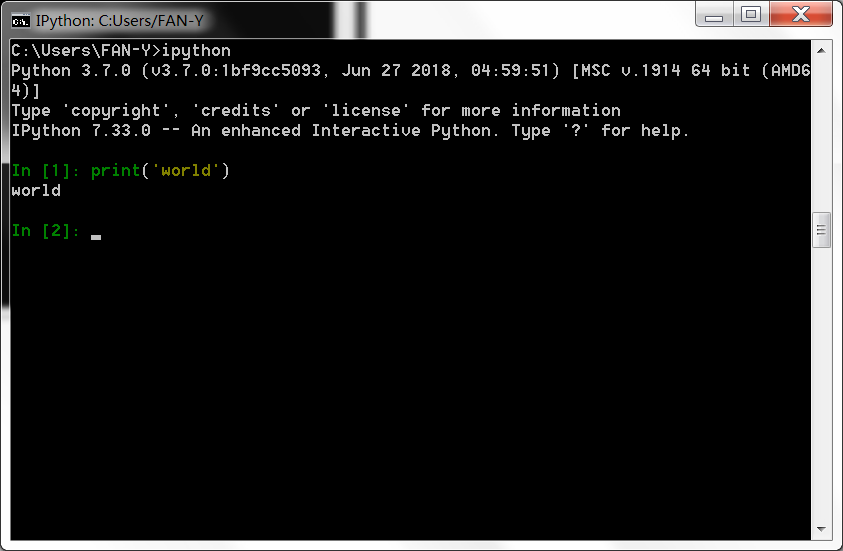
运行.py文件
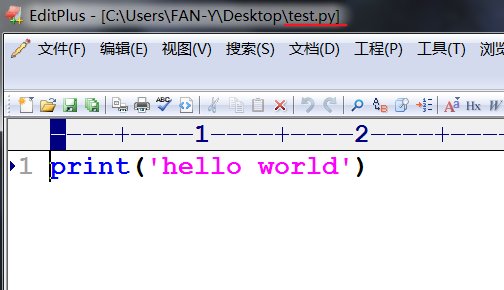
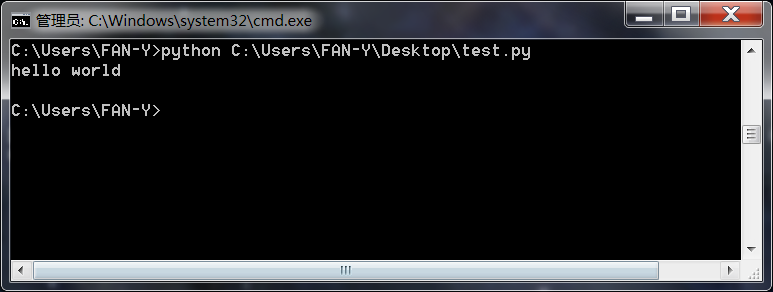
Pycharm
尽管上面介绍的方法已经能够提高我们的编码速度,但是仍然无法应对我们开发中更加复杂的要求。
一般情况下,我们需要借助工具来辅助我们快速的搭建环境,编写代码以及运行程序。
IDE(Integrated Development Environment)称为集成开发环境。
说白了,就是有一款图形化界面的软件,它集成了编辑代码,编译代码,分析代码,执行代码以及调试代码等功能。
在我们Python开发中,最常用的IDE是Pycharm。
Pycharm是由捷克公司JetBrains开发的一款IDE,提供代码分析、图形化调试器,集成测试器、集成版本控制系统等,主要用来编写Python代码。
下载地址:http://www.jetbrains.com/pycharm/download
Python
注释
注释介绍
在我们工作编码的过程中,如果一段代码的逻辑比较复杂,不是特别容易理解,可以适当的添加注释,以辅助自己或者其他编码人员解读代码。

注意:注释是给程序员看的,为了让程序员方便阅读代码,解释器会忽略注释,适当的对代码进行注释说明是一种良好的编码习惯。
注释分类
Python中支持单行注释和多行注释
- 单行注释:以
#开头,#右边的所有东西当做说明,而不是真正要执行的程序,起辅助说明作用。 - 多行注释:以
'''开始,并以'''结束,称之为多行注释。 ```python#开头右边的都是注释,解析器会忽略注释
print(‘hello world’) #我的作用是在控制台输出hello world
‘’’ 佛曰: 写字楼里写字间,写字间里程序员; 程序人员写程序,又拿程序换酒钱。 酒醒只在网上坐,酒醉还来网下眠; 酒醉酒醒日复日,网上网下年复年。 但愿老死电脑间,不愿鞠躬老板前; 奔驰宝马贵者趣,公交自行程序员。 别人笑我忒疯癫,我笑自己命太贱; 不见满街漂亮妹,哪个归得程序员? ‘’’
<a name="DIS67"></a>## 变量及数据类型<a name="VuD8Q"></a>### 变量定义对于重复使用,并且经常需要修改的数据,可以定义为变量,来提高编程效率<br />定义变量的语法为: `变量名 = 变量值`(这里的 = 作用是赋值)<br />定义变量后可以使用变量名来访问变量值```python# 定义一个变量表示这个字符串。如果需要修改内容,只需要修改变量对应的值即可weather = "今天天气真好"print(weather) # 注意,变量名不需要使用引号包裹print(weather)
说明:
- 变量即是可以变化的量,可以随时进行修改。
- 程序就是用来处理数据的,而变量就是用来存储数据的。
变量类型
在 Python 里为了应对不同的业务需求,也把数据分为不同的类型。 ```python
```python变量类型的基本使用
Number 数值
int
money = 5000float
money1 = 1.2
boolean 布尔
男 True
sex = True
string 字符串,使用的是单引号 或者双引号
s = ‘苍茫的大海上有一只海燕 你可长点心吧’ s1 = “嘀嗒嘀嗒嘀”
单引号和双引号的嵌套
s4 = ‘“嘿嘿嘿”‘ print(s4) s5 = “‘嘿嘿’” print(s5)
错误:单引号套单引号 双引号套双引号(就近原则)
s6 = ‘’行还是不行呢’’
s7 = “”行还是不行呢””
list 列表
应用场景:当获取到了很多个数据的时候 那么我们可以将他们存储到列表中 然后直接使用列表访问
name_list = [‘周杰伦’,’科比’] print(name_list)
tuple 元组
age_tuple = (18,19,20,21) print(age_tuple)
dict 字典
应用场景:scrapy框架使用
格式:变量的名字 = {key:value,key1:value1}
person = {‘name’:’红浪漫’,’age’:18} print(person)
<a name="j3wev"></a>### 查看数据的类型在python中,只要定义了一个变量,而且它有数据,那么它的类型就已经确定了,不需要开发者主动的去说明它的类型,系统会自动辨别。也就是说在使用的时候 "变量没有类型,数据才有类型"。<br />比如下面的示例里,a 的类型可以根据数据来确认,但是我们没法预测变量 b 的类型。<br /><br />如果临时想要查看一个变量存储的数据类型,可以使用 `type(变量名)`,来查看变量存储的数据类型。<br /><a name="LJBgD"></a>## 标识符和关键字计算机编程语言中,标识符是用户编程时使用的名字,用于给变量、常量、函数、语句块等命名,以建立起名称与使用之间的关系。1. 标识符由字母、下划线和数字组成,且数字不能开头。1. 严格区分大小写。1. 不能使用关键字。<a name="VwAUK"></a>### 命名规范- 标识符命名要做到顾名思义- `a = "zhangsan" # bad`- `name = "zhangsan" # good`- 遵守一定的命名规范- 驼峰命名法,又分为大驼峰命名法和小驼峰命名法- 小驼峰式命名法(lower camel case): 第一个单词以小写字母开始;第二个单词的首字母大写,例如:`myName`- 大驼峰式命名法(upper camel case): 每一个单字的首字母都采用大写字母,例如:`FirstName`- 使用下划线来连接所有的单词,例如:`send_buf`- Python的命令规则遵循PEP8标准<a name="TkM8B"></a>### 关键字一些具有特殊功能的标识符称为关键字。关键字已经被python官方使用了,不允许开发者自己定义和关键字相同的标识符。```python'''False None True and as assert break class continue def del elif else except finally forfrom global if import in is lambda nonlocal not or pass raise return try while with yield'''
类型转换
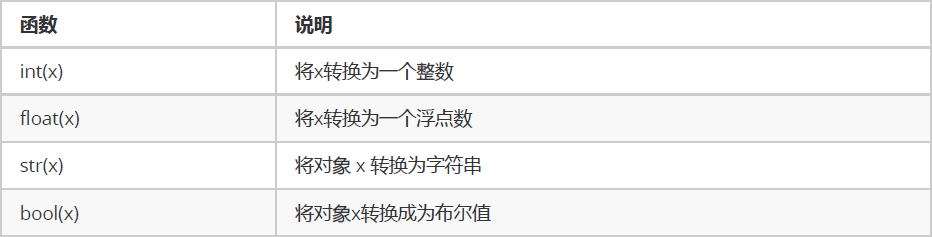
print(int("123")) # 123 将字符串转换成为整数print(int(123.78)) # 123 将浮点数转换成为整数print(int(True)) # 1 布尔值True转换成为整数是 1print(int(False)) # 0 布尔值False转换成为整数是 0# 以下两种情况将会转换失败'''123.456 和 12ab 字符串,都包含非法字符,不能被转换成为整数,会报错print(int("123.456"))print(int("12ab"))'''
f1 = float("12.34")print(f1) # 12.34print(type(f1)) # float 将字符串的 "12.34" 转换成为浮点数 12.34f2 = float(23)print(f2) # 23.0print(type(f2)) # float 将整数转换成为了浮点数
str1 = str(45)str2 = str(34.56)str3 = str(True)print(type(str1),type(str2),type(str3))
# 什么情况下是Falseprint(bool(''))print(bool(""))print(bool(0))print(bool({}))print(bool([]))print(bool(()))
运算符
算数运算符
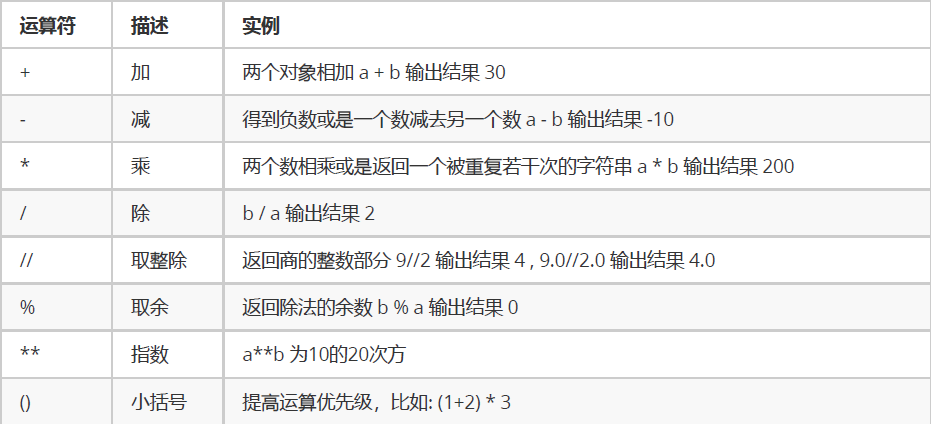
注意:混合运算时,优先级顺序为:
**高于* / % //高于+ -,为了避免歧义,建议使用()来处理运算符优先级。 并且,不同类型的数字在进行混合运算时,整数将会转换成浮点数进行运算。
算数运算符在字符串里的使用:
如果是两个字符串做加法运算,会直接把这两个字符串拼接成一个字符串
In [1]: str1 ='hello'In [2]: str2 = 'world'In [3]: str1+str2Out[3]: 'helloworld'
如果是数字和字符串做加法运算,会直接报错
In [1]: str1 = 'hello'In [2]: a = 2In [3]: a+str1‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐TypeError Traceback (most recent call last)<ipython‐input‐3‐993727a2aa69> in <module>‐‐‐‐> 1 a+str1TypeError: unsupported operand type(s) for +: 'int' and 'str'
如果是数字和字符串做乘法运算,会将这个字符串重复多次
In [4]: str1 = 'hello'In [5]: str1*10Out[5]: 'hellohellohellohellohellohellohellohellohellohello
赋值运算符
 ```python
```python单个变量赋值
num = 10 num 10
同时为多个变量赋值(使用等号连接)
a = b = 4 a 4 b 4
多个变量赋值(使用逗号分隔)
num1, f1, str1 = 100, 3.14, “hello” num1 100 f1 3.14 str1 “hello” ```
复合赋值运算符
```python
示例:+=
a = 100 a += 1 # 相当于执行 a = a + 1 a 101
示例:*=
a = 100 a = 2 # 相当于执行 a = a 2 a 200
示例:*=,运算时,符号右侧的表达式先计算出结果,再与左边变量的值运算
a = 100 a = 1 + 2 # 相当于执行 a = a (1+2) a 300
<a name="qYlOi"></a>### 比较运算符<a name="qPC7b"></a>### 逻辑运算符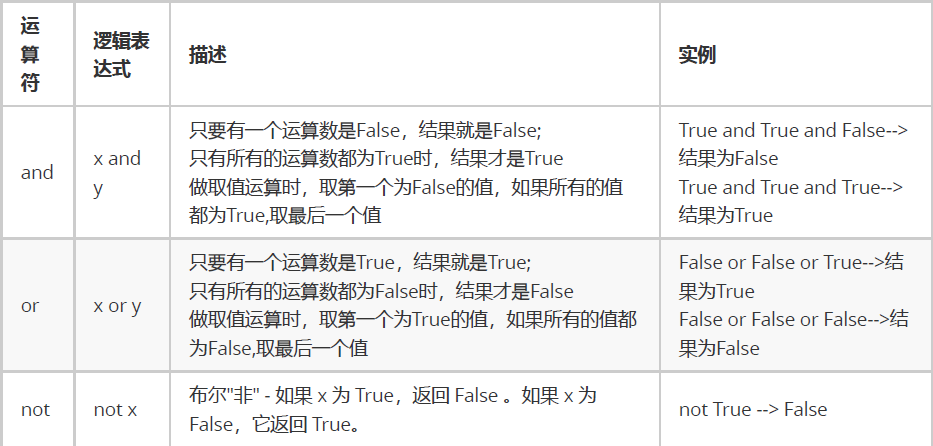<br />性能提升:逻辑运算的短路问题```pythona = 34a > 10 and print('hello world')a < 10 and print('hello world')a >10 or print('你好世界')a <10 or print('你好世界')输入输出
输出
- 普通输出:
print('吴亦凡火了') - 格式化输出
age = 18name = "红浪漫晶哥"# %s 代表的是字符串(s→string) %d 代表的是数值(d→decimal)print("我的姓名是%s, 年龄是%d" % (name, age))
输入
注意:password = input("请输入密码:")print('您刚刚输入的密码是:%s' % password)
- input()的小括号中放入的是提示信息,用来在获取数据之前给用户的一个简单提示
- input()在从键盘获取了数据以后,会存放到等号左边的变量中
- input()会把用户输入的任何值都作为字符串来对待
流程控制语句
if
```python ‘’’ 格式: if 要判断的条件: 条件成立时,要做的事情 ‘’’
在控制台上输入一个年龄 如果您的年龄大于18了 那么打印可以去网吧了
age = input(‘请输入您的年龄’) # input返回的是字符串类型 if int(age) > 18: # 字符串和整数int是不可以比较的 print(‘您成年了,可以去网吧了’)age = 30 if age >= 18: print(“我已经成年了”)
<a name="NWWOn"></a>### if-else```python'''if 条件:满足条件时的操作else:不满足条件时的操作'''# 在控制台上输入一个年龄 如果您的年龄大于18了 那么输出 欢迎光临红浪漫 男宾一位age = int(input('请输入您的年龄'))if age > 18:print('欢迎光临红浪漫,男宾一位')else:print('洗洗睡吧')
elif
'''if xxx1:事情1elif xxx2:事情2elif xxx3:事情3'''# demoscore = 77if score>=90:print('本次考试,等级为A')elif score>=80:print('本次考试,等级为B')elif score>=70:print('本次考试,等级为C')elif score>=60:print('本次考试,等级为D')else:print('不及格')
for
在Python中 for循环可以遍历任何序列的项目,如一个列表或者一个字符串等
'''for 临时变量 in 列表或者字符串等可迭代对象:循环满足条件时执行的代码'''# 遍历字符串for s in "hello":print(s)
range
range 可以生成数字供 for 循环遍历,它可以传递三个参数,分别表示 起始、结束和步长
# range(5) 0~4 左闭右开区间(0,5)for i in range(5):print(i)# range(1,6)# range(起始值,结束值)左闭右开区间for i in range(1,6):print(i)# range(1,10,3)# range(起始值,结束值,步长)1 4 7 10# 左闭右开区间for i in range(1,11,3):print(i)
数据类型高级
字符串高级
# - 获取长度:len len函数可以获取字符串的长度。# - 查找内容:find 查找指定内容在字符串中是否存在,如果存在就返回该内容在字符串中第一次出现的开始位置索引值,如果不存在,则返回-1.# - 判断:startswith,endswith 判断字符串是不是以谁谁谁开头/结尾# - 计算出现次数:count 返回 str在start和end之间 在 mystr里面出现的次数# - 替换内容:replace 替换字符串中指定的内容,如果指定次数count,则替换不会超过count次。# - 切割字符串:split 通过参数的内容切割字符串# - 修改大小写:upper,lower 将字符串中的大小写互换# - 空格处理:strip 去空格# - 字符串拼接:join 字符串拼接# len length的缩写 长度s = 'china'print(len(s))s1 = 'china'print(s1.find('a'))s2 = 'china'print(s2.startswith('h'))print(s2.endswith('n'))s3 = 'aaabb'print(s3.count('b'))s4 = 'cccdd'print(s4.replace('c','d'))s5 = '1#2#3#4'print(s5.split('#'))s6 = 'china'print(s6.upper())s7 = 'CHINA'print(s7.lower())s8 = ' a 'print(len(s8))print(len(s8.strip()))s9 = 'a'print(s9.join('hello'))
列表高级
- 添加
```python
‘’’
添加元素有以下几个方法:
append 在末尾添加元素
insert 在指定位置插入元素
extend 合并两个列表
‘’’
append 追加 在列表的最后来添加一个对象/数据
food_list = [‘铁锅炖大鹅’,’酸菜五花肉’] print(food_list)
food_list.append(‘小鸡炖蘑菇’) print(food_list)
insert 插入
char_list = [‘a’,’c’,’d’] print(char_list)
index的值就是你想插入数据的那个下标
char_list.insert(1,’b’) print(char_list)
extend
num_list = [1,2,3] num1_list = [4,5,6]
num_list.extend(num1_list) print(num_list)
- 修改```python# 将列表中的元素的值修改# 可以通过下标来修改,注意列表中的下标是从0开始的city_list = ['北京','上海','深圳','武汉','西安']print(city_list)city_list[4] = '大连'print(city_list)
- 查询 ```python ‘’’ python中查找的常用方法为: in(存在),如果存在那么结果为true,否则为false not in(不存在),如果不存在那么结果为true,否则false ‘’’
food_list = [‘锅包肉’,’汆白肉’,’东北乱炖’]
判断一下在控制台输入的那个数据 是否在列表中
food = input(‘请输入您想吃的食物’) if food in food_list: print(‘在’) else: print(‘不在’)
- 删除```python'''列表元素的常用删除方法有:del:根据下标进行删除pop:删除最后一个元素remove:根据元素的值进行删除'''a_list = [1,2,3,4,5]print(a_list)# 根据下标来删除列表中的元素# 爬取的数据中 有个别的数据 是我们不想要的 那么我们就可以通过下标的方式来删除del a_list[2]print(a_list)b_list = [1,2,3,4,5]print(b_list)# pop是删除列表中的最后一个元素b_list.pop()print(b_list)c_list = [1,2,3,4,5]print(c_list)# 根据元素来删除列表中的数据c_list.remove(3)print(c_list)
元组高级
Python的元组与列表类似,不同之处在于元组的元素不能修改。元组使用小括号,列表使用方括号。
# 元组访问a_tuple = (1,2,3,4)print(a_tuple[0])print(a_tuple[1])a_tuple = (5)print(type(a_tuple)) # 当元组中只要一个元素的时候 那么他是整型数据# 定义只有一个元素的元组,需要在唯一的元素后写一个逗号b_tuple = (5,)print(type(b_tuple))
切片
切片是指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作。
切片的语法:[起始:结束:步长],也可以简化使用 [起始:结束]
注意:选取的区间从”起始”位开始,到”结束”位的前一位结束(不包含结束位本身),步长表示选取间隔。
# 索引是通过下标取某一个元素# 切片是通过下标去某一段元素s = 'Hello World!'print(s)print(s[4]) # o 字符串里的第4个元素print(s[3:7]) # lo W 包含下标 3,不含下标 7print(s[1:]) # ello World! 从下标为1开始,取出 后面所有的元素(没有结束位)print(s[:4]) # Hell 从起始位置开始,取到 下标为4的前一个元素(不包括结束位本身)print(s[1:5:2]) # el 从下标为1开始,取到下标为5的前一个元素,步长为2(不包括结束位本身)
字典高级
访问person的name
print(person[‘name’])
使用[]的方式,获取字典中不存在的key的时候 会发生异常 keyerror
print(person[‘sex’])
不能使用.的方式来访问字典的数据
print(person.name)
使用.get来获取数据
print(person.get(‘name’))
使用.get的方式,获取字典中不存在的key的时候 会返回None值
print(person.get(‘sex’))
- 修改```python# 字典的每个元素中的数据是可以修改的,只要通过key找到,即可修改person = {'name':'张三','age':18}# 修改name的值为法外狂徒person['name'] = '法外狂徒'# 修改之后的字典print(person)
- 添加 ```python person = {‘name’:’老马’}
给字典添加一个新的key value
如果使用变量名字[‘键’] = 数据时 这个键如果在字典中不存在 那么就会变成新增元素
person[‘age’] = 18
如果这个键在字典中存在 那么就会变成这个元素
person[‘name’] = ‘阿马’
print(person)
- 删除```python'''对字典进行删除操作,有以下两种:delclear()'''# del# (1) 删除字典中指定的某一个元素person = {'name':'老马','age':18}# 删除之前# print(person)# del person['age']# 删除之后# print(person)# (2)删除整个字典# 删除之前# print(person)# del person# 删除之后# print(person)# clear#(3) 清空字典 但是保留字典对象print(person)# 清空指的是将字典中所有的数据 都删除掉 而保留字典的结构person.clear()print(person)
- 遍历 ```python person = {‘name’:’阿马’,’age’:18,’sex’:’男’}
(1) 遍历字典的key
字典.keys() 方法 获取的字典中所有的key值 key是一个变量的名字 我们可以随便起
for key in person.keys():
print(key)
(2) 遍历字典的value
字典.values()方法 获取字典中所有的value值 value也是一个变量 我们可以随便命名
for value in person.values():
print(value)
(3) 遍历字典的key和value
for key,value in person.items():
print(key,value)
(4) 遍历字典的项/元素
for item in person.items(): print(item)
<a name="vJY6a"></a>## 函数<a name="XD5rv"></a>### 函数定义及调用```python'''函数定义格式如下def 函数名():代码'''def f1():print('欢迎马大哥光临红浪漫')print('男宾2位')# 函数定义好以后,函数体里的代码并不会执行,如果想要执行函数体里的内容,需要手动的调用函数# 每次调用函数时,函数都会从头开始执行,当这个函数中的代码执行完毕后,意味着调用结束了f1()
函数的参数
# 定义一个add2num(a, b)函数,来计算任意两个数字之和def sum(a,b):c = a + bprint(c)sum(11, 22) # 调用带有参数的函数时,需要在小括号中,传递数据# 位置参数 按照位置一一对应的关系来传递参数sum(1,2)# 关键字传参sum(b = 200,a = 100)# 定义函数的时候 sum(a,b) 我们称a 和 b 为形式参数 简称形参# 调用函数的时候 sum(1,2) 我们称1 和 2 为实际参数 简称实参
注意:
- 在定义函数的时候,小括号里写等待赋值的变量名
- 在调用函数的时候,小括号里写真正要进行运算的数据
函数的返回值
“返回值”,就是程序中函数完成一件事情后,最后给调用者的结果,想要在函数中把结果返回给调用者,需要在函数中使用return```python def buyIceCream(): return ‘冰激凌’
使用一个变量来接受函数的返回值
food = buyIceCream() print(food)
案例练习
定义一个函数 然后让函数计算两个数值的和 并且返回这个计算之后的结果
def sum(a,b): c = a + b return c
a = sum(123,456) print(a)
<a name="dvYsX"></a>### 局部变量与全局变量```python# 局部变量:在函数的内部定义的变量 我们称之为局部变量# 特点:其作用域范围是函数内部,而函数的外部是不可以使用def f1():# 在函数内部定义的变量 我们叫做局部变量a = 1print(a)f1()# print(a)# 全局变量: 定义在函数外部的变量 我们称之为全局变量# 特点:可以在函数的外部使用,也可以在函数的内部使用a = 1print(a)def f1():print(a)f1()# 在满足条件的情况 要使用作用域最小的那个变量范围
文件
文件的打开和关闭
# 在python,使用open函数可以打开一个已经存在的文件,或者创建一个新文件# 格式为:open(文件路径,访问模式)# 模式: w 可写# r 可读# 创建一个test.txt文件open('test.txt','w')# 打开文件fp = open('test.txt','w')# 文件夹是不可以创建的 暂时需要手动创建# fp = open('demo/text.txt','w')# 文件的关闭fp = open('a.txt','w')fp.close()
- 文件路径
- 绝对路径:指的是绝对位置,完整地描述了目标的所在地,所有目录层级关系是一目了然的
- 例如:
E:\python,从电脑的盘符开始,表示的就是一个绝对路径。
- 例如:
- 相对路径:是从当前文件所在的文件夹开始的路径
test.txt,是在当前文件夹查找test.txt文件./test.txt,也是在当前文件夹里查找test.txt文件,./表示的是当前文件夹../test.txt,从当前文件夹的上一级文件夹里查找test.txt文件。../表示的是上一级文件夹demo/test.txt,在当前文件夹里查找demo这个文件夹,并在这个文件夹里查找test.txt文件
- 访问模式
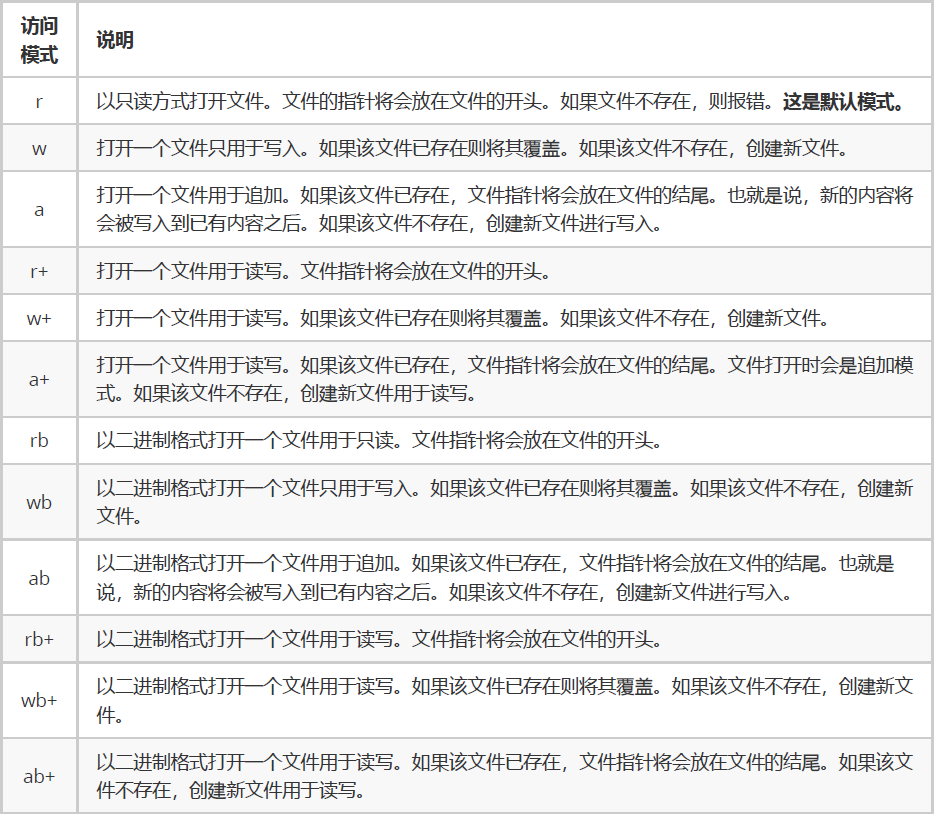
文件的读写
# 写数据:write方法fp = open('test.txt','w')fp.write('hello world,i am here\n' * 5)fp.close()# 如果我再次来运行这段代码 会打印10次还是打印5呢?# 如果文件不存在,那么创建;如果文件存在 会先清空原来的数据 然后再写# 我想在每一次执行之后都要追加数据# 如果模式变为了a 那么就会执行追加的操作# 读数据:read方法fp = open('test.txt','r')# 默认情况下 read是一字节一字节的读 效率比较低# content = fp.read()# print(content)# readline是一行一行的读取 但是只能读取一行# content = fp.readline()# print(content)# readlines可以按照行来读取 但是会将所有的数据都读取到 并且以一个列表的形式返回# 而列表的元素 是一行一行的数据content = fp.readlines()print(content)
文件的序列化和反序列化
通过文件操作,我们可以将字符串写入到一个本地文件。但是,如果是一个对象(例如列表、字典、元组等),就无法直接写入到一个文件里,需要对这个对象进行序列化,然后才能写入到文件里。
设计一套协议,按照某种规则,把内存中的数据转换为字节序列,保存到文件,这就是序列化,反之,从文件的字节序列恢复到内存中,就是反序列化。
- 对象 ——- 字节序列 ——- 序列化
- 字节序列 ——- 对象 ——- 反序列化
Python中提供了Json这个模块用来实现数据的序列化和反序列化
# 序列化的2种方式# 1. dumps()fp = open('test.txt','w')name_list = ['zs','ls']# 导入json模块到该文件中import json# 序列化:将python对象 变成 json字符串# 我们在使用scrapy框架的时候 该框架会返回一个对象 我们要将对象写入到文件中 就要使用json.dumpsnames = json.dumps(name_list)# 将names写入到文件中fp.write(names)fp.close()# 2. dump# 在将对象转换为字符串的同时,指定一个文件的对象 然后把转换后的字符串写入到这个文件里fp = open('text.txt','w')name_list = ['zs','ls']import json# 相当于names = json.dumps(name_list) 和 fp.write(names)json.dump(name_list,fp)fp.close()# 反序列化:将json的字符串变成一个python对象# 1. loads():loads方法需要一个字符串参数,用来将一个字符串加载成为Python对象。fp = open('text.txt','r')content = fp.read()# 读取之后 是字符串类型的# print(content)# print(type(content))import json# 将json字符串变成python对象result = json.loads(content)print(result)print(type(result))# 2. load():load方法可以传入一个文件对象,用来将一个文件对象里的数据加载成为Python对象fp = open('text.txt','r')import jsonresult = json.load(fp)print(result)print(type(result))fp.close()
异常
在读取一个文件时,如果这个文件不存在,则会报出FileNotFoundError 错误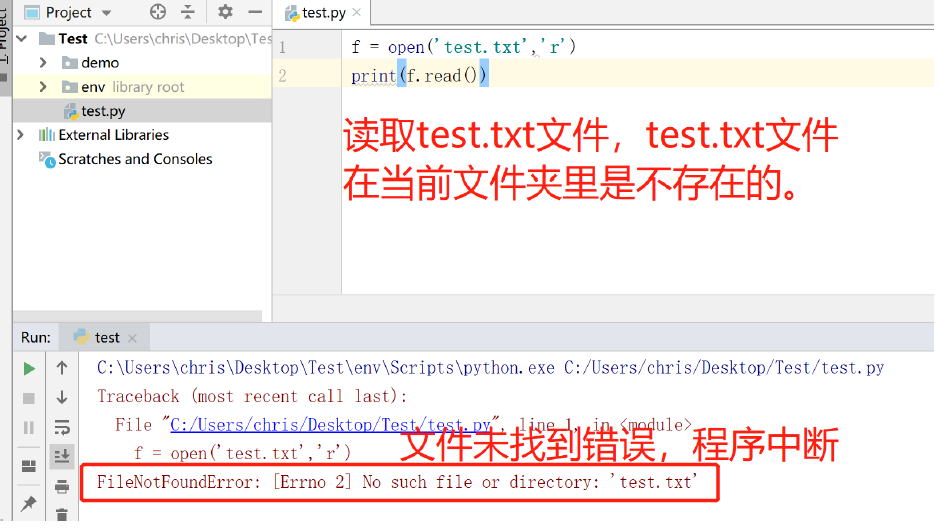
try...except 语句可以对代码运行过程中可能出现的异常进行处理
'''try:可能会出现异常的代码块except 异常的类型:出现异常以后的处理语句'''try:f = open('test.txt', 'r')print(f.read())except FileNotFoundError:print('文件没有找到,请检查文件名称是否正确')

若有收获,就点个赞吧
0 人点赞
