概述
全称为Resilient Distributed Datasets,弹性分布式数据集,是Spark中最基本的数据(计算)抽象,它代表一个不可变,可分区,里面的元素可并行计算的集合。RDD在逻辑上是一个数据集,在物理上则可以分块分布在不同的机器上并发运行。RDD允许用户在执行多个查询时显示的将工作缓存在内存中,后续的查询能够重用工作集,这极大的提升了查询速度。
在Spark 中,对数据的所有操作不外乎创建RDD,转换已有RDD以及调用RDD操作进行求值,每个RDD都被分为多个分区,这些分区运行在集群的不同节点上,RDD可以包含Python,Java,Scala中任意类型的对象,甚至可以是用户自定义对象。
RDD是Spark的核心,也是整个Spark的架构基础。它的特性可以总结如下:
- 它是不变的数据结构存储
- 它是支持跨集群的分布式数据结构
- 可以根据数据记录的key对结构进行分区
- 提供了粗粒度的操作,且这些操作都支持分区
- 它将数据存储在内存中,从而提供了低延迟性
弹性
弹性即是RDD的每个分区的大小都是不固定的,不像hdfs那样,每个数据块就是128MB。因此,RDD是有弹性的。
分布式即是RDD的每个分区分布在集群的各个节点上,而非集中存在于一个节点。创建RDD
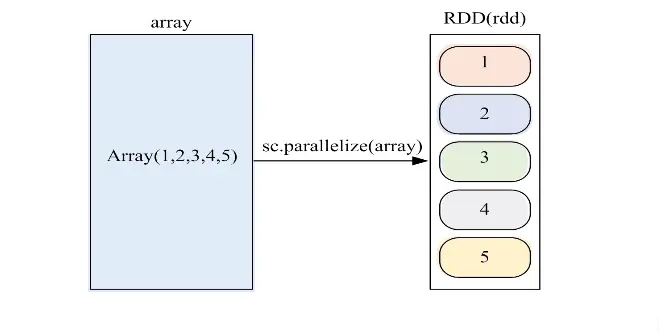
并行集合(数组)
方法:parallelize
val conf = new SparkConf().setAppName("CreateRDDApp").setMaster("local")val sc = new SparkContext(conf)val rdd = sc.makeRDD(Array(1,2,3,4,5))val r = sc.parallelize(Array(1,2,3,4,5))
执行spark-shell
# spark-shellSpark context available as 'sc' (master = local[*], app id = local-1565534714937).Spark session available as 'spark'.Welcome to____ __/ __/__ ___ _____/ /___\ \/ _ \/ _ `/ __/ '_//___/ .__/\_,_/_/ /_/\_\ version 2.3.3/_/Using Scala version 2.11.8 (OpenJDK 64-Bit Server VM, Java 1.8.0_222)Type in expressions to have them evaluated.Type :help for more information.scala> val array = Array(1,2,3,4,5)array: Array[Int] = Array(1, 2, 3, 4, 5)scala> val rdd = sc.parallelize(array)rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:26
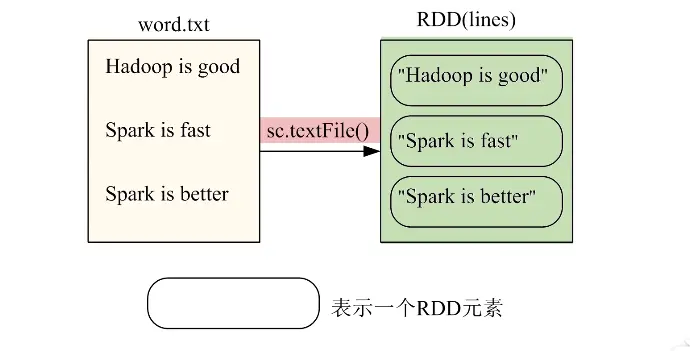
文件系统中加载
SparkContext通过textFile()读取数据生成内存中的RDD
支持的数据类型:
- 本地文件系统(file://)
- 分布式文件系统HDFS加载数据(hdfs://)
- 云端Amazon S3
// 通过外部数据sc.textFile("") // 本地路径 或者hdfs
文件系统读读取
设置文件word.txt
Hadoop is goodSpark is fastSpark is better
val conf = new SparkConf().setAppName("SparkWordCount").setMaster("local[*]")val sc = new SparkContext(conf)val lines= sc.textFile("file:///Users/baxiang/BigData/SparkNote/src/word.txt")lines.collect().foreach(println)
操作
支持两种操作转化操作和行动操作。RDD的转化操作是返回一个新的RDD的操作,map和filter
行动操作则是驱动器程序返回结果或把结果写入外部系统的操作 count,first.
Spark采用惰性计算模式,RDD只有第一次在一个行动操作中得到时,才会真正计算,spark可以优化整个计算过程,默认情况下,spark的RDD会在每次他们进行行动操作是重新计算。
如果需要多个行动中重用一个RDD,可以使用RDD.persist()让Spark把这个RDD缓存下来。
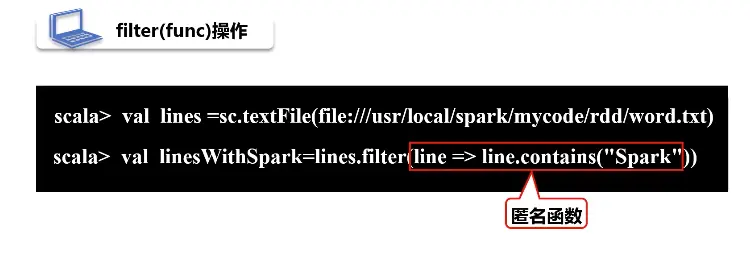
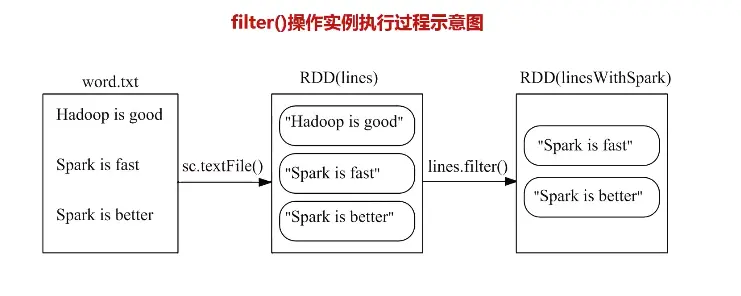
filter过滤
筛选出满足函数func的元素,并返回一个新的数据集
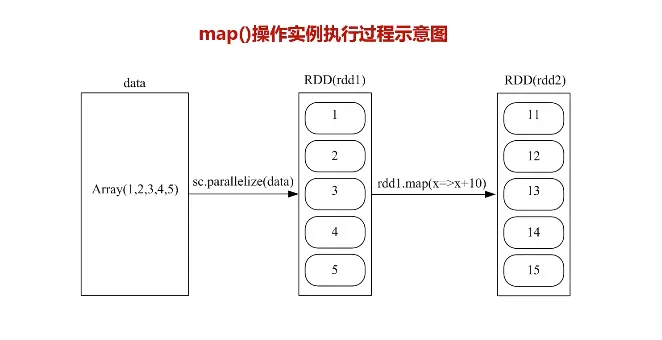
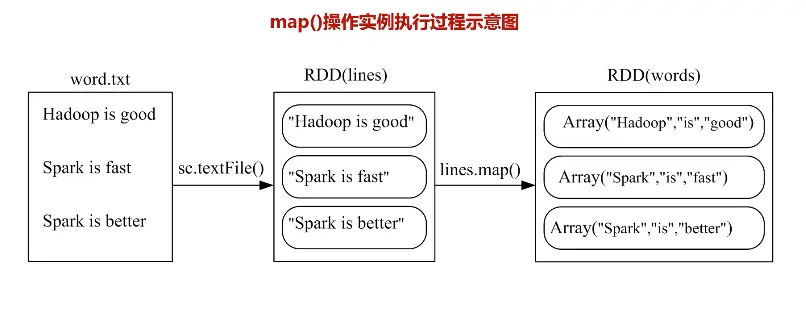
map
将每个元素传递到函数func中,并将结果返回为一个新的数据集


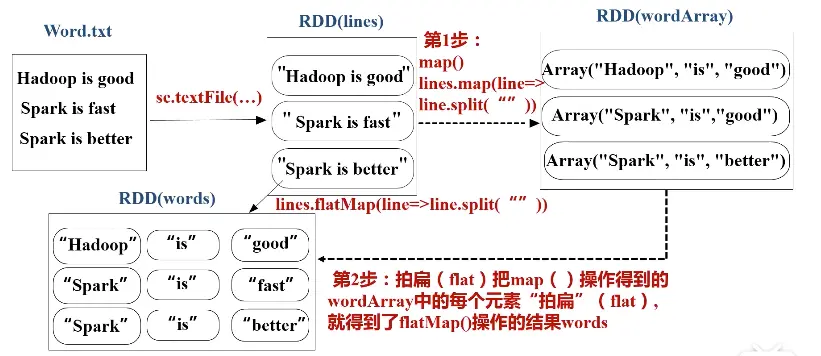
flatMap(func)
与map()相似,但每个输入元素都可以映射到0或多个输出结果

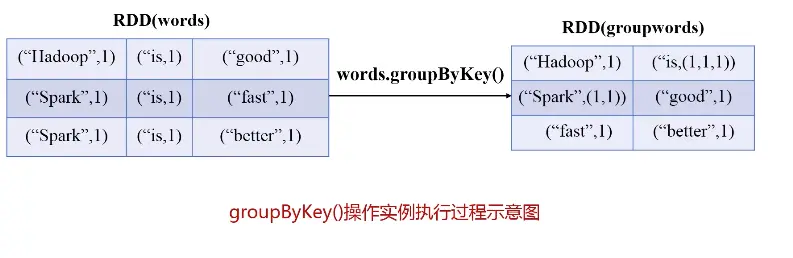
groupByKey()
应用于(K,V)键值对的数据集时,返回一个新的(K,Iterable)形式的数据集
reduceByKey(func)
应用于(K,V)键值对的数据集时,返回一个新的(K,V)形式的数据集,其中每个值是将每个key传递到函数func中进行聚合后的结果。
- 进行分组得到(key,value-list)
- 根据传入的函数再将value-list做操作

打印元素
在实际编程中,我们经常需要把RDD中的元素打印输出到屏幕上(标准输出stdout),一般会采用语句rdd.foreach(println)或者rdd.map(println)。当采用本地模式(local)在单机上执行时,这些语句会打印出一个RDD中的所有元素。但是,当采用集群模式执行时,在worker节点上执行打印语句是输出到worker节点的stdout中,而不是输出到任务控制节点Driver Program中,因此,任务控制节点Driver Program中的stdout是不会显示打印语句的这些输出内容的。为了能够把所有worker节点上的打印输出信息也显示到Driver Program中,可以使用collect()方法,比如,rdd.collect().foreach(println),但是,由于collect()方法会把各个worker节点上的所有RDD元素都抓取到Driver Program中,因此,这可能会导致内存溢出。因此,当你只需要打印RDD的部分元素时,可以采用语句rdd.take(100).foreach(println)。

若有收获,就点个赞吧
0 人点赞
