概述
英文全称是The Hadoop Distributed File System
官方地址http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
Block数据块
默认最基本的存储单位,默认块的大小是64MB,或者是128m,HDFS的文件是分成以block size 为大小的数据块存储的,如果一个文件小于一个数据块的大小,并不是整个数据块的存储空间,文件大小是多大的就占用多少存储空间。
元数据节点Name Node
管理文件系统的命名空间,它将所有的文件和文件夹的元数据保存在一个文件系统树种。一个文件包括哪些数据块,这些数据块分布在哪些数据节点上,这些信息都要存储下来。
数据节点Data Node
文件系统的真正存储数据的地方,一个文件被拆分多个Block后,会将这些Block存储在对应的数据节点上
从数据节点 Secondary NameNode
并不是NameNode节点出现问题是备用节点,它和元数据节点分别负责不同的功能,其主要功能就是周期性地将NameNode的namespace image和edit log合并,防止日志文件过大。
架构
master(NameNode)/slave(DataNodes)主从架构,一个文件会被拆分层多个Block,blocksize默认值是128M,每个机器只存储文件的部分数据,block存放在不同的机器上的,由于容错,HDFS默认采用3个副本机制
主节点NameNode
负责管理整个文件系统的元数据(文件的名称,副本系数,Block存放的dataNode),负责客户端的请求的相应
数据节点DataNode
负责管理用户文件数据块,每一个数据块都可以在datanade上存储多个副本
从节点
用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
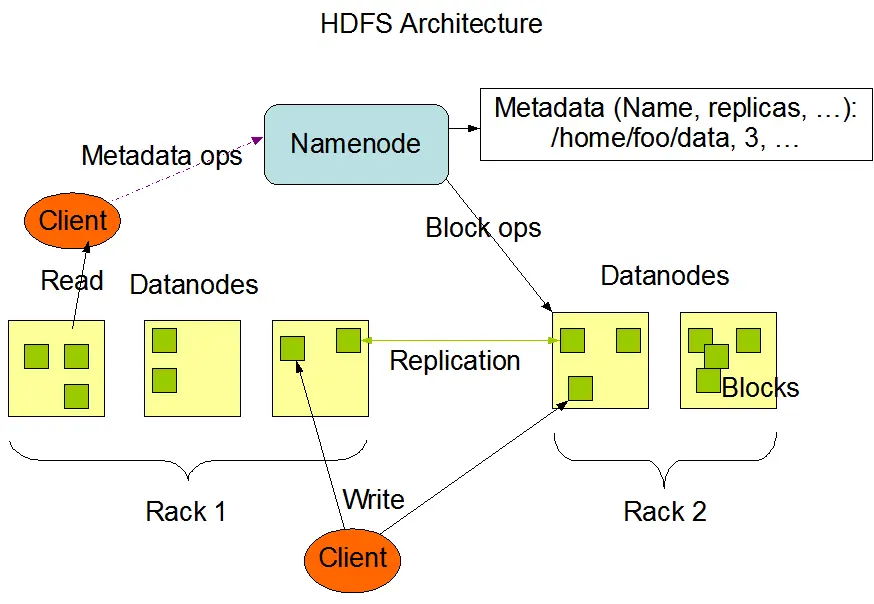
一个master承担NameNode,其他slave承担DataNode,一个文件会被拆分成Block,默认blockSize大小是128M,DataNode存储文件块。一个文件所有的块除了最后一块其他块大小都是一样的
HDFS安装
前置安装
1 安装jdk和ssh工具
修改机器名称 vi /etc/sysconfig/network
NETWORKING=yesHOSTNAME=hadoop
设置IP和hostname的映射关系 /etc/hosts
192.168.1.113 hadoop001127.0.0.1 localhost
设置ssh免密码登录
ssh-keygen -t rsacp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
安装hadoopcdh
下载地址:http://archive.cloudera.com/cdh5/cdh/5/

环境变量配置
vim .bash_profile
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_91export PATH=$JAVA_HOME/bin:$PATHexport HADOOP_HOME=/home/hadoop/app/hadoop-2.6.0-cdh5.15.1export PATH=$HADOOP_HOME/bin:$PATH
执行source .bash_profile让环境变量生效
Hadoop文件结构
[root@maste hadoop]# tree -d -L 2.├── bin├── bin-mapreduce1├── cloudera│ └── patches├── etc│ ├── hadoop│ ├── hadoop-mapreduce1│ ├── hadoop-mapreduce1-pseudo│ └── hadoop-mapreduce1-secure├── examples│ ├── bin│ ├── include│ └── lib├── examples-mapreduce1│ └── Linux-amd64-64├── include├── lib│ └── native├── libexec├── logs├── sbin│ └── Linux├── share│ ├── doc│ └── hadoop├── src│ ├── build│ ├── dev-support│ ├── hadoop-assemblies│ ├── hadoop-client│ ├── hadoop-common-project│ ├── hadoop-dist│ ├── hadoop-hdfs-project│ ├── hadoop-mapreduce1-project│ ├── hadoop-mapreduce-project│ ├── hadoop-maven-plugins│ ├── hadoop-minicluster│ ├── hadoop-project│ ├── hadoop-project-dist│ ├── hadoop-tools│ └── hadoop-yarn-project└── tmp└── dfs43 directories
其中重要的文件夹目录是:
bin Hadoop 客户端命令
etc/hadoop hadoop相关的配置文件存放目录
sbin 启动hadoop的相关命令的脚本
share使用的demo
hadoop相关配置
编辑 etc/hadoop/hadoop-env.sh 定义JAVA_HOME和HADOOP_PREFIX:
# set to the root of your Java installationexport JAVA_HOME=/usr/java/latest# Assuming your installation directory is /usr/local/hadoopexport HADOOP_PREFIX=/usr/local/hadoop
一般我们只需要配置export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.191.b12-1.el7_6.x86_64/就可以了。
执行启动hadoop命令
$ bin/hadoop
hadoop 配置
etc/hadoop/core-site.xml,hadoop.tmp.dir存放hadoop文件系统依赖的基本配置,如果hdfs-site.xml中不配置namenode和datanode的存放位置,默认就放在这个路径中
<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:8020/</value></property><property><name>hadoop.tmp.dir</name><value>/root/hadoop/tmp</value><description>存放hadoop文件系统依赖的基本配置</description></property></configuration>
修改etc/hadoop/hdfs-site.xml配置副本数量,对于单机节点副本只能是1个
<configuration><property><name>dfs.replication</name><value>1</value><description>设置副本数</description></property></configuration>
在sbin启动hdfs命令
sbin]$ ./start-dfs.sh$ jps16370 Jps15869 NameNode15998 DataNode16206 SecondaryNameNode
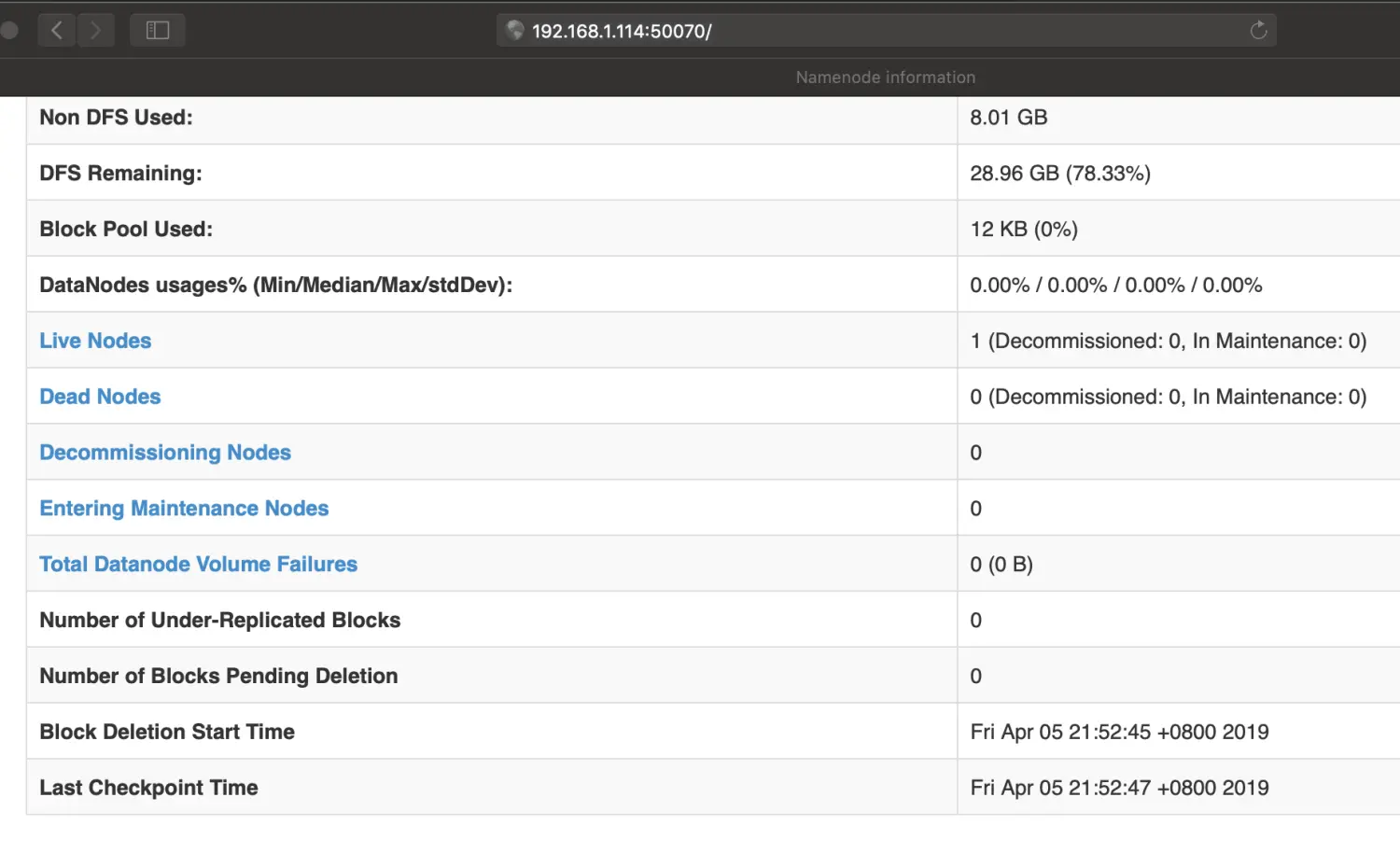
浏览器中输入{host}:50070也可以查看hdfs 情况
Shell操作
格式化
第一次执行需要格式化hadoop,清空整个数据,其中设置的数据目录会被格式化,这个不建议重复执行,会造成数据丢失。
hdfs namenode -format // 格式化hdfs....../root/hadoop/tmp/dfs/name has been successfully formatted.
创建文件目录
$hadoop fs -mkdir /test
列出文件目录
$ hadoop fs -ls /
创建联级目录
$ hadoop fs -mkdir -p /test/hello/input
递归查看目录文件
$ hadoop fs -ls -R /testdrwxr-xr-x - baxiang supergroup 0 2019-08-04 16:23 /test/hellodrwxr-xr-x - baxiang supergroup 0 2019-08-04 16:23 /test/hello/input
上传本地文件到HDFS
$ echo "hello word" >> hello.txt$ hadoop fs -put hello.txt /$ echo "hello hadoop" >> hadoop.txt$ hadoop fs -copyFromLocal hadoop.txt /
下载hdfs文件到本地
$ hadoop fs -get /hello.txt
查看文件内容
$ hadoop fs -cat /hello.txthello word$ hadoop fs -text /hello.txthello word
移动文件到文件夹
$ hadoop fs -mkdir /test$ hadoop fs -mv /hello.txt /test$ hadoop fs -ls /testFound 1 items-rw-r--r-- 1 hadoop supergroup 11 2019-04-05 22:18 /test/hello.txt
删除文件
hadoop fs -rm /hello.txt
删除文件夹
$ hadoop fs -rm -r /testDeleted /test
查看文件大小
统计文件大小使用的单位是字节
$ hadoop fs -du /test
问题总结
dadanode启动失败原因
问题的原因:在第一次格式化dfs后,启动并使用了hadoop,后来又重新执行了格式化命令(hdfs namenode -format),这时namenode的clusterID会重新生成,而datanode的clusterID 保持不变。
打开hdfs-site.xml里配置的datanode和namenode对应的目录,分别打开current文件夹里的VERSION,可以看到clusterID项正如日志里记录的一样,确实不一致,修改datanode里VERSION文件的clusterID 与namenode里的一致,再重新启动dfs(执行start-dfs.sh)再执行jps命令可以看到datanode已正常启动。

若有收获,就点个赞吧
0 人点赞
