概述
官方网站 http://spark.apache.org/
官方文档地址:http://spark.apache.org/docs/latest/

下载
安装Java环境
openjdk 官方教程地址 http://openjdk.java.net/install/
# yum search openjdk-dev

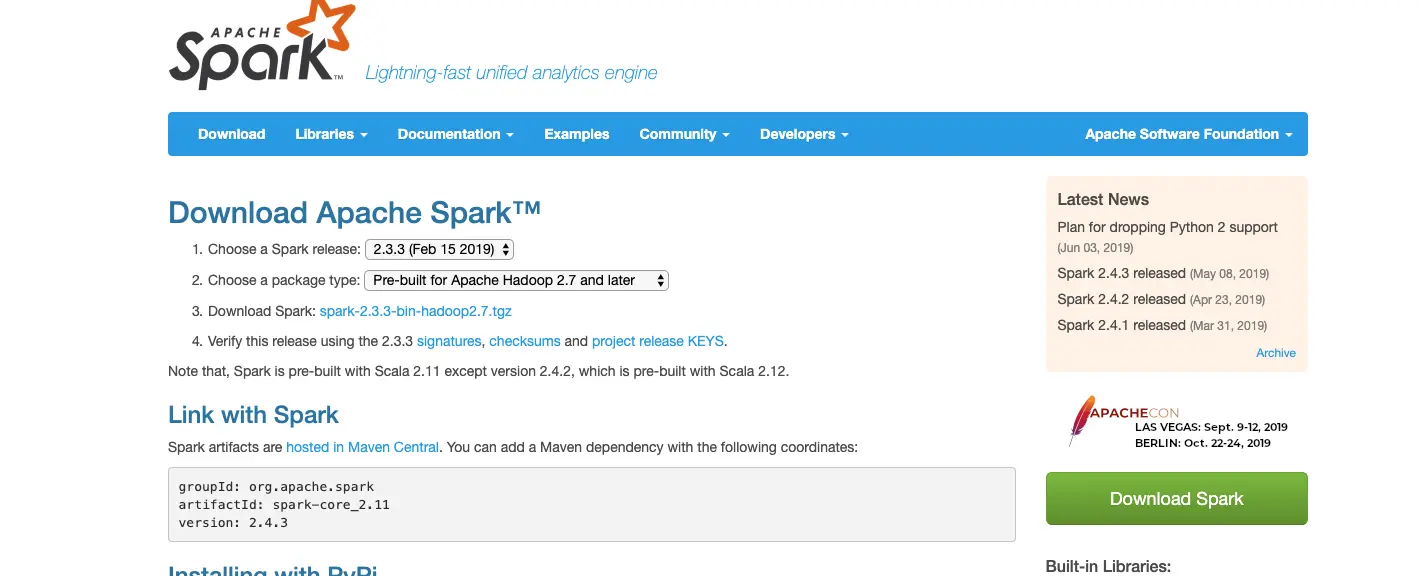
http://spark.apache.org/downloads.html
配置环境变量
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdkexport HADOOP_HOME=$HOME/app/hadoopexport PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/binexport SPARK_HOME=$HOME/app/sparkexport PATH=$PATH:$SPARK_HOME/bin
目录结构
| 目录 | 说明 |
|---|---|
| bin | 可执行脚本,Spark相关命令 |
| conf | spark配置文件 |
| data | spark自带例子用到的数据 |
| examples | spark自带样例程序 |
| jars | spark相关jar包 |
| sbin | 集群启停,因为spark有自带的集群环境 |
Spark软件包bin目录说明:
| 命令 | 说明 |
|---|---|
| spark-shell | spark shell模式启动命令 |
| spark-submit | spark应用程序提交脚本 |
| run-example | 运行spark提供的样例程序 |
| spark-sql | spark SQL命令启动命令 |
启动
/root/app/spark/sbin
./start-all.sh
提交任务
spark-submit --class org.apache.spark.examples.SparkPi --master spark://aliyun:7077 /root/app/spark/examples/jars/spark-examples_2.11-2.3.3.jar 100
计算结果
2019-08-16 20:17:34 INFO DAGScheduler:54 - Job 0 finished: reduce at SparkPi.scala:38, took 8.394727 sPi is roughly 3.1414743141474313
命令解释:
spark-submint :提交命令,提交应用程序,该命令在spark安装目录下的bin底下
–class org.apache.spark.examples.SparkPi:应用程序的主类
–master spark://aliyun:7077 :运行的master
/root/app/spark/examples/jars/spark-examples_2.11-2.3.3.jar:jar包所在路径
spak-shell
local模式
Local模式就是运行在一台计算机上的模式。
local 所有计算都运行在一个线程当中
locak[K]指定使用的几个线程运行计算
local[*]安装CPU最大core来设置线程数
spark
$ spark-shell --master spark://aliyun:7077
#spark-shell2019-08-05 19:31:54 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicableSetting default log level to "WARN".To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).Spark context Web UI available at http://aliyun:4040Spark context available as 'sc' (master = local[*], app id = local-1565004727280).Spark session available as 'spark'.Welcome to____ __/ __/__ ___ _____/ /___\ \/ _ \/ _ `/ __/ '_//___/ .__/\_,_/_/ /_/\_\ version 2.3.3/_/Using Scala version 2.11.8 (OpenJDK 64-Bit Server VM, Java 1.8.0_222)Type in expressions to have them evaluated.Type :help for more information.
spark laocal本地运行模式 local[*]以当前cpu核数运行
Spark context available as 'sc' (master = local[*], app id = local-1565004727280).Spark session available as 'spark'.
在spark的安装目录底下创建测试文件
# cd $SPARK_HOME# mkdir input# vim word.txthello worldhello sparkhello hadoop
启动spark-shell, 读取本地文件input文件夹数据;
# spark-shellscala> sc.textFile("input")res0: org.apache.spark.rdd.RDD[String] = input MapPartitionsRDD[1] at textFile at <console>:25
压平操作,按照空格分割符将一行数据映射成一个个单词;
scala> sc.textFile("input").flatMap(_.split(" "))res1: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[4] at flatMap at <console>:25
对每一个元素操作,将单词映射为元组;
scala> sc.textFile("input").flatMap(_.split(" "))res1: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[4] at flatMap at <console>:25
按照key将值进行聚合,相加,统计结果
scala> sc.textFile("input").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collectres4: Array[(String, Int)] = Array((spark,1), (hadoop,1), (hello,3), (world,1))
Maven 的worldcount
pom.xml
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>cn.bx</groupId><artifactId>WordCount</artifactId><version>1.0-SNAPSHOT</version><properties><spark.version>2.2.3</spark.version></properties><dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>${spark.version}</version></dependency></dependencies><build><finalName>WordCount</finalName><plugins><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>4.1.1</version><executions><execution><goals><goal>compile</goal></goals></execution></executions></plugin></plugins></build></project>
创建测试文件 点击最上层工程目录创建input目录 word.txt
hello sparkhello scalahello hivehello hadoop
创建src/main/scala目录下WordCount
package cn.bx.sparkimport org.apache.spark.{SparkConf, SparkContext}object WordCount {def main(args: Array[String]): Unit = {val conf = new SparkConf().setAppName("WordCount").setMaster("local[*]")val sc = new SparkContext(conf)val lines = sc.textFile("input")val words = lines.flatMap(_.split(" "))val wordToOne = words.map((_, 1))val wordToSum = wordToOne.reduceByKey(_ + _)wordToSum.collect().foreach(println)}}
执行结果
(scala,1)(hive,1)(hello,4)(spark,1)(hadoop,1)
开发hadoop的worldcount
设置maven,修改pom.xml
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>cn.bx</groupId><artifactId>SparkNote</artifactId><version>1.0-SNAPSHOT</version><properties><scala.version>2.11.12</scala.version><spark.version>2.2.3</spark.version><hadoop.version>2.6.0</hadoop.version></properties><dependencies><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version></dependency><!--spark core depedency--><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>${spark.version}</version></dependency><!--hadoop-client depedency--><!-- <dependency>--><!-- <groupId>org.apache.hadoop</groupId>--><!-- <artifactId>hadoop-client</artifactId>--><!-- <version>${hadoop.version}</version>--><!-- </dependency>--></dependencies><build><sourceDirectory>src/main/scala</sourceDirectory><plugins><plugin><groupId>org.scala-tools</groupId><artifactId>maven-scala-plugin</artifactId><version>2.15.0</version><executions><execution><goals><goal>compile</goal></goals><configuration><args><arg>-dependencyfile</arg><arg>${project.build.directory}/.scala_dependencies</arg></args></configuration></execution></executions></plugin></plugins></build></project>
在main/scala/创建SparkWordCount.scala
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}object SparkWordCount {def main(args: Array[String]): Unit = {val conf = new SparkConf().setAppName("SparkWordCount")val sc = new SparkContext(conf)val lines:RDD[String]= sc.textFile(args(0))val words:RDD[String]= lines.flatMap(_.split(" "))val tuples:RDD[(String,Int)] =words.map((_,1))val sum:RDD[(String,Int)] = tuples.reduceByKey(_+_)val sored:RDD[(String,Int)]= sum.sortBy(_._2,ascending = false)sored.saveAsTextFile(args(1))sc.stop()}}
提交jar
vim word.txt
hello world
hello world
hello spark
hello java
hello golang
hello hadoop
将当word.txt放入hdfs中
#hadoop fs -mkdir -p /wc/input
# hadoop fs -put word.txt /wc/input/
# hadoop fs -cat /wc/input/word.txt
hello world
hello world
hello spark
hello java
hello golang
hello hadoop
maven 编译成jar
# spark-submit --class SparkWordCount --master spark://aliyun:7077 SparkNote-1.0-SNAPSHOT.jar hdfs://localhost:9000/wc/input/word.txt hdfs://localhost:9000/wc/output
执行结果
hadoop fs -ls /wc/output/
19/08/07 01:02:33 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 3 items
-rw-r--r-- 3 root supergroup 0 2019-08-07 01:01 /wc/output/_SUCCESS
-rw-r--r-- 3 root supergroup 20 2019-08-07 01:01 /wc/output/part-00000
-rw-r--r-- 3 root supergroup 41 2019-08-07 01:01 /wc/output/part-00001
查看结果
# hadoop fs -cat /wc/output/part-00000
(hello,6)
(world,2)
# hadoop fs -cat /wc/output/part-00001
(golang,1)
(java,1)
(spark,1)
(hadoop,1)

若有收获,就点个赞吧
0 人点赞
