概述
官方地址 http://spark.apache.org/sql/
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了2个编程抽象:DataFrame和DataSet,并且作为分布式SQL查询引擎的作用。
Spark SQL可以很好地支持SQL查询,一方面,可以编写Spark应用程序使用SQL语句进行数据查询,另一方面,也可以使用标准的数据库连接器(比如JDBC或ODBC)连接Spark进行SQL查询。
DataFrame
SparkSQL使用的数据抽象是DataFrame ,DataFrame让Spark具备了处理大数据结构化数据的能力,它不仅比原来的RDD转换方式更加简单易用,而且获得了更高的计算能力。Spark 能够轻松实现从Mysql到DataFrame的转化,并且支持SQL查询。
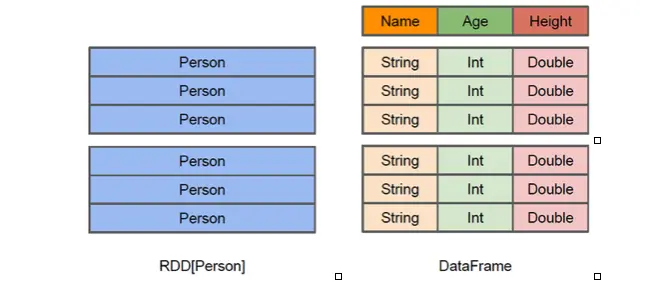
DataFrame是一种以RDD为基础的分布式数据集,提供了详细的数据信息,就相当于关系数据库的一张表,每个RDD元素都是一个Java对象,即Person对象,但是无法知道Person对象的内部结构信息,而采用DataFrame时,Person对象内部机构信息一目了然。它包含Name,Age,并且知道每个字段的数据类型。
DataFrame创建
从Spark2.0以上版本开始,Spark使用全新的SparkSession接口替代Spark1.6中的SQLContext及HiveContext接口来实现其对数据加载、转换、处理等功能。SparkSession实现了SQLContext及HiveContext所有功能。
SparkSession支持从不同的数据源加载数据,并把数据转换成DataFrame,并且支持把DataFrame转换成SQLContext自身中的表,然后使用SQL语句来操作数据。SparkSession亦提供了HiveQL以及其他依赖于Hive的功能的支持。
HelloWorld
在当前工程目录底下创建input目录 创建测试数据文件 people.json
{"name":"Michael"}{"name":"Andy", "age":30}{"name":"Justin", "age":19}
maven 配置
https://mvnrepository.com/search?q=org.apache.spark
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>cn.bx.spark</groupId><artifactId>SparkNote</artifactId><version>1.0-SNAPSHOT</version><properties><scala.version>2.11.12</scala.version><spark.version>2.2.3</spark.version></properties><dependencies><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.11</artifactId><version>${spark.version}</version></dependency></dependencies><build><sourceDirectory>src/main/scala</sourceDirectory><plugins><plugin><groupId>org.scala-tools</groupId><artifactId>maven-scala-plugin</artifactId><version>2.15.0</version><executions><execution><goals><goal>compile</goal></goals><configuration><args><arg>-dependencyfile</arg><arg>${project.build.directory}/.scala_dependencies</arg></args></configuration></execution></executions></plugin></plugins></build></project>
SparkSQL.scala
package cn.bx.sparkimport org.apache.spark.sql.{DataFrame, SparkSession}object SparkSQLNote {def main(args: Array[String]): Unit = {val sparkSession: SparkSession = SparkSession.builder().master("local[*]").getOrCreate()val df: DataFrame = sparkSession.read.json("input/people.json")df.show()df.printSchema()df.select(df("name"),df("age")).show()df.filter(df("age") > 20 ).show()df.groupBy("name").count().show()df.sort(df("age").desc).show()df.sort(df("age").desc, df("name").asc).show()df.select(df("name").as("user_name"),df("age").as("user_age")).show()sparkSession.stop()}}

若有收获,就点个赞吧
0 人点赞
