2.1 经验误差与过拟合
| m个样本,a个分类错误: | 错误率: |
|---|---|
| 精度 = 1 - 错误率: | 精度: |
误差:样本真实输出与预测输出之间的差异

过拟合:学习机器把训练样本学习的“太好”,会导致泛化性下降,也就是面对新样本时,效果不佳
- 学习能力过于强大,解决办法:
- 优化目标加正则项
- 早些停止
- 学习能力过于强大,解决办法:
欠拟合:与过拟合相反,训练不够时。
- 学习能力不足,解决办法:
- 加大学习
- 学习能力不足,解决办法:
现实中,往往有多种学习算法可供选择,甚至同一算法不同的参数配置时,也会产生不同模型,如何选择,即“模型选择”。理想解决方案是对候选模型泛化误差进行评估,然后选择泛化误差最小的模型。
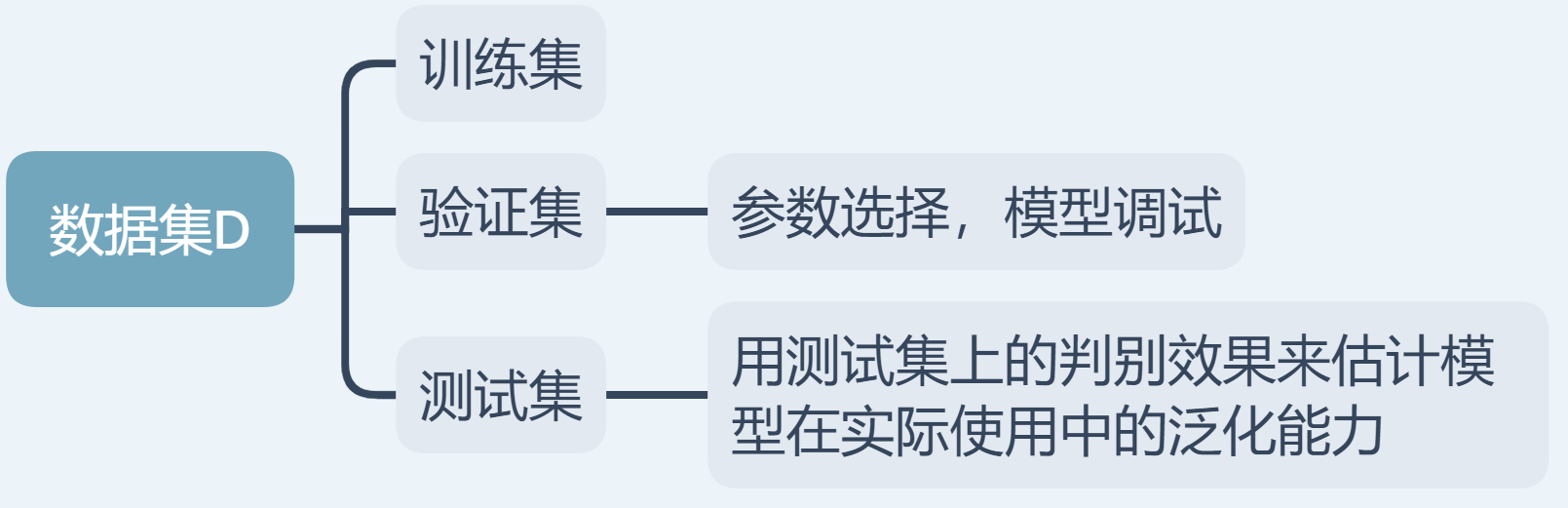
2.2 评估方法
- 通过“测试集”来测试学习机器对新样本的判别能力,然后以测试集上的“测试误差”作为“泛化误差”的近似。
- 测试样本:
- 从样本真实分布中独立同分布采样
- 与训练集尽可能互斥(未出现,未使用过的)
- 但是,我们只有一个包含m个样例的数据集D,如何做到既要训练,又要测试?
2.2.1 留出法
- 直接将数据集D划分为两个互斥集合,训练集S,测试集T。

- 训练/测试集划分要尽可能保持数据分布的一致性。比如在分类任务中要保持样本的类别比例相似。
- 一般若干次随机划分,重复试验平均值。
-
2.2.2 交叉验证法
将数据集
 分层采样划分为k个大小相似的互斥子集
分层采样划分为k个大小相似的互斥子集 ,每个子集
,每个子集 都尽可能与数据分布一致。每次用k-1个子集的并集作为训练集,余下子集作为测试集。最后返回k个测试结果的均值。又称“k折交叉验证”。k通常取10,称为10折交叉验证。为减少因样本不同引入的差别,k折交叉验证通常要随机使用不同的划分重复p次,最终结果是这p次k折交叉验证结果的均值。常见“10次10折交叉验证”
都尽可能与数据分布一致。每次用k-1个子集的并集作为训练集,余下子集作为测试集。最后返回k个测试结果的均值。又称“k折交叉验证”。k通常取10,称为10折交叉验证。为减少因样本不同引入的差别,k折交叉验证通常要随机使用不同的划分重复p次,最终结果是这p次k折交叉验证结果的均值。常见“10次10折交叉验证”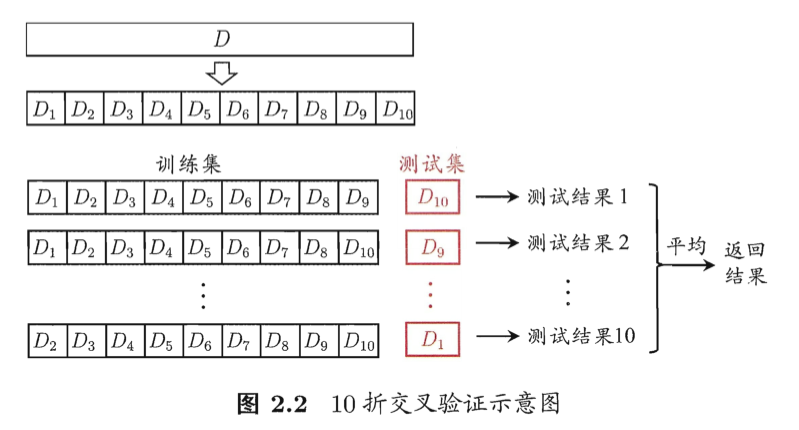
特例:留一法:数据集D中包含m个样本,令k=m,则每次只留1个测试。留一法不受随机样本划分方式的影响。 结果准确
-
2.2.3 自助法
以自助采样法为基础,给定包含m个样本的数据集
,有放回的采样 :每次从中随机选取一个样本,放入中,然后该样本在中仍保留,使得该样本下次采样也可以被采到;重复
:每次从中随机选取一个样本,放入中,然后该样本在中仍保留,使得该样本下次采样也可以被采到;重复 次,得到包含个样本的数据集(中有一部分在中重复出现,有一部分从未出现)
次,得到包含个样本的数据集(中有一部分在中重复出现,有一部分从未出现)
样本在次采样中始终不被采到的概率: ,所以,数据集中大约有
,所以,数据集中大约有 d的样本未出现在训练集中,
d的样本未出现在训练集中, 用作测试集。
用作测试集。
实际评估的模型与期望评估的模型都使用个训练样本,而我们仍有数据总量约为 的没有在训练集中出现,而用于测试,又称“包外估计”
的没有在训练集中出现,而用于测试,又称“包外估计” 使用场合:数据量小,难以有效划分训练/测试集。
- 此外,能产生多个不同的训练集,对集成学习有益。
- 然而,改变了原始分布,引入了估计偏差
2.2.4 调参与最终模型
参数: 1.超参数——>调节参数 2.模型参数
算法都有些参数需要设定,参数配置不同,模型性能不同 ——> “参数调节”“调参”
调参与算法选择本质上是一致的:不同配置得到不同模型,把对应最好的模型参数作为结果。
2.3 性能度量
用来衡量模型泛化能力的评价标准。
预测任务中,样例集 ,其中
,其中 是实例
是实例 的真实标记。要估计学习器
的真实标记。要估计学习器 的性能,就要把预测结果
的性能,就要把预测结果 与真实标记
与真实标记 比较。
比较。
回归任务最常用的性能度量是“均方误差”:
2.3.1 错误率与精度
错误率:分错样本占样本总数的比例。![KJ]@YLML8}5SOVBH%6W($1O.jpg](/uploads/projects/baoxingcan@ai/b55d95974cde608ed45f336ea5e09a87.jpeg)
精度:分对样本占样本总数的比例。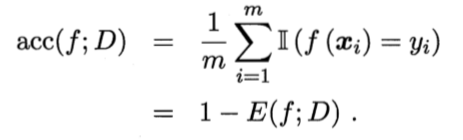
2.3.2 查准率、查全率与F1
| 真实情况 | 预测结果 | |
|---|---|---|
| 正例 | 反例 | |
| 正例 | TP(真正例) | FN(假反例) |
| 反例 | FP(假正例) | TN(真正例) |
查准率: (准不准,竖向相加) 查全率:
(准不准,竖向相加) 查全率: (全不全,横向相加)
(全不全,横向相加)
查准率、查全率是一对矛盾的量。一般而言,查准率高,查全率低;查准率低,查全率高。
根据预测结果对样例排序,排前面的“最可能”是正例的样本,排后面的“最不可能”是正例的样本。 按此顺序逐个把样本作为正例进行预测,计算当前的P,R值,得到P-R曲线,称为“P-R图”,如下:
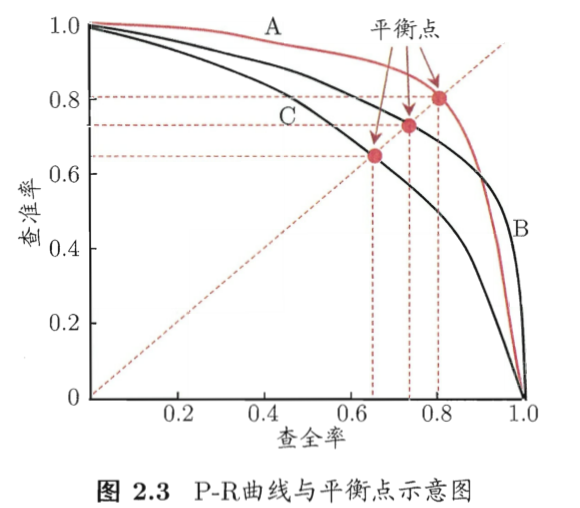
若一个学习器的P-R曲线被另一个完全包住,则后者的性能优于前者。如:A>C
而A、B不能随意下结论,有以下两种方法:
- 对比曲线下的面积大小,但不好估算
- 综合考虑查准率、查全率的性能度量。最优阈值的确定方法:
- 平衡点:查准率 = 查全率 的取值
- F1度量:

- F1度量更一般形式:由于存在一些情况中,对查准率,查全率重视程度不同:

- ,查准率更重要- 退化为F1- ,查全率更重要
 是基于查准率与查全率的调和平均定义的:
是基于查准率与查全率的调和平均定义的: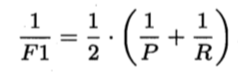
- 与算数平均
 和几何平均
和几何平均 相比,调和平均更重视较小值。
相比,调和平均更重视较小值。
- 与算数平均
 则是加权调和平均:
则是加权调和平均: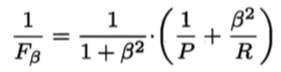
很多时候有多个二分类混淆矩阵,希望在n个二分类混淆矩阵上综合考虑查准率,查全率。
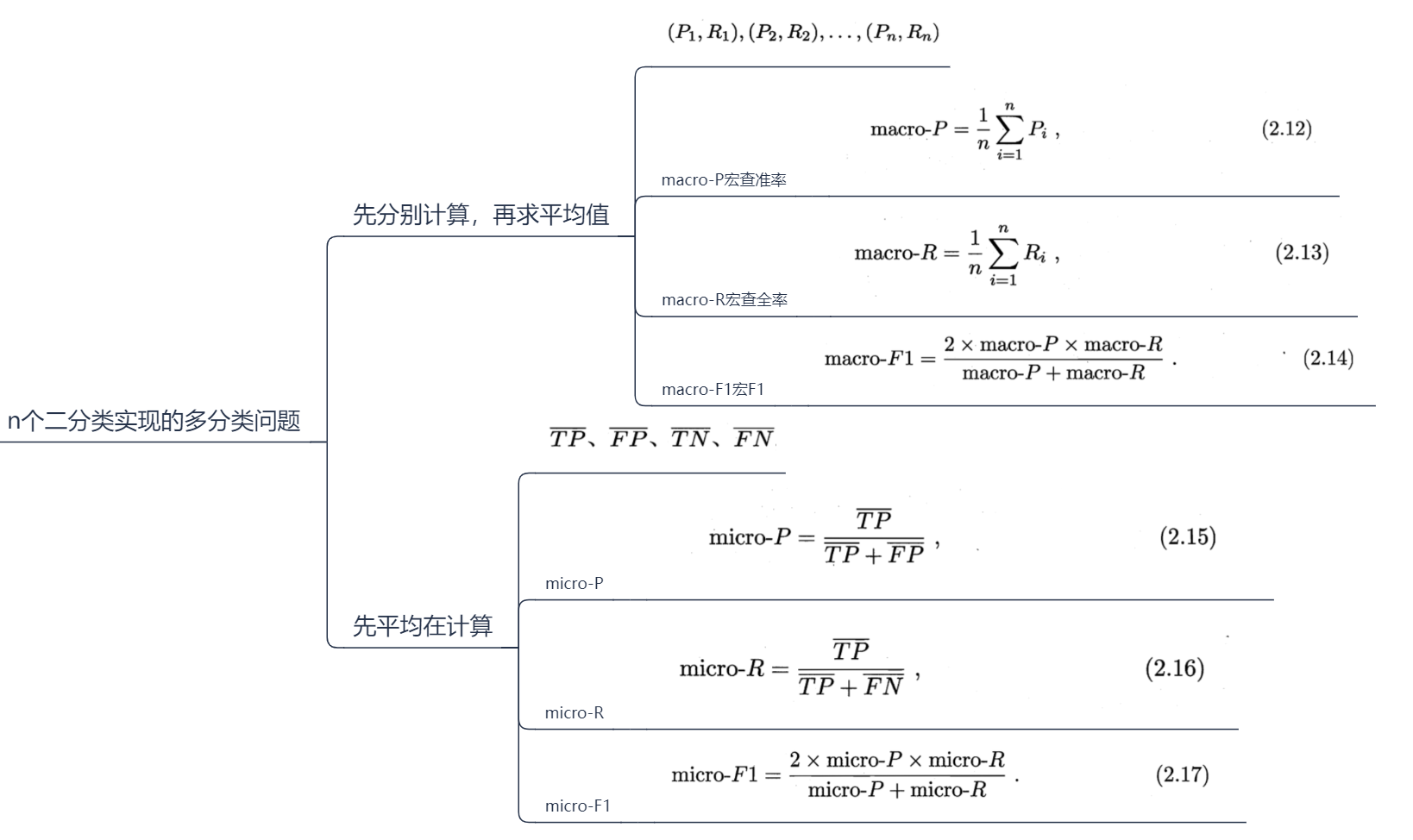
2.3.3 ROC与AOC
很多学习器是为测试样本产生一个实值或概率预测,将其与分类阈值threshold作比较,大于阈值为正类,小于阈值为反类。假如将实值或概率排序,“最可能”是正例排最前,“最不可能”是正例排最后,分类过程相当于在这个排序中以某个“截断点 cut point”将样本进行分类。不同任务,设定不同截断点。若更注重“查准率”则靠前;注重“查全率”则靠后。
根据学习器预测结果对样例排序,按此顺序逐个把样本作为正例预测,每次计算两个值:
纵轴“真正例率”:
横轴“假正例率”:
绘图过程:给定m+个正例,m-个反例
- 根据预测排序,然后将分类阈值设为最大,即把所有样例均预测为反例,此时(0,0)
- 将分类阈值依次设为每个样例预测值,依次将每个样例划分为正例,设前一个标记点坐标为(x,y)
- 当前若为真正例,坐标:
 ;当前若为假正例,坐标:
;当前若为假正例,坐标:
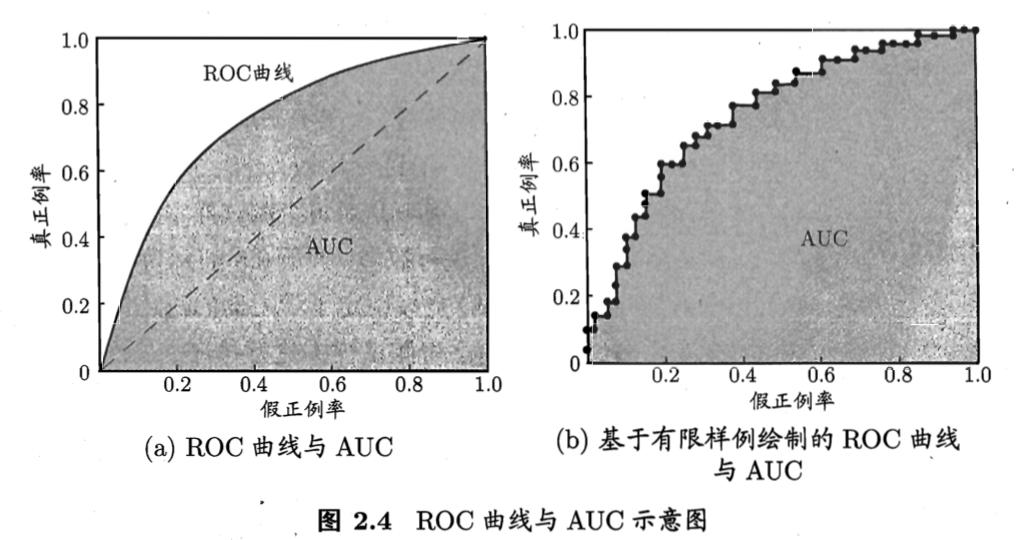
学习器比较时,若一个包住另一个,则可说前者优于后者。若有交叉,可比较ROC曲线下的面积AUC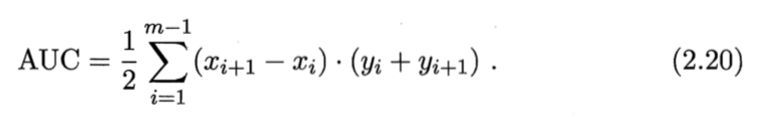
问:为什么用梯形公式,不用矩形公式? 答:如果有几个预测概率相同的正反样例,出现对角线,就会用梯形公式。

2.3.4 代价敏感错误率与代价曲线
为权衡不同类型错误所造成的的不同损失,可将错误赋予“非均等代价”(unequal cost)。
以二分问题为例,设定一个“代价矩阵”(cost matrix)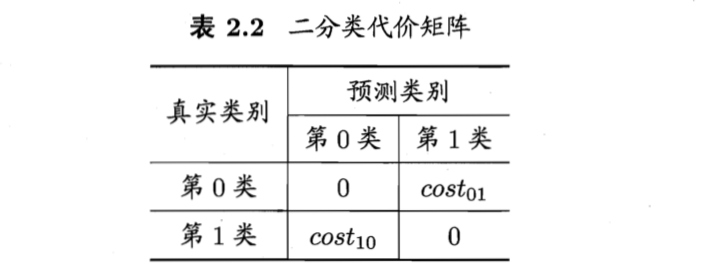
损失程度相对越大,cost与cost值差别越大。一般对比其值,如 5:1 = 50:10
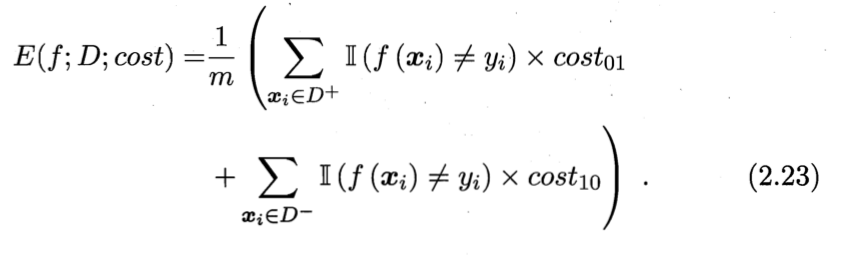
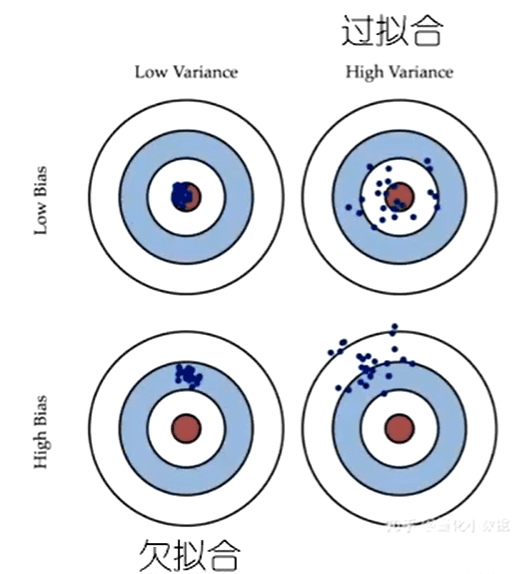
2.5 偏差与方差
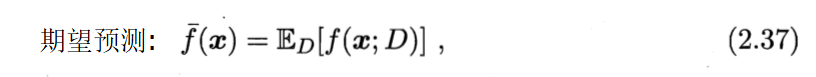<br /> 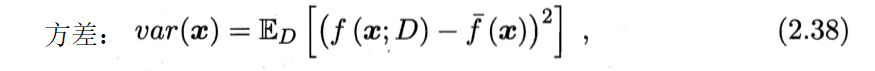<br />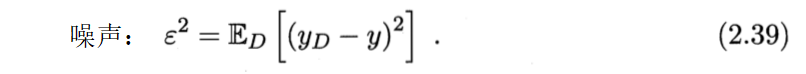<br /> 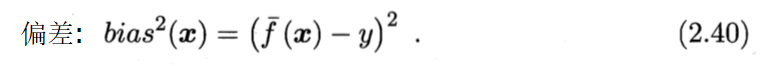
泛化误差可分解为偏差、方差与噪声之和。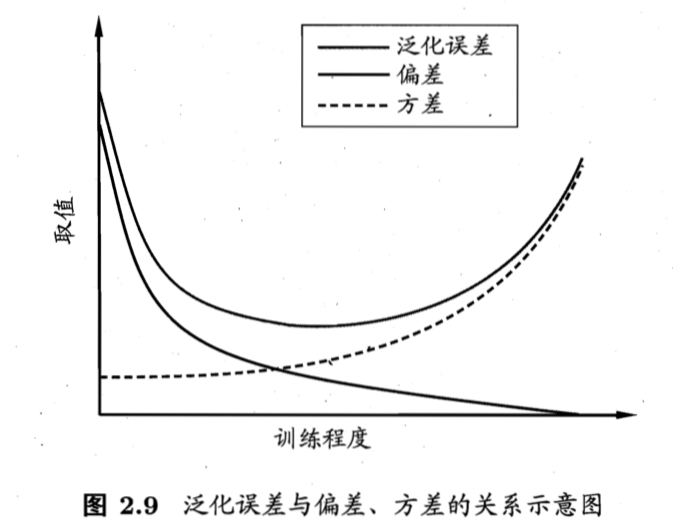

若有收获,就点个赞吧
0 人点赞
